2525 Repositories
Python data-lakehouse Libraries

Code for the paper "Training GANs with Stronger Augmentations via Contrastive Discriminator" (ICLR 2021)
Training GANs with Stronger Augmentations via Contrastive Discriminator (ICLR 2021) This repository contains the code for reproducing the paper: Train
 174 Dec 29, 2022
174 Dec 29, 2022

Unofficial implementation of "TTNet: Real-time temporal and spatial video analysis of table tennis" (CVPR 2020)
TTNet-Pytorch The implementation for the paper "TTNet: Real-time temporal and spatial video analysis of table tennis" An introduction of the project c
 438 Dec 29, 2022
438 Dec 29, 2022

Deep generative modeling for time-stamped heterogeneous data, enabling high-fidelity models for a large variety of spatio-temporal domains.
Neural Spatio-Temporal Point Processes [arxiv] Ricky T. Q. Chen, Brandon Amos, Maximilian Nickel Abstract. We propose a new class of parameterizations
 75 Dec 19, 2022
75 Dec 19, 2022
Visualize Data From Stray Scanner https://keke.dev/blog/2021/03/10/Stray-Scanner.html
StrayVisualizer A set of scripts to work with data collected using Stray Scanner. Usage Installing Dependencies Install dependencies with pip -r requi
 45 Dec 30, 2022
45 Dec 30, 2022
First Party data integration solution built for marketing teams to enable audience and conversion onboarding into Google Marketing products (Google Ads, Campaign Manager, Google Analytics).
Megalista Sample integration code for onboarding offline/CRM data from BigQuery as custom audiences or offline conversions in Google Ads, Google Analy
 76 Dec 29, 2022
76 Dec 29, 2022
TorchMetrics is a collection of 25+ PyTorch metrics implementations and an easy-to-use API to create custom metrics.
Machine learning metrics for distributed, scalable PyTorch applications.
 1.2k Jan 6, 2023
1.2k Jan 6, 2023

Ralph is the CMDB / Asset Management system for data center and back office hardware.
Ralph Ralph is full-featured Asset Management, DCIM and CMDB system for data centers and back offices. Features: keep track of assets purchases and th
 1.9k Jan 1, 2023
1.9k Jan 1, 2023

IP address management (IPAM) and data center infrastructure management (DCIM) tool.
NetBox is an IP address management (IPAM) and data center infrastructure management (DCIM) tool. Initially conceived by the network engineering team a
 11.8k Jan 7, 2023
11.8k Jan 7, 2023
a full featured file system for online data storage
S3QL S3QL is a file system that stores all its data online using storage services like Google Storage, Amazon S3, or OpenStack. S3QL effectively provi
 917 Dec 25, 2022
917 Dec 25, 2022
An open source multi-tool for exploring and publishing data
Datasette An open source multi-tool for exploring and publishing data Datasette is a tool for exploring and publishing data. It helps people take data
 6.8k Jan 1, 2023
6.8k Jan 1, 2023
🦉Data Version Control | Git for Data & Models
Website • Docs • Blog • Twitter • Chat (Community & Support) • Tutorial • Mailing List Data Version Control or DVC is an open-source tool for data sci
 10.9k Jan 9, 2023
10.9k Jan 9, 2023

Finds Jobs on LinkedIn using web-scraping
Find Jobs on LinkedIn 📔 This program finds jobs by scraping on LinkedIn 👨💻 Relies on User Input. Accepts: Country, City, State 📑 Data about jobs
 44 Dec 27, 2022
44 Dec 27, 2022

Consistency Regularization for Adversarial Robustness
Consistency Regularization for Adversarial Robustness Official PyTorch implementation of Consistency Regularization for Adversarial Robustness by Jiho
 40 Dec 17, 2022
40 Dec 17, 2022
All the essential resources and template code needed to understand and practice data structures and algorithms in python with few small projects to demonstrate their practical application.
Data Structures and Algorithms Python INDEX 1. Resources - Books Data Structures - Reema Thareja competitiveCoding Big-O Cheat Sheet DAA Syllabus Inte
 129 Dec 15, 2022
129 Dec 15, 2022

