[ICML 2021] DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
![]()
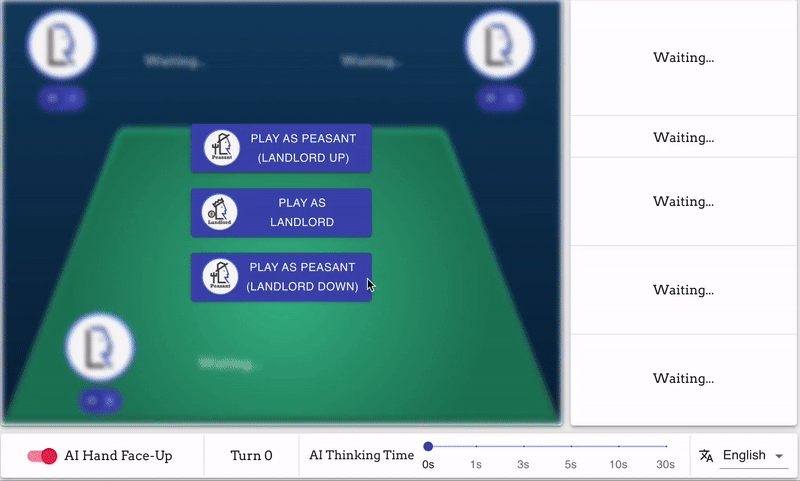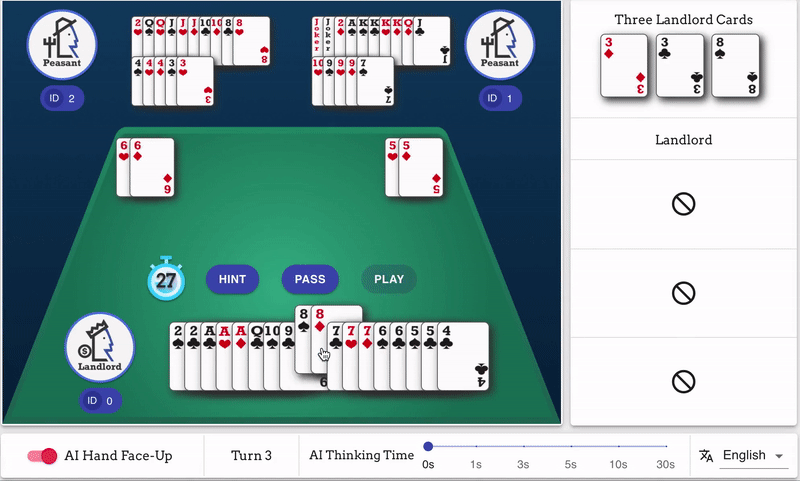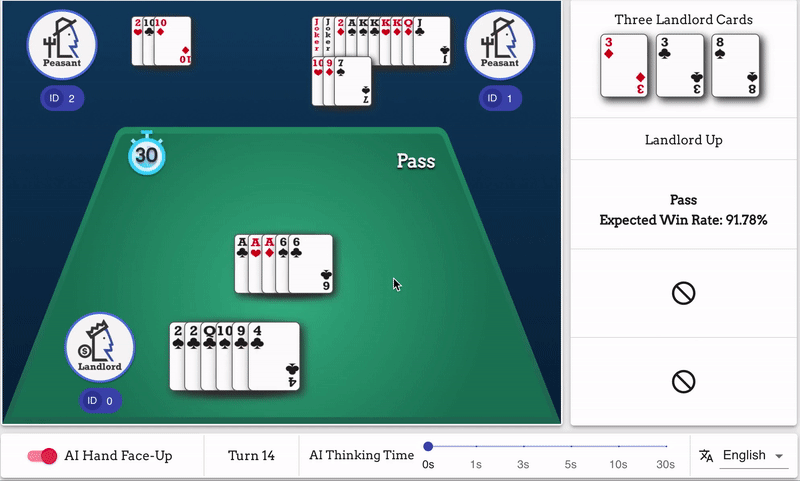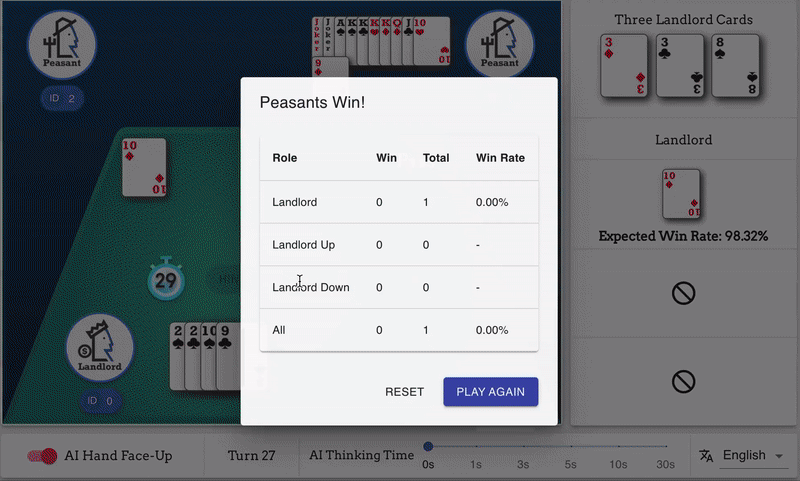
DouZero is a reinforcement learning framework for DouDizhu (斗地主), the most popular card game in China. It is a shedding-type game where the player’s objective is to empty one’s hand of all cards before other players. DouDizhu is a very challenging domain with competition, collaboration, imperfect information, large state space, and particularly a massive set of possible actions where the legal actions vary significantly from turn to turn. DouZero is developed by AI Platform, Kwai Inc. (快手).
