47 Repositories
Python adam-optimizer Libraries
Byzantine-robust decentralized learning via self-centered clipping
Byzantine-robust decentralized learning via self-centered clipping In this paper, we study the challenging task of Byzantine-robust decentralized trai
 4 Aug 27, 2022
4 Aug 27, 2022
MidTerm Project for the Data Analysis FT Bootcamp, Adam Tycner and Florent ZAHOUI
MidTerm Project for the Data Analysis FT Bootcamp, Adam Tycner and Florent ZAHOUI Hallo
 1 Feb 7, 2022
1 Feb 7, 2022
Tools for mathematical optimization region
Tools for mathematical optimization region
 15 Nov 30, 2022
15 Nov 30, 2022
ESGD-M - A stochastic non-convex second order optimizer, suitable for training deep learning models, for PyTorch
ESGD-M - A stochastic non-convex second order optimizer, suitable for training deep learning models, for PyTorch
 53 Dec 29, 2022
53 Dec 29, 2022
High dimensional black-box optimizer using Latent Action Monte Carlo Tree Search algorithm
LA-MCTS The code is based of paper Learning Search Space Partition for Black-box Optimization using Monte Carlo Tree Search. Component LA-MCTS has thr
 18 Oct 24, 2022
18 Oct 24, 2022
Implementation for ACProp ( Momentum centering and asynchronous update for adaptive gradient methdos, NeurIPS 2021)
This repository contains code to reproduce results for submission NeurIPS 2021, "Momentum Centering and Asynchronous Update for Adaptive Gradient Meth
 15 Jun 11, 2022
15 Jun 11, 2022

Adabelief-Optimizer - Repository for NeurIPS 2020 Spotlight "AdaBelief Optimizer: Adapting stepsizes by the belief in observed gradients"
AdaBelief Optimizer NeurIPS 2020 Spotlight, trains fast as Adam, generalizes well as SGD, and is stable to train GANs. Release of package We have rele
998 Dec 29, 2022
Storage-optimizer - Identify potintial optimizations on the cloud storage accounts
Storage Optimizer Identify potintial optimizations on the cloud storage accounts
 1 Feb 13, 2022
1 Feb 13, 2022

Python Fanduel API (2021) - Lineup Automation
Southpaw is a python package that provides access to the Fanduel API. Optimize your DFS experience by programmatically updating your lineups, analyzin
 13 Jan 4, 2023
13 Jan 4, 2023
NOMAD - A blackbox optimization software
################################################################################### #
 78 Dec 29, 2022
78 Dec 29, 2022
AdamW optimizer for bfloat16 models in pytorch.
Image source AdamW optimizer for bfloat16 models in pytorch. Bfloat16 is currently an optimal tradeoff between range and relative error for deep netwo
 8 Nov 20, 2022
8 Nov 20, 2022
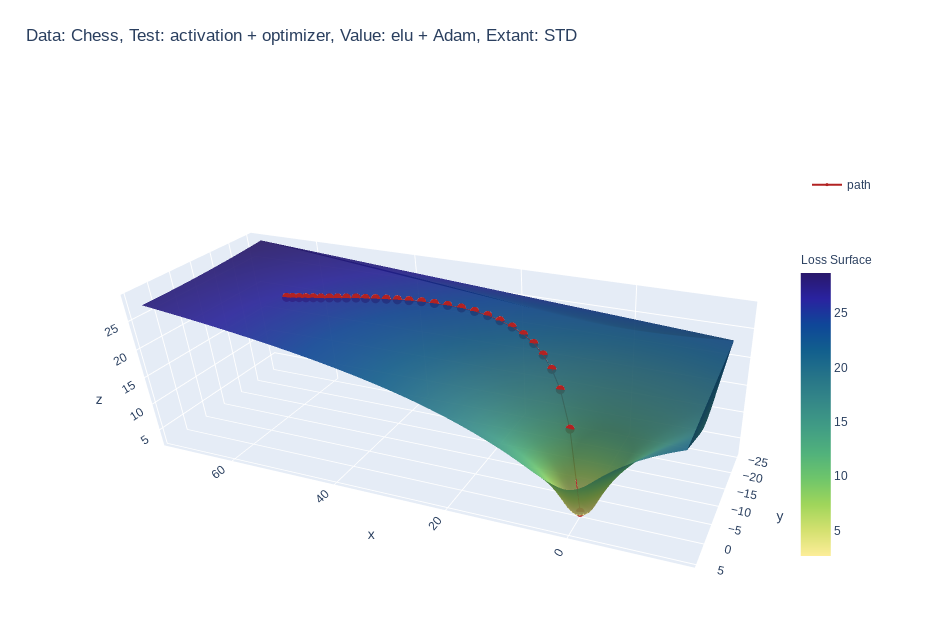
Create 3d loss surface visualizations, with optimizer path. Issues welcome!
MLVTK A loss surface visualization tool Simple feed-forward network trained on chess data, using elu activation and Adam optimizer Simple feed-forward
 7 Dec 21, 2022
7 Dec 21, 2022
A PyTorch Toolbox for Face Recognition
FaceX-Zoo FaceX-Zoo is a PyTorch toolbox for face recognition. It provides a training module with various supervisory heads and backbones towards stat
 1.1k Dec 3, 2021
1.1k Dec 3, 2021