Synthetic data for the people.
zpy: Synthetic data in Blender. Website • Install • Docs • Examples • CLI • Contribute • Licence Abstract Collecting, labeling, and cleaning data for
 253 Dec 21, 2022
253 Dec 21, 2022

A complete end-to-end demonstration in which we collect training data in Unity and use that data to train a deep neural network to predict the pose of a cube. This model is then deployed in a simulated robotic pick-and-place task.
Object Pose Estimation Demo This tutorial will go through the steps necessary to perform pose estimation with a UR3 robotic arm in Unity. You’ll gain
 187 Dec 24, 2022
187 Dec 24, 2022
Django project starter on steroids: quickly create a Django app AND generate source code for data models + REST/GraphQL APIs (the generated code is auto-linted and has 100% test coverage).
Create Django App 💛 We're a Django project starter on steroids! One-line command to create a Django app with all the dependencies auto-installed AND
 68 Oct 19, 2022
68 Oct 19, 2022
(CVPR2021) ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic
ClassSR (CVPR2021) ClassSR: A General Framework to Accelerate Super-Resolution Networks by Data Characteristic Paper Authors: Xiangtao Kong, Hengyuan
 308 Jan 5, 2023
308 Jan 5, 2023

Capture all information throughout your model's development in a reproducible way and tie results directly to the model code!
Rubicon Purpose Rubicon is a data science tool that captures and stores model training and execution information, like parameters and outcomes, in a r
 97 Jan 3, 2023
97 Jan 3, 2023
Code associated with the "Data Augmentation using Pre-trained Transformer Models" paper
Data Augmentation using Pre-trained Transformer Models Code associated with the Data Augmentation using Pre-trained Transformer Models paper Code cont
 44 Dec 31, 2022
44 Dec 31, 2022
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
 10k Jan 1, 2023
10k Jan 1, 2023
An extension to pandas dataframes describe function.
pandas_summary An extension to pandas dataframes describe function. The module contains DataFrameSummary object that extend describe() with: propertie
 450 Dec 30, 2022
450 Dec 30, 2022
A library for augmenting annotated audio data
muda A library for Musical Data Augmentation. muda package implements annotation-aware musical data augmentation, as described in the muda paper. The
 214 Nov 22, 2022
214 Nov 22, 2022
The Python ensemble sampling toolkit for affine-invariant MCMC
emcee The Python ensemble sampling toolkit for affine-invariant MCMC emcee is a stable, well tested Python implementation of the affine-invariant ense
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
Supervised domain-agnostic prediction framework for probabilistic modelling
A supervised domain-agnostic framework that allows for probabilistic modelling, namely the prediction of probability distributions for individual data
 112 Oct 23, 2022
112 Oct 23, 2022
A fork of OpenAI Baselines, implementations of reinforcement learning algorithms
Stable Baselines Stable Baselines is a set of improved implementations of reinforcement learning algorithms based on OpenAI Baselines. You can read a
 3.7k Jan 1, 2023
3.7k Jan 1, 2023
A scikit-learn-compatible Python implementation of ReBATE, a suite of Relief-based feature selection algorithms for Machine Learning.
Master status: Development status: Package information: scikit-rebate This package includes a scikit-learn-compatible Python implementation of ReBATE,
 374 Dec 15, 2022
374 Dec 15, 2022
A fast xgboost feature selection algorithm
BoostARoota A Fast XGBoost Feature Selection Algorithm (plus other sklearn tree-based classifiers) Why Create Another Algorithm? Automated processes l
 187 Dec 22, 2022
187 Dec 22, 2022

