448 Repositories
Python audio-retrieval Libraries

A timer for bird lovers, plays a random birdcall while displaying its image and info.
Birdcall Timer A timer for bird lovers. Siriema hatchling by Junior Peres Junior Background My partner needed a customizable timer for sitting and sta
 1 Jul 8, 2022
1 Jul 8, 2022

A stable and Fast telegram video convertor bot which can compress, convert(video into audio and other video formats), rename with permanent thumbnail and trim.
ᴠɪᴅᴇᴏ ᴄᴏɴᴠᴇʀᴛᴏʀ A stable and Fast telegram video convertor bot which can compress, convert(video into audio and other video formats), rename and trim.
 183 Jan 4, 2023
183 Jan 4, 2023

Align and Prompt: Video-and-Language Pre-training with Entity Prompts
ALPRO Align and Prompt: Video-and-Language Pre-training with Entity Prompts [Paper] Dongxu Li, Junnan Li, Hongdong Li, Juan Carlos Niebles, Steven C.H
 127 Dec 21, 2022
127 Dec 21, 2022
An implementation of the Contrast Predictive Coding (CPC) method to train audio features in an unsupervised fashion.
CPC_audio This code implements the Contrast Predictive Coding algorithm on audio data, as described in the paper Unsupervised Pretraining Transfers we
 283 Dec 30, 2022
283 Dec 30, 2022

Code for the paper: Audio-Visual Scene Analysis with Self-Supervised Multisensory Features
[Paper] [Project page] This repository contains code for the paper: Andrew Owens, Alexei A. Efros. Audio-Visual Scene Analysis with Self-Supervised Mu
 202 Dec 13, 2022
202 Dec 13, 2022
Asad Alexa VC Bot Is A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group.
Asad Alexa VC Bot Is A Telegram Bot Project That's Allow You To Play Audio And Video Music On Telegram Voice Chat Group.
 6 Jun 20, 2022
6 Jun 20, 2022
The easiest way to use deep metric learning in your application. Modular, flexible, and extensible. Written in PyTorch.
News December 27: v1.1.0 New loss functions: CentroidTripletLoss and VICRegLoss Mean reciprocal rank + per-class accuracies See the release notes Than
 5k Jan 5, 2023
5k Jan 5, 2023
Tkinter based YouTube video downloader works on pytube 11.0.2. Can download YouTube videos in 720p(HD), 144p and even only audio.
YouTube-Downloader Tkinter based YouTube video downloader works on pytube 11.0.2. Can download YouTube videos in 720p(HD), 144p and even only audio. G
 2 Dec 27, 2021
2 Dec 27, 2021
Easily download audio described movies and TV shows found on audiovault.net
AudioVault Downloader A convenient downloader for audio described movies and TV shows found on the Audio Vault. get latest binary release for Windows
 5 Feb 10, 2022
5 Feb 10, 2022
EmoTag helps you train emotion detection model for Chinese audios
emoTag emoTag helps you train emotion detection model for Chinese audios. Environment pip install -r requirement.txt Data We used Emotional Speech Dat
 4 Sep 7, 2022
4 Sep 7, 2022

