76 Repositories
Python lyric-crawler Libraries

Dude is a very simple framework for writing web scrapers using Python decorators
Dude is a very simple framework for writing web scrapers using Python decorators. The design, inspired by Flask, was to easily build a web scraper in just a few lines of code. Dude has an easy-to-learn syntax.
 326 Dec 15, 2022
326 Dec 15, 2022

BLYRIC is a Twitter bot that tweets a song lyric every night.
BLYRIC BLYRIC, a bot that tweets a song lyric every night. Follow on Twitter: @blyric_ Overview BLYRIC is a Twitter bot that tweets a song quote every
 6 Oct 5, 2022
6 Oct 5, 2022
🕷 Phone Crawler with multi-thread functionality
Phone Crawler: Phone Crawler with multi-thread functionality Disclaimer: I'm not responsible for any illegal/misuse actions, this program was made for
 3 Feb 10, 2022
3 Feb 10, 2022
This repo has the source code for the crawler and data crawled from auto-data.net
This repo contains the source code for crawler and crawled data of cars specifications from autodata. The data has roughly 45k cars
 5 Nov 22, 2022
5 Nov 22, 2022
Python project that aims to discover CDP neighbors and map their Layer-2 topology within a shareable medium like Visio or Draw.io.
Python project that aims to discover CDP neighbors and map their Layer-2 topology within a shareable medium like Visio or Draw.io.
 3 Feb 11, 2022
3 Feb 11, 2022
Python script for crawling ResearchGate.net papers✨⭐️📎
ResearchGate Crawler Python script for crawling ResearchGate.net papers About the script This code start crawling process by urls in start.txt and giv
 4 Aug 30, 2022
4 Aug 30, 2022
Meme-videos - Scrapes memes and turn them into a video compilations
Meme Videos Scrapes memes from reddit using praw and request and then converts t
 12 Oct 28, 2022
12 Oct 28, 2022
Amazon web scraping using Scrapy Framework
Amazon-web-scraping-using-Scrapy-Framework Scrapy Scrapy is an application framework for crawling web sites and extracting structured data which can b
 1 Jan 25, 2022
1 Jan 25, 2022

Python script that reads Aliexpress offers urls from a Excel filename (.csv) and post then in a Telegram channel using a bot
Aliexpress to telegram post Python script that reads Aliexpress offers urls from a Excel filename (.csv) and post then in a Telegram channel using a b
 6 Dec 6, 2022
6 Dec 6, 2022
Video Games Web Scraper is a project that crawls websites and APIs and extracts video game related data from their pages.
Video Games Web Scraper Video Games Web Scraper is a project that crawls websites and APIs and extracts video game related data from their pages. This
 1 Jan 12, 2022
1 Jan 12, 2022
This is a simple website crawler which asks for a website link from the user to crawl and find specific data from the given website address.
This is a simple website crawler which asks for a website link from the user to crawl and find specific data from the given website address.
 1 Jan 10, 2022
1 Jan 10, 2022
Check bookings for TUM libraries.
TUM Library Checker Only for educational purposes This repository contains a crawler to save bookings for TUM libraries in a CSV file. Sample data fro
 3 Jan 27, 2022
3 Jan 27, 2022
A web crawler for recording posts in "sina weibo"
Web Crawler for "sina weibo" A web crawler for recording posts in "sina weibo" Introduction This script helps collect attributes of posts in "sina wei
 4 Aug 20, 2022
4 Aug 20, 2022

A Telegram crawler to search groups and channels automatically and collect any type of data from them.
Introduction This is a crawler I wrote in Python using the APIs of Telethon months ago. This tool was not intended to be publicly available for a numb
 39 Dec 28, 2022
39 Dec 28, 2022

