574 Repositories
Python bert-onnx-rs-pipeline Libraries
Pretrained EfficientNet, EfficientNet-Lite, MixNet, MobileNetV3 / V2, MNASNet A1 and B1, FBNet, Single-Path NAS
(Generic) EfficientNets for PyTorch A 'generic' implementation of EfficientNet, MixNet, MobileNetV3, etc. that covers most of the compute/parameter ef
 1.5k Jan 1, 2023
1.5k Jan 1, 2023

A GPU-accelerated library containing highly optimized building blocks and an execution engine for data processing to accelerate deep learning training and inference applications.
NVIDIA DALI The NVIDIA Data Loading Library (DALI) is a library for data loading and pre-processing to accelerate deep learning applications. It provi
 4.2k Jan 8, 2023
4.2k Jan 8, 2023

⚡ boost inference speed of T5 models by 5x & reduce the model size by 3x using fastT5.
Reduce T5 model size by 3X and increase the inference speed up to 5X. Install Usage Details Functionalities Benchmarks Onnx model Quantized onnx model
 399 Jan 5, 2023
399 Jan 5, 2023
We have implemented shaDow-GNN as a general and powerful pipeline for graph representation learning. For more details, please find our paper titled Deep Graph Neural Networks with Shallow Subgraph Samplers, available on arXiv (https//arxiv.org/abs/2012.01380).
Deep GNN, Shallow Sampling Hanqing Zeng, Muhan Zhang, Yinglong Xia, Ajitesh Srivastava, Andrey Malevich, Rajgopal Kannan, Viktor Prasanna, Long Jin, R
 117 Dec 20, 2022
117 Dec 20, 2022
An expandable and scalable OCR pipeline
Overview Nidaba is the central controller for the entire OGL OCR pipeline. It oversees and automates the process of converting raw images into citable
 81 Jan 4, 2023
81 Jan 4, 2023

This is a c++ project deploying a deep scene text reading pipeline with tensorflow. It reads text from natural scene images. It uses frozen tensorflow graphs. The detector detect scene text locations. The recognizer reads word from each detected bounding box.
DeepSceneTextReader This is a c++ project deploying a deep scene text reading pipeline. It reads text from natural scene images. Prerequsites The proj
 49 Sep 10, 2022
49 Sep 10, 2022

End-to-end pipeline for real-time scene text detection and recognition.
Real-time-Scene-Text-Detection-and-Recognition-System End-to-end pipeline for real-time scene text detection and recognition. The detection model use
 89 Aug 4, 2022
89 Aug 4, 2022

CUAD
Contract Understanding Atticus Dataset This repository contains code for the Contract Understanding Atticus Dataset (CUAD), a dataset for legal contra
 273 Dec 17, 2022
273 Dec 17, 2022
Contract Understanding Atticus Dataset
Contract Understanding Atticus Dataset This repository contains code for the Contract Understanding Atticus Dataset (CUAD), a dataset for legal contra
273 Dec 17, 2022
Toy example of an applied ML pipeline for me to experiment with MLOps tools.
Toy Machine Learning Pipeline Table of Contents About Getting Started ML task description and evaluation procedure Dataset description Repository stru
 190 Dec 21, 2022
190 Dec 21, 2022
Minimalist BERT implementation assignment for CS11-747
minbert Assignment by Zhengbao Jiang, Shuyan Zhou, and Ritam Dutt This is an exercise in developing a minimalist version of BERT, part of Carnegie Mel
 51 Jan 3, 2023
51 Jan 3, 2023

