Synapse Machine Learning



SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. SynapseML builds on Apache Spark and SparkML to enable new kinds of machine learning, analytics, and model deployment workflows. SynapseML adds many deep learning and data science tools to the Spark ecosystem, including seamless integration of Spark Machine Learning pipelines with the Open Neural Network Exchange (ONNX), LightGBM, The Cognitive Services, Vowpal Wabbit, and OpenCV. These tools enable powerful and highly-scalable predictive and analytical models for a variety of datasources.
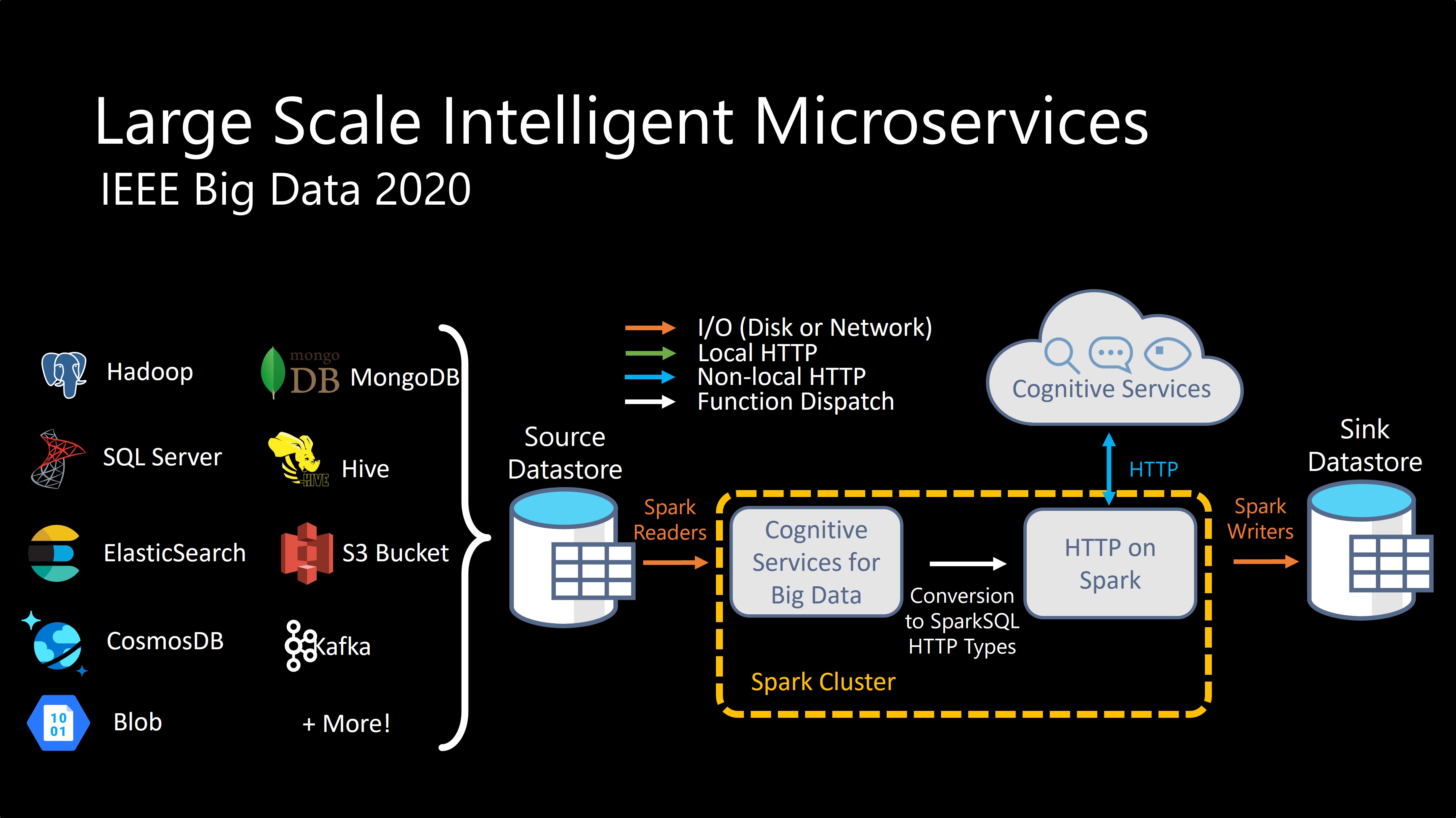
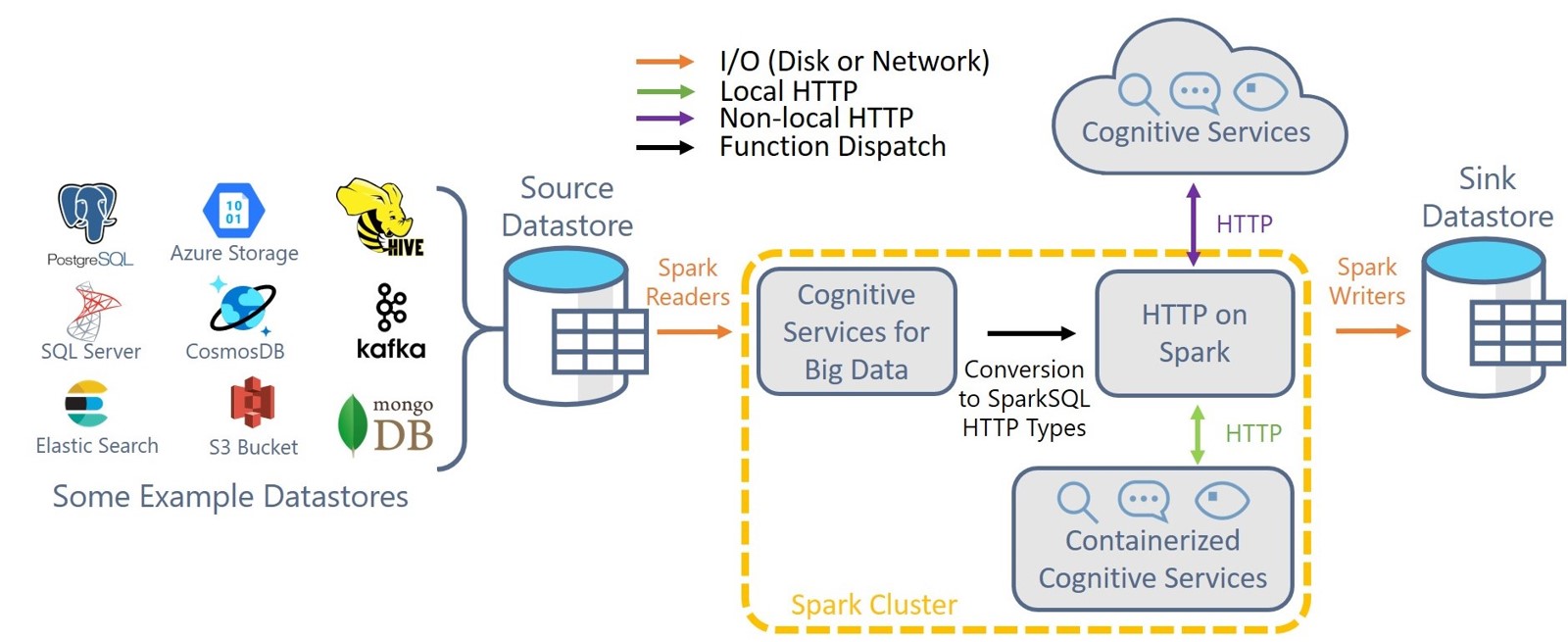
SynapseML also brings new networking capabilities to the Spark Ecosystem. With the HTTP on Spark project, users can embed any web service into their SparkML models. For production grade deployment, the Spark Serving project enables high throughput, sub-millisecond latency web services, backed by your Spark cluster.
SynapseML requires Scala 2.12, Spark 3.2+, and Python 3.6+. See the API documentation for Scala and for PySpark.
Table of Contents
Features
 |
 |
 |
 |
|---|---|---|---|
| Vowpal Wabbit on Spark | The Cognitive Services for Big Data | LightGBM on Spark | Spark Serving |
| Fast, Sparse, and Effective Text Analytics | Leverage the Microsoft Cognitive Services at Unprecedented Scales in your existing SparkML pipelines | Train Gradient Boosted Machines with LightGBM | Serve any Spark Computation as a Web Service with Sub-Millisecond Latency |
 |
 |
 |
 |
|---|---|---|---|
| HTTP on Spark | ONNX on Spark | Responsible AI | Spark Binding Autogeneration |
| An Integration Between Spark and the HTTP Protocol, enabling Distributed Microservice Orchestration | Distributed and Hardware Accelerated Model Inference on Spark | Understand Opaque-box Models and Measure Dataset Biases | Automatically Generate Spark bindings for PySpark and SparklyR |
 |
 |
 |
|---|---|---|
| Isolation Forest on Spark | CyberML | Conditional KNN |
| Distributed Nonlinear Outlier Detection | Machine Learning Tools for Cyber Security | Scalable KNN Models with Conditional Queries |
Documentation and Examples
For quickstarts, documentation, demos, and examples please see our website.