Baleen: Robust Multi-Hop Reasoning at Scale via Condensed Retrieval (NeurIPS'21)
Baleen Baleen is a state-of-the-art model for multi-hop reasoning, enabling scalable multi-hop search over massive collections for knowledge-intensive
 22 Dec 5, 2022
22 Dec 5, 2022
This repo provides code for QB-Norm (Cross Modal Retrieval with Querybank Normalisation)
This repo provides code for QB-Norm (Cross Modal Retrieval with Querybank Normalisation) Usage example python dynamic_inverted_softmax.py --sims_train
 36 Dec 29, 2022
36 Dec 29, 2022
A python library for working with praat, textgrids, time aligned audio transcripts, and audio files.
praatIO Questions? Comments? Feedback? A library for working with praat, time aligned audio transcripts, and audio files that comes with batteries inc
 224 Dec 19, 2022
224 Dec 19, 2022
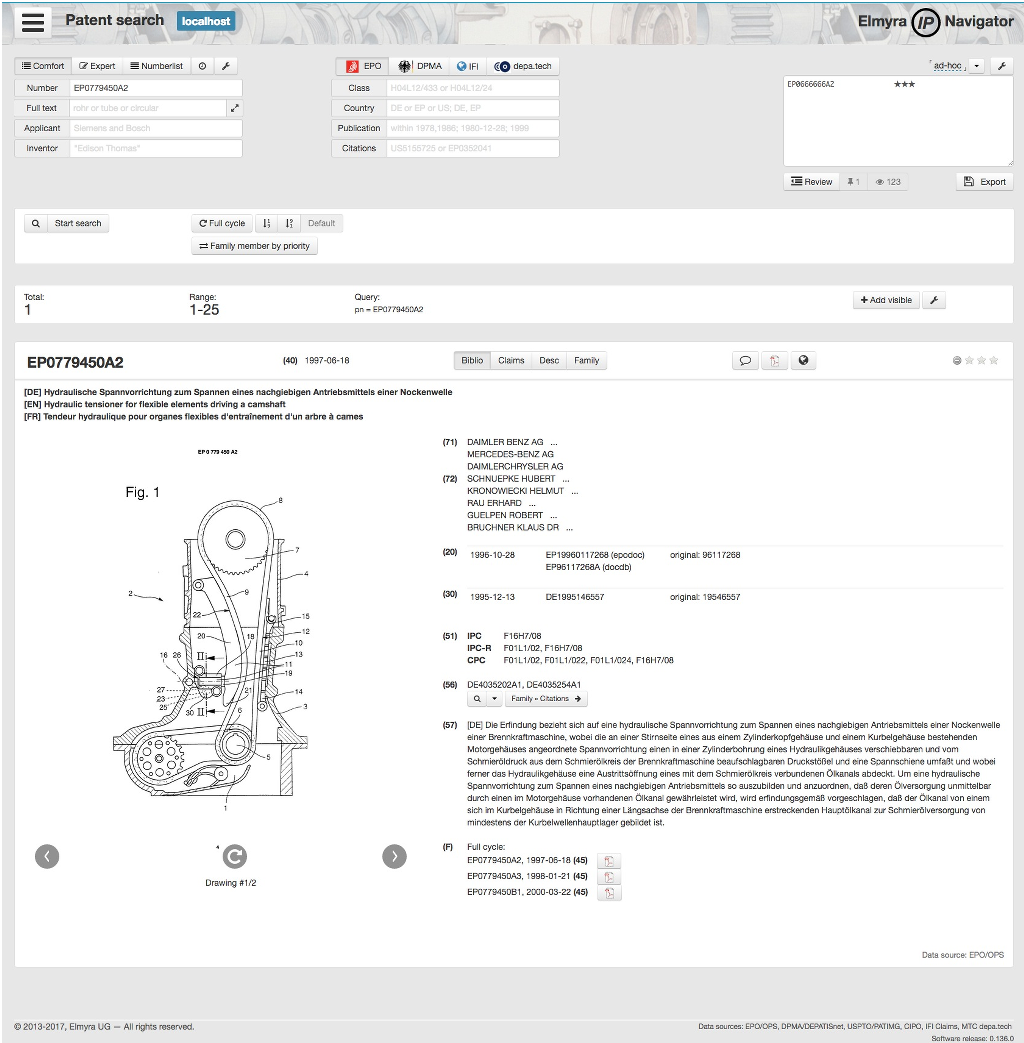
PatZilla is a modular patent information research platform and data integration toolkit with a modern user interface and access to multiple data sources.
PatZilla is a modular patent information research platform and data integration toolkit with a modern user interface and access to multiple data sources.
 68 Dec 14, 2022
68 Dec 14, 2022
A collection of python scripts for extracting and analyzing acoustics from audio files.
pyAcoustics A collection of python scripts for extracting and analyzing acoustics from audio files. Contents 1 Common Use Cases 2 Major revisions 3 Fe
74 Dec 26, 2022
![Joint Versus Independent Multiview Hashing for Cross-View Retrieval[J] (IEEE TCYB 2021, PyTorch Code)](https://github.com/penghu-cs/DCHN/raw/main/paper/DCHN.jpg)
Joint Versus Independent Multiview Hashing for Cross-View Retrieval[J] (IEEE TCYB 2021, PyTorch Code)
Thanks to the low storage cost and high query speed, cross-view hashing (CVH) has been successfully used for similarity search in multimedia retrieval. However, most existing CVH methods use all views to learn a common Hamming space, thus making it difficult to handle the data with increasing views or a large number of views.
 4 Nov 19, 2022
4 Nov 19, 2022