本项目是作者们根据个人面试和经验总结出的自然语言处理(NLP)面试准备的学习笔记与资料,该资料目前包含 自然语言处理各领域的 面试题积累。
【关于 NLP】那些你不知道的事 作者:杨夕、芙蕖、李玲、陈海顺、twilight、LeoLRH、JimmyDU、艾春辉、张永泰、金金金 介绍 本项目是作者们根据个人面试和经验总结出的自然语言处理(NLP)面试准备的学习笔记与资料,该资料目前包含 自然语言处理各领域的 面试题积累。 目录架构 一、【
 1.4k Dec 30, 2022
1.4k Dec 30, 2022
Code associated with the "Data Augmentation using Pre-trained Transformer Models" paper
Data Augmentation using Pre-trained Transformer Models Code associated with the Data Augmentation using Pre-trained Transformer Models paper Code cont
 44 Dec 31, 2022
44 Dec 31, 2022
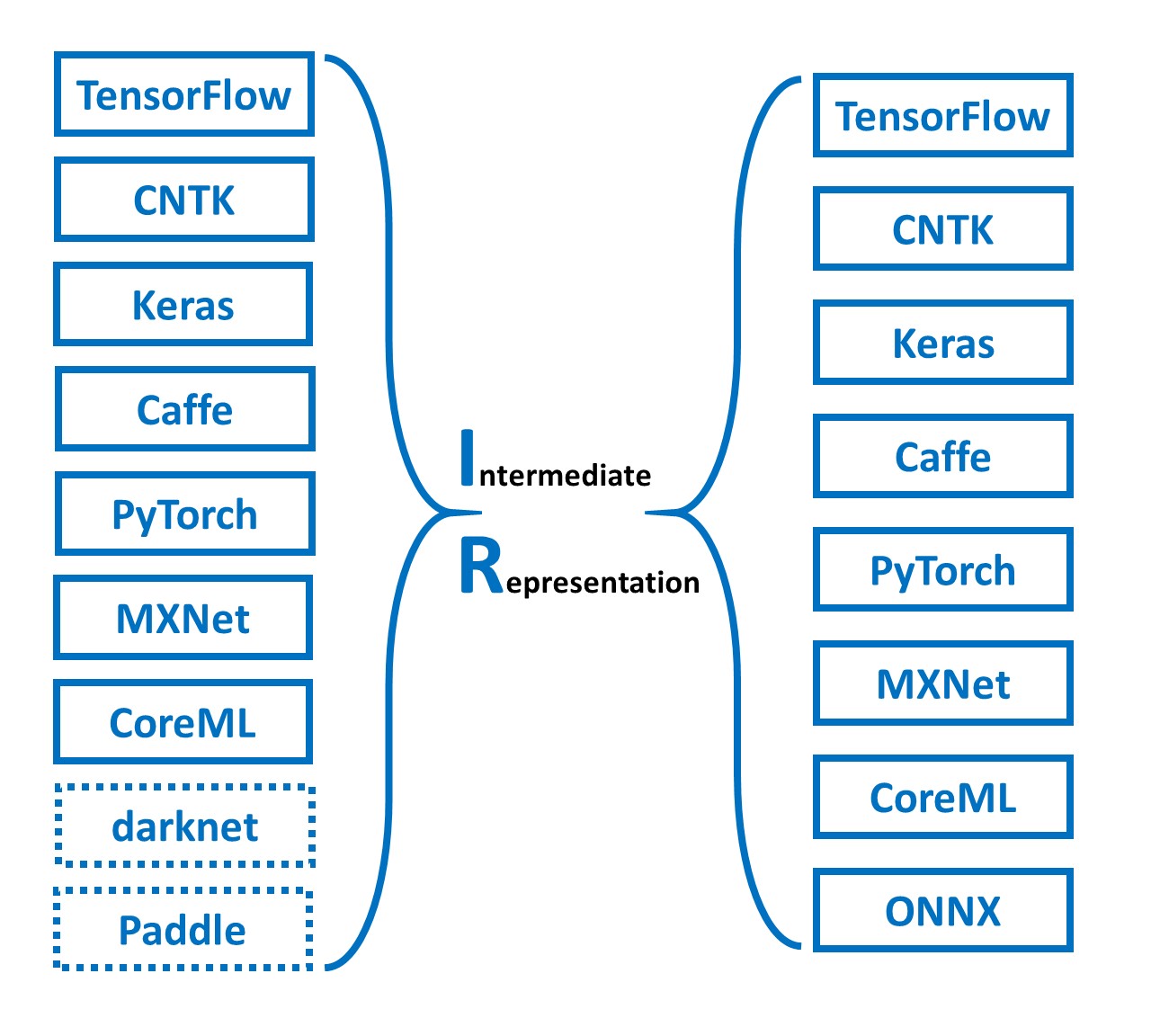
MMdnn is a set of tools to help users inter-operate among different deep learning frameworks. E.g. model conversion and visualization. Convert models between Caffe, Keras, MXNet, Tensorflow, CNTK, PyTorch Onnx and CoreML.
MMdnn MMdnn is a comprehensive and cross-framework tool to convert, visualize and diagnose deep learning (DL) models. The "MM" stands for model manage
 5.7k Jan 9, 2023
5.7k Jan 9, 2023
Open standard for machine learning interoperability
Open Neural Network Exchange (ONNX) is an open ecosystem that empowers AI developers to choose the right tools as their project evolves. ONNX provides
 13.9k Dec 30, 2022
13.9k Dec 30, 2022
BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflows even for datasets that do not fit into memory.
BatchFlow BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflo
 185 Dec 20, 2022
185 Dec 20, 2022
Easy pipelines for pandas DataFrames.
pdpipe ˨ Easy pipelines for pandas DataFrames (learn how!). Website: https://pdpipe.github.io/pdpipe/ Documentation: https://pdpipe.github.io/pdpipe/d
 694 Jan 5, 2023
694 Jan 5, 2023

