2224 Repositories
Python language-generation-dataset Libraries
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Introduction XLNet is a new unsupervised language representation learning method based on a novel generalized permutation language modeling objective.
 6k Jan 7, 2023
6k Jan 7, 2023
TensorFlow code and pre-trained models for BERT
BERT ***** New March 11th, 2020: Smaller BERT Models ***** This is a release of 24 smaller BERT models (English only, uncased, trained with WordPiece
 32.9k Jan 8, 2023
32.9k Jan 8, 2023
Example code for "Real-World Natural Language Processing"
Real-World Natural Language Processing This repository contains example code for the book "Real-World Natural Language Processing." AllenNLP (2.5.0 or
 303 Dec 17, 2022
303 Dec 17, 2022
Resources for "Natural Language Processing" Coursera course.
Natural Language Processing course resources This github contains practical assignments for Natural Language Processing course by Higher School of Eco
 1.1k Jan 1, 2023
1.1k Jan 1, 2023

Lab Materials for MIT 6.S191: Introduction to Deep Learning
This repository contains all of the code and software labs for MIT 6.S191: Introduction to Deep Learning! All lecture slides and videos are available
 5.6k Dec 26, 2022
5.6k Dec 26, 2022
nlp-tutorial is a tutorial for who is studying NLP(Natural Language Processing) using Pytorch
nlp-tutorial is a tutorial for who is studying NLP(Natural Language Processing) using Pytorch. Most of the models in NLP were implemented with less than 100 lines of code.(except comments or blank lines)
 11.9k Jan 8, 2023
11.9k Jan 8, 2023
Transpiler for Excel formula like language to Python. Support script and module mode
Transpiler for Excel formula like language to Python. Support script and module mode (formulas are functions).
 1 Dec 7, 2021
1 Dec 7, 2021

Biterm Topic Model (BTM): modeling topics in short texts
Biterm Topic Model Bitermplus implements Biterm topic model for short texts introduced by Xiaohui Yan, Jiafeng Guo, Yanyan Lan, and Xueqi Cheng. Actua
 49 Dec 30, 2022
49 Dec 30, 2022
A simple pygame implementation of the LOGO programming language.
LOGO-py A simple pygame implementation of the LOGO programming language. Latest Version Notes Fixed a bug where penup/pendown would not work properly.
 1 Dec 5, 2021
1 Dec 5, 2021

This repository will help you get label for images in Stanford Cars Dataset.
STANFORD CARS DATASET stanford-cars "The Cars dataset contains 16,185 images of 196 classes of cars. The data is split into 8,144 training images and
 3 Sep 20, 2022
3 Sep 20, 2022
Json2Xml tool will help you convert from json COCO format to VOC xml format in Object Detection Problem.
JSON 2 XML All codes assume running from root directory. Please update the sys path at the beginning of the codes before running. Over View Json2Xml t
6 Aug 22, 2022
topic modeling on unstructured data in Space news articles retrieved from the Guardian (UK) newspaper using API
NLP Space News Topic Modeling Photos by nasa.gov (1, 2, 3, 4, 5) and extremetech.com Table of Contents Project Idea Data acquisition Primary data sour
 1 Jan 3, 2022
1 Jan 3, 2022
Python client SDK designed to simplify integrations by automating key generation and certificate enrollment using Venafi machine identity services.
This open source project is community-supported. To report a problem or share an idea, use Issues; and if you have a suggestion for fixing the issue,
 13 Sep 27, 2022
13 Sep 27, 2022

This project uses unsupervised machine learning to identify correlations between daily inoculation rates in the USA and twitter sentiment in regards to COVID-19.
Twitter COVID-19 Sentiment Analysis Members: Christopher Bach | Khalid Hamid Fallous | Jay Hirpara | Jing Tang | Graham Thomas | David Wetherhold Pro
 4 Oct 15, 2022
4 Oct 15, 2022
Taichi is a parallel programming language for high-performance numerical computations.
Taichi is a parallel programming language for high-performance numerical computations.
 22k Jan 4, 2023
22k Jan 4, 2023
rst2pdf: Use a text editor. Make a PDF.
rst2pdf: Use a text editor. Make a PDF.
 487 Jan 6, 2023
487 Jan 6, 2023

iAWE is a wonderful dataset for those of us who work on Non-Intrusive Load Monitoring (NILM) algorithms.
iAWE is a wonderful dataset for those of us who work on Non-Intrusive Load Monitoring (NILM) algorithms. You can find its main page and description via this link. If you are familiar with NILM-TK API, you probably know that you can work with iAWE hdf5 data file in NILM-TK.
 3 Mar 19, 2022
3 Mar 19, 2022

