574 Repositories
Python bert-onnx-rs-pipeline Libraries
Pipeline for fast building text classification TF-IDF + LogReg baselines.
Text Classification Baseline Pipeline for fast building text classification TF-IDF + LogReg baselines. Usage Instead of writing custom code for specif
 57 Dec 7, 2022
57 Dec 7, 2022

CPOST is a CLI tool to assist with the proper sizing of Clara Deploy pipelines
CPOST (Clara Pipeline Operator Sizing Tool) Tool to measure resource usage of Clara Platform pipeline operators Cpost is a tool that will help you run
 5 Sep 27, 2021
5 Sep 27, 2021
Convert Apple NeuralHash model for CSAM Detection to ONNX.
Apple NeuralHash is a perceptual hashing method for images based on neural networks. It can tolerate image resize and compression.
 1.5k Dec 31, 2022
1.5k Dec 31, 2022
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023

The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
The tl;dr on a few notable transformer/language model papers + other papers (alignment, memorization, etc).
 166 Jan 4, 2023
166 Jan 4, 2023
Learn meanings behind words is a key element in NLP. This project concentrates on the disambiguation of preposition senses. Therefore, we train a bert-transformer model and surpass the state-of-the-art.
New State-of-the-Art in Preposition Sense Disambiguation Supervisor: Prof. Dr. Alexander Mehler Alexander Henlein Institutions: Goethe University TTLa
 4 Apr 6, 2022
4 Apr 6, 2022
This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, reading data from PubSub.
Sample streaming Dataflow pipeline written in Python This repository contains a streaming Dataflow pipeline written in Python with Apache Beam, readin
 9 Mar 18, 2022
9 Mar 18, 2022
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023
A DNN inference latency prediction toolkit for accurately modeling and predicting the latency on diverse edge devices.
Note: This is an alpha (preview) version which is still under refining. nn-Meter is a novel and efficient system to accurately predict the inference l
 244 Jan 6, 2023
244 Jan 6, 2023

Using VideoBERT to tackle video prediction
VideoBERT This repo reproduces the results of VideoBERT (https://arxiv.org/pdf/1904.01766.pdf). Inspiration was taken from https://github.com/MDSKUL/M
 75 Dec 14, 2022
75 Dec 14, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023
LightSeq is a high performance training and inference library for sequence processing and generation implemented in CUDA
LightSeq: A High Performance Library for Sequence Processing and Generation
 2.5k Jan 6, 2023
2.5k Jan 6, 2023
nn-Meter is a novel and efficient system to accurately predict the inference latency of DNN models on diverse edge devices
A DNN inference latency prediction toolkit for accurately modeling and predicting the latency on diverse edge devices.
241 Dec 26, 2022

End-to-end text to speech system using gruut and onnx. There are 40 voices available across 8 languages.
End to end text to speech system using gruut and onnx
 673 Dec 28, 2022
673 Dec 28, 2022

A robust pointcloud registration pipeline based on correlation.
PHASER: A Robust and Correspondence-Free Global Pointcloud Registration Ubuntu 18.04+ROS Melodic: Overview Pointcloud registration using correspondenc
 101 Dec 1, 2022
101 Dec 1, 2022

Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
 49 Nov 25, 2022
49 Nov 25, 2022
Finetuning Pipeline
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022

Punctuation Restoration using Transformer Models for High-and Low-Resource Languages
Punctuation Restoration using Transformer Models This repository contins official implementation of the paper Punctuation Restoration using Transforme
 142 Jan 1, 2023
142 Jan 1, 2023
This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust.
Demo BERT ONNX pipeline written in rust This demo showcase the use of onnxruntime-rs with a GPU on CUDA 11 to run Bert in a data pipeline with Rust. R
 14 Dec 17, 2022
14 Dec 17, 2022