Visualizer for neural network, deep learning, and machine learning models
Netron is a viewer for neural network, deep learning and machine learning models. Netron supports ONNX (.onnx, .pb, .pbtxt), Keras (.h5, .keras), Tens
 20.9k Dec 28, 2022
20.9k Dec 28, 2022
MLBox is a powerful Automated Machine Learning python library.
MLBox is a powerful Automated Machine Learning python library. It provides the following features: Fast reading and distributed data preprocessing/cle
 1.4k Jan 6, 2023
1.4k Jan 6, 2023
DaCy: The State of the Art Danish NLP pipeline using SpaCy
DaCy: A SpaCy NLP Pipeline for Danish DaCy is a Danish preprocessing pipeline trained in SpaCy. At the time of writing it has achieved State-of-the-Ar
 71 Jan 6, 2023
71 Jan 6, 2023
Data intensive science for everyone.
The latest information about Galaxy can be found on the Galaxy Community Hub. Community support is available at Galaxy Help. Galaxy Quickstart Galaxy
 1k Jan 8, 2023
1k Jan 8, 2023

Summarization, translation, sentiment-analysis, text-generation and more at blazing speed using a T5 version implemented in ONNX.
Summarization, translation, Q&A, text generation and more at blazing speed using a T5 version implemented in ONNX. This package is still in alpha stag
 137 Feb 1, 2021
137 Feb 1, 2021

NeuralQA: A Usable Library for Question Answering on Large Datasets with BERT
NeuralQA: A Usable Library for (Extractive) Question Answering on Large Datasets with BERT Still in alpha, lots of changes anticipated. View demo on n
 184 Feb 10, 2021
184 Feb 10, 2021
Translate - a PyTorch Language Library
NOTE PyTorch Translate is now deprecated, please use fairseq instead. Translate - a PyTorch Language Library Translate is a library for machine transl
 678 Feb 15, 2021
678 Feb 15, 2021
Kashgari is a production-level NLP Transfer learning framework built on top of tf.keras for text-labeling and text-classification, includes Word2Vec, BERT, and GPT2 Language Embedding.
Kashgari Overview | Performance | Installation | Documentation | Contributing 🎉 🎉 🎉 We released the 2.0.0 version with TF2 Support. 🎉 🎉 🎉 If you
 2k Feb 9, 2021
2k Feb 9, 2021
:house_with_garden: Fast & easy transfer learning for NLP. Harvesting language models for the industry. Focus on Question Answering.
(Framework for Adapting Representation Models) What is it? FARM makes Transfer Learning with BERT & Co simple, fast and enterprise-ready. It's built u
 1.1k Feb 14, 2021
1.1k Feb 14, 2021
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
 2.1k Feb 13, 2021
2.1k Feb 13, 2021
Toolkit for Machine Learning, Natural Language Processing, and Text Generation, in TensorFlow. This is part of the CASL project: http://casl-project.ai/
Texar is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar provides
 2.1k Feb 17, 2021
2.1k Feb 17, 2021
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.6k Feb 18, 2021
2.6k Feb 18, 2021