High available distributed ip proxy pool, powerd by Scrapy and Redis
高可用IP代理池 README | 中文文档 本项目所采集的IP资源都来自互联网,愿景是为大型爬虫项目提供一个高可用低延迟的高匿IP代理池。 项目亮点 代理来源丰富 代理抓取提取精准 代理校验严格合理 监控完备,鲁棒性强 架构灵活,便于扩展 各个组件分布式部署 快速开始 注意,代码请在release
 5.2k Jan 3, 2023
5.2k Jan 3, 2023
A distributed crawler for weibo, building with celery and requests.
A distributed crawler for weibo, building with celery and requests.
4.8k Jan 3, 2023
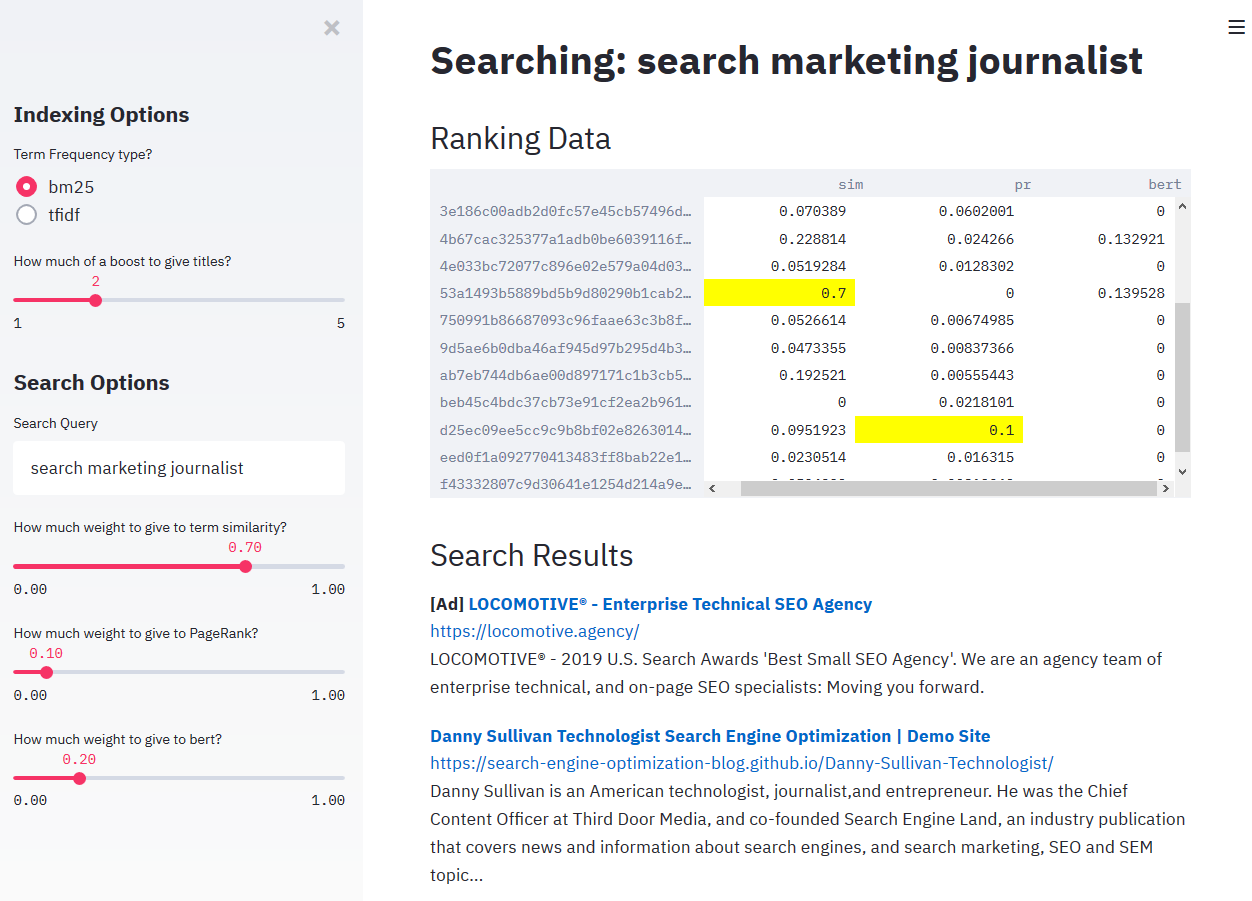
Build a small, 3 domain internet using Github pages and Wikipedia and construct a crawler to crawl, render, and index.
TechSEO Crawler Build a small, 3 domain internet using Github pages and Wikipedia and construct a crawler to crawl, render, and index. Play with the r
 57 Nov 24, 2022
57 Nov 24, 2022
Amazon scraper using scrapy, a python framework for crawling websites.
#Amazon-web-scraper This is a python program, which use scrapy python framework to crawl all pages of the product and scrap products data. This progra
 1 Dec 26, 2021
1 Dec 26, 2021
Create crawler get some new products with maximum discount in banimode website
crawler-banimode create crawler and get some new products with maximum discount in banimode website. این پروژه کوچک جهت یادگیری و کار با ابزار سلنیوم
 2 Feb 17, 2022
2 Feb 17, 2022
Screen scraping and web crawling framework
Pomp Pomp is a screen scraping and web crawling framework. Pomp is inspired by and similar to Scrapy, but has a simpler implementation that lacks the
 61 Jun 21, 2021
61 Jun 21, 2021
Python Testing Crawler 🐍 🩺 🕷️ A crawler for automated functional testing of a web application
Python Testing Crawler 🐍 🩺 🕷️ A crawler for automated functional testing of a web application Crawling a server-side-rendered web application is a
 70 Aug 7, 2022
70 Aug 7, 2022