PyTorch implementation of the YOLO (You Only Look Once) v2
PyTorch implementation of the YOLO (You Only Look Once) v2 The YOLOv2 is one of the most popular one-stage object detector. This project adopts PyTorc
 433 Nov 24, 2022
433 Nov 24, 2022
Implementing SimCSE(paper, official repository) using TensorFlow 2 and KR-BERT.
KR-BERT-SimCSE Implementing SimCSE(paper, official repository) using TensorFlow 2 and KR-BERT. Training Unsupervised python train_unsupervised.py --mi
 27 Dec 12, 2022
27 Dec 12, 2022
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
47 Sep 5, 2022

Learned Token Pruning for Transformers
LTP: Learned Token Pruning for Transformers Check our paper for more details. Installation We follow the same installation procedure as the original H
 52 Dec 29, 2022
52 Dec 29, 2022
YOLOX is a high-performance anchor-free YOLO, exceeding yolov3~v5 with ONNX, TensorRT, ncnn, and OpenVINO supported.
Introduction YOLOX is an anchor-free version of YOLO, with a simpler design but better performance! It aims to bridge the gap between research and ind
 7.7k Jan 3, 2023
7.7k Jan 3, 2023
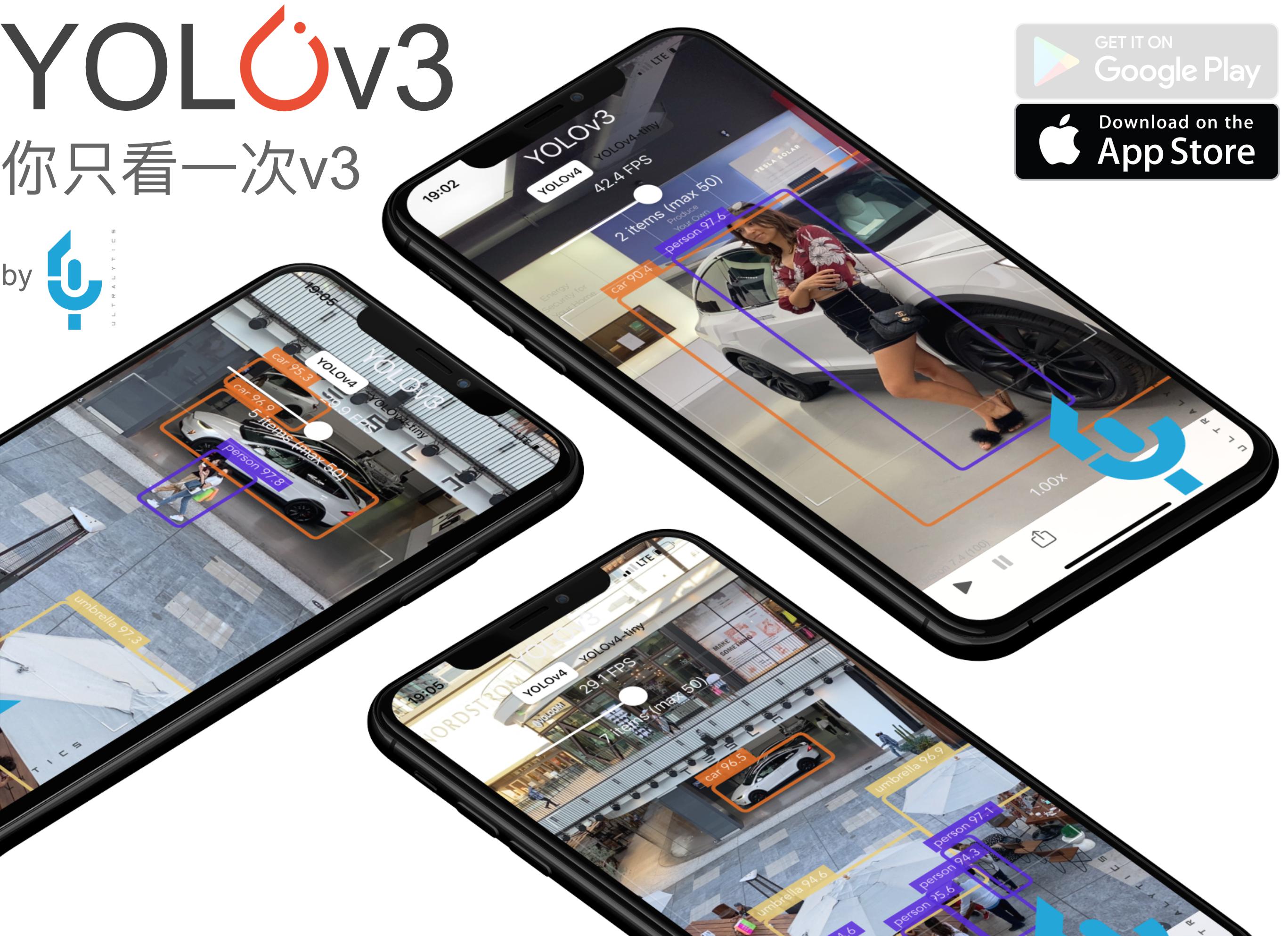
YOLOv3 in PyTorch ONNX CoreML TFLite
This repository represents Ultralytics open-source research into future object detection methods, and incorporates lessons learned and best practices
 9.3k Jan 7, 2023
9.3k Jan 7, 2023
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 3, 2023
77.2k Jan 3, 2023
A high-performance anchor-free YOLO. Exceeding yolov3~v5 with ONNX, TensorRT, NCNN, and Openvino supported.
YOLOX is an anchor-free version of YOLO, with a simpler design but better performance! It aims to bridge the gap between research and industrial communities. For more details, please refer to our report on Arxiv.
7.7k Jan 6, 2023

