574 Repositories
Python bert-onnx-rs-pipeline Libraries
This is the offline-training-pipeline for our project.
offline-training-pipeline This is the offline-training-pipeline for our project. We adopt the offline training and online prediction Machine Learning
 0 Apr 22, 2022
0 Apr 22, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch
Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch. Topics: Face detection with Detectron 2, Time Series anomaly detection with LSTM Autoencoders, Object Detection with YOLO v5, Build your first Neural Network, Time Series forecasting for Coronavirus daily cases, Sentiment Analysis with BERT.
 1.8k Dec 31, 2022
1.8k Dec 31, 2022

Setup and customize deep learning environment in seconds.
Deepo is a series of Docker images that allows you to quickly set up your deep learning research environment supports almost all commonly used deep le
 6.3k Jan 6, 2023
6.3k Jan 6, 2023

Complete pipeline for crawling online newspaper article.
Complete pipeline for crawling online newspaper article. The articles are stored to MongoDB. The whole pipeline is dockerized, thus the user does not need to worry about dependencies. Additionally, docker-compose is available to increase the useability for the user.
 4 May 27, 2022
4 May 27, 2022
A Demo server serving Bert through ONNX with GPU written in Rust with 3
Demo BERT ONNX server written in rust This demo showcase the use of onnxruntime-rs on BERT with a GPU on CUDA 11 served by actix-web and tokenized wit
 28 Jan 1, 2023
28 Jan 1, 2023
Using BERT+Bi-LSTM+CRF
Chinese Medical Entity Recognition Based on BERT+Bi-LSTM+CRF Step 1 I share the dataset on my google drive, please download the whole 'CCKS_2019_Task1
 55 Dec 21, 2022
55 Dec 21, 2022

A lightweight face-recognition toolbox and pipeline based on tensorflow-lite
FaceIDLight 📘 Description A lightweight face-recognition toolbox and pipeline based on tensorflow-lite with MTCNN-Face-Detection and ArcFace-Face-Rec
 16 Dec 7, 2022
16 Dec 7, 2022
Advbox is a toolbox to generate adversarial examples that fool neural networks in PaddlePaddle、PyTorch、Caffe2、MxNet、Keras、TensorFlow and Advbox can benchmark the robustness of machine learning models.
Advbox is a toolbox to generate adversarial examples that fool neural networks in PaddlePaddle、PyTorch、Caffe2、MxNet、Keras、TensorFlow and Advbox can benchmark the robustness of machine learning models. Advbox give a command line tool to generate adversarial examples with Zero-Coding.
 1.3k Dec 25, 2022
1.3k Dec 25, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023

This project deals with a simplified version of a more general problem of Aspect Based Sentiment Analysis.
Aspect_Based_Sentiment_Extraction Created on: 5th Jan, 2022. This project deals with an important field of Natural Lnaguage Processing - Aspect Based
 4 Jan 1, 2023
4 Jan 1, 2023
Fine tuning keras-ocr python package with custom synthetic dataset from scratch
OCR-Pipeline-with-Keras The keras-ocr package generally consists of two parts: a Detector and a Recognizer: Detector is responsible for creating bound
 1 Jan 5, 2022
1 Jan 5, 2022
It is a simple library to speed up CLIP inference up to 3x (K80 GPU)
CLIP-ONNX It is a simple library to speed up CLIP inference up to 3x (K80 GPU) Usage Install clip-onnx module and requirements first. Use this trick !
 93 Dec 20, 2022
93 Dec 20, 2022

Rhyme with AI
Local development Create a conda virtual environment and activate it: conda env create --file environment.yml conda activate rhyme-with-ai Install the
 28 Nov 21, 2022
28 Nov 21, 2022

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
Using BERT-based models for toxic span detection
SemEval 2021 Task 5: Toxic Spans Detection: Task: Link to SemEval-2021: Task 5 Toxic Span Detection is https://competitions.codalab.org/competitions/2
 1 Jan 4, 2022
1 Jan 4, 2022