coURLan: Clean, filter, normalize, and sample URLs
coURLan: Clean, filter, normalize, and sample URLs Why coURLan? “Given that the bandwidth for conducting crawls is neither infinite nor free, it is be
 20 Dec 14, 2022
20 Dec 14, 2022
Crawl BookCorpus
These are scripts to reproduce BookCorpus by yourself.
 590 Jan 3, 2023
590 Jan 3, 2023
This is a web crawler that works on employ email data by gmane.org and visualizes it in different ways.
crawler_to_visual_gmane Analyzing an EMAIL Archive from gmane and vizualizing the data using the D3 JavaScript library. This is a set of tools that al
 1 Dec 20, 2021
1 Dec 20, 2021

PaperRobot: a paper crawler that can quickly download numerous papers, facilitating paper studying and management
PaperRobot PaperRobot 是一个论文抓取工具,可以快速批量下载大量论文,方便后期进行持续的论文管理与学习。 PaperRobot通过多个接口抓取论文,目前抓取成功率维持在90%以上。通过配置Config文件,可以抓取任意计算机领域相关会议的论文。 Installation Down
 47 Nov 23, 2022
47 Nov 23, 2022
An Amazon Product Scraper built using scapy module of python
Amazon Product Scraper This is an Amazon Product Scraper built using scapy module of python Features it scrape various things Product Title Product Im
 1 Dec 13, 2021
1 Dec 13, 2021
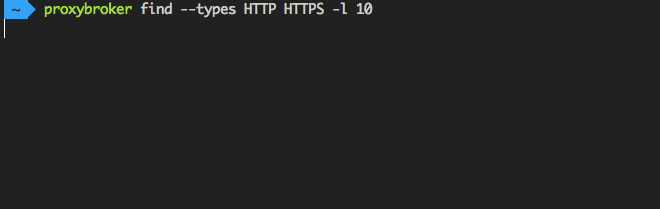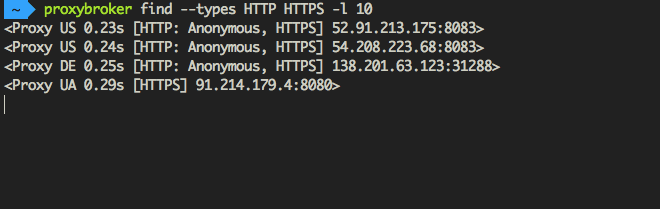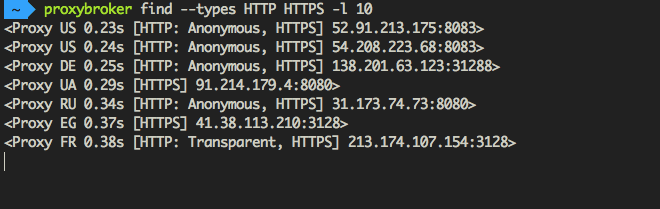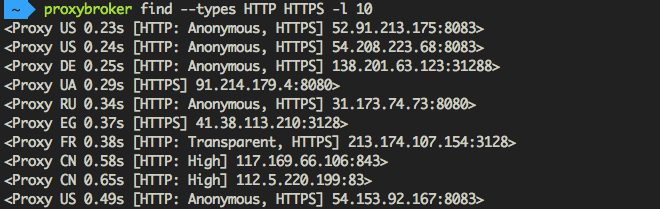
ProxyBroker is an open source tool that asynchronously finds public proxies from multiple sources and concurrently checks them
ProxyBroker is an open source tool that asynchronously finds public proxies from multiple sources and concurrently checks them. Features F
 3.2k Jan 4, 2023
3.2k Jan 4, 2023
A dead simple crawler to get books information from Douban.
Introduction A dead simple crawler to get books information from Douban. Pre-requesites Python 3 Install dependencies from requirements.txt (Optional)
 1 Jan 10, 2022
1 Jan 10, 2022
A dead simple crawler to get books information from Douban.
Introduction A dead simple crawler to get books information from Douban. Pre-requesites Python 3 Install dependencies from requirements.txt (Optional)
1 Jan 10, 2022

About Solve CTF offline disconnection problem - based on python3's small crawler
