Hi there!
We're using Rosetta 0.9.4 on Django 2.2.17, and all is good. Apart from skepticism of professional translators, of course. The main theme is, "The tool doesn't provide a TM, hence we can't use it."
I need some help to understand this topic better.
Note that my wife is a professional translator and project manager in the translation industry, so I am informed largely about the concepts of "traditional translation" of documents (e.g. SDL Trados, Across, OmegaT) but also about the approach emerged from the software development industry (e.g. Transifex, Crowdin), which I have hands-on experience with.
Where is Rosetta's TM?
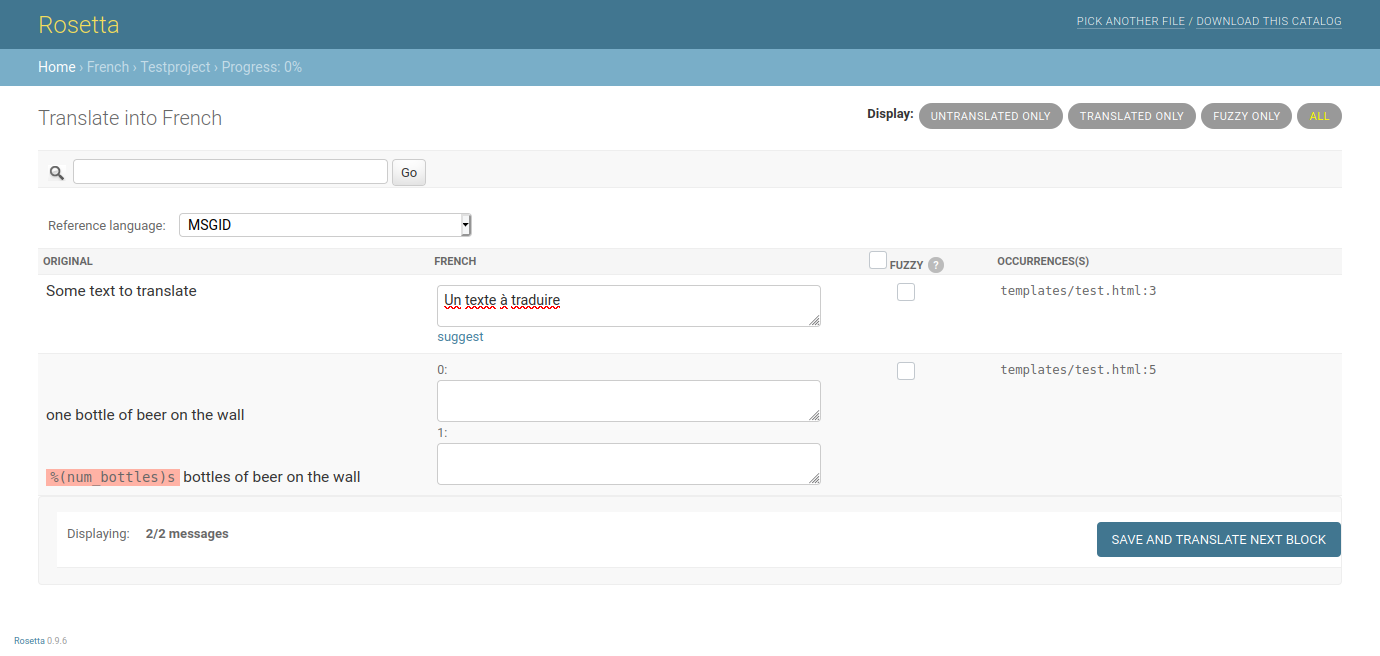
From my understanding, Rosetta is more or less a nice front-end to manipulate .po files, extracted by Python's gettext module integrated in Django. There are no models, yet still Rosetta does "automatic translation", which is visible by fuzzy matches (which I assume is also a feature coming from gettext again, really).
So in essence, the .po files themselves are that TM already. There is no additional or separate component, but as the entire "document" is identical to all (successful) translations that have been done in the past, there is not even a need for a separate TM. It's all read into "Rosetta's memory" in its entirety. There is no disadvantage of having "no TM", given we only deal with our domain specific vocabulary.
Is this view correct?
External TMs?
A related question, after having clarified whether Rosetta has a TM or no, is there a way to
- download Rosetta's TM and/or
- attach (or upload) an external TM
to add, say, more flexibility to the translation process?





















 703 Dec 22, 2022
703 Dec 22, 2022
 167 Nov 10, 2022
167 Nov 10, 2022
 23 Sep 16, 2021
23 Sep 16, 2021
 10k Dec 31, 2022
10k Dec 31, 2022
 51 Sep 15, 2022
51 Sep 15, 2022
 4 Nov 18, 2021
4 Nov 18, 2021
 2.1k Dec 24, 2022
2.1k Dec 24, 2022
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
 3 Dec 11, 2022
3 Dec 11, 2022
 1.6k Jan 6, 2023
1.6k Jan 6, 2023
 1.1k Jan 1, 2023
1.1k Jan 1, 2023
 1.1k Dec 31, 2022
1.1k Dec 31, 2022
 1 Mar 1, 2022
1 Mar 1, 2022
 6 Dec 31, 2021
6 Dec 31, 2021
 384 Nov 23, 2022
384 Nov 23, 2022
 59 Dec 21, 2022
59 Dec 21, 2022
 1.1k Dec 14, 2022
1.1k Dec 14, 2022
 1 Dec 9, 2021
1 Dec 9, 2021
 2.6k Dec 26, 2022
2.6k Dec 26, 2022