Setup and installation
Python
To try out SynapseML on a Python (or Conda) installation you can get Spark installed via pip with pip install pyspark. You can then use pyspark as in the above example, or from python:
import pyspark
spark = pyspark.sql.SparkSession.builder.appName("MyApp") \
.config("spark.jars.packages", "com.microsoft.azure:synapseml_2.12:0.9.5") \
.getOrCreate()
import synapse.ml
SBT
If you are building a Spark application in Scala, add the following lines to your build.sbt:
libraryDependencies += "com.microsoft.azure" % "synapseml_2.12" % "0.9.5"
Spark package
SynapseML can be conveniently installed on existing Spark clusters via the --packages option, examples:
spark-shell --packages com.microsoft.azure:synapseml_2.12:0.9.5
pyspark --packages com.microsoft.azure:synapseml_2.12:0.9.5
spark-submit --packages com.microsoft.azure:synapseml_2.12:0.9.5 MyApp.jar
This can be used in other Spark contexts too. For example, you can use SynapseML in AZTK by adding it to the .aztk/spark-defaults.conf file.
Databricks
To install SynapseML on the Databricks cloud, create a new library from Maven coordinates in your workspace.
For the coordinates use: com.microsoft.azure:synapseml_2.12:0.9.5 with the resolver: https://mmlspark.azureedge.net/maven. Ensure this library is attached to your target cluster(s).
Finally, ensure that your Spark cluster has at least Spark 3.2 and Scala 2.12. If you encounter Netty dependency issues please use DBR 10.1.
You can use SynapseML in both your Scala and PySpark notebooks. To get started with our example notebooks import the following databricks archive:
https://mmlspark.blob.core.windows.net/dbcs/SynapseMLExamplesv0.9.5.dbc
Apache Livy and HDInsight
To install SynapseML from within a Jupyter notebook served by Apache Livy the following configure magic can be used. You will need to start a new session after this configure cell is executed.
Excluding certain packages from the library may be necessary due to current issues with Livy 0.5
%%configure -f
{
"name": "synapseml",
"conf": {
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.9.5",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12"
}
}
In Azure Synapse, "spark.yarn.user.classpath.first" should be set to "true" to override the existing SynapseML packages
%%configure -f
{
"name": "synapseml",
"conf": {
"spark.jars.packages": "com.microsoft.azure:synapseml_2.12:0.9.5",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.12,org.scalactic:scalactic_2.12,org.scalatest:scalatest_2.12",
"spark.yarn.user.classpath.first": "true"
}
}
Docker
The easiest way to evaluate SynapseML is via our pre-built Docker container. To do so, run the following command:
docker run -it -p 8888:8888 -e ACCEPT_EULA=yes mcr.microsoft.com/mmlspark/release
Navigate to http://localhost:8888/ in your web browser to run the sample notebooks. See the documentation for more on Docker use.
To read the EULA for using the docker image, run \
docker run -it -p 8888:8888 mcr.microsoft.com/mmlspark/release eula
GPU VM Setup
SynapseML can be used to train deep learning models on GPU nodes from a Spark application. See the instructions for setting up an Azure GPU VM.
Building from source
SynapseML has recently transitioned to a new build infrastructure. For detailed developer docs please see the Developer Readme
If you are an existing synapsemldeveloper, you will need to reconfigure your development setup. We now support platform independent development and better integrate with intellij and SBT. If you encounter issues please reach out to our support email!
R (Beta)
To try out SynapseML using the R autogenerated wrappers see our instructions. Note: This feature is still under development and some necessary custom wrappers may be missing.
Papers
Learn More
-
Visit our website.
-
Watch our keynote demos at the Spark+AI Summit 2019, the Spark+AI European Summit 2018, and the Spark+AI Summit 2018.
-
See how SynapseML is used to help endangered species.
-
Explore generative adversarial artwork in our collaboration with The MET and MIT.
-
Explore our collaboration with Apache Spark on image analysis.
Contributing & feedback
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact [email protected] with any additional questions or comments.
See CONTRIBUTING.md for contribution guidelines.
To give feedback and/or report an issue, open a GitHub Issue.
Other relevant projects
Apache®, Apache Spark, and Spark® are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.