About Solve CTF offline disconnection problem - based on python3's small crawler, support keyword search and local map bed establishment, currently support Jianshu, xianzhi,anquanke,freebuf,seebug
 32 Oct 25, 2022
32 Oct 25, 2022
Rottentomatoes, Goodreads and IMDB sites crawler. Semantic Web final project.
Crawler Rottentomatoes, Goodreads and IMDB sites crawler. Crawler written by beautifulsoup, selenium and lxml to gather books and films information an
 1 Dec 30, 2021
1 Dec 30, 2021
Building house price data pipelines with Apache Beam and Spark on GCP
This project contains the process from building a web crawler to extract the raw data of house price to create ETL pipelines using Google Could Platform services.
 1 Nov 22, 2021
1 Nov 22, 2021
Google Maps crawler using Selenium
Google Maps Crawler using Selenium Built as part of the Antifragile Dev Project Selenium crawler that browses Google Maps as a regular user and stores
 46 Dec 16, 2022
46 Dec 16, 2022

Python script to check if there is any differences in responses of an application when the request comes from a search engine's crawler.
crawlersuseragents This Python script can be used to check if there is any differences in responses of an application when the request comes from a se
 13 Dec 27, 2022
13 Dec 27, 2022
A Pixiv web crawler module
Pixiv-spider A Pixiv spider module WARNING It's an unfinished work, browsing the code carefully before using it. Features 0004 - Readme.md updated, co
 1 Nov 14, 2021
1 Nov 14, 2021
A multithreaded tool for searching and downloading images from popular search engines. It is straightforward to set up and run!
🕳️ CygnusX1 Code by Trong-Dat Ngo. Overviews 🕳️ CygnusX1 is a multithreaded tool 🛠️ , used to search and download images from popular search engine
 32 Dec 31, 2022
32 Dec 31, 2022
Crawler do site Fundamentus.com com o uso do framework scrapy, tanto da aba detalhada como a de resumo.
Crawler do site Fundamentus.com com o uso do framework scrapy, tanto da aba detalhada como a de resumo. (Todas as infomações)
 3 Oct 4, 2022
3 Oct 4, 2022
Deep Web Miner Python | Spyder Crawler
Webcrawler written in Python. This crawler does dig in till the 3 level of inside addressed and mine the respective data accordingly
 17 Jan 24, 2022
17 Jan 24, 2022