Automatic extraction of relevant features from time series:
tsfresh This repository contains the TSFRESH python package. The abbreviation stands for "Time Series Feature extraction based on scalable hypothesis
 7k Jan 3, 2023
7k Jan 3, 2023
An open source python library for automated feature engineering
"One of the holy grails of machine learning is to automate more and more of the feature engineering process." ― Pedro Domingos, A Few Useful Things to
 6.4k Jan 5, 2023
6.4k Jan 5, 2023
Build, test, deploy, iterate - Dev and prod tool for data science pipelines
Prodmodel is a build system for data science pipelines. Users, testers, contributors are welcome! Motivation · Concepts · Installation · Usage · Contr
 53 Nov 29, 2022
53 Nov 29, 2022
A Python toolkit for processing tabular data
meza: A Python toolkit for processing tabular data Index Introduction | Requirements | Motivation | Hello World | Usage | Interoperability | Installat
 401 Dec 19, 2022
401 Dec 19, 2022
Clean APIs for data cleaning. Python implementation of R package Janitor
pyjanitor pyjanitor is a Python implementation of the R package janitor, and provides a clean API for cleaning data. Why janitor? Originally a port of
 1.1k Jan 1, 2023
1.1k Jan 1, 2023
BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflows even for datasets that do not fit into memory.
BatchFlow BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflo
 185 Dec 20, 2022
185 Dec 20, 2022
functional data manipulation for pandas
pandas-ply: functional data manipulation for pandas pandas-ply is a thin layer which makes it easier to manipulate data with pandas. In particular, it
 188 Nov 24, 2022
188 Nov 24, 2022
Easy pipelines for pandas DataFrames.
pdpipe ˨ Easy pipelines for pandas DataFrames (learn how!). Website: https://pdpipe.github.io/pdpipe/ Documentation: https://pdpipe.github.io/pdpipe/d
 694 Jan 5, 2023
694 Jan 5, 2023

Out-of-Core DataFrames for Python, ML, visualize and explore big tabular data at a billion rows per second 🚀
What is Vaex? Vaex is a high performance Python library for lazy Out-of-Core DataFrames (similar to Pandas), to visualize and explore big tabular data
 7.7k Jan 1, 2023
7.7k Jan 1, 2023
Koalas: pandas API on Apache Spark
pandas API on Apache Spark Explore Koalas docs » Live notebook · Issues · Mailing list Help Thirsty Koalas Devastated by Recent Fires The Koalas proje
 3.2k Jan 4, 2023
3.2k Jan 4, 2023
A Python package for manipulating 2-dimensional tabular data structures
datatable This is a Python package for manipulating 2-dimensional tabular data structures (aka data frames). It is close in spirit to pandas or SFrame
 1.6k Jan 5, 2023
1.6k Jan 5, 2023
High performance datastore for time series and tick data
Arctic TimeSeries and Tick store Arctic is a high performance datastore for numeric data. It supports Pandas, numpy arrays and pickled objects out-of-
 2.9k Dec 23, 2022
2.9k Dec 23, 2022
A pure Python implementation of Apache Spark's RDD and DStream interfaces.
pysparkling Pysparkling provides a faster, more responsive way to develop programs for PySpark. It enables code intended for Spark applications to exe
 254 Dec 6, 2022
254 Dec 6, 2022
Universal 1d/2d data containers with Transformers functionality for data analysis.
XPandas (extended Pandas) implements 1D and 2D data containers for storing type-heterogeneous tabular data of any type, and encapsulates feature extra
25 Mar 14, 2022
Pandas Google BigQuery
pandas-gbq pandas-gbq is a package providing an interface to the Google BigQuery API from pandas Installation Install latest release version via conda
 348 Jan 3, 2023
348 Jan 3, 2023
NumPy and Pandas interface to Big Data
Blaze translates a subset of modified NumPy and Pandas-like syntax to databases and other computing systems. Blaze allows Python users a familiar inte
 3.1k Jan 1, 2023
3.1k Jan 1, 2023
Create HTML profiling reports from pandas DataFrame objects
Pandas Profiling Documentation | Slack | Stack Overflow Generates profile reports from a pandas DataFrame. The pandas df.describe() function is great
10k Jan 1, 2023