Legal text retrieval for python
legal-text-retrieval Overview This system contains 2 steps: generate training data containing negative sample found by mixture score of cosine(tfidf)
 22 Dec 6, 2022
22 Dec 6, 2022
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021

Audio pitch-shifting & re-sampling utility, based on the EMU SP-1200
Pitcher.py Free & OS emulation of the SP-12 & SP-1200 signal chain (now with GUI) Pitch shift / bitcrush / resample audio files Written and tested in
 13 Oct 3, 2022
13 Oct 3, 2022

LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021
LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021 We propose a cross encoder model (LTR_CrossEncoder) for information retrieval, re-retrie
 7 Jan 12, 2022
7 Jan 12, 2022
VIsually-Pivoted Audio and(N) Text
VIP-ANT: VIsually-Pivoted Audio and(N) Text Code for the paper Connecting the Dots between Audio and Text without Parallel Data through Visual Knowled
 16 Nov 4, 2022
16 Nov 4, 2022
A Telegram bot to transcribe audio, video and image into text.
Transcriber Bot A Telegram bot to transcribe audio, video and image into text. Deploy to Heroku Local Deploying Install the FFmpeg. Make sure you have
 10 Dec 19, 2022
10 Dec 19, 2022
Wav2Vec for speech recognition, classification, and audio classification
Soxan در زبان پارسی به نام سخن This repository consists of models, scripts, and notebooks that help you to use all the benefits of Wav2Vec 2.0 in your
 140 Dec 15, 2022
140 Dec 15, 2022
Python script for downloading audio from YouTube songs/videos.
Python script for downloading audio from YouTube songs/videos. All you have to do is specify the path to your folder and then type song's/video's name and the sound will be downloaded into your folder.
 0 Oct 5, 2022
0 Oct 5, 2022
Make an audio file (really) long-winded
longwind Make an audio file (really) long-winded Daily repetitions are an illusion anyway.
 2 Sep 12, 2022
2 Sep 12, 2022
Omniscient Mozart, being able to transcribe everything in the music, including vocal, drum, chord, beat, instruments, and more.
OMNIZART Omnizart is a Python library that aims for democratizing automatic music transcription. Given polyphonic music, it is able to transcribe pitc
 1.3k Jan 8, 2023
1.3k Jan 8, 2023
pyo is a Python module written in C to help digital signal processing script creation.
pyo is a Python module written in C to help digital signal processing script creation.
 1.1k Jan 1, 2023
1.1k Jan 1, 2023

Fine-grained Post-training for Improving Retrieval-based Dialogue Systems - NAACL 2021
Fine-grained Post-training for Multi-turn Response Selection Implements the model described in the following paper Fine-grained Post-training for Impr
 83 Dec 20, 2022
83 Dec 20, 2022

Code for "Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose"
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose We provide PyTorch implementations for our arxiv paper "Audio-dr
 497 Jan 9, 2023
497 Jan 9, 2023
![MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]](https://github.com/uniBruce/Mead/raw/master/Figures/mead.png)
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020]
MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation [ECCV2020] by Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wa
 112 Dec 28, 2022
112 Dec 28, 2022

Code for Talking Face Generation by Adversarially Disentangled Audio-Visual Representation (AAAI 2019)
Talking Face Generation by Adversarially Disentangled Audio-Visual Representation (AAAI 2019) We propose Disentangled Audio-Visual System (DAVS) to ad
 750 Dec 23, 2022
750 Dec 23, 2022
AudioDVP:Photorealistic Audio-driven Video Portraits
AudioDVP This is the official implementation of Photorealistic Audio-driven Video Portraits. Major Requirements Ubuntu = 18.04 PyTorch = 1.2 GCC =
 232 Jan 3, 2023
232 Jan 3, 2023

LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021
LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021 We propose a cross encoder model (LTR_CrossEncoder) for information retrieval, re-retrie
7 Jan 12, 2022