eyes is a Public Opinion Mining System focusing on taiwanese forums such as PTT, Dcard.
eyes is a Public Opinion Mining System focusing on taiwanese forums such as PTT, Dcard. Features 🔥 Article monitor: helps you capture the trend at a
 116 Dec 29, 2022
116 Dec 29, 2022
A web crawler script that crawls the target website and lists its links
A web crawler script that crawls the target website and lists its links || A web crawler script that lists links by scanning the target website.
 2 Apr 29, 2022
2 Apr 29, 2022
A crawler of doubamovie
豆瓣电影 A crawler of doubamovie 一个小小的入门级scrapy框架的应用,选取豆瓣电影对排行榜前1000的电影数据进行爬取。 spider.py start_requests方法为scrapy的方法,我们对它进行重写。 def start_requests(self):
 1 Oct 5, 2021
1 Oct 5, 2021

Crawler job that scrapes comments from social media posts and saves them in a S3 bucket.
Toxicity comments crawler Crawler job that scrapes comments from social media posts and saves them in a S3 bucket. Twitter Tweets and replies are scra
 2 Jan 24, 2022
2 Jan 24, 2022

Audio media crawler for lbry.
Audio media crawler for lbry. Requirements Python 3.8 Poetry 1.1.7 Elasticsearch 7.14.0 Lbry-sdk 0.99.0 Development This project uses poetry as a depe
 4 Dec 3, 2022
4 Dec 3, 2022
A Python package that scrapes Google News article data while remaining undetected by Google.
A Python package that scrapes Google News article data while remaining undetected by Google. Our scraper can scrape page data up until the last page and never trigger a CAPTCHA (download stats: https://pepy.tech/project/GoogleNewsScraper)
 6 Aug 10, 2022
6 Aug 10, 2022

Console application for downloading images from Reddit in Python
RedditImageScraper Console application for downloading images from Reddit in Python Introduction This short Python script was created for the mass-dow
 0 Jul 4, 2021
0 Jul 4, 2021

👁️ Tool for Data Extraction and Web Requests.
httpmapper 👁️ Project • Technologies • Installation • How it works • License Project 🚧 For educational purposes. This is a project that I developed,
 15 Dec 5, 2021
15 Dec 5, 2021
Crawler in Python 3.7, 3.8. 3.9. Pypy3
Description Python Crawler written Python 3. (Supports major Python releases Python3.6, Python3.7 and Python 3.8) Installation and Use Setup VirtualEn
 2 Mar 12, 2022
2 Mar 12, 2022

The core packages of security analyzer web crawler
Security Analyzer 🐍 A large scale web crawler (considered also as vulnerability scanner tool) to take an overview about security of Moroccan sites Cu
 10 Jul 3, 2022
10 Jul 3, 2022