Streaming Finance Data with AWS Lambda
A data pipeline consisting of an AWS lambda function reading data from yfinance API, an AWS Kinesis stream to receive & store data in S3 buckets and AWS Glue crawler & Athena to run SQL queries.
 4 Aug 30, 2022
4 Aug 30, 2022
DeepSpeech - Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation.
(简体中文|English) Quick Start | Documents | Models List PaddleSpeech is an open-source toolkit on PaddlePaddle platform for a variety of critical tasks i
 5.6k Jan 3, 2023
5.6k Jan 3, 2023
Data-science-on-gcp - Source code accompanying book: Data Science on the Google Cloud Platform, Valliappa Lakshmanan, O'Reilly 2017
data-science-on-gcp Source code accompanying book: Data Science on the Google Cloud Platform, 2nd Edition Valliappa Lakshmanan O'Reilly, Jan 2022 Bran
 1.2k Dec 28, 2022
1.2k Dec 28, 2022

Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning And private Server services
Tensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuning
 4.2k Dec 29, 2022
4.2k Dec 29, 2022

KoBERT - Korean BERT pre-trained cased (KoBERT)
KoBERT KoBERT Korean BERT pre-trained cased (KoBERT) Why'?' Training Environment Requirements How to install How to use Using with PyTorch Using with
 1k Jan 2, 2023
1k Jan 2, 2023
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
 5 Sep 28, 2022
5 Sep 28, 2022
Automatic library of congress classification, using word embeddings from book titles and synopses.
Automatic Library of Congress Classification The Library of Congress Classification (LCC) is a comprehensive classification system that was first deve
 3 Oct 1, 2022
3 Oct 1, 2022

PyTorch Lightning + Hydra. A feature-rich template for rapid, scalable and reproducible ML experimentation with best practices. ⚡🔥⚡
Lightning-Hydra-Template A clean and scalable template to kickstart your deep learning project 🚀 ⚡ 🔥 Click on Use this template to initialize new re
 2.1k Jan 9, 2023
2.1k Jan 9, 2023

ncnn is a high-performance neural network inference framework optimized for the mobile platform
ncnn ncnn is a high-performance neural network inference computing framework optimized for mobile platforms. ncnn is deeply considerate about deployme
 16.2k Jan 5, 2023
16.2k Jan 5, 2023
Data reduction pipeline for KOALA on the AAT.
KOALA KOALA, the Kilofibre Optical AAT Lenslet Array, is a wide-field, high efficiency, integral field unit used by the AAOmega spectrograph on the 3.
 4 Sep 26, 2022
4 Sep 26, 2022

Source code of the "Graph-Bert: Only Attention is Needed for Learning Graph Representations" paper
Graph-Bert Source code of "Graph-Bert: Only Attention is Needed for Learning Graph Representations". Please check the script.py as the entry point. We
 14 Mar 25, 2022
14 Mar 25, 2022
Pre-training of Graph Augmented Transformers for Medication Recommendation
G-Bert Pre-training of Graph Augmented Transformers for Medication Recommendation Intro G-Bert combined the power of Graph Neural Networks and BERT (B
 101 Dec 27, 2022
101 Dec 27, 2022
Self-Guided Contrastive Learning for BERT Sentence Representations
Self-Guided Contrastive Learning for BERT Sentence Representations This repository is dedicated for releasing the implementation of the models utilize
 16 Dec 4, 2022
16 Dec 4, 2022
whylogs: A Data and Machine Learning Logging Standard
whylogs: A Data and Machine Learning Logging Standard whylogs is an open source standard for data and ML logging whylogs logging agent is the easiest
 2k Jan 6, 2023
2k Jan 6, 2023

ETL pipeline on movie data using Python and postgreSQL
Movies-ETL ETL pipeline on movie data using Python and postgreSQL Overview This project consisted on a automated Extraction, Transformation and Load p
 0 Jul 7, 2021
0 Jul 7, 2021
Utilize Korean BERT model in sentence-transformers library
ko-sentence-transformers 이 프로젝트는 KoBERT 모델을 sentence-transformers 에서 보다 쉽게 사용하기 위해 만들어졌습니다. Ko-Sentence-BERT-SKTBERT 프로젝트에서는 KoBERT 모델을 sentence-trans
 40 Dec 20, 2022
40 Dec 20, 2022
ONNX Command-Line Toolbox
ONNX Command Line Toolbox Aims to improve your experience of investigating ONNX models. Use it like onnx infershape /path/to/model.onnx. (See the usag
 23 Nov 13, 2022
23 Nov 13, 2022