Logging MXNet data for visualization in TensorBoard.
Logging MXNet Data for Visualization in TensorBoard Overview MXBoard provides a set of APIs for logging MXNet data for visualization in TensorBoard. T
 327 Dec 5, 2022
327 Dec 5, 2022
Interpretability and explainability of data and machine learning models
AI Explainability 360 (v0.2.1) The AI Explainability 360 toolkit is an open-source library that supports interpretability and explainability of datase
 1.2k Dec 29, 2022
1.2k Dec 29, 2022

A library for debugging/inspecting machine learning classifiers and explaining their predictions
ELI5 ELI5 is a Python package which helps to debug machine learning classifiers and explain their predictions. It provides support for the following m
 2.6k Dec 30, 2022
2.6k Dec 30, 2022

An intuitive library to add plotting functionality to scikit-learn objects.
Welcome to Scikit-plot Single line functions for detailed visualizations The quickest and easiest way to go from analysis... ...to this. Scikit-plot i
 2.3k Dec 31, 2022
2.3k Dec 31, 2022

A data-driven approach to quantify the value of classifiers in a machine learning ensemble.
Documentation | External Resources | Research Paper Shapley is a Python library for evaluating binary classifiers in a machine learning ensemble. The
 187 Dec 27, 2022
187 Dec 27, 2022
With Holoviews, your data visualizes itself.
HoloViews Stop plotting your data - annotate your data and let it visualize itself. HoloViews is an open-source Python library designed to make data a
 2.3k Jan 4, 2023
2.3k Jan 4, 2023
How on earth can I ever think of a solution like that in an interview?!
fuck-coding-interviews This repository is created by an awkward programmer who always struggles with coding problems on LeetCode, even with some Easy
 613 Jan 8, 2023
613 Jan 8, 2023
Algorithms and data structures for educational, demonstrational and experimental purposes.
Algorithms and Data Structures (ands) Introduction This project was created for personal use mostly while studying for an exam (starting in the month
 50 Dec 6, 2022
50 Dec 6, 2022
:computer: Data Structures and Algorithms in Python
Algorithms in Python Implementations of a few algorithms and datastructures for fun and profit! Completed Karatsuba Multiplication Basic Sorting Rabin
 2.9k Jan 1, 2023
2.9k Jan 1, 2023
Python library that makes it easy for data scientists to create charts.
Chartify Chartify is a Python library that makes it easy for data scientists to create charts. Why use Chartify? Consistent input data format: Spend l
 3.2k Jan 1, 2023
3.2k Jan 1, 2023
Keras community contributions
keras-contrib : Keras community contributions Keras-contrib is deprecated. Use TensorFlow Addons. The future of Keras-contrib: We're migrating to tens
 1.6k Dec 21, 2022
1.6k Dec 21, 2022
Machine Learning Platform for Kubernetes
Reproduce, Automate, Scale your data science. Welcome to Polyaxon, a platform for building, training, and monitoring large scale deep learning applica
 3.2k Dec 23, 2022
3.2k Dec 23, 2022