User-friendly Voice Cloning Application
Multi-Language-RTVC stands for Multi-Language Real Time Voice Cloning and is a Voice Cloning Tool capable of transfering speaker-specific audio featur
 19 Dec 30, 2022
19 Dec 30, 2022

A Transformer-Based Feature Segmentation and Region Alignment Method For UAV-View Geo-Localization
University1652-Baseline [Paper] [Slide] [Explore Drone-view Data] [Explore Satellite-view Data] [Explore Street-view Data] [Video Sample] [中文介绍] This
 335 Jan 6, 2023
335 Jan 6, 2023
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022

Autoregressive Entity Retrieval
The GENRE (Generative ENtity REtrieval) system as presented in Autoregressive Entity Retrieval implemented in pytorch. @inproceedings{decao2020autoreg
611 Dec 16, 2022
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats
TG-MusicPlayer A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Py
 4 Jul 30, 2022
4 Jul 30, 2022
Delta TTA(Text To Audio) SoftWare
Text-To-Audio-Windows Delta TTA(Text To Audio) SoftWare Info You Can Use It For Convert Your Text To Audio File You Just Write Your Text And Your End
 2 Dec 14, 2021
2 Dec 14, 2021

Text Classification in Turkish Texts with Bert
You can watch the details of the project on my youtube channel Project Interface Project Second Interface Goal= Correctly guessing the classification
 42 Dec 31, 2022
42 Dec 31, 2022

Powerful unsupervised domain adaptation method for dense retrieval.
Powerful unsupervised domain adaptation method for dense retrieval
 191 Dec 28, 2022
191 Dec 28, 2022

Let's you download entire YT-playlists.
Youtube MP3 Playlist Downloader Let's you download entire youtube playlists as mp3 files. This application is basically a script that makes it easier
 11 Dec 18, 2022
11 Dec 18, 2022
A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities
MPT A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities. Implementation for our AAAI 2022 paper: Multi-
 4 May 8, 2022
4 May 8, 2022

DeepDiffusion: Unsupervised Learning of Retrieval-adapted Representations via Diffusion-based Ranking on Latent Feature Manifold
DeepDiffusion Introduction This repository provides the code of the DeepDiffusion algorithm for unsupervised learning of retrieval-adapted representat
 4 Nov 15, 2022
4 Nov 15, 2022
A GUI-based audio player with support for a large variety of formats
Miza-Player A GUI-based audio player with support for a large variety of formats, able to play from web-hosted media platforms such as YouTube, includ
 3 Dec 14, 2022
3 Dec 14, 2022
MelGAN test on audio decoding
Official repository for the paper MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis The original work URL: https://github.com
 1 Apr 29, 2022
1 Apr 29, 2022
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022

Official implementation of the AAAI 2022 paper "Learning Token-based Representation for Image Retrieval"
Token: Token-based Representation for Image Retrieval PyTorch training code for Token-based Representation for Image Retrieval. We propose a joint loc
 42 Dec 6, 2022
42 Dec 6, 2022

Real-Time Spherical Microphone Renderer for binaural reproduction in Python
ReTiSAR Implementation of the Real-Time Spherical Microphone Renderer for binaural reproduction in Python [1][2]. Contents: | Requirements | Setup | Q
 51 Dec 17, 2022
51 Dec 17, 2022
Visualizer using audio and semantic analysis to explore BigGAN (Brock et al., 2018) latent space.
BigGAN Audio Visualizer Description This visualizer explores BigGAN (Brock et al., 2018) latent space by using pitch/tempo of an audio file to generat
 2 Nov 21, 2022
2 Nov 21, 2022
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks - Official Project Page This repository contains the code develope
 1.7k Dec 18, 2022
1.7k Dec 18, 2022