![[BUG]java.lang.Exception: Network init call failed in LightGBM with error: Binding port 12412 failed](https://avatars.githubusercontent.com/u/25664170?v=4)

 |
|:--:|:--:|:--:|:--:|
|OpenAI Language Models | .NET, C#, and F# Support | Full MLFlow Support | Live Demos in Browser |
| Embed 175-billion parameter models into your databases with ease | Use or train any SynapseML model from .NET | Quick and easy MLOps, model management, and autologging | Explore the SynapseML library with zero setup |
|
|
|:--:|:--:|:--:|:--:|
|OpenAI Language Models | .NET, C#, and F# Support | Full MLFlow Support | Live Demos in Browser |
| Embed 175-billion parameter models into your databases with ease | Use or train any SynapseML model from .NET | Quick and easy MLOps, model management, and autologging | Explore the SynapseML library with zero setup |
|  |
| |
|  |
|:--:|:--:|:--:|
| Serena Ruan | Ric Serradas | Puneet Pruthi |
| Serena is a Software Engineer II on the Synapse team in Beijing and a force of nature. In this release, Serena has continued her prolific contribution steak by adding language support for .NET, C#, and F# and integrating SynapseML with MLFlow. Additionally, Serena has contributed several features to the MLFlow and Spark.NET open-source communities so that these systems can work better for every user. These contributions are just some of the many amazing things Serena has accomplished during this release, and her devotion and craft are pivotal to the ecosystem. | Ric is a Senior Engineering Manager on the OneNote team with a shining personality and drive to collaborate. In just a few weeks Ric hit the ground running by setting up an automated link between GitHub and Azure DevOps, building the first working version of SynapseE2E tests, and re-writing our entire build in GH Actions. Furthermore, Ric worked tirelessly through nights and weekends to land his contributions. | Puneet is a Senior Engineer on the SynapseML team with a knack for engineering systems and dockerization. Puneet's contributions to the library include architecting the new binder integration, driving our Synapse E2E tests to completion, and improving SynapseML’ s infrastructure around community engagement. Puneet is constantly thinking of ways to improve the community and we value his effort. |
|
|
|:--:|:--:|:--:|
| Serena Ruan | Ric Serradas | Puneet Pruthi |
| Serena is a Software Engineer II on the Synapse team in Beijing and a force of nature. In this release, Serena has continued her prolific contribution steak by adding language support for .NET, C#, and F# and integrating SynapseML with MLFlow. Additionally, Serena has contributed several features to the MLFlow and Spark.NET open-source communities so that these systems can work better for every user. These contributions are just some of the many amazing things Serena has accomplished during this release, and