This app will let you continuously scrape certain parts of LeasePlan and extract data of cars becoming available for lease.
LeasePlan - Scraper This app will let you continuously scrape certain parts of LeasePlan and extract data of cars becoming available for lease. It has
 4 Nov 18, 2022
4 Nov 18, 2022
输入Google Hacking语句,自动调用Chrome浏览器爬取结果
Google-Hacking-Crawler 该脚本可输入Google Hacking语句,自动调用Chrome浏览器爬取结果 环境配置 python -m pip install -r requirements.txt 下载Chrome浏览器
 4 Jun 21, 2022
4 Jun 21, 2022
A low-code tool that generates python crawler code based on curl or url
KKBA Intruoduction A low-code tool that generates python crawler code based on curl or url Requirement Python = 3.6 Install pip install kkba Usage Co
 8 Sep 20, 2021
8 Sep 20, 2021
Python script to download all images/webms of a 4chan thread
Python3 script to continuously download all images/webms of multiple 4chan thread simultaneously - without installation
 208 Jan 4, 2023
208 Jan 4, 2023
Code for lyric-section-to-comment generation based on huggingface transformers.
CommentGeneration Code for lyric-section-to-comment generation based on huggingface transformers. Migrate Guyu model and code (both 12-layers and 24-l
 8 Sep 4, 2021
8 Sep 4, 2021
A toolkit to automatically crawl the paper list and download paper pdfs of ACL Ahthology.
ACL-Anthology-Crawler A toolkit to automatically crawl the paper list and download paper pdfs of ACL Anthology
 9 Oct 9, 2022
9 Oct 9, 2022
Pixiv 爬虫,使用 Python 实现。支持批量下载、上传到图床。
用 Python 实现的 Pixiv 爬虫,支持批量下载和上传。 随机图片 API: https://loliapi.ml/ Deploy Github Action 集成部署 建议使用本方法部署,相较于本地部署,无需搭建环境,全程在线上完成。并且使用国外服务器下载、上传,网络更加通畅。 Fork
 18 Feb 26, 2022
18 Feb 26, 2022
A Web Scraper built with beautiful soup, that fetches udemy course information. Get udemy course information and convert it to json, csv or xml file
Udemy Scraper A Web Scraper built with beautiful soup, that fetches udemy course information. Installation Virtual Environment Firstly, it is recommen
 15 May 17, 2022
15 May 17, 2022
一款利用Python来自动获取QQ音乐上某个歌手所有歌曲歌词的爬虫软件
QQ音乐歌词爬虫 一款利用Python来自动获取QQ音乐上某个歌手所有歌曲歌词的爬虫软件,默认去除了所有演唱会(Live)版本的歌曲。 使用方法 直接运行python run.py即可,然后输入你想获取的歌手名字,然后静静等待片刻。 output目录下保存生成的歌词和歌名文件。以周杰伦为例,会生成两
 11 Jul 27, 2022
11 Jul 27, 2022

mlscraper: Scrape data from HTML pages automatically with Machine Learning
🤖 Scrape data from HTML websites automatically with Machine Learning
 798 Dec 29, 2022
798 Dec 29, 2022
discovering subdomains, hidden paths, extracting unique links
python-website-crawler discovering subdomains, hidden paths, extracting unique links pip install -r requirements.txt discover subdomain: You can give
 4 Sep 5, 2022
4 Sep 5, 2022
Automatically detect changes made to the official Telegram sites.
🕷 Telegram Web Crawler This project is developed to automatically detect changes made to the official Telegram sites. This is necessary for anticipat
 115 Dec 31, 2022
115 Dec 31, 2022
Backend, modern REST API for obtaining match and odds data crawled from multiple sites. Using FastAPI, MongoDB as database, Motor as async MongoDB client, Scrapy as crawler and Docker.
Introduction Apiestas is a project composed of a backend powered by the awesome framework FastAPI and a crawler powered by Scrapy. This project has fo
 54 Dec 13, 2022
54 Dec 13, 2022
爬虫案例合集。包括但不限于《淘宝、京东、天猫、豆瓣、抖音、快手、微博、微信、阿里、头条、pdd、优酷、爱奇艺、携程、12306、58、搜狐、百度指数、维普万方、Zlibraty、Oalib、小说、招标网、采购网、小红书》
lxSpider 爬虫案例合集。包括但不限于《淘宝、京东、天猫、豆瓣、抖音、快手、微博、微信、阿里、头条、pdd、优酷、爱奇艺、携程、12306、58、搜狐、百度指数、维普万方、Zlibraty、Oalib、小说网站、招标采购网》 简介: 时光荏苒,记不清写了多少案例了。
 793 Jan 5, 2023
793 Jan 5, 2023
Web crawling framework based on asyncio.
Web crawling framework for everyone. Written with asyncio, uvloop and aiohttp. Requirements Python3.5+ Installation pip install gain pip install uvloo
 2k Jan 5, 2023
2k Jan 5, 2023
Incredibly fast crawler designed for OSINT.
Photon Incredibly fast crawler designed for OSINT. Photon Wiki • How To Use • Compatibility • Photon Library • Contribution • Roadmap Key Features Dat
 9.3k Jan 2, 2023
9.3k Jan 2, 2023

