447 Repositories
Python fine-grained-visual-categorization Libraries
![[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427](https://github.com/jiawei-ren/BalancedMSE/raw/main/figures/intro.png)
[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427
Balanced MSE Code for the paper: Balanced MSE for Imbalanced Visual Regression Jiawei Ren, Mingyuan Zhang, Cunjun Yu, Ziwei Liu CVPR 2022 (Oral) News
 267 Jan 1, 2023
267 Jan 1, 2023

One line to host them all. Bootstrap your image search case in minutes.
One line to host them all. Bootstrap your image search case in minutes. Survey NOW gives the world access to customized neural image search in just on
 403 Dec 30, 2022
403 Dec 30, 2022
![[CVPR2022] This repository contains code for the paper](https://github.com/Bazinga699/NCL/raw/main/resource/framework_English.png)
[CVPR2022] This repository contains code for the paper "Nested Collaborative Learning for Long-Tailed Visual Recognition", published at CVPR 2022
Nested Collaborative Learning for Long-Tailed Visual Recognition This repository is the official PyTorch implementation of the paper in CVPR 2022: Nes
 65 Dec 9, 2022
65 Dec 9, 2022
All of the figures and notebooks for my deep learning book, for free!
"Deep Learning - A Visual Approach" by Andrew Glassner This is the official repo for my book from No Starch Press. Ordering the book My book is called
 227 Jan 4, 2023
227 Jan 4, 2023
🤗🖼️ HuggingPics: Fine-tune Vision Transformers for anything using images found on the web.
🤗 🖼️ HuggingPics Fine-tune Vision Transformers for anything using images found on the web. Check out the video below for a walkthrough of this proje
 185 Dec 21, 2022
185 Dec 21, 2022
Code for T-Few from "Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning"
T-Few This repository contains the official code for the paper: "Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learni
 220 Dec 31, 2022
220 Dec 31, 2022

Building a real-time environment using webcam frame division in OpenCV and classify cropped images using a fine-tuned vision transformers on hybryd datasets samples for facial emotion recognition.
Visual Transformer for Facial Emotion Recognition (FER) This project has the aim to build an efficient Visual Transformer for the Facial Emotion Recog
 8 Dec 12, 2022
8 Dec 12, 2022

SeqTR: A Simple yet Universal Network for Visual Grounding
SeqTR This is the official implementation of SeqTR: A Simple yet Universal Network for Visual Grounding, which simplifies and unifies the modelling fo
 76 Dec 24, 2022
76 Dec 24, 2022

Language Models Can See: Plugging Visual Controls in Text Generation
Language Models Can See: Plugging Visual Controls in Text Generation Authors: Yixuan Su, Tian Lan, Yahui Liu, Fangyu Liu, Dani Yogatama, Yan Wang, Lin
 195 Dec 22, 2022
195 Dec 22, 2022

FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset (CVPR2022)
FaceVerse FaceVerse: a Fine-grained and Detail-controllable 3D Face Morphable Model from a Hybrid Dataset Lizhen Wang, Zhiyuan Chen, Tao Yu, Chenguang
 219 Dec 28, 2022
219 Dec 28, 2022

A python package for generating, analyzing and visualizing building shadows
pybdshadow Introduction pybdshadow is a python package for generating, analyzing and visualizing building shadows from large scale building geographic
 13 Nov 30, 2022
13 Nov 30, 2022

Implementation of CaiT models in TensorFlow and ImageNet-1k checkpoints. Includes code for inference and fine-tuning.
CaiT-TF (Going deeper with Image Transformers) This repository provides TensorFlow / Keras implementations of different CaiT [1] variants from Touvron
 9 Jun 26, 2022
9 Jun 26, 2022

Using Machine Learning to Create High-Res Fine Art
BIG.art: Using Machine Learning to Create High-Res Fine Art How to use GLIDE and BSRGAN to create ultra-high-resolution paintings with fine details By
 13 Nov 27, 2022
13 Nov 27, 2022

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023
Includes PyTorch - Keras model porting code for ConvNeXt family of models with fine-tuning and inference notebooks.
ConvNeXt-TF This repository provides TensorFlow / Keras implementations of different ConvNeXt [1] variants. It also provides the TensorFlow / Keras mo
87 Dec 6, 2022