Super easy library for BERT based NLP models
Fast-Bert New - Learning Rate Finder for Text Classification Training (borrowed with thanks from https://github.com/davidtvs/pytorch-lr-finder) Suppor
 1.5k Feb 18, 2021
1.5k Feb 18, 2021
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
 831 Feb 17, 2021
831 Feb 17, 2021
🛸 Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy
spacy-transformers: Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy This package provides spaCy components and architectures to use tr
 903 Feb 17, 2021
903 Feb 17, 2021
✨Fast Coreference Resolution in spaCy with Neural Networks
✨ NeuralCoref 4.0: Coreference Resolution in spaCy with Neural Networks. NeuralCoref is a pipeline extension for spaCy 2.1+ which annotates and resolv
 2.2k Feb 18, 2021
2.2k Feb 18, 2021
:mag: End-to-End Framework for building natural language search interfaces to data by utilizing Transformers and the State-of-the-Art of NLP. Supporting DPR, Elasticsearch, HuggingFace’s Modelhub and much more!
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
1.4k Feb 18, 2021
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
 1.9k Feb 18, 2021
1.9k Feb 18, 2021
Sentence Embeddings with BERT & XLNet
Sentence Transformers: Multilingual Sentence Embeddings using BERT / RoBERTa / XLM-RoBERTa & Co. with PyTorch This framework provides an easy method t
 4.2k Feb 18, 2021
4.2k Feb 18, 2021
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production
Provides an implementation of today's most used tokenizers, with a focus on performance and versatility. Main features: Train new vocabularies and tok
4.3k Feb 18, 2021
🤗Transformers: State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0.
State-of-the-art Natural Language Processing for PyTorch and TensorFlow 2.0 🤗 Transformers provides thousands of pretrained models to perform tasks o
40.9k Feb 18, 2021
An audio digital processing toolbox based on a workflow/pipeline principle
AudioTK Audio ToolKit is a set of audio filters. It helps assembling workflows for specific audio processing workloads. The audio workflow is split in
 238 Oct 18, 2022
238 Oct 18, 2022
InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective
InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective This is the official code base for our ICLR 2021 paper
 71 Nov 25, 2022
71 Nov 25, 2022
PipeLayer is a lightweight Python pipeline framework
PipeLayer is a lightweight Python pipeline framework. Define a series of steps, and chain them together to create modular applications
 64 Jul 21, 2022
64 Jul 21, 2022
Summarization, translation, sentiment-analysis, text-generation and more at blazing speed using a T5 version implemented in ONNX.
Summarization, translation, Q&A, text generation and more at blazing speed using a T5 version implemented in ONNX. This package is still in alpha stag
211 Dec 28, 2022
NeuralQA: A Usable Library for Question Answering on Large Datasets with BERT
NeuralQA: A Usable Library for (Extractive) Question Answering on Large Datasets with BERT Still in alpha, lots of changes anticipated. View demo on n
220 Dec 11, 2022
Translate - a PyTorch Language Library
NOTE PyTorch Translate is now deprecated, please use fairseq instead. Translate - a PyTorch Language Library Translate is a library for machine transl
775 Dec 24, 2022
Kashgari is a production-level NLP Transfer learning framework built on top of tf.keras for text-labeling and text-classification, includes Word2Vec, BERT, and GPT2 Language Embedding.