- Online Demo: https://www.douzero.org/
-
📢 New Version with Bid(叫牌版本): https://www.douzero.org/bid
-
- Run the Demo Locally: https://github.com/datamllab/rlcard-showdown
- Paper: https://arxiv.org/abs/2106.06135
- Related Project: RLCard Project
- Related Resources: Awesome-Game-AI
- Google Colab: jupyter notebook
Community:
- Slack: Discuss in DouZero channel.
- QQ Group: Join our QQ group 819204202. Password: douzeroqqgroup
Cite this Work
For now, please cite our Arxiv version:
Zha, Daochen, et al. "DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning." arXiv preprint arXiv:2106.06135 (2021).
@article{zha2021douzero,
title={DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning},
author={Zha, Daochen and Xie, Jingru and Ma, Wenye and Zhang, Sheng and Lian, Xiangru and Hu, Xia and Liu, Ji},
journal={arXiv preprint arXiv:2106.06135},
year={2021}
}
What Makes DouDizhu Challenging?
In addition to the challenge of imperfect information, DouDizhu has huge state and action spaces. In particular, the action space of DouDizhu is 10^4 (see this table). Unfortunately, most reinforcement learning algorithms can only handle very small action spaces. Moreover, the players in DouDizhu need to both compete and cooperate with others in a partially-observable environment with limited communication, i.e., two Peasants players will play as a team to fight against the Landlord player. Modeling both competing and cooperation is an open research challenge.
In this work, we propose Deep Monte Carlo (DMC) algorithm with action encoding and parallel actors. This leads to a very simple yet surprisingly effective solution for DouDizhu. Please read our paper for more details.
Installation
The training code is designed for GPUs. Thus, you need to first install CUDA if you want to train models. You may refer to this guide. For evaluation, CUDA is optional and you can use CPU for evaluation.
First, clone the repo with
git clone https://github.com/kwai/DouZero.git
Make sure you have python 3.6+ installed. Install dependencies:
cd douzero
pip3 install -r requirements.txt
We recommend installing the stable version of DouZero with
pip3 install douzero
or install the up-to-date version (it could be not stable) with
pip3 install -e .
Training
We assume you have at least one GPU available. Run
python3 train.py
This will train DouZero on one GPU. To train DouZero on multiple GPUs. Use the following arguments.
--gpu_devices: what gpu devices are visible--num_actors_devices: how many of the GPU deveices will be used for simulation, i.e., self-play--num_actors: how many actor processes will be used for each device--training_device: which device will be used for training DouZero
For example, if we have 4 GPUs, where we want to use the first 3 GPUs to have 15 actors each for simulating and the 4th GPU for training, we can run the following command:
python3 train.py --gpu_devices 0,1,2,3 --num_actors_devices 3 --num_actors 15 --training_device 3
Known issues for Windows system: You may encounter operation not supported error if you use a Windows system. This is because doing multiprocessing on CUDA tensors is not supported in Windows. However, our code extensively operates on the CUDA tensors since the code is optimized for GPUs. Thus, we recommend using a Linux server to train the models. Nonetheless, Windows users can still evaluate the models with multiple processes and run the demo locally. Please contact us if you find any solutions!