her devotion and craft are pivotal to the ecosystem. | Ric is a Senior Engineering Manager on the OneNote team with a shining personality and drive to collaborate. In just a few weeks Ric hit the ground running by setting up an automated link between GitHub and Azure DevOps, building the first working version of SynapseE2E tests, and re-writing our entire build in GH Actions. Furthermore, Ric worked tirelessly through nights and weekends to land his contributions. | Puneet is a Senior Engineer on the SynapseML team with a knack for engineering systems and dockerization. Puneet's contributions to the library include architecting the new binder integration, driving our Synapse E2E tests to completion, and improving SynapseML’ s infrastructure around community engagement. Puneet is constantly thinking of ways to improve the community and we value his effort. |
|  |
| |
|  |
| Mark Niehaus | Keerthi Yanda | Yagna Oruganti |
| Mark is a Senior Software Engineer on the SynapseML team with a deep knowledge of the .NET ecosystem and infrastructure development. In this release, Mark architected SynapseML’ s .NET binding blob publishing strategy, drove the OpenAI GPT-3 bindings to completion, and wrote
|
| Mark Niehaus | Keerthi Yanda | Yagna Oruganti |
| Mark is a Senior Software Engineer on the SynapseML team with a deep knowledge of the .NET ecosystem and infrastructure development. In this release, Mark architected SynapseML’ s .NET binding blob publishing strategy, drove the OpenAI GPT-3 bindings to completion, and wrote 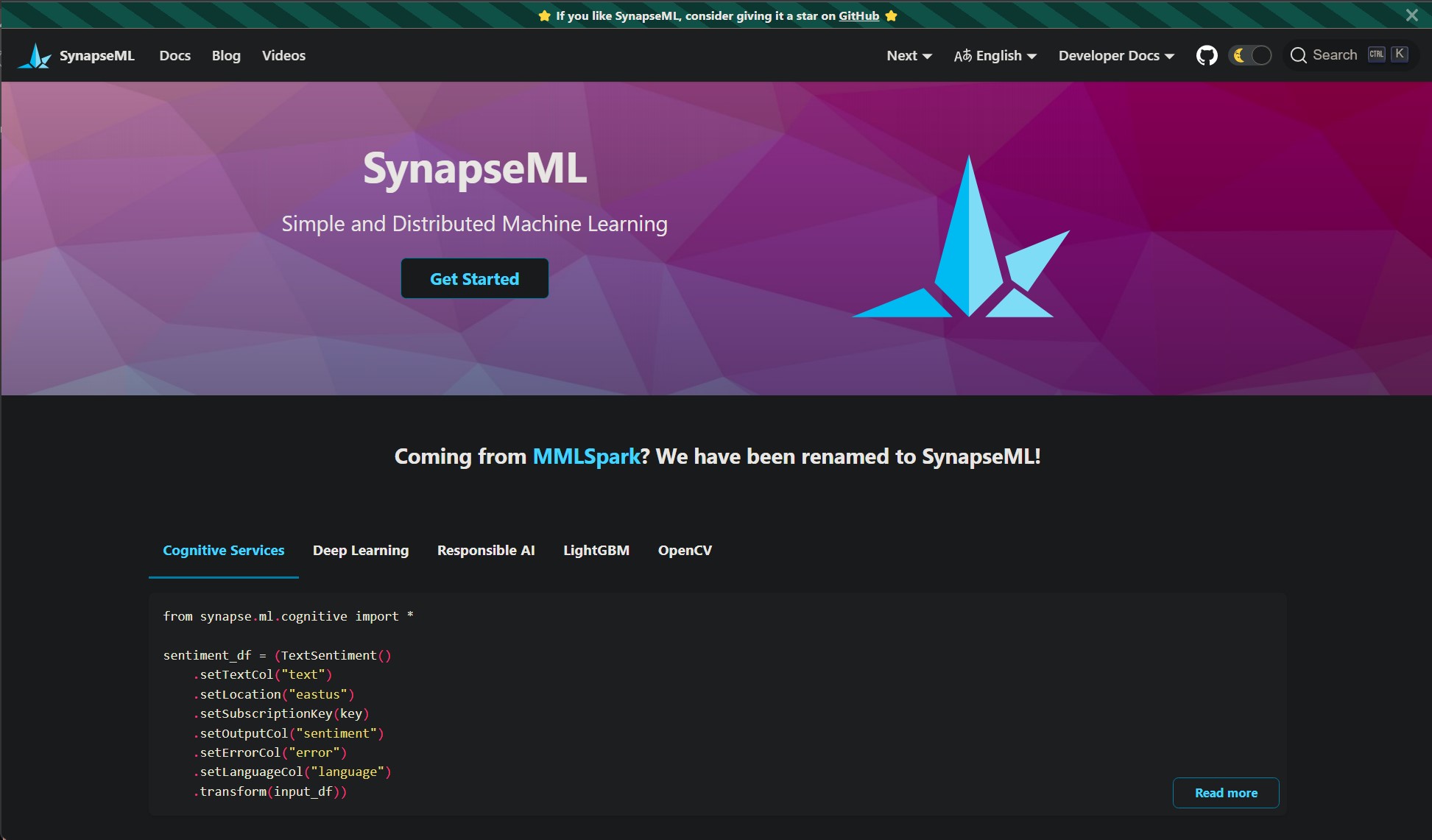 |
| |
|  |
|:--:|:--:|:--:|
| Visit
|
|:--:|:--:|:--:|
| Visit  |
| |
|  |
| Watch
|
| Watch  |
| |
|  |
|  |
|:--:|:--:|:--:|:--:|:--:|
| Geospatial Intelligence |Multivariate Anomaly Detection | Responsible AI at Scale | Text To Speech | Healthcare Analytics |
| Large-scale map and geocoding operations | Build custom time series anomaly detection systems | Distributed Conditional Expectation and Partial Dependence Analysis | East-to-use Neural Text to Speech for large datasets | Quickly understand entities and relationships in corpora of medical text. |
|
|:--:|:--:|:--:|:--:|:--:|
| Geospatial Intelligence |Multivariate Anomaly Detection | Responsible AI at Scale | Text To Speech | Healthcare Analytics |
| Large-scale map and geocoding operations | Build custom time series anomaly detection systems | Distributed Conditional Expectation and Partial Dependence Analysis | East-to-use Neural Text to Speech for large datasets | Quickly understand entities and relationships in corpora of medical text. | |
|.jpg) |
|  |
|:--:|:--:|:--:|
| Serena Ruan | Ilya Matiach | Sudhindra Kovalam |