The object detection pipeline is based on Ultralytics YOLOv5
AYOLOv2 The main goal of this repository is to rewrite the object detection pipeline with a better code structure for better portability and adaptabil
 153 Dec 22, 2022
153 Dec 22, 2022
jiant is an NLP toolkit
🚨 Update 🚨 : As of 2021/10/17, the jiant project is no longer being actively maintained. This means there will be no plans to add new models, tasks,
 1.5k Dec 28, 2022
1.5k Dec 28, 2022
PyBERT is a serial communication link bit error rate tester simulator with a graphical user interface (GUI).
PyBERT PyBERT is a serial communication link bit error rate tester simulator with a graphical user interface (GUI). It uses the Traits/UI package of t
 59 Dec 23, 2022
59 Dec 23, 2022
Korean Sentence Embedding Repository
Korean-Sentence-Embedding 🍭 Korean sentence embedding repository. You can download the pre-trained models and inference right away, also it provides
 80 Jan 2, 2023
80 Jan 2, 2023
pypyr task-runner cli & api for automation pipelines.
pypyr task-runner cli & api for automation pipelines. Automate anything by combining commands, different scripts in different languages & applications into one pipeline process.
 471 Dec 15, 2022
471 Dec 15, 2022
An executor that loads ONNX models and embeds documents using the ONNX runtime.
ONNXEncoder An executor that loads ONNX models and embeds documents using the ONNX runtime. Usage via Docker image (recommended) from jina import Flow
 2 Mar 15, 2022
2 Mar 15, 2022
The DL Streamer Pipeline Zoo is a catalog of optimized media and media analytics pipelines.
The DL Streamer Pipeline Zoo is a catalog of optimized media and media analytics pipelines. It includes tools for downloading pipelines and their dependencies and tools for measuring their performace.
 8 Dec 4, 2022
8 Dec 4, 2022
Spline is a tool that is capable of running locally as well as part of well known pipelines like Jenkins (Jenkinsfile), Travis CI (.travis.yml) or similar ones.
Welcome to spline - the pipeline tool Important note: Since change in my job I didn't had the chance to continue on this project. My main new project
 29 Aug 22, 2022
29 Aug 22, 2022

Build an Amazon SageMaker Pipeline to Transform Raw Texts to A Knowledge Graph
Build an Amazon SageMaker Pipeline to Transform Raw Texts to A Knowledge Graph This repository provides a pipeline to create a knowledge graph from ra
 3 Jan 1, 2022
3 Jan 1, 2022
ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator
ONNX Runtime is a cross-platform inference and training machine-learning accelerator. ONNX Runtime inference can enable faster customer experiences an
 8k Jan 4, 2023
8k Jan 4, 2023
A pipeline for making highlighted text stand-alone.
title emoji colorFrom colorTo sdk app_file pinned decontextualizer 📤 green gray streamlit main.py false Decontextualizer As a second step in improvin
 26 Dec 17, 2022
26 Dec 17, 2022

⛵️The official PyTorch implementation for "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing" (EMNLP 2020).
BERT-of-Theseus Code for paper "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing". BERT-of-Theseus is a new compressed BERT by progre
 284 Nov 25, 2022
284 Nov 25, 2022
Basic yet complete Machine Learning pipeline for NLP tasks
Basic yet complete Machine Learning pipeline for NLP tasks This repository accompanies the article on building basic yet complete ML pipelines for sol
 20 Aug 22, 2022
20 Aug 22, 2022
simple way to build the declarative and destributed data pipelines with python
unipipeline simple way to build the declarative and distributed data pipelines. Why you should use it Declarative strict config Scaffolding Fully type
 0 Jan 26, 2022
0 Jan 26, 2022
Python library for creating data pipelines with chain functional programming
PyFunctional Features PyFunctional makes creating data pipelines easy by using chained functional operators. Here are a few examples of what it can do
 2.1k Jan 5, 2023
2.1k Jan 5, 2023

A full pipeline AutoML tool for tabular data
HyperGBM Doc | 中文 We Are Hiring! Dear folks,we are offering challenging opportunities located in Beijing for both professionals and students who are k
 240 Jan 3, 2023
240 Jan 3, 2023

