69 Repositories
Python pyspark-etl-nyc-taxi Libraries
A Python package develop for transportation spatio-temporal big data processing, analysis and visualization.
English 中文版 TransBigData Introduction TransBigData is a Python package developed for transportation spatio-temporal big data processing, analysis and
 251 Jan 3, 2023
251 Jan 3, 2023
Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogramas anuais com spark, em pyspark e SQL!
Olá! Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogr
 10 Apr 4, 2022
10 Apr 4, 2022
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify.
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify. The ETL process flows from AWS's S3 into staging tables in AWS Redshift.
 1 Feb 11, 2022
1 Feb 11, 2022

Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
 1 Feb 11, 2022
1 Feb 11, 2022

Airflow ETL With EKS EFS Sagemaker
Airflow ETL With EKS EFS & Sagemaker (en desarrollo) Diagrama de la solución Imp
 1 Feb 14, 2022
1 Feb 14, 2022
A data structure that extends pyspark.sql.DataFrame with metadata information.
MetaFrame A data structure that extends pyspark.sql.DataFrame with metadata info
 8 Feb 15, 2022
8 Feb 15, 2022

Processo de ETL (extração, transformação, carregamento) realizado pela equipe no projeto final do curso da Soul Code Academy.
Processo de ETL (extração, transformação, carregamento) realizado pela equipe no projeto final do curso da Soul Code Academy.
 1 Feb 3, 2022
1 Feb 3, 2022

PySpark Structured Streaming ROS Kafka ApacheSpark Cassandra
PySpark-Structured-Streaming-ROS-Kafka-ApacheSpark-Cassandra The purpose of this project is to demonstrate a structured streaming pipeline with Apache
 5 Nov 13, 2022
5 Nov 13, 2022
Pyspark sam - Analyze Big Sequence Alignments with PySpark in AWS EMR
pyspark_sam This repo hosts my code for the article "Analyze Big Sequence Alignm
 4 Dec 9, 2022
4 Dec 9, 2022
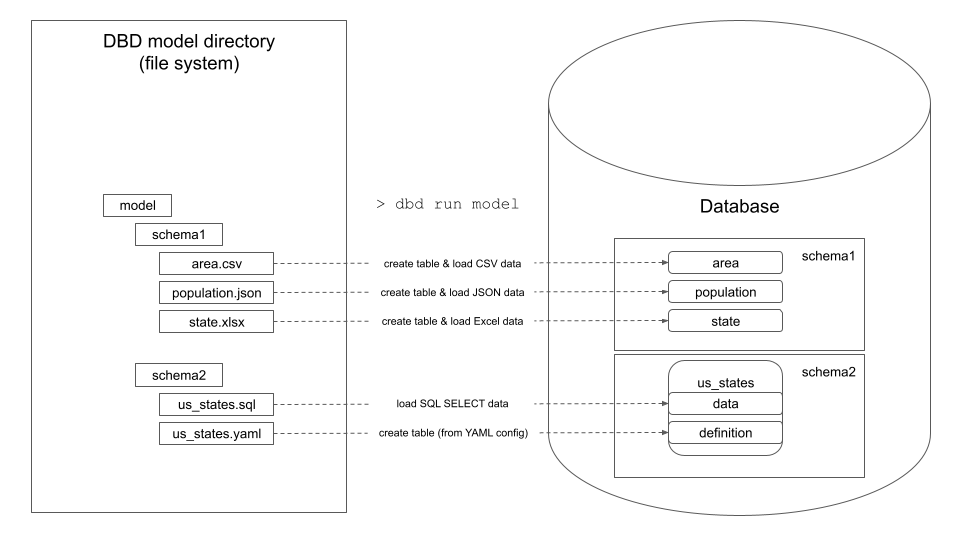
dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL databases.
dbd: database prototyping tool dbd is a database prototyping tool that enables data analysts and engineers to quickly load and transform data in SQL d
 47 Dec 7, 2022
47 Dec 7, 2022

PrimaryBid - Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift
Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift This project is composed of two parts: Part1 and Part2
 1 Jan 19, 2022
1 Jan 19, 2022
SynapseML - an open source library to simplify the creation of scalable machine learning pipelines
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022