| Serena is an engineer on the Azure Synapse team in Beijing. In this release, Serena has continued her unbelievable speed of contributions with support for Multivariate Anomaly Detection, MLFlow, and installation from Maven Central. These contributions are just a few of the many projects Serena has contributed since she joined just a few months ago! | Ilya is a prolific engineer on the Azure Machine Learning Boston team working on responsible AI. Ilya contributed LightGBM on Spark and worked tirelessly to improve and support this feature. Ilya has been an active contributor to the SynapseML project for 5 years and has built many of the tools in the library. | Sudhindra is an engineer on the Microsoft Maps team and has contributed intelligent geospatial APIs to SynapseML v0.9.5. Sudhindra developed new ways to automate generation of Spark code from swagger files allowing him to contribute a large suite of features rapidly. |
|
|
|:--:|:--:|:--:|
| Serena Ruan | Ilya Matiach | Sudhindra Kovalam |
| Serena is an engineer on the Azure Synapse team in Beijing. In this release, Serena has continued her unbelievable speed of contributions with support for Multivariate Anomaly Detection, MLFlow, and installation from Maven Central. These contributions are just a few of the many projects Serena has contributed since she joined just a few months ago! | Ilya is a prolific engineer on the Azure Machine Learning Boston team working on responsible AI. Ilya contributed LightGBM on Spark and worked tirelessly to improve and support this feature. Ilya has been an active contributor to the SynapseML project for 5 years and has built many of the tools in the library. | Sudhindra is an engineer on the Microsoft Maps team and has contributed intelligent geospatial APIs to SynapseML v0.9.5. Sudhindra developed new ways to automate generation of Spark code from swagger files allowing him to contribute a large suite of features rapidly. |
|  |
|.png) |
| .jpg) |
| Elena Zherdeva | The Text Analytics Explorer Interns | Stuart Leeks |
| Elena is an engineer on the CSX Data team working on building scalable responsible AI tools. In Elena's first contribution to SynapseML she added Individual Conditional Expectation plots at scale. She also contributed
|
| Elena Zherdeva | The Text Analytics Explorer Interns | Stuart Leeks |
| Elena is an engineer on the CSX Data team working on building scalable responsible AI tools. In Elena's first contribution to SynapseML she added Individual Conditional Expectation plots at scale. She also contributed  |
|:--:|:--:|:--:|
| Visit
|
|:--:|:--:|:--:|
| Visit  |
| |
| Learn more about
|
| Learn more about  |
| |
|:--:|:--:|:--:|:--:|:--:|
| General Availability on Synapse |ONNX on Spark | Responsible AI | Form Recognition and Translation | Reinforcement Learning |
| We are ready to help you productionalize on Azure Synapse Analytics | Distributed and hardware accelerated model inference on Spark | Understand opaque-box models, measure dataset biases, Explainable Boosting Machines | Parse PDFs and translate dataframes between over 100 languages | Contextual Bandit Reinforcement Learning with Vowpal Wabbit |