In this tutorial, you will perform inference across 10 well-known pre-trained object detectors and fine-tune on a custom dataset. Design and train your own object detector.
Object Detection Object detection is a computer vision task for locating instances of predefined objects in images or videos. In this tutorial, you wi
 62 Dec 25, 2022
62 Dec 25, 2022

A Decentralized Omnidirectional Visual-Inertial-UWB State Estimation System for Aerial Swar.
Omni-swarm A Decentralized Omnidirectional Visual-Inertial-UWB State Estimation System for Aerial Swarm Introduction Omni-swarm is a decentralized omn
 99 Dec 23, 2022
99 Dec 23, 2022

Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology (LMRL Workshop, NeurIPS 2021)
Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology Self-Supervised Vision Transformers Learn Visual Concepts in Histopatholog
 95 Dec 24, 2022
95 Dec 24, 2022
Multilingual Emotion classification using BERT (fine-tuning). Published at the WASSA workshop (ACL2022).
XLM-EMO: Multilingual Emotion Prediction in Social Media Text Abstract Detecting emotion in text allows social and computational scientists to study h
 35 Sep 17, 2022
35 Sep 17, 2022
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022

Facestar dataset. High quality audio-visual recordings of human conversational speech.
Facestar Dataset Description Existing audio-visual datasets for human speech are either captured in a clean, controlled environment but contain only a
 87 Dec 21, 2022
87 Dec 21, 2022

Official page of Struct-MDC (RA-L'22 with IROS'22 option); Depth completion from Visual-SLAM using point & line features
Struct-MDC (click the above buttons for redirection!) Official page of "Struct-MDC: Mesh-Refined Unsupervised Depth Completion Leveraging Structural R
 37 Dec 22, 2022
37 Dec 22, 2022
PyTorch code for the paper "Complementarity is the King: Multi-modal and Multi-grained Hierarchical Semantic Enhancement Network for Cross-modal Retrieval".
Complementarity is the King: Multi-modal and Multi-grained Hierarchical Semantic Enhancement Network for Cross-modal Retrieval (M2HSE) PyTorch code fo
 6 Dec 23, 2022
6 Dec 23, 2022
![[ICCV2021] 3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds](https://github.com/zlccccc/3DVG-Transformer/raw/main/demo/Model.png)
[ICCV2021] 3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds
3DVG-Transformer This repository is for the ICCV 2021 paper "3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds" Our method "3DV
 22 Dec 11, 2022
22 Dec 11, 2022

Repository for fine-tuning Transformers 🤗 based seq2seq speech models in JAX/Flax.
Seq2Seq Speech in JAX A JAX/Flax repository for combining a pre-trained speech encoder model (e.g. Wav2Vec2, HuBERT, WavLM) with a pre-trained text de
 21 Dec 14, 2022
21 Dec 14, 2022

Implementation of 🦩 Flamingo, state-of-the-art few-shot visual question answering attention net out of Deepmind, in Pytorch
🦩 Flamingo - Pytorch Implementation of Flamingo, state-of-the-art few-shot visual question answering attention net, in Pytorch. It will include the p
 630 Dec 28, 2022
630 Dec 28, 2022

A Flask Sentiment Analysis API, with visual implementation
The Sentiment Analysis Api was created using python flask module,it allows users to parse a text or sentence throught the (?text) arguement, then view the sentiment analysis of that sentence. It can be implementable into a web application.
 10 Jul 17, 2022
10 Jul 17, 2022
Code for our SIGIR 2022 accepted paper : P3 Ranker: Mitigating the Gaps between Pre-training and Ranking Fine-tuning with Prompt-based Learning and Pre-finetuning
P3 Ranker Implementation for our SIGIR2022 accepted paper: P3 Ranker: Mitigating the Gaps between Pre-training and Ranking Fine-tuning with Prompt-bas
 14 Jan 4, 2023
14 Jan 4, 2023

Under the hood working of transformers, fine-tuning GPT-3 models, DeBERTa, vision models, and the start of Metaverse, using a variety of NLP platforms: Hugging Face, OpenAI API, Trax, and AllenNLP
Transformers-for-NLP-2nd-Edition @copyright 2022, Packt Publishing, Denis Rothman Contact me for any question you have on LinkedIn Get the book on Ama
 150 Dec 23, 2022
150 Dec 23, 2022