Neurons Dataset API - The official dataloader and visualization tools for Neurons Datasets.
Neurons Dataset API - The official dataloader and visualization tools for Neurons Datasets. Introduction We propose our dataloader API for loading and
 1 Nov 19, 2021
1 Nov 19, 2021

VGGFace2-HQ - A high resolution face dataset for face editing purpose
The first open source high resolution dataset for face swapping!!! A high resolution version of VGGFace2 for academic face editing purpose
 232 Dec 29, 2022
232 Dec 29, 2022
The implementation of DeBERTa
DeBERTa: Decoding-enhanced BERT with Disentangled Attention This repository is the official implementation of DeBERTa: Decoding-enhanced BERT with Dis
 1.2k Jan 6, 2023
1.2k Jan 6, 2023
A pre-trained language model for social media text in Spanish
RoBERTuito A pre-trained language model for social media text in Spanish READ THE FULL PAPER Github Repository RoBERTuito is a pre-trained language mo
 25 Dec 29, 2022
25 Dec 29, 2022
A number of methods in order to perform Natural Language Processing on live data derived from Twitter
A number of methods in order to perform Natural Language Processing on live data derived from Twitter
 1 Nov 24, 2021
1 Nov 24, 2021

Official PyTorch implementation of "BlendGAN: Implicitly GAN Blending for Arbitrary Stylized Face Generation" (NeurIPS 2021)
BlendGAN: Implicitly GAN Blending for Arbitrary Stylized Face Generation Official PyTorch implementation of the NeurIPS 2021 paper Mingcong Liu, Qiang
 462 Dec 29, 2022
462 Dec 29, 2022
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
 1.4k Jan 4, 2023
1.4k Jan 4, 2023
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 A repository part of the MarIA project. Corpora 📃 Corpora Number of documents Number of tokens Size (GB) BNE 201,080,084
 203 Dec 20, 2022
203 Dec 20, 2022

SHIFT15M: multiobjective large-scale fashion dataset with distributional shifts
[arXiv] The main motivation of the SHIFT15M project is to provide a dataset that contains natural dataset shifts collected from a web service IQON, wh
 138 Nov 24, 2022
138 Nov 24, 2022
Code for text augmentation method leveraging large-scale language models
HyperMix Code for our paper GPT3Mix and conducting classification experiments using GPT-3 prompt-based data augmentation. Getting Started Installing P
 47 Dec 20, 2022
47 Dec 20, 2022
Eros is an expiremental programming language built using simple Python code.
Eros is an expiremental programming language built using simple Python code. Featuring an easy syntax and unique features like type slicing, the language remains an expirement that grows in down time.
 2 Nov 21, 2021
2 Nov 21, 2021
Reproduction process of BERT on SST2 dataset
BERT-SST2-Prod Reproduction process of BERT on SST2 dataset 安装说明 下载代码库 git clone https://github.com/JunnYu/BERT-SST2-Prod 进入文件夹,安装requirements pip ins
 1 Nov 18, 2021
1 Nov 18, 2021
PyTorch Kafka Dataset: A definition of a dataset to get training data from Kafka.
PyTorch Kafka Dataset: A definition of a dataset to get training data from Kafka.
 7 Aug 1, 2022
7 Aug 1, 2022
Code for training and evaluation of the model from "Language Generation with Recurrent Generative Adversarial Networks without Pre-training"
Language Generation with Recurrent Generative Adversarial Networks without Pre-training Code for training and evaluation of the model from "Language G
 253 Sep 14, 2022
253 Sep 14, 2022