|
|:--:|:--:|:--:|:--:|:--:|
| General Availability on Synapse |ONNX on Spark | Responsible AI | Form Recognition and Translation | Reinforcement Learning |
| We are ready to help you productionalize on Azure Synapse Analytics | Distributed and hardware accelerated model inference on Spark | Understand opaque-box models, measure dataset biases, Explainable Boosting Machines | Parse PDFs and translate dataframes between over 100 languages | Contextual Bandit Reinforcement Learning with Vowpal Wabbit | |
|  |
|:--:|:--:|:--:|
| Serena Ruan | Jason Wang | Wenqing Xu |
| Serena is an Engineer on the Azure Synapse team in Beijing. Within her first months working on SynapseML, Serena contributed Forms and Translator cognitive services, a unified logging and telemetry system, notebooks and documentation for every transformer and estimator, and a new docusaurus-based website. | Jason is a Principal Engineer on Microsoft's DSP team and is focused on large-scale responsible AI. Jason started his contribution streak with a new API for model explainability that unifies both SHAP and LIME. Jason has also contributed ONNX on Spark which dramatically broadens the scope of models that can be used in SynapseML. | Wenqing is a software engineer on the Azure Synapse team in Beijing. Wenqing has been instrumental in preparing SynapseML for General Availability. In particular, Wenqing added support for linked service authentication of cognitive services, extended E2E testing to Synapse Analytics, and added the PII identification service. |
|
|
|:--:|:--:|:--:|
| Serena Ruan | Jason Wang | Wenqing Xu |
| Serena is an Engineer on the Azure Synapse team in Beijing. Within her first months working on SynapseML, Serena contributed Forms and Translator cognitive services, a unified logging and telemetry system, notebooks and documentation for every transformer and estimator, and a new docusaurus-based website. | Jason is a Principal Engineer on Microsoft's DSP team and is focused on large-scale responsible AI. Jason started his contribution streak with a new API for model explainability that unifies both SHAP and LIME. Jason has also contributed ONNX on Spark which dramatically broadens the scope of models that can be used in SynapseML. | Wenqing is a software engineer on the Azure Synapse team in Beijing. Wenqing has been instrumental in preparing SynapseML for General Availability. In particular, Wenqing added support for linked service authentication of cognitive services, extended E2E testing to Synapse Analytics, and added the PII identification service. |
|  |
| |
|  |
| Kashyap Patel | Rohit Agrawal | Jack Gerrits |