Ensemble Knowledge Guided Sub-network Search and Fine-tuning for Filter Pruning
Ensemble Knowledge Guided Sub-network Search and Fine-tuning for Filter Pruning This repository is official Tensorflow implementation of paper: Ensemb
 12 Oct 18, 2022
12 Oct 18, 2022
Code for One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022) Paper | Demo Requirements Python = 3.6 , Pytorch
 84 Jan 3, 2023
84 Jan 3, 2023

SUPERVISED-CONTRASTIVE-LEARNING-FOR-PRE-TRAINED-LANGUAGE-MODEL-FINE-TUNING - The Facebook paper about fine tuning RoBERTa with contrastive loss
"# SUPERVISED-CONTRASTIVE-LEARNING-FOR-PRE-TRAINED-LANGUAGE-MODEL-FINE-TUNING" i
 28 Dec 12, 2022
28 Dec 12, 2022
The visual framework is designed on the idea of module and implemented by mixin method
Visual Framework The visual framework is designed on the idea of module and implemented by mixin method. Its biggest feature is the mixins module whic
 9 Sep 19, 2022
9 Sep 19, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023

A python package to fine-tune transformer-based models for named entity recognition (NER).
nerblackbox A python package to fine-tune transformer-based language models for named entity recognition (NER). Resources Source Code: https://github.
 13 Jul 30, 2022
13 Jul 30, 2022
A visual indicator of what environment/system you're using in django
A visual indicator of what environment/system you're using in django
 4 Nov 26, 2022
4 Nov 26, 2022
A Broad Study on the Transferability of Visual Representations with Contrastive Learning
A Broad Study on the Transferability of Visual Representations with Contrastive Learning This repository contains code for the paper: A Broad Study on
 29 Nov 9, 2022
29 Nov 9, 2022

Learning Visual Words for Weakly-Supervised Semantic Segmentation
[IJCAI 2021] Learning Visual Words for Weakly-Supervised Semantic Segmentation Implementation of IJCAI 2021 paper Learning Visual Words for Weakly-Sup
 24 Oct 5, 2022
24 Oct 5, 2022

On the Limits of Pseudo Ground Truth in Visual Camera Re-Localization
On the Limits of Pseudo Ground Truth in Visual Camera Re-Localization This repository contains the evaluation code and alternative pseudo ground truth
 36 Dec 22, 2022
36 Dec 22, 2022
Customizing Visual Styles in Plotly
Customizing Visual Styles in Plotly Code for a workshop originally developed for an Unconference session during the Outlier Conference hosted by Data
 9 Aug 3, 2022
9 Aug 3, 2022
SAGE: Sensitivity-guided Adaptive Learning Rate for Transformers
SAGE: Sensitivity-guided Adaptive Learning Rate for Transformers This repo contains our codes for the paper "No Parameters Left Behind: Sensitivity Gu
 23 Nov 7, 2022
23 Nov 7, 2022
FIRA: Fine-Grained Graph-Based Code Change Representation for Automated Commit Message Generation
FIRA is a learning-based commit message generation approach, which first represents code changes via fine-grained graphs and then learns to generate commit messages automatically.
 21 Dec 30, 2022
21 Dec 30, 2022

A Novel Plug-in Module for Fine-grained Visual Classification
Pytorch implementation for A Novel Plug-in Module for Fine-Grained Visual Classification. fine-grained visual classification task.
 109 Dec 20, 2022
109 Dec 20, 2022

HAIS_2GNN: 3D Visual Grounding with Graph and Attention
HAIS_2GNN: 3D Visual Grounding with Graph and Attention This repository is for the HAIS_2GNN research project. Tao Gu, Yue Chen Introduction The motiv
 1 Nov 26, 2022
1 Nov 26, 2022
SAAVN - Sound Adversarial Audio-Visual Navigation,ICLR2022 (In PyTorch)
SAAVN SAAVN Code release for paper "Sound Adversarial Audio-Visual Navigation,IC
 10 Aug 30, 2022
10 Aug 30, 2022

PyTorch code for BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
 1.3k Dec 31, 2022
1.3k Dec 31, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
 32 Dec 29, 2022
32 Dec 29, 2022