MoCoGAN: Decomposing Motion and Content for Video Generation
MoCoGAN: Decomposing Motion and Content for Video Generation This repository contains an implementation and further details of MoCoGAN: Decomposing Mo
 514 Dec 18, 2022
514 Dec 18, 2022
natural image generation using ConvNets
The Eyescream Project Generating Natural Images using Neural Networks. For our research summary on this work, please read the Arxiv paper: http://arxi
 601 Nov 23, 2022
601 Nov 23, 2022
GitHub repository for "Improving Video Generation for Multi-functional Applications"
Improving Video Generation for Multi-functional Applications GitHub repository for "Improving Video Generation for Multi-functional Applications" Pape
 328 Dec 7, 2022
328 Dec 7, 2022

GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data
GeneGAN: Learning Object Transfiguration and Attribute Subspace from Unpaired Data By Shuchang Zhou, Taihong Xiao, Yi Yang, Dieqiao Feng, Qinyao He, W
 141 Apr 16, 2021
141 Apr 16, 2021

Pytorch implementation AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks
AttnGAN Pytorch implementation for reproducing AttnGAN results in the paper AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative
 1.2k Dec 26, 2022
1.2k Dec 26, 2022

Official repository for ABC-GAN
ABC-GAN The work represented in this repository is the result of a 14 week semesterthesis on photo-realistic image generation using generative adversa
 10 Jun 23, 2022
10 Jun 23, 2022

A repository for the paper "Improved Adversarial Systems for 3D Object Generation and Reconstruction".
Improved Adversarial Systems for 3D Object Generation and Reconstruction: This is a repository for the paper "Improved Adversarial Systems for 3D Obje
 188 Dec 25, 2022
188 Dec 25, 2022
Training, generation, and analysis code for Learning Particle Physics by Example: Location-Aware Generative Adversarial Networks for Physics
Location-Aware Generative Adversarial Networks (LAGAN) for Physics Synthesis This repository contains all the code used in L. de Oliveira (@lukedeo),
 57 Oct 22, 2022
57 Oct 22, 2022

Software that can generate photos from paintings, turn horses into zebras, perform style transfer, and more.
CycleGAN PyTorch | project page | paper Torch implementation for learning an image-to-image translation (i.e. pix2pix) without input-output pairs, for
 11.5k Dec 30, 2022
11.5k Dec 30, 2022

Image-to-image translation with conditional adversarial nets
pix2pix Project | Arxiv | PyTorch Torch implementation for learning a mapping from input images to output images, for example: Image-to-Image Translat
 9.3k Jan 8, 2023
9.3k Jan 8, 2023

Interactive Image Generation via Generative Adversarial Networks
iGAN: Interactive Image Generation via Generative Adversarial Networks Project | Youtube | Paper Recent projects: [pix2pix]: Torch implementation for
3.9k Dec 23, 2022

A DCGAN to generate anime faces using custom mined dataset
Anime-Face-GAN-Keras A DCGAN to generate anime faces using custom dataset in Keras. Dataset The dataset is created by crawling anime database websites
 190 Jan 3, 2023
190 Jan 3, 2023

Extract rooms type, door, neibour rooms, rooms corners nad bounding boxes, and generate graph from rplan dataset
Housegan-data-reader House-GAN++ (data-reader) Code and instructions for converting rplan dataset (raster images) to housegan++ data format. House-GAN
 13 Nov 24, 2022
13 Nov 24, 2022

Powerful and efficient Computer Vision Annotation Tool (CVAT)
Computer Vision Annotation Tool (CVAT) CVAT is free, online, interactive video and image annotation tool for computer vision. It is being used by our
 8.6k Jan 1, 2023
8.6k Jan 1, 2023
Exemplary lightweight and ready-to-deploy machine learning project
Exemplary lightweight and ready-to-deploy machine learning project
 6 Dec 20, 2022
6 Dec 20, 2022
For making Tagtog annotation into csv dataset
tagtog_relation_extraction for making Tagtog annotation into csv dataset How to Use On Tagtog 1. Go to Project Downloads 2. Download all documents,
 4 Dec 28, 2021
4 Dec 28, 2021
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding
CLUES: Few-Shot Learning Evaluation in Natural Language Understanding This repo contains the data and source code for baseline models in the NeurIPS 2
10 Nov 17, 2021
An experimental Python-to-C transpiler and domain specific language for embedded high-performance computing
An experimental Python-to-C transpiler and domain specific language for embedded high-performance computing
 562 Dec 28, 2022
562 Dec 28, 2022
Simple Baselines for Human Pose Estimation and Tracking
Simple Baselines for Human Pose Estimation and Tracking News Our new work High-Resolution Representations for Labeling Pixels and Regions is available
2.7k Jan 5, 2023

