ddpg-aigym
Deep Deterministic Policy Gradient
Implementation of Deep Deterministic Policy Gradiet Algorithm (Lillicrap et al.arXiv:1509.02971.) in Tensorflow
How to use
git clone https://github.com/stevenpjg/ddpg-aigym.git
cd ddpg-aigym
python main.py
During training
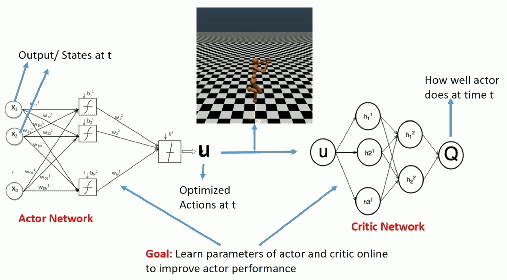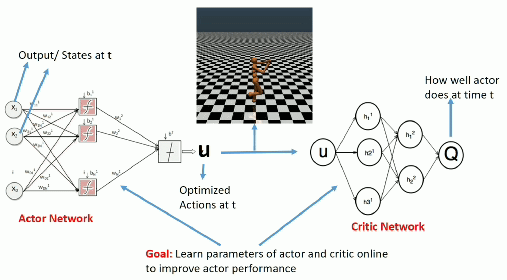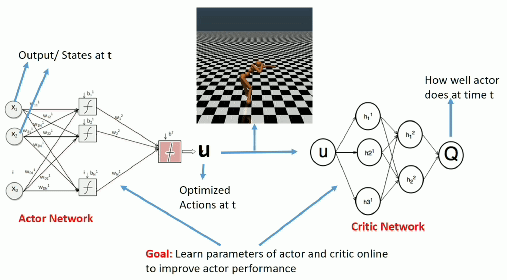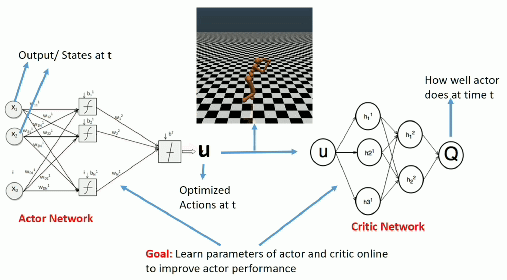
Once trained
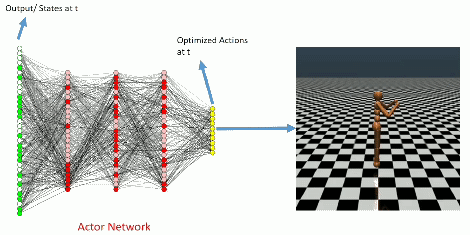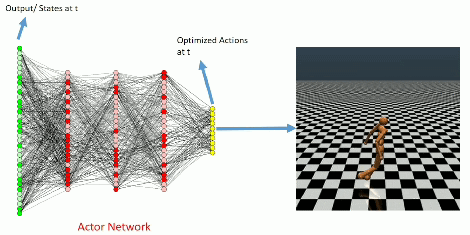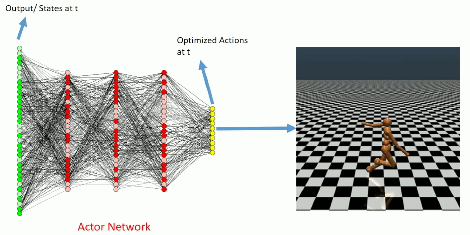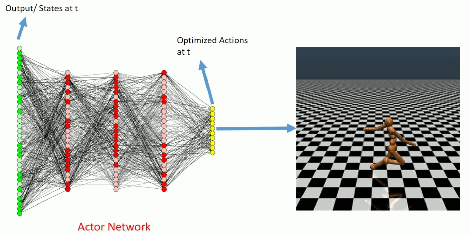
Learning Curve
The learning curve for InvertedPendulum-v1 environment.

Dependencies
- Tensorflow (Developed in tensorflow version 0.11.0rc0 [CPU version] [GPU version])
- OpenAi gym
- Mujoco
Features
- Batch Normalization (improvement in learning speed)
- Grad-inverter (given in arXiv: arXiv:1511.04143)
Note
To use different environment
experiment= 'InvertedPendulum-v1' #specify environments here
To use batch normalization
is_batch_norm = True #batch normalization switch
Let me know if there are any issues and clarifications regarding hyperparameter tuning.








 3.7k Jan 3, 2023
3.7k Jan 3, 2023
 50 Dec 17, 2022
50 Dec 17, 2022
 59 Dec 9, 2022
59 Dec 9, 2022
 187 Dec 26, 2022
187 Dec 26, 2022
 69 Nov 28, 2022
69 Nov 28, 2022
 1 Feb 4, 2022
1 Feb 4, 2022
 3 Dec 28, 2021
3 Dec 28, 2021
 3k Jan 9, 2023
3k Jan 9, 2023
 2.4k Jan 5, 2023
2.4k Jan 5, 2023
 329 Jan 3, 2023
329 Jan 3, 2023
 769 Dec 25, 2022
769 Dec 25, 2022
 1.5k Dec 29, 2022
1.5k Dec 29, 2022
 56 Jan 1, 2023
56 Jan 1, 2023
 163 Dec 26, 2022
163 Dec 26, 2022
 96 Dec 22, 2022
96 Dec 22, 2022
 25 Dec 8, 2022
25 Dec 8, 2022