For more customized configuration of training, see the following optional arguments:
--xpid XPID Experiment id (default: douzero)
--save_interval SAVE_INTERVAL
Time interval (in minutes) at which to save the model
--objective {adp,wp} Use ADP or WP as reward (default: ADP)
--gpu_devices GPU_DEVICES
Which GPUs to be used for training
--num_actor_devices NUM_ACTOR_DEVICES
The number of devices used for simulation
--num_actors NUM_ACTORS
The number of actors for each simulation device
--training_device TRAINING_DEVICE
The index of the GPU used for training models
--load_model Load an existing model
--disable_checkpoint Disable saving checkpoint
--savedir SAVEDIR Root dir where experiment data will be saved
--total_frames TOTAL_FRAMES
Total environment frames to train for
--exp_epsilon EXP_EPSILON
The probability for exploration
--batch_size BATCH_SIZE
Learner batch size
--unroll_length UNROLL_LENGTH
The unroll length (time dimension)
--num_buffers NUM_BUFFERS
Number of shared-memory buffers
--num_threads NUM_THREADS
Number learner threads
--max_grad_norm MAX_GRAD_NORM
Max norm of gradients
--learning_rate LEARNING_RATE
Learning rate
--alpha ALPHA RMSProp smoothing constant
--momentum MOMENTUM RMSProp momentum
--epsilon EPSILON RMSProp epsilon
Evaluation
The evaluation can be performed with GPU or CPU (GPU will be much faster). Pretrained model is available at Google Drive or 百度网盘, 提取码: 4624. Put pre-trained weights in baselines/. The performance is evaluated through self-play. We have provided pre-trained models and some heuristics as baselines:
- random: agents that play randomly (uniformly)
- rlcard: the rule-based agent in RLCard
- SL (
baselines/sl/): the pre-trained deep agents on human data - DouZero-ADP (
baselines/douzero_ADP/): the pretrained DouZero agents with Average Difference Points (ADP) as objective - DouZero-WP (
baselines/douzero_WP/): the pretrained DouZero agents with Winning Percentage (WP) as objective
Step 1: Generate evaluation data
python3 generate_eval_data.py
Some important hyperparameters are as follows.
--output: where the pickled data will be saved--num_games: how many random games will be generated, default 10000
Step 2: Self-Play
python3 evaluate.py
Some important hyperparameters are as follows.
--landlord: which agent will play as Landlord, which can be random, rlcard, or the path of the pre-trained model--landlord_up: which agent will play as LandlordUp (the one plays before the Landlord), which can be random, rlcard, or the path of the pre-trained model--landlord_down: which agent will play as LandlordDown (the one plays after the Landlord), which can be random, rlcard, or the path of the pre-trained model--eval_data: the pickle file that contains evaluation data
For example, the following command evaluates DouZero-ADP in Landlord position against random agents
python3 evaluate.py --landlord baselines/douzero_ADP/landlord.ckpt --landlord_up random --landlord_down random
The following command evaluates DouZero-ADP in Peasants position against RLCard agents
python3 evaluate.py --landlord rlcard --landlord_up baselines/douzero_ADP/landlord_up.ckpt --landlord_down baselines/douzero_ADP/landlord_down.ckpt
By default, our model will be saved in douzero_checkpoints/douzero every half an hour. We provide a script to help you identify the most recent checkpoint. Run
sh get_most_recent.sh douzero_checkpoints/douzero/
The most recent model will be in most_recent_model.
Core Team
- Algorithm: Daochen Zha, Jingru Xie, Wenye Ma, Sheng Zhang, Xiangru Lian, Xia Hu, Ji Liu
- GUI Demo: Songyi Huang
Acknowlegements
- The demo is largely based on RLCard-Showdown
- Code implementation is inspired by TorchBeast













 120 Jan 5, 2023
120 Jan 5, 2023
 2.6k Dec 31, 2022
2.6k Dec 31, 2022
 343 Dec 24, 2022
343 Dec 24, 2022
 67 Dec 29, 2022
67 Dec 29, 2022
 20 Jan 6, 2023
20 Jan 6, 2023
 13.2k Jan 2, 2023
13.2k Jan 2, 2023
 4.8k Jan 4, 2023
4.8k Jan 4, 2023
 128 Sep 12, 2022
128 Sep 12, 2022
 2.1k Dec 23, 2022
2.1k Dec 23, 2022
 186 Dec 29, 2022
186 Dec 29, 2022
 71 Dec 6, 2022
71 Dec 6, 2022
 99 Dec 12, 2022
99 Dec 12, 2022
 422 Jan 3, 2023
422 Jan 3, 2023
 243 Dec 30, 2022
243 Dec 30, 2022
 101 Dec 12, 2022
101 Dec 12, 2022
 1.9k Jan 8, 2023
1.9k Jan 8, 2023
 2.4k Jan 8, 2023
2.4k Jan 8, 2023
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
 3.2k Jan 4, 2023
3.2k Jan 4, 2023