44 Repositories
Python benchmarks Libraries
Code for testing various M1 Chip benchmarks with TensorFlow.
M1, M1 Pro, M1 Max Machine Learning Speed Test Comparison This repo contains some sample code to benchmark the new M1 MacBooks (M1 Pro and M1 Max) aga
 348 Jan 4, 2023
348 Jan 4, 2023
Theory-inspired Parameter Control Benchmarks for Dynamic Algorithm Configuration
This repo is for the paper: Theory-inspired Parameter Control Benchmarks for Dynamic Algorithm Configuration The DAC environment is based on the Dynam
 1 Aug 19, 2022
1 Aug 19, 2022
All public open-source implementations of convnets benchmarks
convnet-benchmarks Easy benchmarking of all public open-source implementations of convnets. A summary is provided in the section below. Machine: 6-cor
 2.7k Dec 30, 2022
2.7k Dec 30, 2022

Best practices for segmentation of the corporate network of any company
Best-practice-for-network-segmentation What is this? This project was created to publish the best practices for segmentation of the corporate network
 2k Jan 7, 2023
2k Jan 7, 2023
Code examples and benchmarks from the paper "Understanding Entropy Coding With Asymmetric Numeral Systems (ANS): a Statistician's Perspective"
Code For the Paper "Understanding Entropy Coding With Asymmetric Numeral Systems (ANS): a Statistician's Perspective" Author: Robert Bamler Date: 22 D
 4 Nov 2, 2022
4 Nov 2, 2022
A benchmark framework for Tensorflow
TensorFlow benchmarks This repository contains various TensorFlow benchmarks. Currently, it consists of two projects: PerfZero: A benchmark framework
 1.1k Dec 30, 2022
1.1k Dec 30, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022
Benchmarks for Model-Based Optimization
Design-Bench Design-Bench is a benchmarking framework for solving automatic design problems that involve choosing an input that maximizes a black-box
 43 Dec 20, 2022
43 Dec 20, 2022
Benchmark spaces - Benchmarks of how well different two dimensional spaces work for clustering algorithms
benchmark_spaces Benchmarks of how well different two dimensional spaces work fo
 6 May 7, 2022
6 May 7, 2022
Rust Markdown Parsing Benchmarks
Rust Markdown Parsing Benchmarks This repo tries to assess Rust markdown parsing
 1 Aug 24, 2022
1 Aug 24, 2022

Raster processing benchmarks for Python and R packages
Raster processing benchmarks This repository contains a collection of raster processing benchmarks for Python and R packages. The tests cover the most
 13 Oct 24, 2022
13 Oct 24, 2022

Benchmarks for Object Detection in Aerial Images
Benchmarks for Object Detection in Aerial Images
 691 Dec 30, 2022
691 Dec 30, 2022
PyTorch implementation of a collections of scalable Video Transformer Benchmarks.
PyTorch implementation of Video Transformer Benchmarks This repository is mainly built upon Pytorch and Pytorch-Lightning. We wish to maintain a colle
 156 Jan 8, 2023
156 Jan 8, 2023

A benchmark dataset for emulating atmospheric radiative transfer in weather and climate models with machine learning (NeurIPS 2021 Datasets and Benchmarks Track)
ClimART - A Benchmark Dataset for Emulating Atmospheric Radiative Transfer in Weather and Climate Models Official PyTorch Implementation Using deep le
 21 Dec 31, 2022
21 Dec 31, 2022

Benchmarks for the Optimal Power Flow Problem
Power Grid Lib - Optimal Power Flow This benchmark library is curated and maintained by the IEEE PES Task Force on Benchmarks for Validation of Emergi
 207 Dec 8, 2022
207 Dec 8, 2022