| Kashyap is an Engineer on Microsoft's DSP team working on improving the fairness of machine learning models. Kashyap contributed tools for assessing dataset bias without requiring a labelled dataset or model. | Rohit is a Senior Engineer on Microsoft's Cognitive Service team working on large-scale orchestration of intelligent services. Rohit modernized our Text Analytics Stack by updating to v3.0 and laid the groundwork for E2E testing on Synapse Analytics.| Jack is a Senior Engineer on the decision service and reinforcement learning team at Microsoft Research NYC. Jack contributed support for contextual bandit reinforcement learning with Vowpal Wabbit. |
|
| Kashyap Patel | Rohit Agrawal | Jack Gerrits |
| Kashyap is an Engineer on Microsoft's DSP team working on improving the fairness of machine learning models. Kashyap contributed tools for assessing dataset bias without requiring a labelled dataset or model. | Rohit is a Senior Engineer on Microsoft's Cognitive Service team working on large-scale orchestration of intelligent services. Rohit modernized our Text Analytics Stack by updating to v3.0 and laid the groundwork for E2E testing on Synapse Analytics.| Jack is a Senior Engineer on the decision service and reinforcement learning team at Microsoft Research NYC. Jack contributed support for contextual bandit reinforcement learning with Vowpal Wabbit. |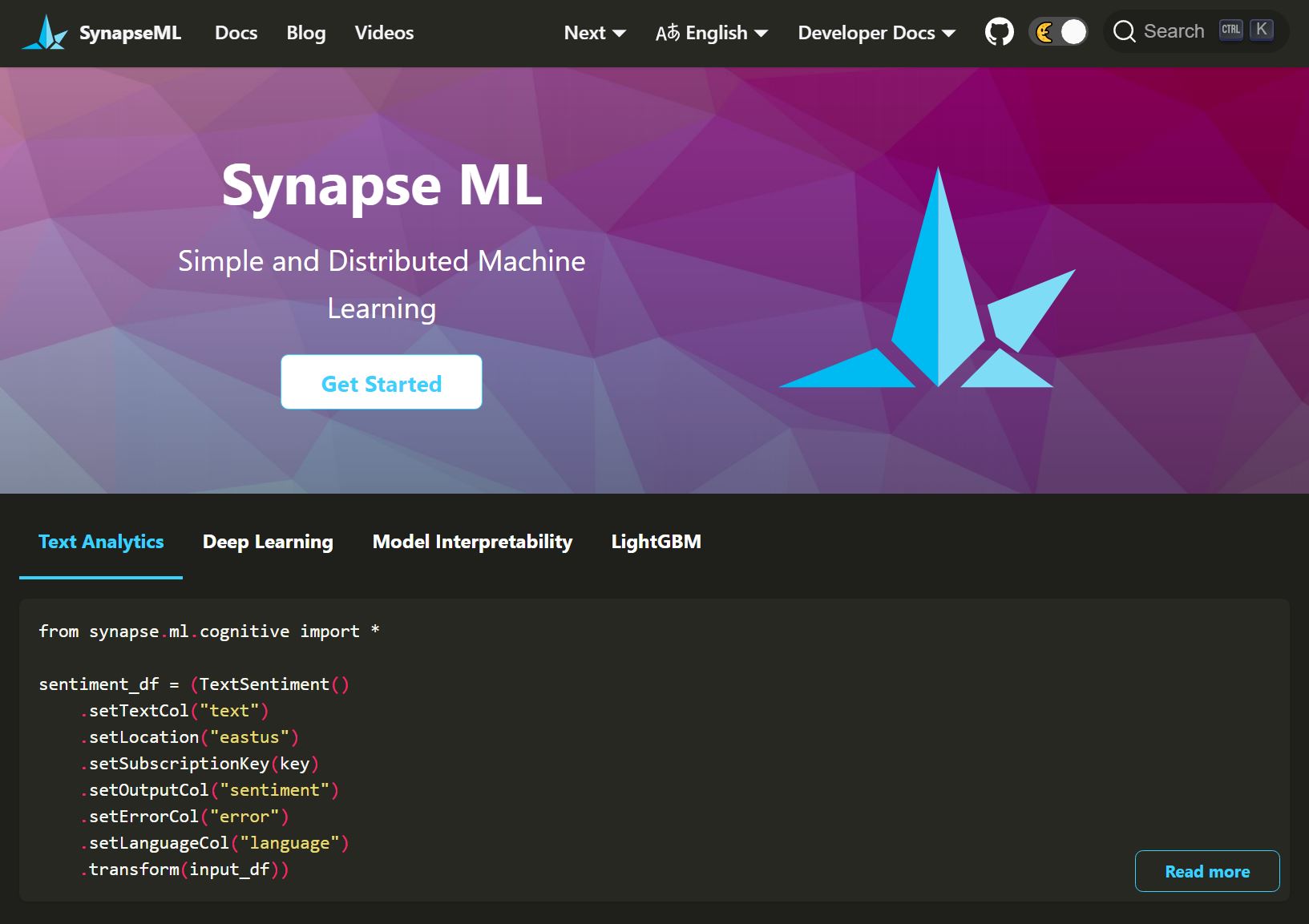 |
| |
| |
|  |
| Read the Synapse Analytics
|
| Read the Synapse Analytics 
 |
|  |
|:--:|:--:|:--:|:--:|:--:|
| Isolation Forest on Spark | CyberML | Speech To Text | Conditional KNN | LightGBM + SHAP |
| Distributed Nonlinear Outlier Detection | Machine Learning Tools for Cyber Security | Custom Speech to Text with Streaming Support | Scalable KNN Models with Conditional Queries | Interpret LightGBM Models using Additive Shapley Explanations |
|
|:--:|:--:|:--:|:--:|:--:|
| Isolation Forest on Spark | CyberML | Speech To Text | Conditional KNN | LightGBM + SHAP |
| Distributed Nonlinear Outlier Detection | Machine Learning Tools for Cyber Security | Custom Speech to Text with Streaming Support | Scalable KNN Models with Conditional Queries | Interpret LightGBM Models using Additive Shapley Explanations | |
| |
|  |
|:--:|:--:|:--:|
| MosAIc Finds Hidden Connections in World Art (
|
|:--:|:--:|:--:|
| MosAIc Finds Hidden Connections in World Art ( |
|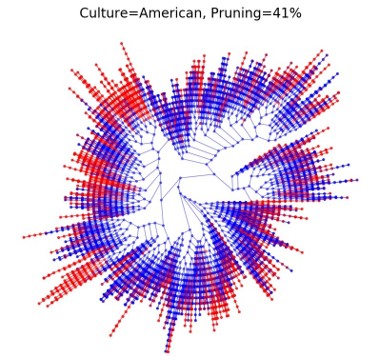 |
| 
 |
| 
 |
| 
 175 Jan 8, 2023
175 Jan 8, 2023
 25 Sep 15, 2022
25 Sep 15, 2022
 216 Dec 23, 2022
216 Dec 23, 2022
 2.6k Jan 8, 2023
2.6k Jan 8, 2023
 4.2k Jan 1, 2023
4.2k Jan 1, 2023
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
 26 Nov 6, 2022
26 Nov 6, 2022
 1.8k Jan 1, 2023
1.8k Jan 1, 2023
 23.6k Jan 3, 2023
23.6k Jan 3, 2023
 3k Jan 8, 2023
3k Jan 8, 2023
 3.1k Jan 6, 2023
3.1k Jan 6, 2023
 2 Jul 29, 2021
2 Jul 29, 2021
 1.4k Dec 27, 2022
1.4k Dec 27, 2022
 0 Dec 6, 2021
0 Dec 6, 2021
 33 Dec 3, 2022
33 Dec 3, 2022
 1 Apr 26, 2022
1 Apr 26, 2022
 3 Sep 16, 2022
3 Sep 16, 2022
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
 84 Nov 25, 2022
84 Nov 25, 2022