An Implicit Function Theorem (IFT) optimizer for bi-level optimizations
iftopt An Implicit Function Theorem (IFT) optimizer for bi-level optimizations. Requirements Python 3.7+ PyTorch 1.x Installation $ pip install git+ht
 2 Dec 2, 2021
2 Dec 2, 2021
Implement the Pareto Optimizer and pcgrad to make a self-adaptive loss for multi-task
multi-task_losses_optimizer Implement the Pareto Optimizer and pcgrad to make a self-adaptive loss for multi-task 已经实验过了,不会有cuda out of memory情况 ##Par
 14 Dec 25, 2022
14 Dec 25, 2022

DeepOBS: A Deep Learning Optimizer Benchmark Suite
DeepOBS - A Deep Learning Optimizer Benchmark Suite DeepOBS is a benchmarking suite that drastically simplifies, automates and improves the evaluation
 7 May 12, 2020
7 May 12, 2020
AdamW optimizer and cosine learning rate annealing with restarts
AdamW optimizer and cosine learning rate annealing with restarts This repository contains an implementation of AdamW optimization algorithm and cosine
 133 Dec 20, 2022
133 Dec 20, 2022
This is an implementation of Googles Yogi-Optimizer in Keras (tf.keras)
Yogi-Optimizer_Keras This is an implementation of Googles Yogi-Optimizer in Keras (tf.keras) The NeurIPS-Paper can be found here: http://papers.nips.c
 14 Sep 13, 2022
14 Sep 13, 2022
An attempt at furthering Factorio Calculator to work in more general contexts.
factorio-optimizer Lets do Factorio Calculator but make it optimize. Why not use Factorio Calculator? Becuase factorio calculator is not general. The
 1 Jun 3, 2022
1 Jun 3, 2022
Over9000 optimizer
Optimizers and tests Every result is avg of 20 runs. Dataset LR Schedule Imagenette size 128, 5 epoch Imagewoof size 128, 5 epoch Adam - baseline OneC
 405 Nov 27, 2022
405 Nov 27, 2022

Keras implementation of AdaBound
AdaBound for Keras Keras port of AdaBound Optimizer for PyTorch, from the paper Adaptive Gradient Methods with Dynamic Bound of Learning Rate. Usage A
 132 Sep 23, 2022
132 Sep 23, 2022
Apollo optimizer in tensorflow
Apollo Optimizer in Tensorflow 2.x Notes: Warmup is important with Apollo optimizer, so be sure to pass in a learning rate schedule vs. a constant lea
 1 Nov 9, 2021
1 Nov 9, 2021

Second-Order Neural ODE Optimizer, NeurIPS 2021 spotlight
Second-order Neural ODE Optimizer (NeurIPS 2021 Spotlight) [arXiv] ✔️ faster convergence in wall-clock time | ✔️ O(1) memory cost | ✔️ better test-tim
 39 Oct 22, 2022
39 Oct 22, 2022