Pizza Orders Data Pipeline Usecase Solved by SQL, Sqoop, HDFS, Hive, Airflow.
PizzaOrders_DataPipeline There is a Tony who is owning a New Pizza shop. He knew that pizza alone was not going to help him get seed funding to expand
 4 Jun 5, 2022
4 Jun 5, 2022
Apache Spark & Python (pySpark) tutorials for Big Data Analysis and Machine Learning as IPython / Jupyter notebooks
Spark Python Notebooks This is a collection of IPython notebook/Jupyter notebooks intended to train the reader on different Apache Spark concepts, fro
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

songplays datamart provide details about the musical taste of our customers and can help us to improve our recomendation system
Songplays User activity datamart The following document describes the model used to build the songplays datamart table and the respective ETL process.
 1 Jul 13, 2021
1 Jul 13, 2021
A Streamlit demo to interactively visualize Uber pickups in New York City
Streamlit Demo: Uber Pickups in New York City A Streamlit demo written in pure Python to interactively visualize Uber pickups in New York City. View t
 230 Dec 28, 2022
230 Dec 28, 2022
Python’s bokeh, holoviews, matplotlib, plotly, seaborn package-based visualizations about COVID statistics eventually hosted as a web app on Heroku
COVID-Watch-NYC-Python-Visualization-App Python’s bokeh, holoviews, matplotlib, plotly, seaborn package-based visualizations about COVID statistics ev
 1 Jan 4, 2022
1 Jan 4, 2022
A quick reference guide to the most commonly used patterns and functions in PySpark SQL
Using PySpark we can process data from Hadoop HDFS, AWS S3, and many file systems. PySpark also is used to process real-time data using Streaming and
 53 Dec 21, 2022
53 Dec 21, 2022

ETL pipeline on movie data using Python and postgreSQL
Movies-ETL ETL pipeline on movie data using Python and postgreSQL Overview This project consisted on a automated Extraction, Transformation and Load p
 0 Jul 7, 2021
0 Jul 7, 2021
ETL for tononkira.serasera.org
python-tononkiramalagasy-api Api Endpoints: ### get artists - /artists/int:page [page_offset = 20] ### get artist's songs, index was given by
 1 Dec 24, 2021
1 Dec 24, 2021
Fetching tweets and integrating it with Kafka and PySpark
KafkaPySpark Zookeeper bin/zookeeper-server-start.sh config/zookeeper.properties Kafka Server bin/kafka-server-start.sh config/server.properties Kafka
 2 Dec 29, 2021
2 Dec 29, 2021
Implementation of K-Nearest Neighbors Algorithm Using PySpark
KNN With Spark Implementation of KNN using PySpark. The KNN was used on two separate datasets (https://archive.ics.uci.edu/ml/datasets/iris and https:
 4 Dec 30, 2022
4 Dec 30, 2022

AWS Glue ETL Code Samples
AWS Glue ETL Code Samples This repository has samples that demonstrate various aspects of the new AWS Glue service, as well as various AWS Glue utilit
 1.2k Jan 3, 2023
1.2k Jan 3, 2023
Apache (Py)Spark type annotations (stub files).
PySpark Stubs A collection of the Apache Spark stub files. These files were generated by stubgen and manually edited to include accurate type hints. T
 114 Nov 22, 2022
114 Nov 22, 2022
Pyspark project that able to do joins on the spark data frames.
SPARK JOINS This project is to perform inner, all outer joins and semi joins. create_df.py: load_data.py : helps to put data into Spark data frames. d
 1 Dec 14, 2021
1 Dec 14, 2021
Singer is an open source standard for moving data between databases, web APIs, files, queues, and just about anything else you can think of.
Singer is an open source standard for moving data between databases, web APIs, files, queues, and just about anything else you can think of. Th
 1.1k Jan 5, 2023
1.1k Jan 5, 2023
An ETL framework + Monitoring UI/API (experimental project for learning purposes)
Fastlane An ETL framework for building pipelines, and Flask based web API/UI for monitoring pipelines. Project structure fastlane |- fastlane: (ETL fr
 2 Jan 6, 2022
2 Jan 6, 2022