A heterogeneous entity-augmented academic language model based on Open Academic Graph (OAG)
Library | Paper | Slack We released two versions of OAG-BERT in CogDL package. OAG-BERT is a heterogeneous entity-augmented academic language model wh
 58 Dec 17, 2022
58 Dec 17, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 43 Nov 21, 2022
43 Nov 21, 2022

Official repository for the paper, MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding.
MidiBERT-Piano Authors: Yi-Hui (Sophia) Chou, I-Chun (Bronwin) Chen Introduction This is the official repository for the paper, MidiBERT-Piano: Large-
 137 Dec 15, 2022
137 Dec 15, 2022
ONNX Runtime for PyTorch accelerates PyTorch model training using ONNX Runtime.
Accelerate PyTorch models with ONNX Runtime
 270 Dec 24, 2022
270 Dec 24, 2022

Export CenterPoint PonintPillars ONNX Model For TensorRT
CenterPoint-PonintPillars Pytroch model convert to ONNX and TensorRT Welcome to CenterPoint! This project is fork from tianweiy/CenterPoint. I impleme
 149 Dec 13, 2022
149 Dec 13, 2022

VD-BERT: A Unified Vision and Dialog Transformer with BERT
VD-BERT: A Unified Vision and Dialog Transformer with BERT PyTorch Code for the following paper at EMNLP2020: Title: VD-BERT: A Unified Vision and Dia
 44 Nov 1, 2022
44 Nov 1, 2022
Recognize Handwritten Digits using Deep Learning on the browser itself.
MNIST on the Web An attempt to predict MNIST handwritten digits from my PyTorch model from the browser (client-side) and not from the server, with the
 7 May 28, 2022
7 May 28, 2022
VD-BERT: A Unified Vision and Dialog Transformer with BERT
VD-BERT: A Unified Vision and Dialog Transformer with BERT PyTorch Code for the following paper at EMNLP2020: Title: VD-BERT: A Unified Vision and Dia
44 Nov 1, 2022

Distributed DataLoader For Pytorch Based On Ray
Dpex——用户无感知分布式数据预处理组件 一、前言 随着GPU与CPU的算力差距越来越大以及模型训练时的预处理Pipeline变得越来越复杂,CPU部分的数据预处理已经逐渐成为了模型训练的瓶颈所在,这导致单机的GPU配置的提升并不能带来期望的线性加速。预处理性能瓶颈的本质在于每个GPU能够使用的C
 23 Nov 2, 2022
23 Nov 2, 2022
Huggingface Transformers + Adapters = ❤️
adapter-transformers A friendly fork of HuggingFace's Transformers, adding Adapters to PyTorch language models adapter-transformers is an extension of
 1.2k Jan 9, 2023
1.2k Jan 9, 2023

