Video Representation Learning by Recognizing Temporal Transformations [Project Page]
Simon Jenni, Givi Meishvili, and Paolo Favaro.
In ECCV, 2020.
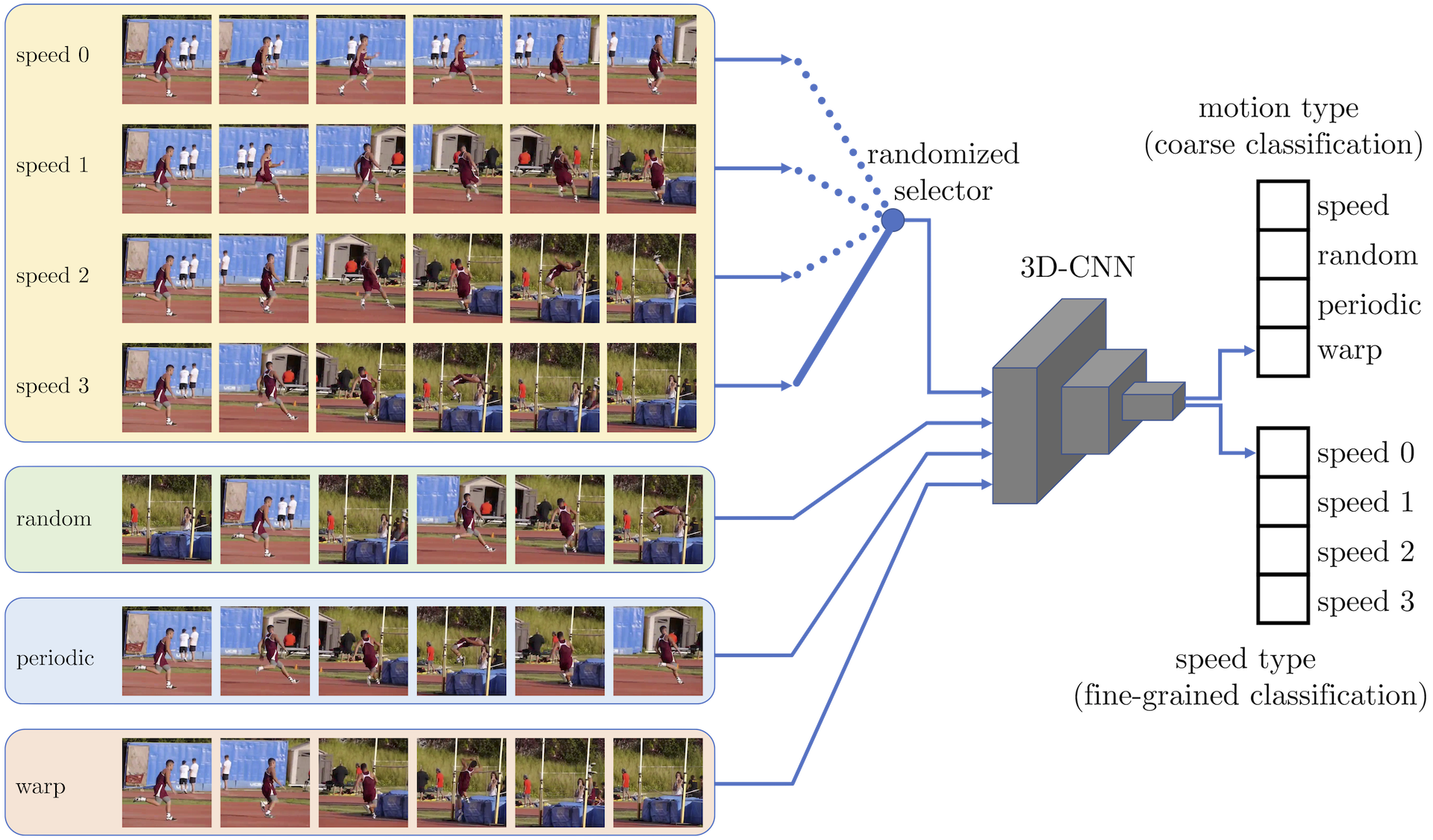
This repository contains code for self-supervised pre-training on UCF101 and supervised transfer learning on the UCF101 and HMDB51 action recognition benchmarks.
Requirements
The code is based on Python 3.7 and tensorflow 1.15.
How to use it
1. Setup
- Dowload UCF101 and HMDB51.
- Set the paths to the data and log directories in constants.py.
- Run init_datasets.py to convert the UCF101 and HMDB datasets to the TFRecord format:
python init_datasets.py
2. Training and evaluation
- To train and evaluate a model using the C3D architecture, execute train_test_C3D.py. An example usage could look like this:
python train_test_C3D.py --tag='test' --num_gpus=2








 42 Dec 9, 2022
42 Dec 9, 2022
 90 Oct 19, 2022
90 Oct 19, 2022
 207 Jan 5, 2023
207 Jan 5, 2023
 2 Oct 31, 2022
2 Oct 31, 2022
 41 Jan 6, 2023
41 Jan 6, 2023
 5 Sep 16, 2022
5 Sep 16, 2022
 4 Dec 11, 2022
4 Dec 11, 2022
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
 1 Sep 18, 2022
1 Sep 18, 2022
 24 Nov 29, 2022
24 Nov 29, 2022
 24 Oct 22, 2022
24 Oct 22, 2022
 37 Dec 4, 2022
37 Dec 4, 2022
 30 Nov 3, 2022
30 Nov 3, 2022
 438 Dec 29, 2022
438 Dec 29, 2022
 221 Dec 30, 2022
221 Dec 30, 2022
 79 Oct 8, 2022
79 Oct 8, 2022
 21 Nov 20, 2022
21 Nov 20, 2022
 54 Dec 15, 2022
54 Dec 15, 2022
 98 Dec 7, 2022
98 Dec 7, 2022