Deep ViT Features as Dense Visual Descriptors
dino-vit-features [paper] [project page] Official implementation of the paper "Deep ViT Features as Dense Visual Descriptors". We demonstrate the effe
 113 Dec 24, 2022
113 Dec 24, 2022
Ensemble Visual-Inertial Odometry (EnVIO)
Ensemble Visual-Inertial Odometry (EnVIO) Authors : Jae Hyung Jung, Yeongkwon Choe, and Chan Gook Park 1. Overview This is a ROS package of Ensemble V
 95 Jan 3, 2023
95 Jan 3, 2023
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control
FIGARO: Generating Symbolic Music with Fine-Grained Artistic Control by Dimitri von Rütte, Luca Biggio, Yannic Kilcher, Thomas Hofmann FIGARO: Generat
 83 Jan 7, 2023
83 Jan 7, 2023
Generate fine-tuning samples & Fine-tuning the model & Generate samples by transferring Note On
UPMT Generate fine-tuning samples & Fine-tuning the model & Generate samples by transferring Note On See main.py as an example: from model import PopM
 7 Sep 1, 2022
7 Sep 1, 2022

PyTorch implementation for the paper Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime
Visual Representation Learning with Self-Supervised Attention for Low-Label High-Data Regime Created by Prarthana Bhattacharyya. Disclaimer: This is n
 5 Nov 8, 2022
5 Nov 8, 2022
Vpw analyzer - A visual J1850 VPW analyzer written in Python
VPW Analyzer A visual J1850 VPW analyzer written in Python Requires Tkinter, Pan
 7 May 1, 2022
7 May 1, 2022
Towards Fine-Grained Reasoning for Fake News Detection
FinerFact This is the PyTorch implementation for the FinerFact model in the AAAI 2022 paper Towards Fine-Grained Reasoning for Fake News Detection (Ar
 15 Dec 15, 2022
15 Dec 15, 2022
Revisiting Weakly Supervised Pre-Training of Visual Perception Models
SWAG: Supervised Weakly from hashtAGs This repository contains SWAG models from the paper Revisiting Weakly Supervised Pre-Training of Visual Percepti
134 Jan 5, 2023

On the Adversarial Robustness of Visual Transformer
On the Adversarial Robustness of Visual Transformer Code for our paper "On the Adversarial Robustness of Visual Transformers"
 35 Dec 14, 2022
35 Dec 14, 2022
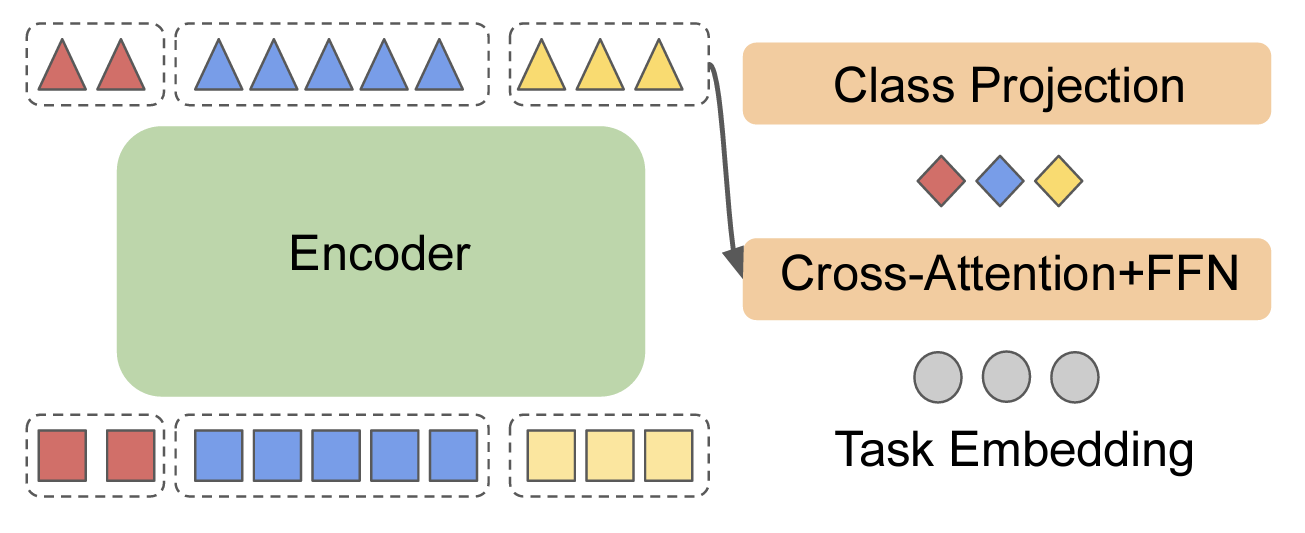
EncT5: Fine-tuning T5 Encoder for Non-autoregressive Tasks
EncT5 (Unofficial) Pytorch Implementation of EncT5: Fine-tuning T5 Encoder for Non-autoregressive Tasks About Finetune T5 model for classification & r
 34 Jan 1, 2023
34 Jan 1, 2023
This repository contains the implementation of the following paper: Cross-Descriptor Visual Localization and Mapping
Cross-Descriptor Visual Localization and Mapping This repository contains the implementation of the following paper: "Cross-Descriptor Visual Localiza
 81 Oct 6, 2022
81 Oct 6, 2022