APIlocal_dbAWS_RDS - Disclaimer! All data used is for educational purposes only.
APIlocal_dbAWS_RDS Disclaimer! All data used is for educational purposes only. ETL pipeline diagram. Aim of project By creating a fully working pipe
 0 Apr 25, 2022
0 Apr 25, 2022
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
3.9k Dec 30, 2022
NYCT-GTFS - Real-time NYC subway data parsing for humans
NYCT-GTFS - Real-time NYC subway data parsing for humans This python library provides a human-friendly, native python interface for dealing with the N
 37 Dec 27, 2022
37 Dec 27, 2022
Calculate multilateral price indices in Python (with Pandas and PySpark).
IndexNumCalc Calculate multilateral price indices using the GEKS-T (CCDI), Time Product Dummy (TPD), Time Dummy Hedonic (TDH), Geary-Khamis (GK) metho
 3 Apr 27, 2022
3 Apr 27, 2022
This is a repo documenting the best practices in PySpark.
Spark-Syntax This is a public repo documenting all of the "best practices" of writing PySpark code from what I have learnt from working with PySpark f
 447 Dec 25, 2022
447 Dec 25, 2022
PySpark bindings for H3, a hierarchical hexagonal geospatial indexing system
h3-pyspark: Uber's H3 Hexagonal Hierarchical Geospatial Indexing System in PySpark PySpark bindings for the H3 core library. For available functions,
 12 Dec 24, 2022
12 Dec 24, 2022
Kaggler is a Python package for lightweight online machine learning algorithms and utility functions for ETL and data analysis.
Kaggler is a Python package for lightweight online machine learning algorithms and utility functions for ETL and data analysis. It is distributed under the MIT License.
 720 Dec 25, 2022
720 Dec 25, 2022
AWS Glue PySpark - Apache Hudi Quick Start Guide
AWS Glue PySpark - Apache Hudi Quick Start Guide Disclaimer: This is a quick start guide for the Apache Hudi Python Spark connector, running on AWS Gl
 8 Nov 14, 2022
8 Nov 14, 2022
Building house price data pipelines with Apache Beam and Spark on GCP
This project contains the process from building a web crawler to extract the raw data of house price to create ETL pipelines using Google Could Platform services.
 1 Nov 22, 2021
1 Nov 22, 2021
An orchestration platform for the development, production, and observation of data assets.
Dagster An orchestration platform for the development, production, and observation of data assets. Dagster lets you define jobs in terms of the data f
 6.2k Jan 8, 2023
6.2k Jan 8, 2023

Created covid data pipeline using PySpark and MySQL that collected data stream from API and do some processing and store it into MYSQL database.
Created covid data pipeline using PySpark and MySQL that collected data stream from API and do some processing and store it into MYSQL database.
 2 Nov 20, 2021
2 Nov 20, 2021
PySpark ML Bank Churn Prediction
PySpark-Bank-Churn Surname: corresponds to the record (row) number and has no effect on the output. CreditScore: contains random values and has no eff
 2 Nov 11, 2021
2 Nov 11, 2021
This repository has datasets containing information of Uber pickups in NYC from April 2014 to September 2014 and January to June 2015. data Analysis , virtualization and some insights are gathered here
uber-pickups-analysis Data Source: https://www.kaggle.com/fivethirtyeight/uber-pickups-in-new-york-city Information about data set The dataset contain
 1 Nov 3, 2021
1 Nov 3, 2021
Instant search for and access to many datasets in Pyspark.
SparkDataset Provides instant access to many datasets right from Pyspark (in Spark DataFrame structure). Drop a star if you like the project. 😃 Motiv
 31 Dec 16, 2022
31 Dec 16, 2022
this repository has datasets containing information of Uber pickups in NYC from April 2014 to September 2014 and January to June 2015. data Analysis , virtualization and some insights are gathered here
uber-pickups-analysis Data Source: https://www.kaggle.com/fivethirtyeight/uber-pickups-in-new-york-city Information about data set The dataset contain
 1 Nov 2, 2021
1 Nov 2, 2021
In this project, ETL pipeline is build on data warehouse hosted on AWS Redshift.
ETL Pipeline for AWS Project Description In this project, ETL pipeline is build on data warehouse hosted on AWS Redshift. The data is loaded from S3 t
 1 Nov 1, 2021
1 Nov 1, 2021
A Big Data ETL project in PySpark on the historical NYC Taxi Rides data
Processing NYC Taxi Data using PySpark ETL pipeline Description This is an project to extract, transform, and load large amount of data from NYC Taxi
 2 Dec 12, 2021
2 Dec 12, 2021

A collection of neat and practical data science and machine learning projects
Data Science A collection of neat and practical data science and machine learning projects Explore the docs » Report Bug · Request Feature Table of Co
 2 Dec 10, 2021
2 Dec 10, 2021
wikirepo is a Python package that provides a framework to easily source and leverage standardized Wikidata information
Python based Wikidata framework for easy dataframe extraction wikirepo is a Python package that provides a framework to easily source and leverage sta
 35 Jan 4, 2023
35 Jan 4, 2023

ETL flow framework based on Yaml configs in Python
ETL framework based on Yaml configs in Python A light framework for creating data streams. Setting up streams through configuration in the Yaml file.
 18 Jul 6, 2022
18 Jul 6, 2022

A web scraping pipeline project that retrieves TV and movie data from two sources, then transforms and stores data in a MySQL database.
New to Streaming Scraper An in-progress web scraping project built with Python, R, and SQL. The scraped data are movie and TV show information. The go
 1 Mar 28, 2022
1 Mar 28, 2022
Eland is a Python Elasticsearch client for exploring and analyzing data in Elasticsearch with a familiar Pandas-compatible API.
Python Client and Toolkit for DataFrames, Big Data, Machine Learning and ETL in Elasticsearch
 463 Dec 30, 2022
463 Dec 30, 2022
Python library which makes it possible to dynamically mask/anonymize data using JSON string or python dict rules in a PySpark environment.
pyspark-anonymizer Python library which makes it possible to dynamically mask/anonymize data using JSON string or python dict rules in a PySpark envir
 6 Jun 30, 2022
6 Jun 30, 2022