Steerable discovery of neural audio effects
Steerable discovery of neural audio effects Christian J. Steinmetz and Joshua D. Reiss Abstract Applications of deep learning for audio effects often
 182 Dec 29, 2022
182 Dec 29, 2022
Code for csig audio deepfake detection
FMFCC Audio Deepfake Detection Solution This repo provides an solution for the 多媒体伪造取证大赛. Our solution achieve the 1st in the Audio Deepfake Detection
 9 Jun 4, 2022
9 Jun 4, 2022
InsCLR: Improving Instance Retrieval with Self-Supervision
InsCLR: Improving Instance Retrieval with Self-Supervision This is an official PyTorch implementation of the InsCLR paper. Download Dataset Dataset Im
 25 Aug 30, 2022
25 Aug 30, 2022
Userscript qutebrowser for downloading audio / video from youtube using aria2
Yt-Downloader Userscript qutebrowser for downloading video / audio from youtube using aria2 by hint links. Requirements Rofi youtube-dl aria2 dunst In
 0 Dec 11, 2021
0 Dec 11, 2021
Train Dense Passage Retriever (DPR) with a single GPU
Gradient Cached Dense Passage Retrieval Gradient Cached Dense Passage Retrieval (GC-DPR) - is an extension of the original DPR library. We introduce G
 92 Jan 2, 2023
92 Jan 2, 2023

The official repository for Audio ALBERT
AALBERT Here is also the official repository of AALBERT, which is Pytorch lightning reimplementation of the paper, Audio ALBERT: A Lite Bert for Self-
 55 Dec 11, 2022
55 Dec 11, 2022
Implementation of the algorithm shown in the article "Modelo de Predicción de Éxito de Canciones Basado en Descriptores de Audio"
Success Predictor Implementation of the algorithm shown in the article "Modelo de Predicción de Éxito de Canciones Basado en Descriptores de Audio". B
 4 Mar 17, 2022
4 Mar 17, 2022
Interpretable and Generalizable Person Re-Identification with Query-Adaptive Convolution and Temporal Lifting
QAConv Interpretable and Generalizable Person Re-Identification with Query-Adaptive Convolution and Temporal Lifting This PyTorch code is proposed in
 166 Dec 28, 2022
166 Dec 28, 2022
OpenL3: Open-source deep audio and image embeddings
OpenL3 OpenL3 is an open-source Python library for computing deep audio and image embeddings. Please refer to the documentation for detailed instructi
 326 Jan 2, 2023
326 Jan 2, 2023
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats
TG-MusicPlayer A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Py
 4 Dec 14, 2022
4 Dec 14, 2022
Fluency ENhanced Sentence-bert Evaluation (FENSE), metric for audio caption evaluation. And Benchmark dataset AudioCaps-Eval, Clotho-Eval.
FENSE The metric, Fluency ENhanced Sentence-bert Evaluation (FENSE), for audio caption evaluation, proposed in the paper "Can Audio Captions Be Evalua
 13 Dec 23, 2022
13 Dec 23, 2022
Near-Duplicate Video Retrieval with Deep Metric Learning
Near-Duplicate Video Retrieval with Deep Metric Learning This repository contains the Tensorflow implementation of the paper Near-Duplicate Video Retr
 2 Jan 24, 2022
2 Jan 24, 2022

Official repository of the paper "GPR1200: A Benchmark for General-PurposeContent-Based Image Retrieval"
GPR1200 Dataset GPR1200: A Benchmark for General-Purpose Content-Based Image Retrieval (ArXiv) Konstantin Schall, Kai Uwe Barthel, Nico Hezel, Klaus J
 16 Nov 21, 2022
16 Nov 21, 2022
Code for unmixing audio signals in four different stems "drums, bass, vocals, others". The code is adapted from "Jukebox: A Generative Model for Music"
Status: Archive (code is provided as-is, no updates expected) Disclaimer This code is a based on "Jukebox: A Generative Model for Music" Paper We adju
 24 Dec 29, 2022
24 Dec 29, 2022
Code for the ECIR'22 paper "Evaluating the Robustness of Retrieval Pipelines with Query Variation Generators"
Query Variation Generators This repository contains the code and annotation data for the ECIR'22 paper "Evaluating the Robustness of Retrieval Pipelin
 12 Nov 20, 2022
12 Nov 20, 2022
A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats.
VC UserBot A Telegram Userbot to play Audio and Video songs / files in Telegram Voice Chats. It's made with PyTgCalls and Pyrogram Requirements Python
 1 Nov 29, 2021
1 Nov 29, 2021