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
The source codes for ACL 2021 paper 'BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data'
BoB: BERT Over BERT for Training Persona-based Dialogue Models from Limited Personalized Data This repository provides the implementation details for
 124 Dec 27, 2022
124 Dec 27, 2022
PyTorch impelementations of BERT-based Spelling Error Correction Models
PyTorch impelementations of BERT-based Spelling Error Correction Models
 59 Jun 29, 2021
59 Jun 29, 2021
PyTorch impelementations of BERT-based Spelling Error Correction Models.
PyTorch impelementations of BERT-based Spelling Error Correction Models. 基于BERT的文本纠错模型,使用PyTorch实现。
209 Dec 30, 2022

A BERT-based reverse-dictionary of Korean proverbs
Wisdomify A BERT-based reverse-dictionary of Korean proverbs. 김유빈 : 모델링 / 데이터 수집 / 프로젝트 설계 / back-end 김종윤 : 데이터 수집 / 프로젝트 설계 / front-end Quick Start C
 94 Dec 8, 2022
94 Dec 8, 2022
LV-BERT: Exploiting Layer Variety for BERT (Findings of ACL 2021)
LV-BERT Introduction In this repo, we introduce LV-BERT by exploiting layer variety for BERT. For detailed description and experimental results, pleas
 14 Aug 24, 2022
14 Aug 24, 2022
TorchX is a library containing standard DSLs for authoring and running PyTorch related components for an E2E production ML pipeline.
TorchX is a library containing standard DSLs for authoring and running PyTorch related components for an E2E production ML pipeline
193 Dec 22, 2022
LV-BERT: Exploiting Layer Variety for BERT (Findings of ACL 2021)
LV-BERT Introduction In this repo, we introduce LV-BERT by exploiting layer variety for BERT. For detailed description and experimental results, pleas
14 Aug 24, 2022

TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset.
TunBERT is the first release of a pre-trained BERT model for the Tunisian dialect using a Tunisian Common-Crawl-based dataset. TunBERT was applied to three NLP downstream tasks: Sentiment Analysis (SA), Tunisian Dialect Identification (TDI) and Reading Comprehension Question-Answering (RCQA)
 72 Dec 9, 2022
72 Dec 9, 2022

This repository contains the code for our fast polygonal building extraction from overhead images pipeline.
Polygonal Building Segmentation by Frame Field Learning We add a frame field output to an image segmentation neural network to improve segmentation qu
 186 Jan 4, 2023
186 Jan 4, 2023

This repository contains all the source code that is needed for the project : An Efficient Pipeline For Bloom’s Taxonomy Using Natural Language Processing and Deep Learning
Pipeline For NLP with Bloom's Taxonomy Using Improved Question Classification and Question Generation using Deep Learning This repository contains all
 9 Jul 17, 2021
9 Jul 17, 2021
Pipeline for chemical image-to-text competition
BMS-Molecular-Translation Introduction This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got
 7 Sep 20, 2022
7 Sep 20, 2022
Python Implementation of ``Modeling the Influence of Verb Aspect on the Activation of Typical Event Locations with BERT'' (Findings of ACL: ACL 2021)
BERT-for-Surprisal Python Implementation of ``Modeling the Influence of Verb Aspect on the Activation of Typical Event Locations with BERT'' (Findings
 7 Dec 5, 2022
7 Dec 5, 2022
Baseline code for Korean open domain question answering(ODQA)
Open-Domain Question Answering(ODQA)는 다양한 주제에 대한 문서 집합으로부터 자연어 질의에 대한 답변을 찾아오는 task입니다. 이때 사용자 질의에 답변하기 위해 주어지는 지문이 따로 존재하지 않습니다. 따라서 사전에 구축되어있는 Knowl
 69 Nov 4, 2022
69 Nov 4, 2022
Evaluation Pipeline for our ECCV2020: Journey Towards Tiny Perceptual Super-Resolution.
Journey Towards Tiny Perceptual Super-Resolution Test code for our ECCV2020 paper: https://arxiv.org/abs/2007.04356 Our x4 upscaling pre-trained model
 6 Mar 30, 2022
6 Mar 30, 2022