Rotazioni: a linear programming workout split optimizer
Rotazioni: a linear programming workout split optimizer Dependencies Dependencies for the frontend and backend are respectively listed in client/packa
 3 Oct 13, 2022
3 Oct 13, 2022

Ranger - a synergistic optimizer using RAdam (Rectified Adam), Gradient Centralization and LookAhead in one codebase
Ranger-Deep-Learning-Optimizer Ranger - a synergistic optimizer combining RAdam (Rectified Adam) and LookAhead, and now GC (gradient centralization) i
 1.1k Dec 21, 2022
1.1k Dec 21, 2022

Python Image Optimizer Script
Image-Optimizer Download and Install git clone https://github.com/stefankumpan/Image-Optimizer-Script.git cd Image-Optimizer-Script pip install -r req
 0 Jul 15, 2021
0 Jul 15, 2021
Automatic CPU speed & power optimizer for Linux
Automatic CPU speed & power optimizer for Linux based on active monitoring of laptop's battery state, CPU usage, CPU temperature and system load. Ultimately allowing you to improve battery life without making any compromises.
 3.4k Jan 7, 2023
3.4k Jan 7, 2023
guapow is an on-demand and auto performance optimizer for Linux applications.
guapow is an on-demand and auto performance optimizer for Linux applications. This project's name is an abbreviation for Guarana powder (Guaraná is a fruit from the Amazon rainforest with a highly caffeinated seed).
 19 Nov 18, 2022
19 Nov 18, 2022
Over9000 optimizer
Optimizers and tests Every result is avg of 20 runs. Dataset LR Schedule Imagenette size 128, 5 epoch Imagewoof size 128, 5 epoch Adam - baseline OneC
405 Nov 27, 2022

On the Variance of the Adaptive Learning Rate and Beyond
RAdam On the Variance of the Adaptive Learning Rate and Beyond We are in an early-release beta. Expect some adventures and rough edges. Table of Conte
 2.5k Dec 27, 2022
2.5k Dec 27, 2022

lookahead optimizer (Lookahead Optimizer: k steps forward, 1 step back) for pytorch
lookahead optimizer for pytorch PyTorch implement of Lookahead Optimizer: k steps forward, 1 step back Usage: base_opt = torch.optim.Adam(model.parame
 318 Dec 9, 2022
318 Dec 9, 2022

Bunch of optimizer implementations in PyTorch
Bunch of optimizer implementations in PyTorch
 76 Jan 3, 2023
76 Jan 3, 2023

Demonstrates how to divide a DL model into multiple IR model files (division) and introduce a simplest way to implement a custom layer works with OpenVINO IR models.
Demonstration of OpenVINO techniques - Model-division and a simplest-way to support custom layers Description: Model Optimizer in Intel(r) OpenVINO(tm
 12 Nov 9, 2022
12 Nov 9, 2022
auto-tuning momentum SGD optimizer
YellowFin YellowFin is an auto-tuning optimizer based on momentum SGD which requires no manual specification of learning rate and momentum. It measure
 288 Nov 19, 2022
288 Nov 19, 2022
Adam with minor modifications which give significant improvement
BAdam Modification of Adam [1] optimizer with increased stability and better performance. Tricks used: Decoupled weight decay as in AdamW [2]. Such de
 19 May 11, 2022
19 May 11, 2022
PyTorch implementation of our Adam-NSCL algorithm from our CVPR2021 (oral) paper "Training Networks in Null Space for Continual Learning"
Adam-NSCL This is a PyTorch implementation of Adam-NSCL algorithm for continual learning from our CVPR2021 (oral) paper: Title: Training Networks in N
 34 Dec 21, 2022
34 Dec 21, 2022

How Do Adam and Training Strategies Help BNNs Optimization? In ICML 2021.
AdamBNN This is the pytorch implementation of our paper "How Do Adam and Training Strategies Help BNNs Optimization?", published in ICML 2021. In this
 47 Sep 20, 2022
47 Sep 20, 2022
ML Optimizers from scratch using JAX
Toy implementations of some popular ML optimizers using Python/JAX
 38 Jul 29, 2022
38 Jul 29, 2022

