Improving Transformer Models by Reordering their Sublayers
This repository contains the code for running the character-level Sandwich Transformers from our ACL 2020 paper on Improving Transformer Models by Reordering their Sublayers (video presentation here, summary here).
Our character-level model (and this repo) is based on the Adaptive Attention Span for Transformers model. In our paper we showed that by simply reordering that model's self-attention and feedforward sublayers, we could improve performance on the enwik8 benchmark (where we achieve 0.968 BPC on the test set).
The code here simply adds a way to reorder the sublayers of the Adaptive Span model, using the --architecture parameter.
If you use this code or results from our paper, please cite:
@inproceedings{press-etal-2020-improving,
title = "Improving Transformer Models by Reordering their Sublayers",
author = "Press, Ofir and Smith, Noah A. and Levy, Omer",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.270",
doi = "10.18653/v1/2020.acl-main.270",
pages = "2996--3005",
}
Requirements
You need CUDA 10 and PyTorch 1.2.0 to run this code. See this page for installation instructions. To replicate our experimental conditions eight V100 GPUs are needed.
Running experiments in the paper
The scripts for training the character-level models from the paper are located in the ./experiments/ directory. For example, to train the enwik8 model, run:
bash experiments/enwik8_large.sh
We used eight V100 GPUs, but if you'd like to run this model on GPUs with less memory you can increase the --batch-split (it splits batches into smaller pieces without changing the final result).
We obtained the following results in our experiments:
| Experiment | #params | valid (bpc) | test (bpc) |
|---|---|---|---|
| enwik8 Sandwich Transformer | 209M | 0.992 | 0.968 |
| text8 Sandwich Transformer | 209M | 1.012 | 1.076 |
The --architecture parameter
A standard transformer with 3 layers (so 6 self-attention and feedforward sublayers) would use be trained using --architecture sfsfsf. That 6 sublayer model with a sandwiching coefficient of 1 would be --architecture s.sfsf.f and with a sandwiching coefficient of 2 would be --architecture s.s.sf.f.f. Make sure to also set the --nlayers parameter to be the length of the architecture string divided by 2.
License
The code is licensed under CC-BY-NC license. See the LICENSE file for more details.
Acknowledgements + More Information
This code is based on the code of the Adaptive Span model. We recommend reading the Adaptive Span README for further information on this codebase.
 4 Mar 20, 2022
4 Mar 20, 2022
 154 Jan 1, 2023
154 Jan 1, 2023

 90 Dec 27, 2022
90 Dec 27, 2022
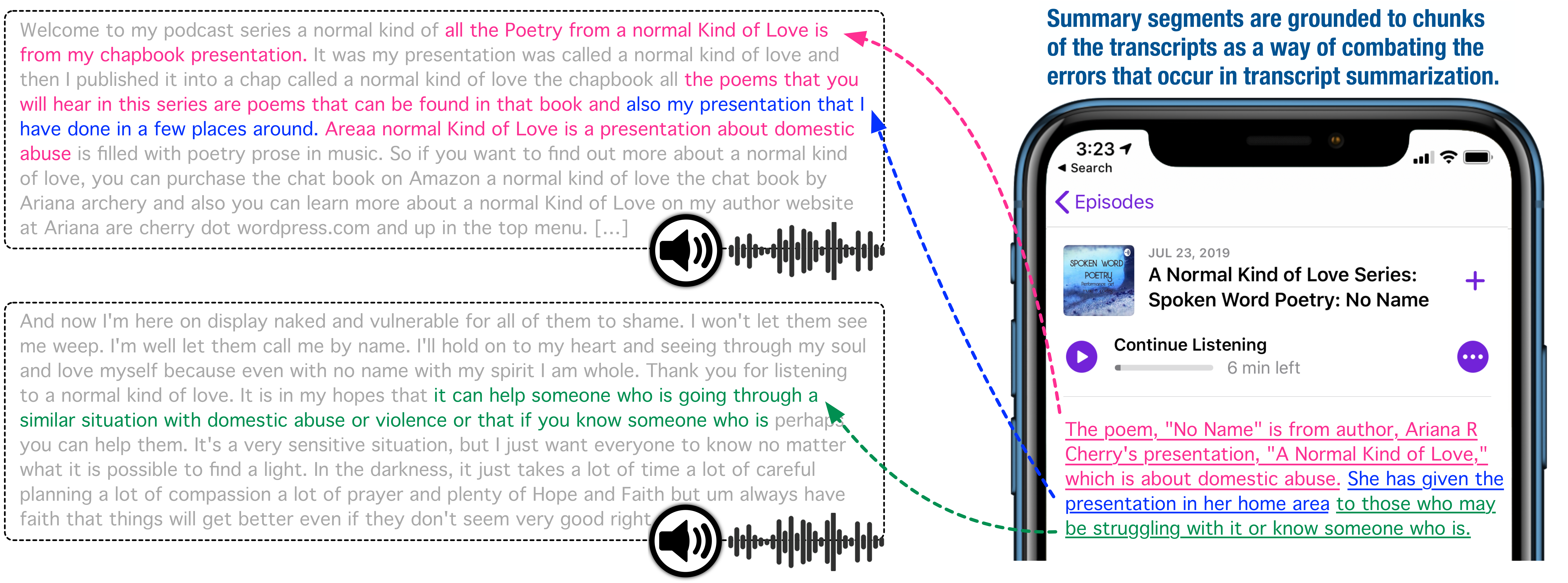
 10 Jul 1, 2022
10 Jul 1, 2022
 14 Jan 3, 2023
14 Jan 3, 2023
 6 Apr 29, 2022
6 Apr 29, 2022
 86 Dec 28, 2022
86 Dec 28, 2022
 43 Dec 28, 2022
43 Dec 28, 2022


 79 Dec 27, 2022
79 Dec 27, 2022
 7 Dec 5, 2022
7 Dec 5, 2022
 2 Feb 3, 2022
2 Feb 3, 2022
 46 Dec 15, 2022
46 Dec 15, 2022
 478 Dec 25, 2022
478 Dec 25, 2022
 20 Dec 12, 2022
20 Dec 12, 2022
 27 Nov 20, 2022
27 Nov 20, 2022
 2k Jan 1, 2023
2k Jan 1, 2023
 197 Dec 25, 2022
197 Dec 25, 2022