Healthsea is a spaCy pipeline for analyzing user reviews of supplementary products for their effects on health.
Welcome to Healthsea ✨ Create better access to health with spaCy. Healthsea is a pipeline for analyzing user reviews to supplement products by extract
 75 Dec 19, 2022
75 Dec 19, 2022
Transform a Google Drive server into a VFX pipeline ready server
Google Drive VFX Server VFX Pipeline About The Project Quick tutorial to setup a Google Drive Server for multiple machines access, and VFX Pipeline on
 17 Jun 27, 2022
17 Jun 27, 2022
BERT, LDA, and TFIDF based keyword extraction in Python
BERT, LDA, and TFIDF based keyword extraction in Python kwx is a toolkit for multilingual keyword extraction based on Google's BERT and Latent Dirichl
 41 Dec 27, 2022
41 Dec 27, 2022

BERT-based Financial Question Answering System
BERT-based Financial Question Answering System In this example, we use Jina, PyTorch, and Hugging Face transformers to build a production-ready BERT-b
 61 Sep 18, 2022
61 Sep 18, 2022
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
Chinese named entity recognization (bert/roberta/macbert/bert_wwm with Keras)
 2 Jul 5, 2022
2 Jul 5, 2022
Chinese NER with albert/electra or other bert descendable model (keras)
Chinese NLP (albert/electra with Keras) Named Entity Recognization Project Structure ./ ├── NER │ ├── __init__.py │ ├── log
2 Nov 20, 2022

Label data using HuggingFace's transformers and automatically get a prediction service
Label Studio for Hugging Face's Transformers Website • Docs • Twitter • Join Slack Community Transfer learning for NLP models by annotating your textu
 135 Dec 29, 2022
135 Dec 29, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022
ConvBERT: Improving BERT with Span-based Dynamic Convolution
ConvBERT Introduction In this repo, we introduce a new architecture ConvBERT for pre-training based language model. The code is tested on a V100 GPU.
 237 Dec 10, 2022
237 Dec 10, 2022
Repository for the paper "Optimal Subarchitecture Extraction for BERT"
Bort Companion code for the paper "Optimal Subarchitecture Extraction for BERT." Bort is an optimal subset of architectural parameters for the BERT ar
 461 Nov 21, 2022
461 Nov 21, 2022
DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
DeeBERT This is the code base for the paper DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference. Code in this repository is also available
 132 Nov 14, 2022
132 Nov 14, 2022
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
DeBERTa: Decoding-enhanced BERT with Disentangled Attention This repository is the official implementation of DeBERTa: Decoding-enhanced BERT with Dis
1.2k Jan 3, 2023
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
ALBERT ***************New March 28, 2020 *************** Add a colab tutorial to run fine-tuning for GLUE datasets. ***************New January 7, 2020
 3k Dec 26, 2022
3k Dec 26, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023

Text Classification in Turkish Texts with Bert
You can watch the details of the project on my youtube channel Project Interface Project Second Interface Goal= Correctly guessing the classification
 42 Dec 31, 2022
42 Dec 31, 2022

Powerful unsupervised domain adaptation method for dense retrieval.
Powerful unsupervised domain adaptation method for dense retrieval
 191 Dec 28, 2022
191 Dec 28, 2022
Convert onnx models to pytorch.
onnx2torch onnx2torch is an ONNX to PyTorch converter. Our converter: Is easy to use – Convert the ONNX model with the function call convert; Is easy
 264 Dec 30, 2022
264 Dec 30, 2022
Allele-specific pipeline for unbiased read mapping(WIP), QTL discovery(WIP), and allelic-imbalance analysis
WASP2 (Currently in pre-development): Allele-specific pipeline for unbiased read mapping(WIP), QTL discovery(WIP), and allelic-imbalance analysis Requ
 2 Aug 11, 2022
2 Aug 11, 2022
Using Bert as the backbone model for lime, designed for NLP task explanation (sentence pair text classification task)
Lime Comparing deep contextualized model for sentences highlighting task. In addition, take the classic explanation model "LIME" with bert-base model
 2 Jan 18, 2022
2 Jan 18, 2022
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
A computational block to solve entity alignment over textual attributes in a knowledge graph creation pipeline.
How to apply? Create your config.ini file following the example provided in config.ini Choose one of the options below to run: Run with Python3 pip in
 3 Jun 23, 2022
3 Jun 23, 2022