 1.2k Dec 26, 2022
1.2k Dec 26, 2022
implementation of the KNN algorithm on crab biometrics dataset for CS16
crab-knn implementation of the KNN algorithm in Python applied to biometrics data of purple rock crabs (leptograpsus variegatus) to classify the sex o
 1 Nov 18, 2021
1 Nov 18, 2021
A socket script to obtain chinese phones-sequence for any english word
Foreign Pronunciation Generator (English-Chinese) We provide a simple socket script for acquiring Chinese pronunciation of English words (phones in ai
 5 Jul 25, 2022
5 Jul 25, 2022
CCQA A New Web-Scale Question Answering Dataset for Model Pre-Training
CCQA: A New Web-Scale Question Answering Dataset for Model Pre-Training This is the official repository for the code and models of the paper CCQA: A N
 29 Nov 30, 2022
29 Nov 30, 2022
Hamming code generation, error detection & correction.
Hamming code generation, error detection & correction.
 2 Jun 30, 2022
2 Jun 30, 2022
Python library for Serbian Natural language processing (NLP)
SrbAI - Python biblioteka za procesiranje srpskog jezika SrbAI je projekat prikupljanja algoritama i modela za procesiranje srpskog jezika u jedinstve
 3 Nov 22, 2022
3 Nov 22, 2022
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository will provide the official PyTorch implementa
 238 Nov 25, 2022
238 Nov 25, 2022
Extracting and filtering paraphrases by bridging natural language inference and paraphrasing
nli2paraphrases Source code repository accompanying the preprint Extracting and filtering paraphrases by bridging natural language inference and parap
 1 Mar 9, 2022
1 Mar 9, 2022

This repository contains the needed resources to build the HIRID-ICU-Benchmark dataset
HiRID-ICU-Benchmark This repository contains the needed resources to build the HIRID-ICU-Benchmark dataset for which the manuscript can be found here.
 30 Dec 16, 2022
30 Dec 16, 2022
Extracting knowledge graphs from language models as a diagnostic benchmark of model performance.
Interpreting Language Models Through Knowledge Graph Extraction Idea: How do we interpret what a language model learns at various stages of training?
 9 Oct 25, 2022
9 Oct 25, 2022
Source code for our EMNLP'21 paper 《Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning》
Child-Tuning Source code for EMNLP 2021 Long paper: Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning. 1. Environ
 46 Dec 12, 2022
46 Dec 12, 2022

TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning
TaCL: Improving BERT Pre-training with Token-aware Contrastive Learning Authors: Yixuan Su, Fangyu Liu, Zaiqiao Meng, Lei Shu, Ehsan Shareghi, and Nig
 21 Nov 17, 2021
21 Nov 17, 2021
AfriBERTa: Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages
AfriBERTa: Exploring the Viability of Pretrained Multilingual Language Models for Low-resourced Languages This repository contains the code for the pa
 40 Nov 24, 2022
40 Nov 24, 2022
Voice helper on russian
Voice helper on russian
 1 Jun 30, 2022
1 Jun 30, 2022
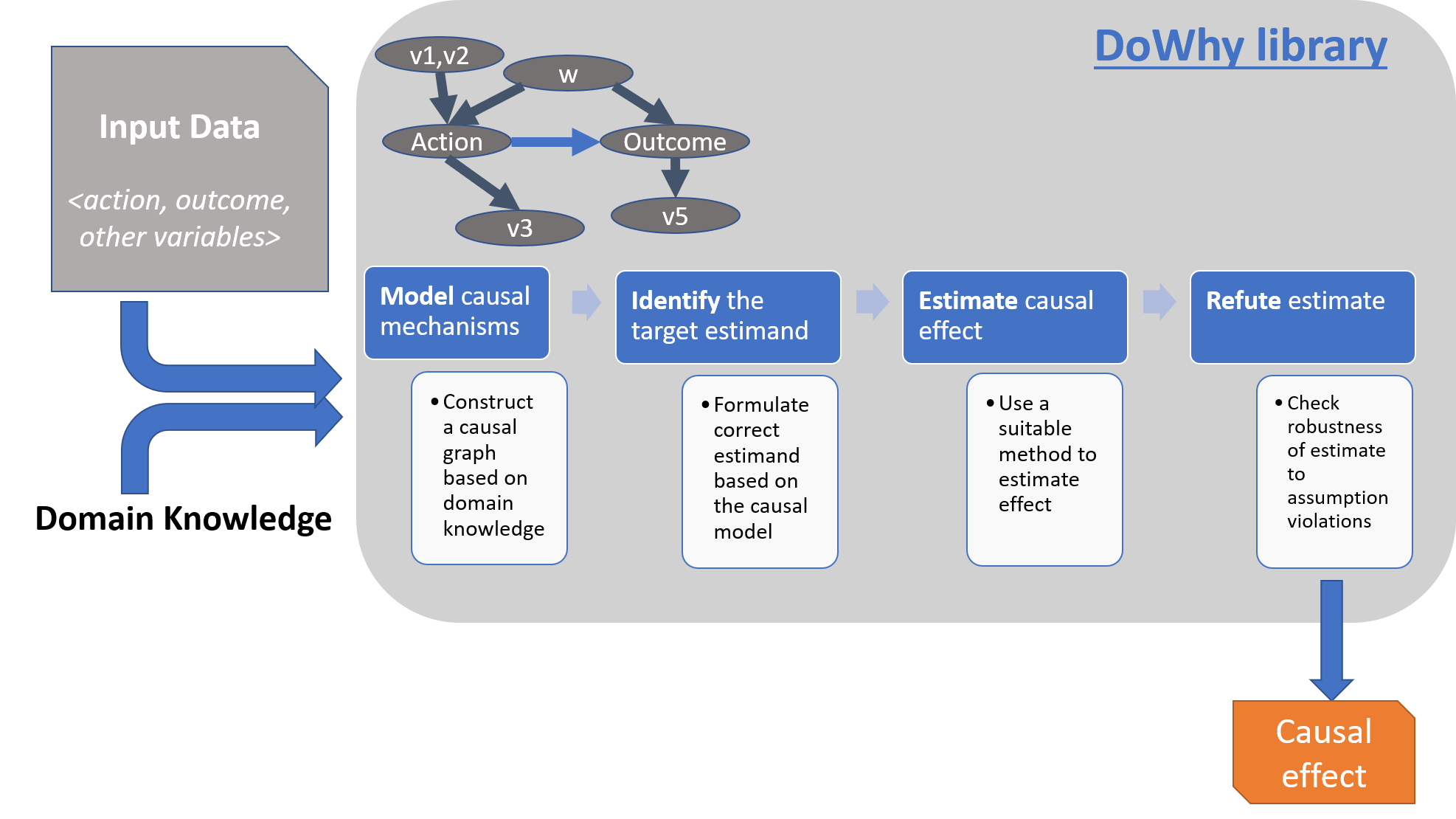
DoWhy is a Python library for causal inference that supports explicit modeling and testing of causal assumptions. DoWhy is based on a unified language for causal inference, combining causal graphical models and potential outcomes frameworks.
DoWhy | An end-to-end library for causal inference Amit Sharma, Emre Kiciman Introducing DoWhy and the 4 steps of causal inference | Microsoft Researc
5.6k Jan 7, 2023
moDel Agnostic Language for Exploration and eXplanation
moDel Agnostic Language for Exploration and eXplanation Overview Unverified black box model is the path to the failure. Opaqueness leads to distrust.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023
CVXPY is a Python-embedded modeling language for convex optimization problems.
CVXPY The CVXPY documentation is at cvxpy.org. We are building a CVXPY community on Discord. Join the conversation! For issues and long-form discussio
 4.3k Jan 8, 2023
4.3k Jan 8, 2023
GiantMIDI-Piano is a classical piano MIDI dataset contains 10,854 MIDI files of 2,786 composers
GiantMIDI-Piano is a classical piano MIDI dataset contains 10,854 MIDI files of 2,786 composers
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
🚪✊Knock Knock: Get notified when your training ends with only two additional lines of code
Knock Knock A small library to get a notification when your training is complete or when it crashes during the process with two additional lines of co
 2.5k Jan 7, 2023
2.5k Jan 7, 2023