Training code and evaluation benchmarks for the "Self-Supervised Policy Adaptation during Deployment" paper.
Self-Supervised Policy Adaptation during Deployment PyTorch implementation of PAD and evaluation benchmarks from Self-Supervised Policy Adaptation dur
 101 Nov 1, 2022
101 Nov 1, 2022
Just a little benchmark for scrapper PC's
PopMark Just a little benchmark for scrapper PC's This benchmark is for old computer that dont support other benchmark because of support. Like lack o
 1 Nov 24, 2021
1 Nov 24, 2021

NeurIPS 2021 Datasets and Benchmarks Track
AP-10K: A Benchmark for Animal Pose Estimation in the Wild Introduction | Updates | Overview | Download | Training Code | Key Questions | License Intr
 82 Dec 11, 2022
82 Dec 11, 2022
Source code and notebooks to reproduce experiments and benchmarks on Bias Faces in the Wild (BFW).
Face Recognition: Too Bias, or Not Too Bias? Robinson, Joseph P., Gennady Livitz, Yann Henon, Can Qin, Yun Fu, and Samson Timoner. "Face recognition:
 41 Dec 12, 2022
41 Dec 12, 2022

QED-C: The Quantum Economic Development Consortium provides these computer programs and software for use in the fields of quantum science and engineering.
Application-Oriented Performance Benchmarks for Quantum Computing This repository contains a collection of prototypical application- or algorithm-cent
 67 Nov 30, 2022
67 Nov 30, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 A repository part of the MarIA project. Corpora 📃 Corpora Number of documents Number of tokens Size (GB) BNE 201,080,084
 203 Dec 20, 2022
203 Dec 20, 2022
![[NeurIPS 2021] Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods](https://user-images.githubusercontent.com/58995473/120717799-27fd9200-c496-11eb-940f-b16d4d528e0f.png)
[NeurIPS 2021] Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods
Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods Large Scale Learning on Non-Homophilous Graphs: New Benchmark
 16 Nov 12, 2021
16 Nov 12, 2021
Source code for the paper: Variance-Aware Machine Translation Test Sets (NeurIPS 2021 Datasets and Benchmarks Track)
Variance-Aware-MT-Test-Sets Variance-Aware Machine Translation Test Sets License See LICENSE. We follow the data licensing plan as the same as the WMT
 5 Dec 21, 2021
5 Dec 21, 2021

SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning
Datasets | Website | Raw Data | OpenReview SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning Christopher
 67 Dec 17, 2022
67 Dec 17, 2022

SW components and demos for visual kinship recognition. An emphasis is put on the FIW dataset-- data loaders, benchmarks, results in summary.
FIW Data Development Kit Table of Contents Introduction Families In the Wild Database Publications Organization To Do License Getting Involved Introdu
12 Jun 4, 2022
[NeurIPS 2021] Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods
Large Scale Learning on Non-Homophilous Graphs: New Benchmarks and Strong Simple Methods Large Scale Learning on Non-Homophilous Graphs: New Benchmark
60 Jan 3, 2023
Simple data balancing baselines for worst-group-accuracy benchmarks.
BalancingGroups Code to replicate the experimental results from Simple data balancing baselines achieve competitive worst-group-accuracy. Replicating
 29 Dec 2, 2022
29 Dec 2, 2022

A suite of benchmarks for CPU and GPU performance of the most popular high-performance libraries for Python :rocket:
A suite of benchmarks for CPU and GPU performance of the most popular high-performance libraries for Python :rocket:
 255 Jan 4, 2023
255 Jan 4, 2023
Simple data balancing baselines for worst-group-accuracy benchmarks.
BalancingGroups Code to replicate the experimental results from Simple data balancing baselines achieve competitive worst-group-accuracy. Replicating
29 Dec 2, 2022