A simplified framework and utilities for PyTorch
Here is Poutyne. Poutyne is a simplified framework for PyTorch and handles much of the boilerplating code needed to train neural networks. Use Poutyne
 534 Dec 17, 2022
534 Dec 17, 2022
Data loaders and abstractions for text and NLP
torchtext This repository consists of: torchtext.datasets: The raw text iterators for common NLP datasets torchtext.data: Some basic NLP building bloc
 3.2k Jan 8, 2023
3.2k Jan 8, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
 14.5k Jan 7, 2023
14.5k Jan 7, 2023
Python-based implementations of algorithms for learning on imbalanced data.
ND DIAL: Imbalanced Algorithms Minimalist Python-based implementations of algorithms for imbalanced learning. Includes deep and representational learn
 220 Dec 13, 2022
220 Dec 13, 2022
A Python Package to Tackle the Curse of Imbalanced Datasets in Machine Learning
imbalanced-learn imbalanced-learn is a python package offering a number of re-sampling techniques commonly used in datasets showing strong between-cla
 6.2k Jan 1, 2023
6.2k Jan 1, 2023
MLBox is a powerful Automated Machine Learning python library.
MLBox is a powerful Automated Machine Learning python library. It provides the following features: Fast reading and distributed data preprocessing/cle
 1.4k Jan 6, 2023
1.4k Jan 6, 2023
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
Master status: Development status: Package information: TPOT stands for Tree-based Pipeline Optimization Tool. Consider TPOT your Data Science Assista
8.9k Jan 9, 2023
Tool for producing high quality forecasts for time series data that has multiple seasonality with linear or non-linear growth.
Prophet: Automatic Forecasting Procedure Prophet is a procedure for forecasting time series data based on an additive model where non-linear trends ar
 15.4k Jan 7, 2023
15.4k Jan 7, 2023
A machine learning toolkit dedicated to time-series data
tslearn The machine learning toolkit for time series analysis in Python Section Description Installation Installing the dependencies and tslearn Getti
 2.3k Jan 5, 2023
2.3k Jan 5, 2023
![[HELP REQUESTED] Generalized Additive Models in Python](https://github.com/dswah/pyGAM/raw/master/imgs/pygam_tensor.png)
[HELP REQUESTED] Generalized Additive Models in Python
pyGAM Generalized Additive Models in Python. Documentation Official pyGAM Documentation: Read the Docs Building interpretable models with Generalized
 747 Jan 5, 2023
747 Jan 5, 2023
50% faster, 50% less RAM Machine Learning. Numba rewritten Sklearn. SVD, NNMF, PCA, LinearReg, RidgeReg, Randomized, Truncated SVD/PCA, CSR Matrices all 50+% faster
[Due to the time taken @ uni, work + hell breaking loose in my life, since things have calmed down a bit, will continue commiting!!!] [By the way, I'm
 1.4k Jan 1, 2023
1.4k Jan 1, 2023
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2021 Links Doc
 4.2k Dec 29, 2022
4.2k Dec 29, 2022
A toolkit for making real world machine learning and data analysis applications in C++
dlib C++ library Dlib is a modern C++ toolkit containing machine learning algorithms and tools for creating complex software in C++ to solve real worl
 11.6k Jan 2, 2023
11.6k Jan 2, 2023
High performance, easy-to-use, and scalable machine learning (ML) package, including linear model (LR), factorization machines (FM), and field-aware factorization machines (FFM) for Python and CLI interface.
What is xLearn? xLearn is a high performance, easy-to-use, and scalable machine learning package that contains linear model (LR), factorization machin
 3k Jan 8, 2023
3k Jan 8, 2023
daily report of @arkinvest ETF activity + data collection
ark_invest daily weekday report of @arkinvest ETF activity + data collection This script was created to: Extract and save daily csv's from ARKInvest's
 27 Jan 2, 2023
27 Jan 2, 2023

test
Lidar-data-decode In this project, you can decode your lidar data frame(pcap file) and make your own datasets(test dataset) in Windows without any hug
 46 Dec 5, 2022
46 Dec 5, 2022
An automated tool that fetches information about your crypto stake and generates historical data in time.
Introduction Yield explorer is a WIP! I needed a tool that would show me historical data and performance of my staked crypto but was unable to find a
 42 Nov 26, 2022
42 Nov 26, 2022

Deep Illuminator is a data augmentation tool designed for image relighting.
Deep Illuminator Deep Illuminator is a data augmentation tool designed for image relighting. It can be used to easily and efficiently genera
 52 Nov 29, 2022
52 Nov 29, 2022

Ultra-Data-Efficient GAN Training: Drawing A Lottery Ticket First, Then Training It Toughly
Ultra-Data-Efficient GAN Training: Drawing A Lottery Ticket First, Then Training It Toughly Code for this paper Ultra-Data-Efficient GAN Tra
 77 Oct 5, 2022
77 Oct 5, 2022