The official implementation of You Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient.
You Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient (paper) @misc{zhang2021compress,
 46 Dec 7, 2022
46 Dec 7, 2022

Source code for NAACL 2021 paper "TR-BERT: Dynamic Token Reduction for Accelerating BERT Inference"
TR-BERT Source code and dataset for "TR-BERT: Dynamic Token Reduction for Accelerating BERT Inference". The code is based on huggaface's transformers.
 37 Oct 30, 2022
37 Oct 30, 2022
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022
tf2onnx - Convert TensorFlow, Keras and Tflite models to ONNX.
tf2onnx converts TensorFlow (tf-1.x or tf-2.x), tf.keras and tflite models to ONNX via command line or python api.
 1.8k Jan 8, 2023
1.8k Jan 8, 2023
SparseML is a libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models
SparseML is a toolkit that includes APIs, CLIs, scripts and libraries that apply state-of-the-art sparsification algorithms such as pruning and quantization to any neural network. General, recipe-driven approaches built around these algorithms enable the simplification of creating faster and smaller models for the ML performance community at large.
 1.5k Dec 30, 2022
1.5k Dec 30, 2022

Clairvoyance: a Unified, End-to-End AutoML Pipeline for Medical Time Series
Clairvoyance: A Pipeline Toolkit for Medical Time Series Authors: van der Schaar Lab This repository contains implementations of Clairvoyance: A Pipel
 89 Dec 7, 2022
89 Dec 7, 2022

Code for the ACL2021 paper "Lexicon Enhanced Chinese Sequence Labelling Using BERT Adapter"
Lexicon Enhanced Chinese Sequence Labeling Using BERT Adapter Code and checkpoints for the ACL2021 paper "Lexicon Enhanced Chinese Sequence Labelling
 274 Dec 6, 2022
274 Dec 6, 2022
Guide & Examples to create deeplearning gstreamer plugins and use them in your pipeline
upai-gst-dl-plugins Guide & Examples to create deeplearning gstreamer plugins and use them in your pipeline Introduction Thanks to the work done by @j
 11 Dec 11, 2022
11 Dec 11, 2022

A declarative Kubeflow Management Tool inspired by Terraform
🍭 KRSH is Alpha version, so many bugs can be reported. If you find a bug, please write an Issue and grow the project together! A declarative Kubeflow
 128 Oct 18, 2022
128 Oct 18, 2022
(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
248 Dec 4, 2022
Procedural 3D data generation pipeline for architecture
Synthetic Dataset Generator Authors: Stanislava Fedorova Alberto Tono Meher Shashwat Nigam Jiayao Zhang Amirhossein Ahmadnia Cecilia bolognesi Dominik
49 Nov 25, 2022
A code generator from ONNX to PyTorch code
onnx-pytorch Generating pytorch code from ONNX. Currently support onnx==1.9.0 and torch==1.8.1. Installation From PyPI pip install onnx-pytorch From
 94 Jan 6, 2023
94 Jan 6, 2023
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
44 Jan 6, 2023
![[CVPR-2021] UnrealPerson: An adaptive pipeline for costless person re-identification](https://github.com/FlyHighest/UnrealPerson/raw/main/imgs/unrealperson.jpg)
[CVPR-2021] UnrealPerson: An adaptive pipeline for costless person re-identification
UnrealPerson: An Adaptive Pipeline for Costless Person Re-identification In our paper (arxiv), we propose a novel pipeline, UnrealPerson, that decreas
 70 Oct 10, 2022
70 Oct 10, 2022