PySpark Cheat Sheet - learn PySpark and develop apps faster
This cheat sheet will help you learn PySpark and write PySpark apps faster. Everything in here is fully functional PySpark code you can run or adapt to your programs.
 168 Jan 1, 2023
168 Jan 1, 2023

Estudos e projetos feitos com PySpark.
PySpark (Spark com Python) PySpark é uma biblioteca Spark escrita em Python, e seu objetivo é permitir a análise interativa dos dados em um ambiente d
 54 Nov 6, 2022
54 Nov 6, 2022
Churn prediction with PySpark
It is expected to develop a machine learning model that can predict customers who will leave the company.
 3 Aug 13, 2021
3 Aug 13, 2021

Python ELT Studio, an application for building ELT (and ETL) data flows.
The Python Extract, Load, Transform Studio is an application for performing ELT (and ETL) tasks. Under the hood the application consists of a two parts.
 55 Nov 18, 2022
55 Nov 18, 2022
Pyspark Spotify ETL
This is my first Data Engineering project, it extracts data from the user's recently played tracks using Spotify's API, transforms data and then loads it into Postgresql using SQLAlchemy engine. Data is shown as a Spark Dataframe before loading and the whole ETL job is scheduled with crontab. Token never expires since an HTTP POST method with Spotify's token API is used in the beginning of the script.
 16 Jun 9, 2022
16 Jun 9, 2022
ETL python utilizando API do Spotify
Processo de ETL com Python e Airflow usando API do Spotify Sobre Projeto de ETL(Extract, Transform e Load) utilizando Python com API do Spotify e Airf
 10 Mar 16, 2022
10 Mar 16, 2022
Ethereum ETL lets you convert blockchain data into convenient formats like CSVs and relational databases.
Python scripts for ETL (extract, transform and load) jobs for Ethereum blocks, transactions, ERC20 / ERC721 tokens, transfers, receipts, logs, contracts, internal transactions.
 2.3k Jan 1, 2023
2.3k Jan 1, 2023

Educational project on how to build an ETL (Extract, Transform, Load) data pipeline, orchestrated with Airflow.
ETL Pipeline with Airflow, Spark, s3, MongoDB and Amazon Redshift
 214 Jan 2, 2023
214 Jan 2, 2023

Distributed scikit-learn meta-estimators in PySpark
sk-dist: Distributed scikit-learn meta-estimators in PySpark What is it? sk-dist is a Python package for machine learning built on top of scikit-learn
 282 Dec 9, 2022
282 Dec 9, 2022
Microsoft Machine Learning for Apache Spark
Microsoft Machine Learning for Apache Spark MMLSpark is an ecosystem of tools aimed towards expanding the distributed computing framework Apache Spark
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
Petastorm library enables single machine or distributed training and evaluation of deep learning models from datasets in Apache Parquet format. It supports ML frameworks such as Tensorflow, Pytorch, and PySpark and can be used from pure Python code.
Petastorm Contents Petastorm Installation Generating a dataset Plain Python API Tensorflow API Pytorch API Spark Dataset Converter API Analyzing petas
 1.6k Dec 31, 2022
1.6k Dec 31, 2022
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023
PySpark + Scikit-learn = Sparkit-learn
Sparkit-learn PySpark + Scikit-learn = Sparkit-learn GitHub: https://github.com/lensacom/sparkit-learn About Sparkit-learn aims to provide scikit-lear
 1.1k Jan 4, 2023
1.1k Jan 4, 2023
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
 1.9k Feb 18, 2021
1.9k Feb 18, 2021

 578 Dec 30, 2022
578 Dec 30, 2022
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
3k Jan 5, 2023
Pandas on AWS - Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL).
AWS Data Wrangler Pandas on AWS Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretMana
 3.3k Dec 31, 2022
3.3k Dec 31, 2022

:truck: Agile Data Preparation Workflows made easy with dask, cudf, dask_cudf and pyspark
To launch a live notebook server to test optimus using binder or Colab, click on one of the following badges: Optimus is the missing framework to prof
 1.3k Dec 30, 2022
1.3k Dec 30, 2022
Pandas on AWS - Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL).
AWS Data Wrangler Pandas on AWS Easy integration with Athena, Glue, Redshift, Timestream, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretMana
3.3k Jan 4, 2023