PyTorch implementation DRO: Deep Recurrent Optimizer for Structure-from-Motion
DRO: Deep Recurrent Optimizer for Structure-from-Motion This is the official PyTorch implementation code for DRO-sfm. For technical details, please re
 56 Dec 12, 2022
56 Dec 12, 2022
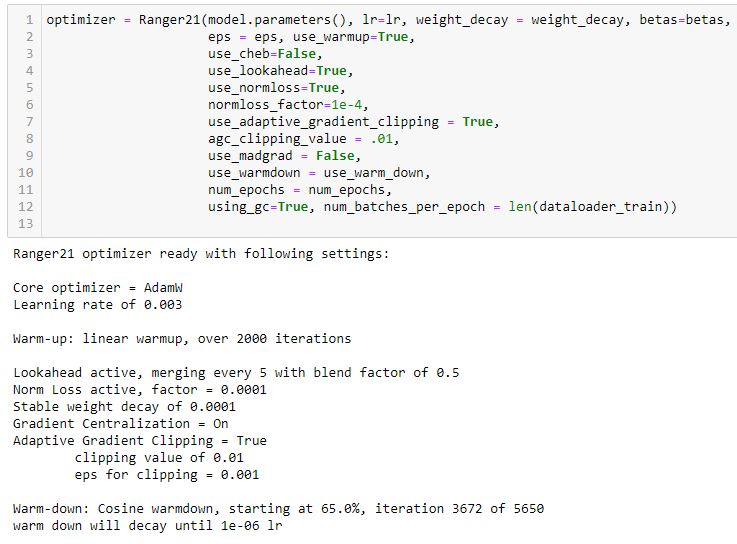
Ranger deep learning optimizer rewrite to use newest components
Ranger21 - integrating the latest deep learning components into a single optimizer Ranger deep learning optimizer rewrite to use newest components Ran
266 Dec 28, 2022

This is the official PyTorch implementation of the paper "TransFG: A Transformer Architecture for Fine-grained Recognition" (Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, Changhu Wang, Alan Yuille).
TransFG: A Transformer Architecture for Fine-grained Recognition Official PyTorch code for the paper: TransFG: A Transformer Architecture for Fine-gra
 307 Jan 3, 2023
307 Jan 3, 2023
This is the official PyTorch implementation of the paper "TransFG: A Transformer Architecture for Fine-grained Recognition" (Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, Changhu Wang, Alan Yuille).
TransFG: A Transformer Architecture for Fine-grained Recognition Official PyTorch code for the paper: TransFG: A Transformer Architecture for Fine-gra
307 Jan 3, 2023
An optimizer that trains as fast as Adam and as good as SGD.
AdaBound An optimizer that trains as fast as Adam and as good as SGD, for developing state-of-the-art deep learning models on a wide variety of popula
 2.9k Dec 27, 2022
2.9k Dec 27, 2022
torch-optimizer -- collection of optimizers for Pytorch
torch-optimizer torch-optimizer -- collection of optimizers for PyTorch compatible with optim module. Simple example import torch_optimizer as optim
 2.6k Jan 3, 2023
2.6k Jan 3, 2023

A mini library for Policy Gradients with Parameter-based Exploration, with reference implementation of the ClipUp optimizer from NNAISENSE.
PGPElib A mini library for Policy Gradients with Parameter-based Exploration [1] and friends. This library serves as a clean re-implementation of the
 56 Jan 1, 2023
56 Jan 1, 2023
A PyTorch implementation of Sharpness-Aware Minimization for Efficiently Improving Generalization
sam.pytorch A PyTorch implementation of Sharpness-Aware Minimization for Efficiently Improving Generalization ( Foret+2020) Paper, Official implementa
 102 Dec 28, 2022
102 Dec 28, 2022

A PyTorch Toolbox for Face Recognition
FaceX-Zoo FaceX-Zoo is a PyTorch toolbox for face recognition. It provides a training module with various supervisory heads and backbones towards stat
1.6k Jan 6, 2023