This is a repository for the Duke University Cloud Computing course project on Serveless Data Engineering Pipeline. For this project, I recreated the below pipeline.
AWS Data Engineering Pipeline This is a repository for the Duke University Cloud Computing course project on Serverless Data Engineering Pipeline. For
 15 Jul 28, 2021
15 Jul 28, 2021
Train 🤗transformers with DeepSpeed: ZeRO-2, ZeRO-3
Fork from https://github.com/huggingface/transformers/tree/86d5fb0b360e68de46d40265e7c707fe68c8015b/examples/pytorch/language-modeling at 2021.05.17.
 12 Oct 26, 2022
12 Oct 26, 2022
![[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.](https://github.com/cambridgeltl/sapbert/raw/main/sapbert_front_graphs_v6.png?raw=true)
[NAACL & ACL 2021] SapBERT: Self-alignment pretraining for BERT.
SapBERT: Self-alignment pretraining for BERT This repo holds code for the SapBERT model presented in our NAACL 2021 paper: Self-Alignment Pretraining
 104 Dec 7, 2022
104 Dec 7, 2022

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022
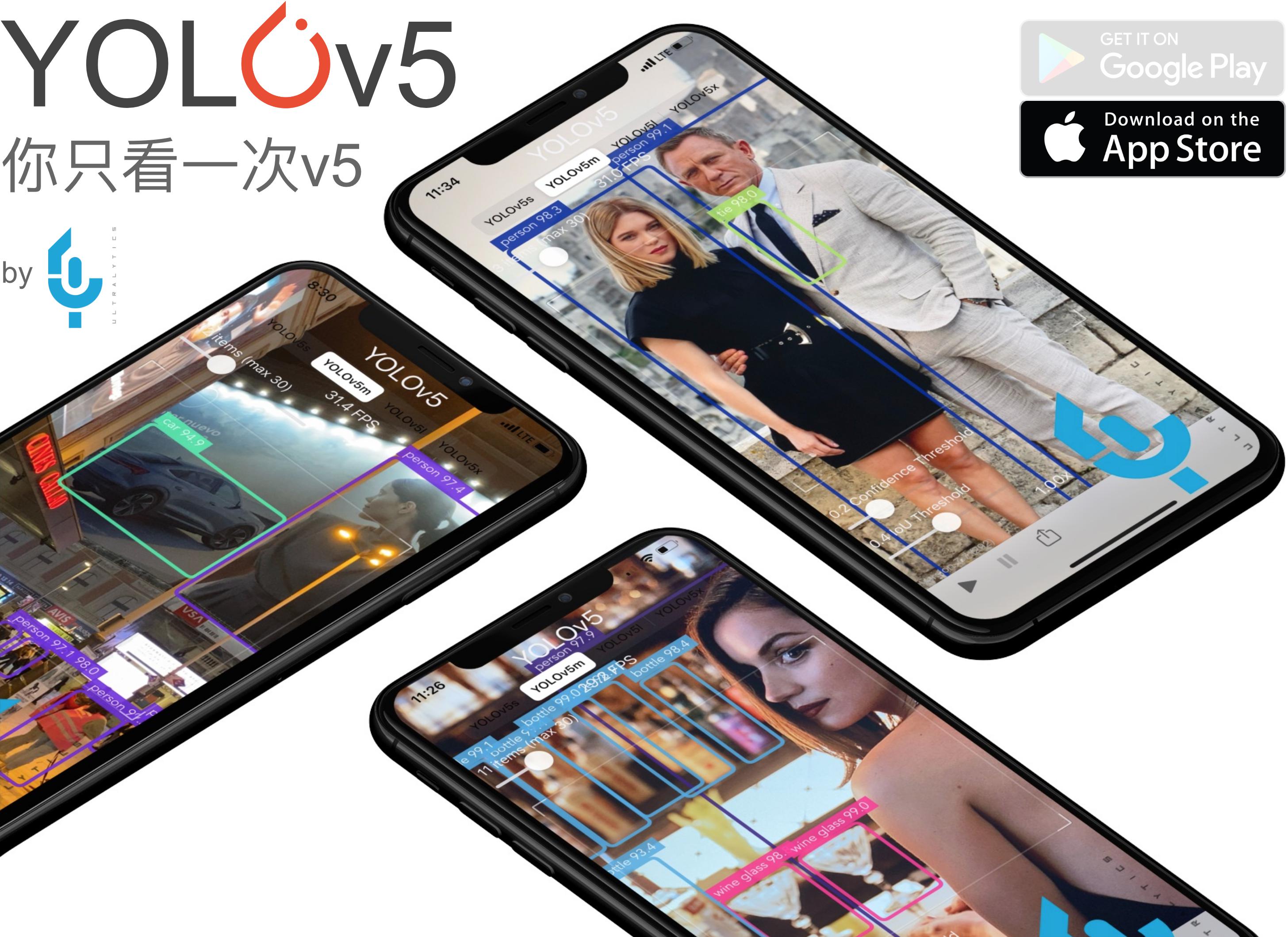
YOLOv5 in PyTorch ONNX CoreML TFLite
This repository represents Ultralytics open-source research into future object detection methods, and incorporates lessons learned and best practices evolved over thousands of hours of training and evolution on anonymized client datasets. All code and models are under active development, and are subject to modification or deletion without notice.
34.1k Dec 31, 2022
Integrating the Best of TF into PyTorch, for Machine Learning, Natural Language Processing, and Text Generation. This is part of the CASL project: http://casl-project.ai/
Texar-PyTorch is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar
 726 Dec 30, 2022
726 Dec 30, 2022