Kashgari Overview | Performance | Installation | Documentation | Contributing 🎉 🎉 🎉 We released the 2.0.0 version with TF2 Support. 🎉 🎉 🎉 If you
2.3k Dec 29, 2022
:house_with_garden: Fast & easy transfer learning for NLP. Harvesting language models for the industry. Focus on Question Answering.
(Framework for Adapting Representation Models) What is it? FARM makes Transfer Learning with BERT & Co simple, fast and enterprise-ready. It's built u
1.6k Dec 27, 2022
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
2.7k Jan 8, 2023
Toolkit for Machine Learning, Natural Language Processing, and Text Generation, in TensorFlow. This is part of the CASL project: http://casl-project.ai/
Texar is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar provides
2.3k Jan 7, 2023
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
2.9k Jan 2, 2023
Super easy library for BERT based NLP models
Fast-Bert New - Learning Rate Finder for Text Classification Training (borrowed with thanks from https://github.com/davidtvs/pytorch-lr-finder) Suppor
1.8k Dec 27, 2022
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
1.3k Jan 3, 2023
🛸 Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy
spacy-transformers: Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy This package provides spaCy components and architectures to use tr
1.2k Jan 8, 2023
✨Fast Coreference Resolution in spaCy with Neural Networks
✨ NeuralCoref 4.0: Coreference Resolution in spaCy with Neural Networks. NeuralCoref is a pipeline extension for spaCy 2.1+ which annotates and resolv
2.6k Jan 4, 2023
:mag: Transformers at scale for question answering & neural search. Using NLP via a modular Retriever-Reader-Pipeline. Supporting DPR, Elasticsearch, HuggingFace's Modelhub...
Haystack is an end-to-end framework for Question Answering & Neural search that enables you to ... ... ask questions in natural language and find gran
6.4k Jan 9, 2023
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
3k Jan 5, 2023
Sentence Embeddings with BERT & XLNet
Sentence Transformers: Multilingual Sentence Embeddings using BERT / RoBERTa / XLM-RoBERTa & Co. with PyTorch This framework provides an easy method t
9.1k Jan 2, 2023
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production
Provides an implementation of today's most used tokenizers, with a focus on performance and versatility. Main features: Train new vocabularies and tok
6.2k Dec 31, 2022
🤗Transformers: State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0.
State-of-the-art Natural Language Processing for PyTorch and TensorFlow 2.0 🤗 Transformers provides thousands of pretrained models to perform tasks o
77.3k Jan 3, 2023
Machine learning framework for both deep learning and traditional algorithms
NeoML is an end-to-end machine learning framework that allows you to build, train, and deploy ML models. This framework is used by ABBYY engineers for
 704 Dec 27, 2022
704 Dec 27, 2022
MongoDB data stream pipeline tools by YouGov (adopted from MongoDB)
mongo-connector The mongo-connector project originated as a MongoDB mongo-labs project and is now community-maintained under the custody of YouGov, Pl
 1.9k Jan 4, 2023
1.9k Jan 4, 2023
Pipeline is an asset packaging library for Django.
Pipeline Pipeline is an asset packaging library for Django, providing both CSS and JavaScript concatenation and compression, built-in JavaScript templ
 1.4k Jan 3, 2023
1.4k Jan 3, 2023