Fake videos detection by tracing the source using video hashing retrieval.
Vision Transformer Based Video Hashing Retrieval for Tracing the Source of Fake Videos 🎉️ 📜 Directory Introduction VTL Trace Samples and Acc of Hash
 56 Dec 22, 2022
56 Dec 22, 2022
Haystack is an open source NLP framework that leverages Transformer models.
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
 2.7k Nov 28, 2021
2.7k Nov 28, 2021
Pyserini is a Python toolkit for reproducible information retrieval research with sparse and dense representations.
Pyserini Pyserini is a Python toolkit for reproducible information retrieval research with sparse and dense representations. Retrieval using sparse re
 706 Dec 29, 2022
706 Dec 29, 2022
An Open-Source Package for Information Retrieval.
OpenMatch An Open-Source Package for Information Retrieval. 😃 What's New Top Spot on TREC-COVID Challenge (May 2020, Round2) The twin goals of the ch
 439 Dec 27, 2022
439 Dec 27, 2022

A curated list of awesome papers for Semantic Retrieval (TOIS Accepted: Semantic Models for the First-stage Retrieval: A Comprehensive Review).
A curated list of awesome papers for Semantic Retrieval (TOIS Accepted: Semantic Models for the First-stage Retrieval: A Comprehensive Review).
 189 Dec 28, 2022
189 Dec 28, 2022

Multimodal commodity image retrieval 多模态商品图像检索
Multimodal commodity image retrieval 多模态商品图像检索 Not finished yet... introduce explain:The specific description of the project and the product image dat
 8 Nov 25, 2022
8 Nov 25, 2022

(NeurIPS 2021) Pytorch implementation of paper "Re-ranking for image retrieval and transductive few-shot classification"
SSR (NeurIPS 2021) Pytorch implementation of paper "Re-ranking for image retrieval and transductivefew-shot classification" [Paper] [Project webpage]
 29 Dec 6, 2022
29 Dec 6, 2022
Convert Video Files To Text And Audio
Video-To-Text Convert Video Files To Text And Audio Convert To Audio 1: open dvtt folder in cmd 2: run this command in cmd = main.py Audio Convert To
2 Dec 5, 2021
Question and answer retrieval in Turkish with BERT
trfaq Google supported this work by providing Google Cloud credit. Thank you Google for supporting the open source! 🎉 What is this? At this repo, I'm
 13 Oct 10, 2022
13 Oct 10, 2022

R interface to fast.ai
R interface to fastai The fastai package provides R wrappers to fastai. The fastai library simplifies training fast and accurate neural nets using mod
 113 Dec 20, 2022
113 Dec 20, 2022
🔊 Audio and fastai v2
Fastaudio An audio module for fastai v2. We want to help you build audio machine learning applications while minimizing the need for audio domain expe
 152 Dec 28, 2022
152 Dec 28, 2022

Deep Reinforced Attention Regression for Partial Sketch Based Image Retrieval.
DARP-SBIR Intro This repository contains the source code implementation for ICDM submission paper Deep Reinforced Attention Regression for Partial Ske
 2 Jan 9, 2022
2 Jan 9, 2022
A Python wrapper of Neighbor Retrieval Visualizer (NeRV)
PyNeRV A Python wrapper of the dimensionality reduction algorithm Neighbor Retrieval Visualizer (NeRV) Compile Set up the paths in Makefile then make.
 2 Aug 29, 2021
2 Aug 29, 2021

PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition, CVPR 2018
PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place
 294 Dec 12, 2022
294 Dec 12, 2022
A GPU-optional modular synthesizer in pytorch, 16200x faster than realtime, for audio ML researchers.
torchsynth The fastest synth in the universe. Introduction torchsynth is based upon traditional modular synthesis written in pytorch. It is GPU-option
 229 Jan 2, 2023
229 Jan 2, 2023
A desktop GUI providing an audio interface for GPT3.
Jabberwocky neil_degrasse_tyson_with_audio.mp4 Project Description This GUI provides an audio interface to GPT-3. My main goal was to provide a conven
 16 Nov 27, 2022
16 Nov 27, 2022
This bot can stream audio or video files and urls in telegram voice chats
Voice Chat Streamer This bot can stream audio or video files and urls in telegram voice chats :) 🎯 Follow me and star this repo for more telegram bot
 4 Oct 9, 2022
4 Oct 9, 2022
This is a Client-Server-System which can send audio from a microphone from the server to client and in the other direction.
Audio-Streaming-Python This is a Client-Server-System which can send audio from a microphone from the server to client and in the other direction. You
 0 Jan 5, 2023
0 Jan 5, 2023