Clustering is a popular approach to detect patterns in unlabeled data
Visual Clustering Clustering is a popular approach to detect patterns in unlabeled data. Existing clustering methods typically treat samples in a data
 24 Nov 11, 2022
24 Nov 11, 2022

This is a small program that prints a user friendly, visual representation, of your current bsp tree
bspcq, q for query A bspc analyzer (utility for bspwm) This is a small program that prints a user friendly, visual representation, of your current bsp
 9 Apr 24, 2022
9 Apr 24, 2022
Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
ademxapp Visual applications by the University of Adelaide In designing our Model A, we did not over-optimize its structure for efficiency unless it w
 338 Dec 12, 2022
338 Dec 12, 2022
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features
Multi-modal Text Recognition Networks: Interactive Enhancements between Visual and Semantic Features | paper | Official PyTorch implementation for Mul
 48 Dec 28, 2022
48 Dec 28, 2022
TensorDebugger (TDB) is a visual debugger for deep learning. It extends TensorFlow with breakpoints + real-time visualization of the data flowing through the computational graph
TensorDebugger (TDB) is a visual debugger for deep learning. It extends TensorFlow (Google's Deep Learning framework) with breakpoints + real-time visualization of the data flowing through the computational graph.
 1.4k Dec 15, 2022
1.4k Dec 15, 2022
Provide fine-grained push access to GitHub from a JupyterHub
github-app-user-auth Provide fine-grained push access to GitHub from a JupyterHub. Goals Allow users on a JupyterHub to grant push access to only spec
 20 Sep 13, 2022
20 Sep 13, 2022

OMNIVORE is a single vision model for many different visual modalities
Omnivore: A Single Model for Many Visual Modalities [paper][website] OMNIVORE is a single vision model for many different visual modalities. It learns
451 Dec 27, 2022
Collect some papers about transformer with vision. Awesome Transformer with Computer Vision (CV)
Awesome Visual-Transformer Collect some Transformer with Computer-Vision (CV) papers. If you find some overlooked papers, please open issues or pull r
 2.8k Jan 8, 2023
2.8k Jan 8, 2023
Transformer in Vision
Transformer-in-Vision Recent Transformer-based CV and related works. Welcome to comment/contribute! Keep updated. Resource SCENIC: A JAX Library for C
 1.1k Dec 30, 2022
1.1k Dec 30, 2022

A general python framework for visual object tracking and video object segmentation, based on PyTorch
PyTracking A general python framework for visual object tracking and video object segmentation, based on PyTorch. 📣 Two tracking/VOS papers accepted
 2.6k Jan 4, 2023
2.6k Jan 4, 2023

X-VLM: Multi-Grained Vision Language Pre-Training
X-VLM: learning multi-grained vision language alignments Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts. Yan Zeng, Xi
 286 Dec 23, 2022
286 Dec 23, 2022

A novel dual model approach for categorization of unbalanced skin lesion image classes (Presented technical paper 📃)
A novel dual model approach for categorization of unbalanced skin lesion image classes (Presented technical paper 📃)
 1 Jan 19, 2022
1 Jan 19, 2022

Visual Python and C++ nanosecond profiler, logger, tests enabler
Look into Palanteer and get an omniscient view of your program Palanteer is a set of lean and efficient tools to improve the quality of software, for
 1.9k Dec 26, 2022
1.9k Dec 26, 2022
Flow-based visual scripting for Python
A simple visual node editor for Python Ryven combines flow-based visual scripting with Python. It gives you absolute freedom for your nodes and a simp
 3.1k Jan 6, 2023
3.1k Jan 6, 2023