Repo for "Physion: Evaluating Physical Prediction from Vision in Humans and Machines" submission to NeurIPS 2021 (Datasets & Benchmarks track)
Physion: Evaluating Physical Prediction from Vision in Humans and Machines This repo contains code and data to reproduce the results in our paper, Phy
 38 Jan 6, 2023
38 Jan 6, 2023
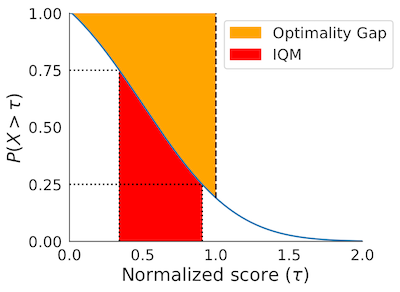
rliable is an open-source Python library for reliable evaluation, even with a handful of runs, on reinforcement learning and machine learnings benchmarks.
Open-source library for reliable evaluation on reinforcement learning and machine learning benchmarks. See NeurIPS 2021 oral for details.
 529 Jan 1, 2023
529 Jan 1, 2023
This repository contains a set of benchmarks of different implementations of Parquet (storage format) - Arrow (in-memory format).
Parquet benchmarks This repository contains a set of benchmarks of different implementations of Parquet (storage format) - Arrow (in-memory format).
 11 Dec 21, 2022
11 Dec 21, 2022
Reproducible nvim completion framework benchmarks.
Nvim.Bench Reproducible nvim completion framework benchmarks. Runs inside Docker. Fair and balanced Methodology Note: for all "randomness", they are g
 14 Nov 20, 2022
14 Nov 20, 2022
Sequence modeling benchmarks and temporal convolutional networks
Sequence Modeling Benchmarks and Temporal Convolutional Networks (TCN) This repository contains the experiments done in the work An Empirical Evaluati
 3.5k Jan 1, 2023
3.5k Jan 1, 2023

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files. If multiple configs are benchmarked it will output a file ranking them from fastest to slowest.
 12 May 7, 2022
12 May 7, 2022
Standard implementations of FedLab and its provided benchmarks.
FedLab-benchmarks This repo contains standard implementations of FedLab and its provided benchmarks. Currently, following algorithms or benchrmarks ar
 104 Dec 5, 2022
104 Dec 5, 2022
Sequence modeling benchmarks and temporal convolutional networks
Sequence Modeling Benchmarks and Temporal Convolutional Networks (TCN) This repository contains the experiments done in the work An Empirical Evaluati
3.5k Jan 3, 2023
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
203 Dec 20, 2022
Benchmarks for semi-supervised domain generalization.
Semi-Supervised Domain Generalization This code is the official implementation of the following paper: Semi-Supervised Domain Generalization with Stoc
 49 Dec 10, 2022
49 Dec 10, 2022
This repository contains the implementations related to the experiments of a set of publicly available datasets that are used in the time series forecasting research space.
TSForecasting This repository contains the implementations related to the experiments of a set of publicly available datasets that are used in the tim
 80 Dec 30, 2022
80 Dec 30, 2022
"NAS-Bench-301 and the Case for Surrogate Benchmarks for Neural Architecture Search".
NAS-Bench-301 This repository containts code for the paper: "NAS-Bench-301 and the Case for Surrogate Benchmarks for Neural Architecture Search". The
 57 Nov 30, 2022
57 Nov 30, 2022
![[WWW 2021 GLB] New Benchmarks for Learning on Non-Homophilous Graphs](https://user-images.githubusercontent.com/58995473/113487776-f3665d80-9487-11eb-8035-fbf5126f85df.png)
[WWW 2021 GLB] New Benchmarks for Learning on Non-Homophilous Graphs
New Benchmarks for Learning on Non-Homophilous Graphs Here are the codes and datasets accompanying the paper: New Benchmarks for Learning on Non-Homop
94 Dec 21, 2022
Code and model benchmarks for "SEVIR : A Storm Event Imagery Dataset for Deep Learning Applications in Radar and Satellite Meteorology"
NeurIPS 2020 SEVIR Code for paper: SEVIR : A Storm Event Imagery Dataset for Deep Learning Applications in Radar and Satellite Meteorology Requirement
 46 Dec 15, 2022
46 Dec 15, 2022