Pytorch-Named-Entity-Recognition-with-BERT
BERT NER Use google BERT to do CoNLL-2003 NER ! Train model using Python and Inference using C++ ALBERT-TF2.0 BERT-NER-TENSORFLOW-2.0 BERT-SQuAD Requi
 1.1k Dec 25, 2022
1.1k Dec 25, 2022
Google AI 2018 BERT pytorch implementation
BERT-pytorch Pytorch implementation of Google AI's 2018 BERT, with simple annotation BERT 2018 BERT: Pre-training of Deep Bidirectional Transformers f
 5.3k Jan 7, 2023
5.3k Jan 7, 2023
jiant is an NLP toolkit
jiant is an NLP toolkit The multitask and transfer learning toolkit for natural language processing research Why should I use jiant? jiant supports mu
 1.5k Jan 4, 2023
1.5k Jan 4, 2023
PyTorch ,ONNX and TensorRT implementation of YOLOv4
PyTorch ,ONNX and TensorRT implementation of YOLOv4
 4.2k Jan 1, 2023
4.2k Jan 1, 2023
Codes for our paper "SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge" (EMNLP 2020)
SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge Introduction SentiLARE is a sentiment-aware pre-trained language
 74 Dec 30, 2022
74 Dec 30, 2022

QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
 152 Jan 2, 2023
152 Jan 2, 2023
An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models.
DeepNER An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models. This repository contains complex Deep
 9 May 30, 2022
9 May 30, 2022
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
QuickAI is a Python library that makes it extremely easy to experiment with state-of-the-art Machine Learning models.
152 Jan 2, 2023
LightSeq: A High-Performance Inference Library for Sequence Processing and Generation
LightSeq is a high performance inference library for sequence processing and generation implemented in CUDA. It enables highly efficient computation of modern NLP models such as BERT, GPT2, Transformer, etc. It is therefore best useful for Machine Translation, Text Generation, Dialog, Language Modelling, and other related tasks using these models.
2.5k Jan 3, 2023

 387 Jan 4, 2023
387 Jan 4, 2023
Code for the paper "Improving Vision-and-Language Navigation with Image-Text Pairs from the Web" (ECCV 2020)
Improving Vision-and-Language Navigation with Image-Text Pairs from the Web Arjun Majumdar, Ayush Shrivastava, Stefan Lee, Peter Anderson, Devi Parikh
 44 Dec 14, 2022
44 Dec 14, 2022
Focus on Algorithm Design, Not on Data Wrangling
The dataTap Python library is the primary interface for using dataTap's rich data management tools. Create datasets, stream annotations, and analyze model performance all with one library.
 37 Nov 25, 2022
37 Nov 25, 2022