In this project, we compared Spanish BERT and Multilingual BERT in the Sentiment Analysis task.
Applying BERT Fine Tuning to Sentiment Classification on Amazon Reviews Abstract Sentiment analysis has made great progress in recent years, due to th
 5 Jan 3, 2022
5 Jan 3, 2022
"Exploring Vision Transformers for Fine-grained Classification" at CVPRW FGVC8
FGVC8 Exploring Vision Transformers for Fine-grained Classification paper presented at the CVPR 2021, The Eight Workshop on Fine-Grained Visual Catego
 19 Dec 6, 2022
19 Dec 6, 2022
PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluation of Visual Stories via Semantic Consistency"
Improving Generation and Evaluation of Visual Stories via Semantic Consistency PyTorch code for the NAACL 2021 paper "Improving Generation and Evaluat
 28 Dec 8, 2022
28 Dec 8, 2022
Visual dialog agents with pre-trained vision-and-language encoders.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation Or READ-UP: Referring Expression Agent Dialog with Unified Pretr
 7 Oct 8, 2022
7 Oct 8, 2022

LegoDNN: a block-grained scaling tool for mobile vision systems
Table of contents 1 Introduction 1.1 Major features 1.2 Architecture 2 Code and Installation 2.1 Code 2.2 Installation 3 Repository of DNNs in vision
 41 Dec 24, 2022
41 Dec 24, 2022

Implementations for the ICLR-2021 paper: SEED: Self-supervised Distillation For Visual Representation.
Implementations for the ICLR-2021 paper: SEED: Self-supervised Distillation For Visual Representation.
 27 Oct 23, 2022
27 Oct 23, 2022

PyFlow is a general purpose visual scripting framework for python
PyFlow is a general purpose visual scripting framework for python. State Base structure of program implemented, such things as packages disco
 1.8k Jan 7, 2023
1.8k Jan 7, 2023
Reproducing-BowNet: Learning Representations by Predicting Bags of Visual Words
Reproducing-BowNet Our reproducibility effort based on the 2020 ML Reproducibility Challenge. We are reproducing the results of this CVPR 2020 paper:
 6 Mar 16, 2022
6 Mar 16, 2022
Source codes for Improved Few-Shot Visual Classification (CVPR 2020), Enhancing Few-Shot Image Classification with Unlabelled Examples
Source codes for Improved Few-Shot Visual Classification (CVPR 2020), Enhancing Few-Shot Image Classification with Unlabelled Examples (WACV 2022) and Beyond Simple Meta-Learning: Multi-Purpose Models for Multi-Domain, Active and Continual Few-Shot Learning (TPAMI 2022 - in submission)
 42 Dec 6, 2022
42 Dec 6, 2022
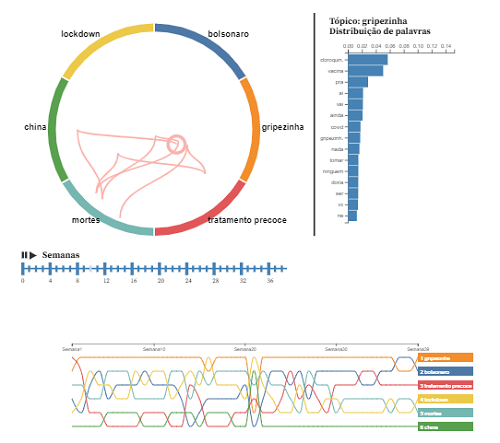
Project for the discipline of Visual Data Analysis at EMAp FGV.
Analysis of the dissemination of fake news about COVID-19 on Twitter This project was the final work for the discipline of Visual Data Analysis of the
 2 Jan 17, 2022
2 Jan 17, 2022

We present a regularized self-labeling approach to improve the generalization and robustness properties of fine-tuning.
Overview This repository provides the implementation for the paper "Improved Regularization and Robustness for Fine-tuning in Neural Networks", which
 21 Sep 8, 2022
21 Sep 8, 2022
VL-LTR: Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition
VL-LTR: Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition Usage First, install PyTorch 1.7.1+, torchvision 0.8.2
 40 Dec 12, 2022
40 Dec 12, 2022

PyTorch implementation of Lip to Speech Synthesis with Visual Context Attentional GAN (NeurIPS2021)
Lip to Speech Synthesis with Visual Context Attentional GAN This repository contains the PyTorch implementation of the following paper: Lip to Speech
 6 Nov 2, 2022
6 Nov 2, 2022
RARA: Zero-shot Sim2Real Visual Navigation with Following Foreground Cues
RARA: Zero-shot Sim2Real Visual Navigation with Following Foreground Cues FGBG (foreground-background) pytorch package for defining and training model
 1 Jun 2, 2022
1 Jun 2, 2022

