126 Repositories
Python parallel-tacotron2 Libraries
Massively parallel self-organizing maps: accelerate training on multicore CPUs, GPUs, and clusters
Somoclu Somoclu is a massively parallel implementation of self-organizing maps. It exploits multicore CPUs, it is able to rely on MPI for distributing
 239 Nov 10, 2022
239 Nov 10, 2022
Python bindings for MPI
MPI for Python Overview Welcome to MPI for Python. This package provides Python bindings for the Message Passing Interface (MPI) standard. It is imple
 604 Dec 29, 2022
604 Dec 29, 2022
Interactive Parallel Computing in Python
Interactive Parallel Computing with IPython ipyparallel is the new home of IPython.parallel. ipyparallel is a Python package and collection of CLI scr
 2.3k Dec 30, 2022
2.3k Dec 30, 2022
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
Ray provides a simple, universal API for building distributed applications. Ray is packaged with the following libraries for accelerating machine lear
 23.3k Dec 31, 2022
23.3k Dec 31, 2022

Unofficial implementation of "TTNet: Real-time temporal and spatial video analysis of table tennis" (CVPR 2020)
TTNet-Pytorch The implementation for the paper "TTNet: Real-time temporal and spatial video analysis of table tennis" An introduction of the project c
 438 Dec 29, 2022
438 Dec 29, 2022
Smaller, easier, more powerful, and more reliable than make. An implementation of djb's redo.
redo - a recursive build system Smaller, easier, more powerful, and more reliable than make. This is an implementation of Daniel J. Bernstein's redo b
 1.7k Jan 4, 2023
1.7k Jan 4, 2023
TensorFlowTTS: Real-Time State-of-the-art Speech Synthesis for Tensorflow 2 (supported including English, Korean, Chinese, German and Easy to adapt for other languages)
🤪 TensorFlowTTS provides real-time state-of-the-art speech synthesis architectures such as Tacotron-2, Melgan, Multiband-Melgan, FastSpeech, FastSpeech2 based-on TensorFlow 2. With Tensorflow 2, we can speed-up training/inference progress, optimizer further by using fake-quantize aware and pruning, make TTS models can be run faster than real-time and be able to deploy on mobile devices or embedded systems.
 3k Jan 4, 2023
3k Jan 4, 2023
Model parallel transformers in Jax and Haiku
Mesh Transformer Jax A haiku library using the new(ly documented) xmap operator in Jax for model parallelism of transformers. See enwik8_example.py fo
 4.8k Jan 1, 2023
4.8k Jan 1, 2023
PArallel Distributed Deep LEarning: Machine Learning Framework from Industrial Practice (『飞桨』核心框架,深度学习&机器学习高性能单机、分布式训练和跨平台部署)
English | 简体中文 Welcome to the PaddlePaddle GitHub. PaddlePaddle, as the only independent R&D deep learning platform in China, has been officially open
 19.4k Dec 30, 2022
19.4k Dec 30, 2022

A package which efficiently applies any function to a pandas dataframe or series in the fastest available manner
swifter A package which efficiently applies any function to a pandas dataframe or series in the fastest available manner. Blog posts Release 1.0.0 Fir
 2.2k Jan 4, 2023
2.2k Jan 4, 2023
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
 14.5k Jan 7, 2023
14.5k Jan 7, 2023
An implementation of the 1. Parallel, 2. Streaming, 3. Randomized SVD using MPI4Py
PYPARSVD This implementation allows for a singular value decomposition which is: Distributed using MPI4Py Streaming - data can be shown in batches to
 44 Dec 31, 2022
44 Dec 31, 2022

Extensible, parallel implementations of t-SNE
openTSNE openTSNE is a modular Python implementation of t-Distributed Stochasitc Neighbor Embedding (t-SNE) [1], a popular dimensionality-reduction al
 751 Feb 15, 2021
751 Feb 15, 2021