Educational project on how to build an ETL (Extract, Transform, Load) data pipeline, orchestrated with Airflow.
ETL Pipeline with Airflow, Spark, s3, MongoDB and Amazon Redshift
 214 Jan 2, 2023
214 Jan 2, 2023
Pytorch version of BERT-whitening
BERT-whitening This is the Pytorch implementation of "Whitening Sentence Representations for Better Semantics and Faster Retrieval". BERT-whitening is
 255 Dec 27, 2022
255 Dec 27, 2022
Weakly supervised medical named entity classification
Trove Trove is a research framework for building weakly supervised (bio)medical named entity recognition (NER) and other entity attribute classifiers
 60 Nov 18, 2022
60 Nov 18, 2022

Python library containing BART query generation and BERT-based Siamese models for neural retrieval.
Neural Retrieval Embedding-based Zero-shot Retrieval through Query Generation leverages query synthesis over large corpuses of unlabeled text (such as
 35 Apr 14, 2022
35 Apr 14, 2022

I-BERT: Integer-only BERT Quantization
I-BERT: Integer-only BERT Quantization HuggingFace Implementation I-BERT is also available in the master branch of HuggingFace! Visit the following li
139 Dec 27, 2022

Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
Tool for visualizing attention in the Transformer model (BERT, GPT-2, Albert, XLNet, RoBERTa, CTRL, etc.)
 4.7k Jan 1, 2023
4.7k Jan 1, 2023
Code for pre-training CharacterBERT models (as well as BERT models).
Pre-training CharacterBERT (and BERT) This is a repository for pre-training BERT and CharacterBERT. DISCLAIMER: The code was largely adapted from an o
 31 Dec 5, 2022
31 Dec 5, 2022

Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT
CheXbert: Combining Automatic Labelers and Expert Annotations for Accurate Radiology Report Labeling Using BERT CheXbert is an accurate, automated dee
 51 Dec 8, 2022
51 Dec 8, 2022

Transformer related optimization, including BERT, GPT
This repository provides a script and recipe to run the highly optimized transformer-based encoder and decoder component, and it is tested and maintained by NVIDIA.
1.7k Jan 4, 2023
Adversarial Adaptation with Distillation for BERT Unsupervised Domain Adaptation
Knowledge Distillation for BERT Unsupervised Domain Adaptation Official PyTorch implementation | Paper Abstract A pre-trained language model, BERT, ha
 29 Nov 30, 2022
29 Nov 30, 2022

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
Socorro is the Mozilla crash ingestion pipeline. It accepts and processes Breakpad-style crash reports. It provides analysis tools.
Socorro Socorro is a Mozilla-centric ingestion pipeline and analysis tools for crash reports using the Breakpad libraries. Support This is a Mozilla-s
 552 Dec 19, 2022
552 Dec 19, 2022
![git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]](https://github.com/happycaoyue/Pseudo-ISP/raw/main/img/3.png)
git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]
Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser Abstract The success of deep denoisers on real-world colo
 51 Nov 22, 2022
51 Nov 22, 2022

Automated Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning
The mljar-supervised is an Automated Machine Learning Python package that works with tabular data. I
 2.4k Jan 2, 2023
2.4k Jan 2, 2023
(AAAI' 20) A Python Toolbox for Machine Learning Model Combination
combo: A Python Toolbox for Machine Learning Model Combination Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License
 606 Dec 21, 2022
606 Dec 21, 2022
PyTorch extensions for fast R&D prototyping and Kaggle farming
Pytorch-toolbelt A pytorch-toolbelt is a Python library with a set of bells and whistles for PyTorch for fast R&D prototyping and Kaggle farming: What
 1.3k Jan 5, 2023
1.3k Jan 5, 2023