A real-time financial data streaming pipeline and visualization platform using Apache Kafka, Cassandra, and Bokeh.
Realtime Financial Market Data Visualization and Analysis Introduction This repo shows my project about real-time stock data pipeline. All the code is
 6 Sep 7, 2022
6 Sep 7, 2022
RCT-ART is an NLP pipeline built with spaCy for converting clinical trial result sentences into tables through jointly extracting intervention, outcome and outcome measure entities and their relations.
Randomised controlled trial abstract result tabulator RCT-ART is an NLP pipeline built with spaCy for converting clinical trial result sentences into
 2 Sep 16, 2022
2 Sep 16, 2022

Python scripts for performing object detection with the 1000 labels of the ImageNet dataset in ONNX.
Python scripts for performing object detection with the 1000 labels of the ImageNet dataset in ONNX. The repository combines a class agnostic object localizer to first detect the objects in the image, and next a ResNet50 model trained on ImageNet is used to label each box.
 24 Nov 14, 2022
24 Nov 14, 2022
Microsoft Azure provides a wide number of services for managing and storing data
Microsoft Azure provides a wide number of services for managing and storing data. One product is Microsoft Azure SQL. Which gives us the capability to create and manage instances of SQL Servers hosted in the cloud. This project, demonstrates how to use these services to manage data we collect from different sources.
 1 Dec 12, 2021
1 Dec 12, 2021

Automatically replace ONNX's RandomNormal node with Constant node.
onnx-remove-random-normal This is a script to replace RandomNormal node with Constant node. Example Imagine that we have something ONNX model like the
 1 Dec 11, 2021
1 Dec 11, 2021
Experiments and examples converting Transformers to ONNX
Experiments and examples converting Transformers to ONNX This repository containes experiments and examples on converting different Transformers to ON
 4 Dec 24, 2022
4 Dec 24, 2022
The sarge package provides a wrapper for subprocess which provides command pipeline functionality.
Overview The sarge package provides a wrapper for subprocess which provides command pipeline functionality. This package leverages subprocess to provi
 14 Dec 18, 2022
14 Dec 18, 2022
SOLOv2 on onnx & tensorRT
SOLOv2.tensorRT: NOTE: code based on WXinlong/SOLO add support to TensorRT inference onnxruntime tensorRT full_dims and dynamic shape postprocess with
 47 Nov 26, 2022
47 Nov 26, 2022

iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
 435 Jan 6, 2023
435 Jan 6, 2023
K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce (EMNLP Founding 2021)
Introduction K-PLUG: Knowledge-injected Pre-trained Language Model for Natural Language Understanding and Generation in E-Commerce. Installation PyTor
 21 Nov 16, 2022
21 Nov 16, 2022
iBOT: Image BERT Pre-Training with Online Tokenizer
Image BERT Pre-Training with iBOT Official PyTorch implementation and pretrained models for paper iBOT: Image BERT Pre-Training with Online Tokenizer.
435 Jan 6, 2023
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
922 Dec 10, 2021

MapReader: A computer vision pipeline for the semantic exploration of maps at scale
MapReader A computer vision pipeline for the semantic exploration of maps at scale MapReader is an end-to-end computer vision (CV) pipeline designed b
 25 Dec 26, 2022
25 Dec 26, 2022
This repository contains full machine learning pipeline of the Zillow Houses competition on Kaggle platform.
Zillow-Houses This repository contains full machine learning pipeline of the Zillow Houses competition on Kaggle platform. Pipeline is consists of 10
 2 Jan 9, 2022
2 Jan 9, 2022
BERTMap: A BERT-Based Ontology Alignment System
BERTMap: A BERT-based Ontology Alignment System Important Notices The relevant paper was accepted in AAAI-2022. Arxiv version is available at: https:/
 36 Dec 24, 2022
36 Dec 24, 2022
Convert ONNX model graph to Keras model format.
Convert ONNX model graph to Keras model format.
 175 Dec 28, 2022
175 Dec 28, 2022