Translate darknet to tensorflow. Load trained weights, retrain/fine-tune using tensorflow, export constant graph def to mobile devices
Intro Real-time object detection and classification. Paper: version 1, version 2. Read more about YOLO (in darknet) and download weight files here. In
 6.1k Jan 4, 2023
6.1k Jan 4, 2023
Housing Price Prediction Using Machine Learning.
HOUSING PRICE PREDICTION USING MACHINE LEARNING DESCRIPTION Housing Price Prediction Using Machine Learning is to predict the data of housings. Here I
 1 Aug 3, 2022
1 Aug 3, 2022
Which Apple Keeps Which Doctor Away? Colorful Word Representations with Visual Oracles
Which Apple Keeps Which Doctor Away? Colorful Word Representations with Visual Oracles (TASLP 2022)
 3 Apr 14, 2022
3 Apr 14, 2022

PyTorch implementaton of our CVPR 2021 paper "Bridging the Visual Gap: Wide-Range Image Blending"
Bridging the Visual Gap: Wide-Range Image Blending PyTorch implementaton of our CVPR 2021 paper "Bridging the Visual Gap: Wide-Range Image Blending".
 69 Dec 20, 2022
69 Dec 20, 2022

A self-supervised learning framework for audio-visual speech
AV-HuBERT (Audio-Visual Hidden Unit BERT) Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction Robust Self-Supervised A
431 Jan 7, 2023

Python3 / PyTorch implementation of the following paper: Fine-grained Semantics-aware Representation Enhancement for Self-supervisedMonocular Depth Estimation. ICCV 2021 (oral)
FSRE-Depth This is a Python3 / PyTorch implementation of FSRE-Depth, as described in the following paper: Fine-grained Semantics-aware Representation
 77 Dec 28, 2022
77 Dec 28, 2022

We propose the adversarial blur attack (ABA) against visual object tracking.
ABA We propose the adversarial blur attack (ABA) against visual object tracking. The ICCV link: https://arxiv.org/abs/2107.12085 and, https://openacce
 13 Dec 1, 2022
13 Dec 1, 2022

Train Scene Graph Generation for Visual Genome and GQA in PyTorch = 1.2 with improved zero and few-shot generalization.
Scene Graph Generation Object Detections Ground truth Scene Graph Generated Scene Graph In this visualization, woman sitting on rock is a zero-shot tr
 93 Dec 28, 2022
93 Dec 28, 2022
Code and Experiments for ACL-IJCNLP 2021 Paper Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering.
Code and Experiments for ACL-IJCNLP 2021 Paper Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering.
 50 Nov 16, 2022
50 Nov 16, 2022

Bottom-up attention model for image captioning and VQA, based on Faster R-CNN and Visual Genome
bottom-up-attention This code implements a bottom-up attention model, based on multi-gpu training of Faster R-CNN with ResNet-101, using object and at
 1.3k Jan 9, 2023
1.3k Jan 9, 2023
Fine tuning keras-ocr python package with custom synthetic dataset from scratch
OCR-Pipeline-with-Keras The keras-ocr package generally consists of two parts: a Detector and a Recognizer: Detector is responsible for creating bound
 1 Jan 5, 2022
1 Jan 5, 2022

Go from graph data to a secure and interactive visual graph app in 15 minutes. Batteries-included self-hosting of graph data apps with Streamlit, Graphistry, RAPIDS, and more!
✔️ Linux ✔️ OS X ❌ Windows (#39) Welcome to graph-app-kit Turn your graph data into a secure and interactive visual graph app in 15 minutes! Why This
 107 Jan 2, 2023
107 Jan 2, 2023

Referring Video Object Segmentation
Awesome-Referring-Video-Object-Segmentation Welcome to starts ⭐ & comments 💹 & sharing 😀 !! - 2021.12.12: Recent papers (from 2021) - welcome to ad
 57 Dec 11, 2022
57 Dec 11, 2022
PyTorch code for: Learning to Generate Grounded Visual Captions without Localization Supervision
Learning to Generate Grounded Visual Captions without Localization Supervision This is the PyTorch implementation of our paper: Learning to Generate G
 41 Nov 17, 2022
41 Nov 17, 2022