Using modified BiSeNet for face parsing in PyTorch
face-parsing.PyTorch Contents Training Demo References Training Prepare training data: -- download CelebAMask-HQ dataset -- change file path in the pr
 1.6k Jan 8, 2023
1.6k Jan 8, 2023
TensorFlow implementation of ENet, trained on the Cityscapes dataset.
segmentation TensorFlow implementation of ENet (https://arxiv.org/pdf/1606.02147.pdf) based on the official Torch implementation (https://github.com/e
 248 Dec 16, 2022
248 Dec 16, 2022

Semantic segmentation task for ADE20k & cityscapse dataset, based on several models.
semantic-segmentation-tensorflow This is a Tensorflow implementation of semantic segmentation models on MIT ADE20K scene parsing dataset and Cityscape
 83 Oct 13, 2022
83 Oct 13, 2022
Using fully convolutional networks for semantic segmentation with caffe for the cityscapes dataset
Using fully convolutional networks for semantic segmentation (Shelhamer et al.) with caffe for the cityscapes dataset How to get started Download the
 27 Jun 6, 2022
27 Jun 6, 2022
PyTorch Implementations for DeeplabV3 and PSPNet
Pytorch-segmentation-toolbox DOC Pytorch code for semantic segmentation. This is a minimal code to run PSPnet and Deeplabv3 on Cityscape dataset. Shor
 746 Dec 15, 2022
746 Dec 15, 2022

This is an (re-)implementation of DeepLab-ResNet in TensorFlow for semantic image segmentation on the PASCAL VOC dataset.
DeepLab-ResNet-TensorFlow This is an (re-)implementation of DeepLab-ResNet in TensorFlow for semantic image segmentation on the PASCAL VOC dataset. Up
 19 Jan 16, 2022
19 Jan 16, 2022
UNet model with VGG11 encoder pre-trained on Kaggle Carvana dataset
TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation By Vladimir Iglovikov and Alexey Shvets Introduction TernausNet is
 1k Dec 28, 2022
1k Dec 28, 2022
Python package for Turkish Language.
PyTurkce Python package for Turkish Language. Documentation: https://pyturkce.readthedocs.io. Installation pip install pyturkce Usage from pyturkce im
 14 Oct 9, 2022
14 Oct 9, 2022
A combination of autoregressors and autoencoders using XLNet for sentiment analysis
A combination of autoregressors and autoencoders using XLNet for sentiment analysis Abstract In this paper sentiment analysis has been performed in or
 2 Nov 20, 2021
2 Nov 20, 2021

Code for our EMNLP 2021 paper “Heterogeneous Graph Neural Networks for Keyphrase Generation”
GATER This repository contains the code for our EMNLP 2021 paper “Heterogeneous Graph Neural Networks for Keyphrase Generation”. Our implementation is
 12 Nov 24, 2022
12 Nov 24, 2022
Identifies the faulty wafer before it can be used for the fabrication of integrated circuits and, in photovoltaics, to manufacture solar cells.
Identifies the faulty wafer before it can be used for the fabrication of integrated circuits and, in photovoltaics, to manufacture solar cells. The project retrains itself after every prediction, making it more robust and generalized over time.
 2 Jul 1, 2022
2 Jul 1, 2022
Nateve compiler developed with python.
Adam Adam is a Nateve Programming Language compiler developed using Python. Nateve Nateve is a new general domain programming language open source ins
 7 Jan 15, 2022
7 Jan 15, 2022
Recommendation System to recommend top books from the dataset
recommendersystem Recommendation System to recommend top books from the dataset Introduction The recom.py is the main program code. The dataset is als
 1 Nov 15, 2021
1 Nov 15, 2021
Python dataset creator to construct datasets composed of OpenFace extracted features and Shimmer3 GSR+ Sensor datas
Python dataset creator to construct datasets composed of OpenFace extracted features and Shimmer3 GSR+ Sensor datas
 3 Jul 5, 2022
3 Jul 5, 2022
FS-Mol: A Few-Shot Learning Dataset of Molecules
FS-Mol is A Few-Shot Learning Dataset of Molecules, containing molecular compounds with measurements of activity against a variety of protein targets. The dataset is presented with a model evaluation benchmark which aims to drive few-shot learning research in the domain of molecules and graph-structured data.
114 Dec 15, 2022
🕟 Date and time processing language
Date Time Expression dte is a WIP date-time processing language with focus on broad interpretation. If you don't think it's intuitive, it's most likel
 303 Dec 19, 2022
303 Dec 19, 2022