Parallel t-SNE implementation with Python and Torch wrappers.
Multicore t-SNE This is a multicore modification of Barnes-Hut t-SNE by L. Van der Maaten with python and Torch CFFI-based wrappers. This code also wo
 1.5k Feb 17, 2021
1.5k Feb 17, 2021
Extensible, parallel implementations of t-SNE
openTSNE openTSNE is a modular Python implementation of t-Distributed Stochasitc Neighbor Embedding (t-SNE) [1], a popular dimensionality-reduction al
1.1k Jan 3, 2023
Parallel t-SNE implementation with Python and Torch wrappers.
Multicore t-SNE This is a multicore modification of Barnes-Hut t-SNE by L. Van der Maaten with python and Torch CFFI-based wrappers. This code also wo
1.7k Jan 9, 2023
PArallel Distributed Deep LEarning: Machine Learning Framework from Industrial Practice (『飞桨』核心框架,深度学习&机器学习高性能单机、分布式训练和跨平台部署)
English | 简体中文 Welcome to the PaddlePaddle GitHub. PaddlePaddle, as the only independent R&D deep learning platform in China, has been officially open
19.4k Jan 4, 2023
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
14.5k Jan 8, 2023
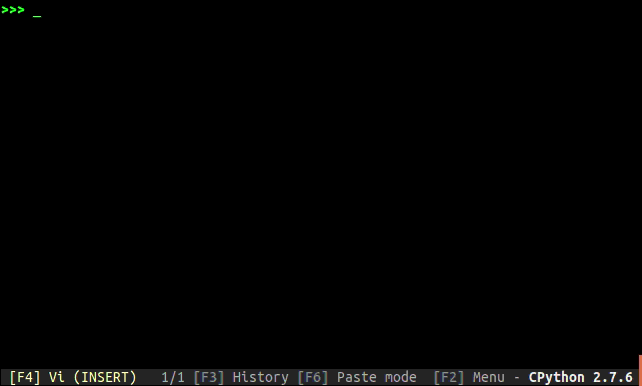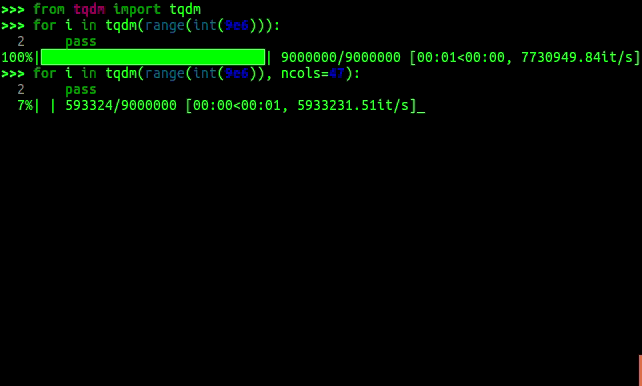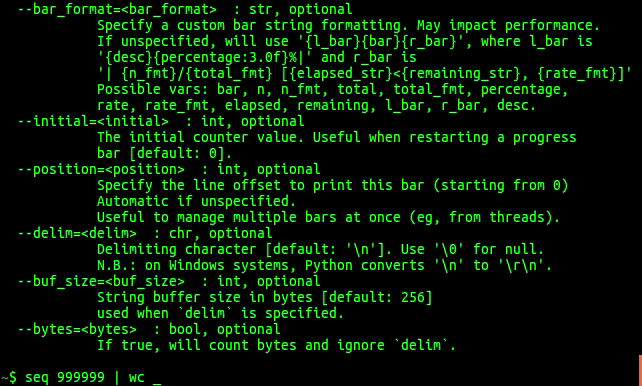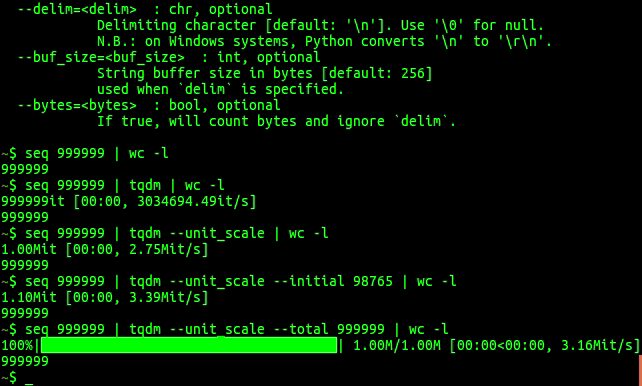
A Fast, Extensible Progress Bar for Python and CLI
tqdm tqdm derives from the Arabic word taqaddum (تقدّم) which can mean "progress," and is an abbreviation for "I love you so much" in Spanish (te quie
 23.7k Jan 1, 2023
23.7k Jan 1, 2023
Asynchronous parallel SSH client library.
parallel-ssh Asynchronous parallel SSH client library. Run SSH commands over many - hundreds/hundreds of thousands - number of servers asynchronously
 1.1k Dec 31, 2022
1.1k Dec 31, 2022
An implementation of model parallel GPT-3-like models on GPUs, based on the DeepSpeed library. Designed to be able to train models in the hundreds of billions of parameters or larger.
GPT-NeoX An implementation of model parallel GPT-3-like models on GPUs, based on the DeepSpeed library. Designed to be able to train models in the hun
 3.1k Jan 8, 2023
3.1k Jan 8, 2023
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
14.5k Jan 8, 2023
Massively parallel self-organizing maps: accelerate training on multicore CPUs, GPUs, and clusters
Somoclu Somoclu is a massively parallel implementation of self-organizing maps. It exploits multicore CPUs, it is able to rely on MPI for distributing
239 Nov 10, 2022
A Sklearn-like Framework for Hyperparameter Tuning and AutoML in Deep Learning projects. Finally have the right abstractions and design patterns to properly do AutoML. Let your pipeline steps have hyperparameter spaces. Enable checkpoints to cut duplicate calculations. Go from research to production environment easily.
Neuraxle Pipelines Code Machine Learning Pipelines - The Right Way. Neuraxle is a Machine Learning (ML) library for building machine learning pipeline
 555 Dec 24, 2022
555 Dec 24, 2022
Fast, flexible and easy to use probabilistic modelling in Python.
Please consider citing the JMLR-MLOSS Manuscript if you've used pomegranate in your academic work! pomegranate is a package for building probabilistic
 3k Dec 29, 2022
3k Dec 29, 2022
An open source framework that provides a simple, universal API for building distributed applications. Ray is packaged with RLlib, a scalable reinforcement learning library, and Tune, a scalable hyperparameter tuning library.
Ray provides a simple, universal API for building distributed applications. Ray is packaged with the following libraries for accelerating machine lear
23.2k Dec 30, 2022