Video Corpus Moment Retrieval with Contrastive Learning (SIGIR 2021)
Video Corpus Moment Retrieval with Contrastive Learning PyTorch implementation for the paper "Video Corpus Moment Retrieval with Contrastive Learning"
 42 Dec 29, 2022
42 Dec 29, 2022
Implementing Graph Convolutional Networks and Information Retrieval Mechanisms using pure Python and NumPy
Implementing Graph Convolutional Networks and Information Retrieval Mechanisms using pure Python and NumPy
 3 Jun 22, 2022
3 Jun 22, 2022
Python based Telegram bot. Search and download YouTube video or audio.
Python-Telegram-Youtube-Media-Bot Python based Telegram bot. Search and download YouTube video or audio. Just change settings.py and start TelegramBot
 2 Oct 2, 2022
2 Oct 2, 2022
cisip-FIRe - Fast Image Retrieval
Fast Image Retrieval (FIRe) is an open source image retrieval project release by Center of Image and Signal Processing Lab (CISiP Lab), Universiti Malaya. This project implements most of the major binary hashing methods to date, together with different popular backbone networks and public datasets.
 39 Nov 25, 2022
39 Nov 25, 2022

Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
Official implementation of the RAVE model: a Realtime Audio Variational autoEncoder
 589 Jan 2, 2023
589 Jan 2, 2023

The audio-video synchronization of MKV Container Format is exploited to achieve data hiding
The audio-video synchronization of MKV Container Format is exploited to achieve data hiding, where the hidden data can be utilized for various management purposes, including hyper-linking, annotation, and authentication
 1 Nov 17, 2021
1 Nov 17, 2021
Fast Image Retrieval (FIRe) is an open source image retrieval project
Fast Image Retrieval (FIRe) is an open source image retrieval project release by Center of Image and Signal Processing Lab (CISiP Lab), Universiti Malaya. This project implements most of the major binary hashing methods to date, together with different popular backbone networks and public datasets.
39 Nov 25, 2022

Code for the TASLP paper "PSLA: Improving Audio Tagging With Pretraining, Sampling, Labeling, and Aggregation".
PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation Introduction Getting Started FSD50K Recipe AudioSet Recipe Label E
 84 Dec 27, 2022
84 Dec 27, 2022
Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings
Text2Music Emotion Embedding Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings Reference Emotion Embedding Spaces for Matching
 50 Dec 5, 2022
50 Dec 5, 2022
SomaFM Plugin for Kodi
SomaFM XBMC Plugin This description is a bit outdated. You can simply install this addon by browsing the official repositories from within Kodi. Insta
 7 Jan 21, 2022
7 Jan 21, 2022
Fast Image Retrieval is an open source image retrieval framework
Fast Image Retrieval is an open source image retrieval framework release by Center of Image and Signal Processing Lab (CISiP Lab), Universiti Malaya. This framework implements most of the major binary hashing methods, together with both popular backbone networks and public datasets.
39 Nov 25, 2022
Audio/Video downloader
youtubeDownloader Audio/Video downloader • The project downloads audio/video/both after link is entered • It also shows total size of the file, time l
 1 Nov 16, 2021
1 Nov 16, 2021
YOLOX_AUDIO is an audio event detection model based on YOLOX
YOLOX_AUDIO is an audio event detection model based on YOLOX, an anchor-free version of YOLO. This repo is an implementated by PyTorch. Main goal of YOLOX_AUDIO is to detect and classify pre-defined audio events in multi-spectrogram domain using image object detection frameworks.
 77 Dec 19, 2022
77 Dec 19, 2022
A discord bot for downloading youtube video and audio files
disctube disctube is a discord bot for downloading video and audio files from youtube using python pytube. disclaimer i am not the best python program
 3 Feb 3, 2022
3 Feb 3, 2022

ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning. In ICCV, 2021.
ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning This repository contains the code for our ICCV 202
 28 Nov 8, 2022
28 Nov 8, 2022