🍊 :bar_chart: :bulb: Orange: Interactive data analysis
Orange Data Mining Orange is a data mining and visualization toolbox for novice and expert alike. To explore data with Orange, one requires no program
 3.9k Jan 5, 2023
3.9k Jan 5, 2023
3D visualization of scientific data in Python
Mayavi: 3D visualization of scientific data in Python Mayavi docs: http://docs.enthought.com/mayavi/mayavi/ TVTK docs: http://docs.enthought.com/mayav
 1.1k Jan 6, 2023
1.1k Jan 6, 2023
Data intensive science for everyone.
The latest information about Galaxy can be found on the Galaxy Community Hub. Community support is available at Galaxy Help. Galaxy Quickstart Galaxy
 1k Jan 8, 2023
1k Jan 8, 2023
CKAN is an open-source DMS (data management system) for powering data hubs and data portals. CKAN makes it easy to publish, share and use data. It powers catalog.data.gov, open.canada.ca/data, data.humdata.org among many other sites.
CKAN: The Open Source Data Portal Software CKAN is the world’s leading open-source data portal platform. CKAN makes it easy to publish, share and work
 3.6k Dec 27, 2022
3.6k Dec 27, 2022
An interactive explorer for single-cell transcriptomics data
an interactive explorer for single-cell transcriptomics data cellxgene (pronounced "cell-by-gene") is an interactive data explorer for single-cell tra
 424 Dec 15, 2022
424 Dec 15, 2022

A Python library that helps data scientists to infer causation rather than observing correlation.
A Python library that helps data scientists to infer causation rather than observing correlation.
 1.7k Jan 4, 2023
1.7k Jan 4, 2023

ProPublica's collaborative tip-gathering framework. Import and manage CSV, Google Sheets and Screendoor data with ease.
Collaborate This is a web application for managing and building stories based on tips solicited from the public. This project is meant to be easy to s
 86 Oct 18, 2022
86 Oct 18, 2022
🦉Data Version Control | Git for Data & Models
Website • Docs • Blog • Twitter • Chat (Community & Support) • Tutorial • Mailing List Data Version Control or DVC is an open-source tool for data sci
10.9k Jan 5, 2023
ProPublica's collaborative tip-gathering framework. Import and manage CSV, Google Sheets and Screendoor data with ease.
Collaborate This is a web application for managing and building stories based on tips solicited from the public. This project is meant to be easy to s
86 Oct 18, 2022
Backend, modern REST API for obtaining match and odds data crawled from multiple sites. Using FastAPI, MongoDB as database, Motor as async MongoDB client, Scrapy as crawler and Docker.
Introduction Apiestas is a project composed of a backend powered by the awesome framework FastAPI and a crawler powered by Scrapy. This project has fo
 54 Dec 13, 2022
54 Dec 13, 2022

API & Webapp to answer questions about COVID-19. Using NLP (Question Answering) and trusted data sources.
This open source project serves two purposes. Collection and evaluation of a Question Answering dataset to improve existing QA/search methods - COVID-
 329 Nov 10, 2022
329 Nov 10, 2022
MazeRL is an application oriented Deep Reinforcement Learning (RL) framework
MazeRL is an application oriented Deep Reinforcement Learning (RL) framework, addressing real-world decision problems. Our vision is to cover the complete development life cycle of RL applications ranging from simulation engineering up to agent development, training and deployment.
 222 Dec 24, 2022
222 Dec 24, 2022
Data Visualizer for Super Mario Kart (SNES)
Data Visualizer for Super Mario Kart (SNES)
 21 Nov 20, 2022
21 Nov 20, 2022
💻 Algo-Phantoms-Backend is an Application that provides pathways and quizzes along with a code editor to help you towards your DSA journey.📰🔥 This repository contains the REST APIs of the application.✨
Algo-Phantom-Backend 💻 Algo-Phantoms-Backend is an Application that provides pathways and quizzes along with a code editor to help you towards your D
 44 Nov 15, 2022
44 Nov 15, 2022
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton.
Boltons boltons should be builtins. Boltons is a set of over 230 BSD-licensed, pure-Python utilities in the same spirit as — and yet conspicuously mis
 5.4k Feb 20, 2021
5.4k Feb 20, 2021