History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
 46 Nov 23, 2022
46 Nov 23, 2022

Python bindings for JIGSAW: a Delaunay-based unstructured mesh generator.
JIGSAW: An unstructured mesh generator JIGSAW is an unstructured mesh generator and tessellation library; designed to generate high-quality triangulat
 26 Dec 13, 2022
26 Dec 13, 2022

Source code for our paper "Empathetic Response Generation with State Management"
Source code for our paper "Empathetic Response Generation with State Management" this repository is maintained by both Jun Gao and Yuhan Liu Model Ove
 3 Oct 8, 2022
3 Oct 8, 2022

Source code for our paper "Improving Empathetic Response Generation by Recognizing Emotion Cause in Conversations"
Source code for our paper "Improving Empathetic Response Generation by Recognizing Emotion Cause in Conversations" this repository is maintained by bo
24 Nov 29, 2022
Blazing fast language detection using fastText model
Luga A blazing fast language detection using fastText's language models Luga is a Swahili word for language. fastText provides a blazing fast language
 18 Dec 20, 2022
18 Dec 20, 2022
Luminous is a framework for testing the performance of Embodied AI (EAI) models in indoor tasks.
Luminous is a framework for testing the performance of Embodied AI (EAI) models in indoor tasks. Generally, we intergrete different kind of functional
 28 Jan 8, 2023
28 Jan 8, 2023
A Python script to convert your favorite TV series into an Anki deck.
Ankiniser A Python3.8 script to convert your favorite TV series into an Anki deck. How to install? Download the script with git or download it manualy
 37 Nov 3, 2022
37 Nov 3, 2022
A flag generation AI created using DeepAIs API
Vex AI or Vexiology AI is an Artifical Intelligence created to generate custom made flag design texts. It uses DeepAIs API. Please be aware that you must include your own DeepAI API key. See instructions below for more information.
 10 Apr 6, 2022
10 Apr 6, 2022
Simple python tool for the purpose of swapping latinic letters with cirilic ones and vice versa in txt, docx and pdf files in Serbian language
Alpha Swap English This is a simple python tool for the purpose of swapping latinic letters with cirylic ones and vice versa, in txt, docx and pdf fil
 3 May 31, 2022
3 May 31, 2022
An Agora Python Flask token generation server
A Flask Starter Application with Login and Registration About A token generation Server using the factory pattern and Blueprints. A forked stripped do
 1 Jan 21, 2022
1 Jan 21, 2022
History Aware Multimodal Transformer for Vision-and-Language Navigation
History Aware Multimodal Transformer for Vision-and-Language Navigation This repository is the official implementation of History Aware Multimodal Tra
46 Nov 23, 2022
We have built a Voice based Personal Assistant for people to access files hands free in their device using natural language processing.
Voice Based Personal Assistant We have built a Voice based Personal Assistant for people to access files hands free in their device using natural lang
 2 Nov 13, 2021
2 Nov 13, 2021
Partially offline multi-language translator built upon Huggingface transformers.
Translate Command-line interface to translation pipelines, powered by Huggingface transformers. This tool can download translation models, and then us
 8 Oct 25, 2022
8 Oct 25, 2022
CiteURL is an extensible tool that parses legal citations and makes links to websites where you can read the cited language for free.
CiteURL is an extensible tool that parses legal citations and makes links to websites where you can read the cited language for free. It can be used t
 15 Dec 27, 2022
15 Dec 27, 2022
PyKaldi is a Python scripting layer for the Kaldi speech recognition toolkit.
PyKaldi is a Python scripting layer for the Kaldi speech recognition toolkit. It provides easy-to-use, low-overhead, first-class Python wrappers for t
 922 Dec 31, 2022
922 Dec 31, 2022