Web scraping library and command-line tool for text discovery and extraction (main content, metadata, comments)
trafilatura: Web scraping tool for text discovery and retrieval Description Trafilatura is a Python package and command-line tool which seamlessly dow
704 Jan 6, 2023
Async Python 3.6+ web scraping micro-framework based on asyncio
Ruia 🕸️ Async Python 3.6+ web scraping micro-framework based on asyncio. ⚡ Write less, run faster. Overview Ruia is an async web scraping micro-frame
 1.6k Jan 1, 2023
1.6k Jan 1, 2023

A Smart, Automatic, Fast and Lightweight Web Scraper for Python
AutoScraper: A Smart, Automatic, Fast and Lightweight Web Scraper for Python This project is made for automatic web scraping to make scraping easy. It
 4.8k Jan 4, 2023
4.8k Jan 4, 2023
Distributed Crawler Management Framework Based on Scrapy, Scrapyd, Django and Vue.js
Gerapy Distributed Crawler Management Framework Based on Scrapy, Scrapyd, Scrapyd-Client, Scrapyd-API, Django and Vue.js. Documentation Documentation
 2.9k Jan 3, 2023
2.9k Jan 3, 2023
News, full-text, and article metadata extraction in Python 3. Advanced docs:
Newspaper3k: Article scraping & curation Inspired by requests for its simplicity and powered by lxml for its speed: "Newspaper is an amazing python li
 12.3k Jan 7, 2023
12.3k Jan 7, 2023
Scrapy, a fast high-level web crawling & scraping framework for Python.
Scrapy Overview Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pag
 45.5k Jan 7, 2023
45.5k Jan 7, 2023

scrapes medias, likes, followers, tags and all metadata. Inspired by instagram-php-scraper,bot
instagram_scraper This is a minimalistic Instagram scraper written in Python. It can fetch media, accounts, videos, comments etc. `Comment` and `Like`
 2.5k Nov 16, 2022
2.5k Nov 16, 2022

Discover hidden deepweb pages
DeepWeb Scapper Att: Demo version An simple script to scrappe deepweb to find pages. Will return if any of those exists and will save on a file. You s
 77 Oct 2, 2022
77 Oct 2, 2022
Python wrapper for Wikipedia
Wikipedia API Wikipedia-API is easy to use Python wrapper for Wikipedias' API. It supports extracting texts, sections, links, categories, translations
 369 Dec 30, 2022
369 Dec 30, 2022
Every web site provides APIs.
Toapi Overview Toapi give you the ability to make every web site provides APIs. Version v2.0.0, Completely rewrote. More elegant. More pythonic v1.0.0
3.3k Jan 5, 2023
News, full-text, and article metadata extraction in Python 3. Advanced docs:
Newspaper3k: Article scraping & curation Inspired by requests for its simplicity and powered by lxml for its speed: "Newspaper is an amazing python li
12.3k Jan 1, 2023
A Powerful Spider(Web Crawler) System in Python.
pyspider A Powerful Spider(Web Crawler) System in Python. Write script in Python Powerful WebUI with script editor, task monitor, project manager and
 15.7k Jan 4, 2023
15.7k Jan 4, 2023