NLP Core Library and Model Zoo based on PaddlePaddle 2.0
PaddleNLP 2.0拥有丰富的模型库、简洁易用的API与高性能的分布式训练的能力,旨在为飞桨开发者提升文本建模效率,并提供基于PaddlePaddle 2.0的NLP领域最佳实践。
 6.9k Jan 1, 2023
6.9k Jan 1, 2023

天池中药说明书实体识别挑战冠军方案;中文命名实体识别;NER; BERT-CRF & BERT-SPAN & BERT-MRC;Pytorch
天池中药说明书实体识别挑战冠军方案;中文命名实体识别;NER; BERT-CRF & BERT-SPAN & BERT-MRC;Pytorch
 751 Dec 30, 2022
751 Dec 30, 2022
Big Bird: Transformers for Longer Sequences
BigBird, is a sparse-attention based transformer which extends Transformer based models, such as BERT to much longer sequences. Moreover, BigBird comes along with a theoretical understanding of the capabilities of a complete transformer that the sparse model can handle.
 457 Dec 23, 2022
457 Dec 23, 2022

PhoNLP: A BERT-based multi-task learning toolkit for part-of-speech tagging, named entity recognition and dependency parsing
PhoNLP is a multi-task learning model for joint part-of-speech (POS) tagging, named entity recognition (NER) and dependency parsing. Experiments on Vietnamese benchmark datasets show that PhoNLP produces state-of-the-art results, outperforming a single-task learning approach that fine-tunes the pre-trained Vietnamese language model PhoBERT for each task independently.
 109 Dec 2, 2022
109 Dec 2, 2022
Soda SQL Data testing, monitoring and profiling for SQL accessible data.
Soda SQL Data testing, monitoring and profiling for SQL accessible data. What does Soda SQL do? Soda SQL allows you to Stop your pipeline when bad dat
 51 Jan 1, 2023
51 Jan 1, 2023
Code of paper: A Recurrent Vision-and-Language BERT for Navigation
Recurrent VLN-BERT Code of the Recurrent-VLN-BERT paper: A Recurrent Vision-and-Language BERT for Navigation Yicong Hong, Qi Wu, Yuankai Qi, Cristian
 109 Dec 21, 2022
109 Dec 21, 2022
CCF BDCI 2020 房产行业聊天问答匹配赛道 A榜47/2985
CCF BDCI 2020 房产行业聊天问答匹配 A榜47/2985 赛题描述详见:https://www.datafountain.cn/competitions/474 文件说明 data: 存放训练数据和测试数据以及预处理代码 model_bert.py: 网络模型结构定义 adv_train
 40 Sep 28, 2022
40 Sep 28, 2022
Reinforcement Learning Coach by Intel AI Lab enables easy experimentation with state of the art Reinforcement Learning algorithms
Coach Coach is a python reinforcement learning framework containing implementation of many state-of-the-art algorithms. It exposes a set of easy-to-us
2.2k Jan 5, 2023
Pipeline is an asset packaging library for Django.
Pipeline Pipeline is an asset packaging library for Django, providing both CSS and JavaScript concatenation and compression, built-in JavaScript templ
1.4k Dec 26, 2022

Automates Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning :rocket:
MLJAR Automated Machine Learning Documentation: https://supervised.mljar.com/ Source Code: https://github.com/mljar/mljar-supervised Table of Contents
 2.4k Dec 31, 2022
2.4k Dec 31, 2022
A Sklearn-like Framework for Hyperparameter Tuning and AutoML in Deep Learning projects. Finally have the right abstractions and design patterns to properly do AutoML. Let your pipeline steps have hyperparameter spaces. Enable checkpoints to cut duplicate calculations. Go from research to production environment easily.
Neuraxle Pipelines Code Machine Learning Pipelines - The Right Way. Neuraxle is a Machine Learning (ML) library for building machine learning pipeline
 555 Dec 24, 2022
555 Dec 24, 2022
Visualizer for neural network, deep learning, and machine learning models
Netron is a viewer for neural network, deep learning and machine learning models. Netron supports ONNX (.onnx, .pb, .pbtxt), Keras (.h5, .keras), Tens
21k Jan 6, 2023
Lightweight, Python library for fast and reproducible experimentation :microscope:
Steppy What is Steppy? Steppy is a lightweight, open-source, Python 3 library for fast and reproducible experimentation. Steppy lets data scientist fo
 134 Jul 10, 2022
134 Jul 10, 2022