ColBERT: Contextualized Late Interaction over BERT (SIGIR'20)
Update: if you're looking for ColBERTv2 code, you can find it alongside a new simpler API, in the branch new_api. ColBERT ColBERT is a fast and accura
 637 Jan 8, 2023
637 Jan 8, 2023
Demonstrate a Dataflow pipeline that saves data from an API into BigQuery table
Overview dataflow-mvp provides a basic example pipeline that pulls data from an API and writes it to a BigQuery table using GCP's Dataflow (i.e., Apac
 1 Dec 3, 2021
1 Dec 3, 2021
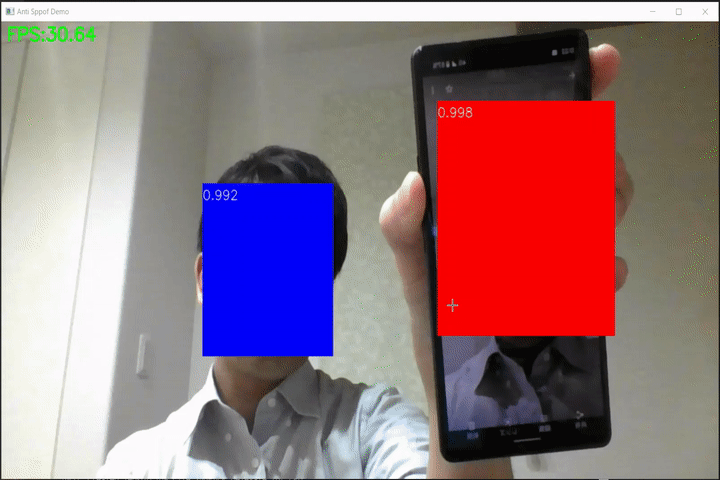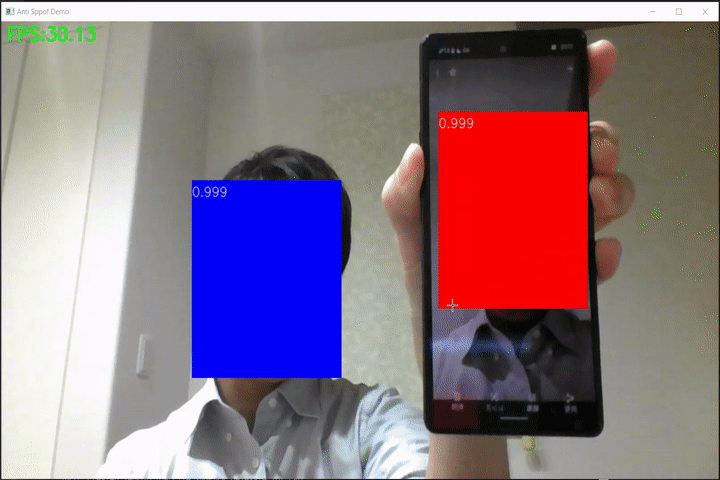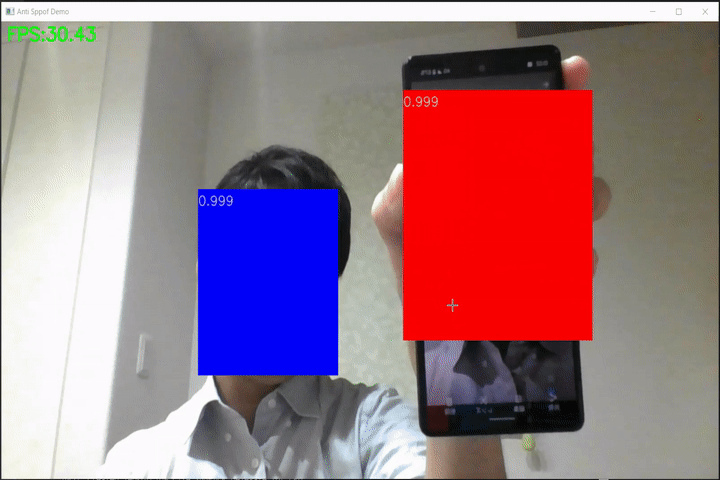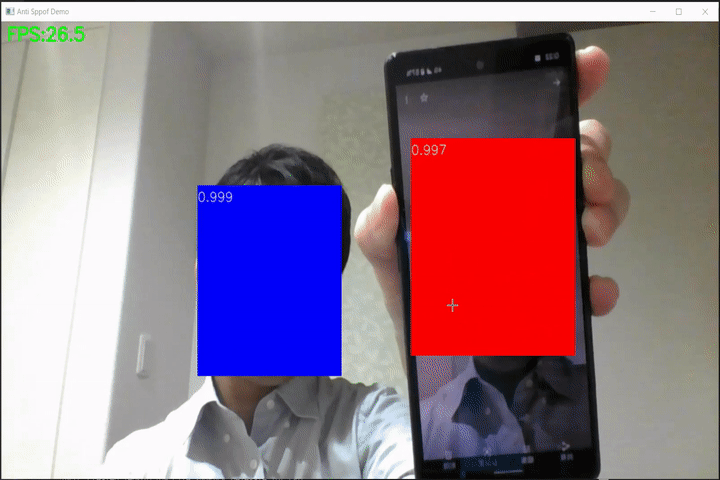
なりすまし検出(anti-spoof-mn3)のWebカメラ向けデモ
FaceDetection-Anti-Spoof-Demo なりすまし検出(anti-spoof-mn3)のWebカメラ向けデモです。 モデルはPINTO_model_zoo/191_anti-spoof-mn3からONNX形式のモデルを使用しています。 Requirement mediapipe
 8 Nov 18, 2022
8 Nov 18, 2022
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022

