![Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering]()
Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering
Graph ConvNets in PyTorch October 15, 2017 Xavier Bresson http://www.ntu.edu.sg/home/xbresson https://github.com/xbresson https://twitter.com/xbresson
![Conference planning tool: CfP, scheduling, speaker management]()
Conference planning tool: CfP, scheduling, speaker management
pretalx is a conference planning tool focused on providing the best experience for organisers, speakers, reviewers, and attendees alike. It handles th
![Conference planning tool: CfP, scheduling, speaker management]()
Conference planning tool: CfP, scheduling, speaker management
pretalx is a conference planning tool focused on providing the best experience for organisers, speakers, reviewers, and attendees alike. It handles th
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model Edresson Casanova, Christopher Shulby, Eren Gölge, Nicolas Michael Müller, Frede
![This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization.]()
![ERISHA is a mulitilingual multispeaker expressive speech synthesis framework. It can transfer the expressivity to the speaker's voice for which no expressive speech corpus is available.]()
![PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation]()
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
![PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation]()
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
![Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)]()
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
Use android as mic/speaker for ubuntu
Pulse Audio Control Panel Platforms Requirements sudo apt install ffmpeg pactl (already installed) Download Download the AppImage from release page ch
![TalkNet: Audio-visual active speaker detection Model]()
TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
neural network based speaker embedder
Content What is deepaudio-speaker? Installation Get Started Model Architecture How to contribute to deepaudio-speaker? Acknowledge What is deepaudio-s
Look Who’s Talking: Active Speaker Detection in the Wild
Look Who's Talking: Active Speaker Detection in the Wild Dependencies pip install -r requirements.txt
In addition to the Python dependencies, ffmpeg
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
![Demo for the paper]()
Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
![Demo for the paper]()
Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
Original implementation of the pooling method introduced in "Speaker embeddings by modeling channel-wise correlations"
Speaker-Embeddings-Correlation-Pooling This is the original implementation of the pooling method introduced in "Speaker embeddings by modeling channel
![SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification]()
SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
Unofficial reimplementation of ECAPA-TDNN for speaker recognition (EER=0.86 for Vox1_O when train only in Vox2)
Introduction This repository contains my unofficial reimplementation of the standard ECAPA-TDNN, which is the speaker recognition in VoxCeleb2 dataset

 287 Jan 4, 2023
287 Jan 4, 2023
 492 Dec 28, 2022
492 Dec 28, 2022
 92 Dec 9, 2022
92 Dec 9, 2022
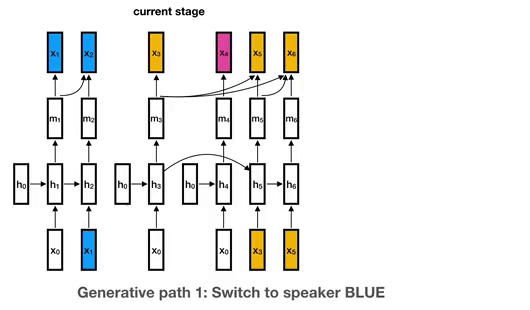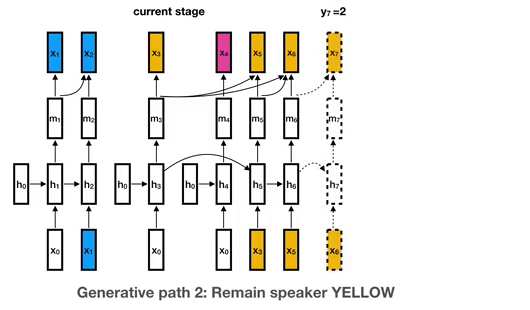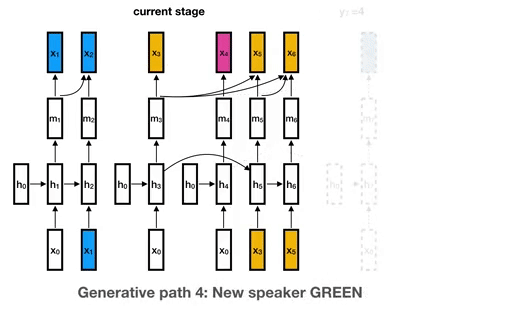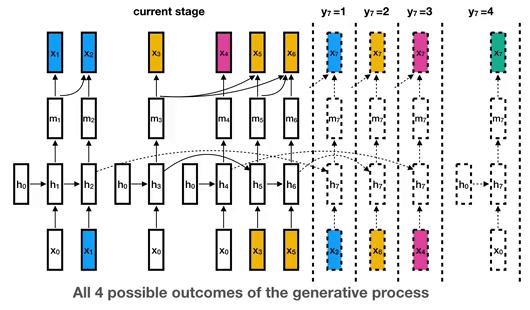
 1.4k Dec 28, 2022
1.4k Dec 28, 2022

 43 Nov 27, 2022
43 Nov 27, 2022

 142 Jan 6, 2023
142 Jan 6, 2023
 38.5k Jan 3, 2023
38.5k Jan 3, 2023
 19 Dec 1, 2022
19 Dec 1, 2022

 142 Dec 14, 2022
142 Dec 14, 2022
 20 Dec 29, 2022
20 Dec 29, 2022
 60 Dec 8, 2022
60 Dec 8, 2022
 24 Sep 7, 2022
24 Sep 7, 2022

 185 Jan 1, 2023
185 Jan 1, 2023
 10 Apr 30, 2022
10 Apr 30, 2022

 24 May 20, 2022
24 May 20, 2022

 19 Dec 1, 2022
19 Dec 1, 2022
 5.1k Jan 2, 2023
5.1k Jan 2, 2023
 231 Dec 26, 2022
231 Dec 26, 2022
 215 Nov 16, 2022
215 Nov 16, 2022
 310 Jan 1, 2023
310 Jan 1, 2023
 2.1k Dec 31, 2022
2.1k Dec 31, 2022
 146 Nov 29, 2022
146 Nov 29, 2022
 97 Dec 23, 2022
97 Dec 23, 2022