A PyTorch implementation of "Pathfinder Discovery Networks for Neural Message Passing"
A PyTorch implementation of "Pathfinder Discovery Networks for Neural Message Passing" (WebConf 2021). Abstract In this work we propose Pathfind
49 Dec 1, 2022
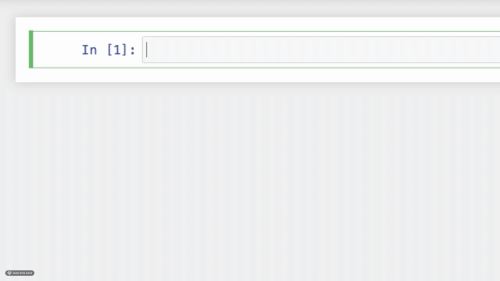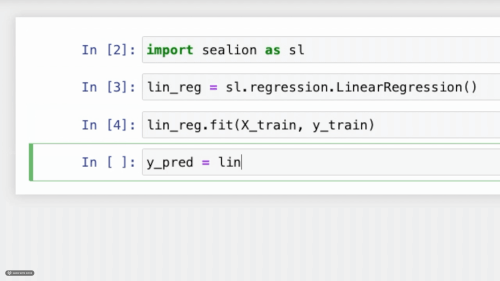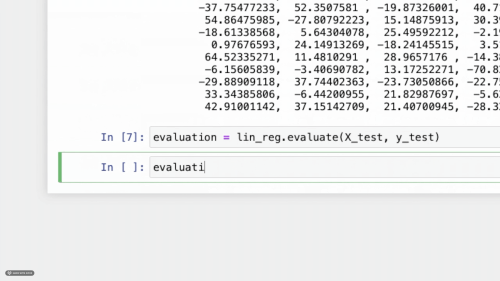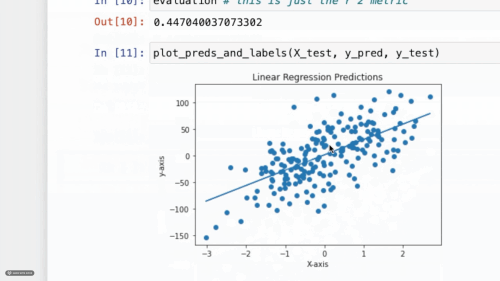
The first machine learning framework that encourages learning ML concepts instead of memorizing class functions.
SeaLion is designed to teach today's aspiring ml-engineers the popular machine learning concepts of today in a way that gives both intuition and ways of application. We do this through concise algorithms that do the job in the least jargon possible and examples to guide you through every step of the way.
 324 Dec 27, 2022
324 Dec 27, 2022
Contrastive Learning Inverts the Data Generating Process
Official code to reproduce the results and data presented in the paper Contrastive Learning Inverts the Data Generating Process.
 71 Nov 25, 2022
71 Nov 25, 2022
ForecastGA is a Python tool to forecast Google Analytics data using several popular time series models.
ForecastGA is a tool that combines a couple of popular libraries, Atspy and googleanalytics, with a few enhancements.
 36 Jan 3, 2023
36 Jan 3, 2023
Aggregating gridded data (xarray) to polygons
A package to aggregate gridded data in xarray to polygons in geopandas using area-weighting from the relative area overlaps between pixels and polygons. Check out the binder link above for a sample code run!
 42 Nov 9, 2022
42 Nov 9, 2022
A simple worker for OpenClubhouse to sync data.
OpenClubhouse-Worker This is a simple worker for OpenClubhouse to sync CH channel data.
 100 Dec 17, 2022
100 Dec 17, 2022
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 11.7k Feb 18, 2021
11.7k Feb 18, 2021
Toolkit for Machine Learning, Natural Language Processing, and Text Generation, in TensorFlow. This is part of the CASL project: http://casl-project.ai/
Texar is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar provides
 2.1k Feb 17, 2021
2.1k Feb 17, 2021