Pre-Training with Whole Word Masking for Chinese BERT
Pre-Training with Whole Word Masking for Chinese BERT
 7.7k Dec 31, 2022
7.7k Dec 31, 2022
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
BERT has a Mouth, and It Must Speak: BERT as a Markov Random Field Language Model
 303 Dec 17, 2022
303 Dec 17, 2022

Official implementations for various pre-training models of ERNIE-family, covering topics of Language Understanding & Generation, Multimodal Understanding & Generation, and beyond.
English|简体中文 ERNIE是百度开创性提出的基于知识增强的持续学习语义理解框架,该框架将大数据预训练与多源丰富知识相结合,通过持续学习技术,不断吸收海量文本数据中词汇、结构、语义等方面的知识,实现模型效果不断进化。ERNIE在累积 40 余个典型 NLP 任务取得 SOTA 效果,并在 G
5.4k Jan 3, 2023

Revisiting Pre-trained Models for Chinese Natural Language Processing (Findings of EMNLP 2020)
This repository contains the resources in our paper "Revisiting Pre-trained Models for Chinese Natural Language Processing", which will be published i
463 Dec 30, 2022
Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph",
K-BERT Sorce code and datasets for "K-BERT: Enabling Language Representation with Knowledge Graph", which is implemented based on the UER framework. R
 834 Jan 9, 2023
834 Jan 9, 2023
Phrase-BERT: Improved Phrase Embeddings from BERT with an Application to Corpus Exploration
Phrase-BERT: Improved Phrase Embeddings from BERT with an Application to Corpus Exploration This is the official repository for the EMNLP 2021 long pa
 70 Dec 11, 2022
70 Dec 11, 2022

Code for ICLR 2020 paper "VL-BERT: Pre-training of Generic Visual-Linguistic Representations".
VL-BERT By Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, Jifeng Dai. This repository is an official implementation of the paper VL-BERT:
 698 Dec 18, 2022
698 Dec 18, 2022
BERTAC (BERT-style transformer-based language model with Adversarially pretrained Convolutional neural network)
BERTAC (BERT-style transformer-based language model with Adversarially pretrained Convolutional neural network) BERTAC is a framework that combines a
 6 Jan 24, 2022
6 Jan 24, 2022
BERT Attention Analysis
BERT Attention Analysis This repository contains code for What Does BERT Look At? An Analysis of BERT's Attention. It includes code for getting attent
 401 Dec 11, 2022
401 Dec 11, 2022
Assessing syntactic abilities of BERT
BERT-Syntax Assesing the syntactic abilities of BERT. What Evaluate Google's BERT-Base and BERT-Large models on the syntactic agreement datasets from
 147 Aug 2, 2022
147 Aug 2, 2022