64 Repositories
Python w2v2-speaker Libraries

Comprehensive-E2E-TTS - PyTorch Implementation
A Non-Autoregressive End-to-End Text-to-Speech (text-to-wav), supporting a family of SOTA unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate E2E-TTS
 114 Nov 13, 2022
114 Nov 13, 2022
Code for One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022)
One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning (AAAI 2022) Paper | Demo Requirements Python = 3.6 , Pytorch
 84 Jan 3, 2023
84 Jan 3, 2023

PyTorch Implementation of DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
DiffGAN-TTS - PyTorch Implementation PyTorch implementation of DiffGAN-TTS: High
157 Jan 1, 2023

Temporal Dynamic Convolutional Neural Network for Text-Independent Speaker Verification and Phonemetic Analysis
TDY-CNN for Text-Independent Speaker Verification Official implementation of Temporal Dynamic Convolutional Neural Network for Text-Independent Speake
 16 Oct 17, 2022
16 Oct 17, 2022
Baseline for the Spoofing-aware Speaker Verification Challenge 2022
Introduction This repository contains several materials that supplements the Spoofing-Aware Speaker Verification (SASV) Challenge 2022 including: calc
 40 Dec 28, 2022
40 Dec 28, 2022
A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk.
Simple-Vosk A Python wrapper for simple offline real-time dictation (speech-to-text) and speaker-recognition using Vosk. Check out the official Vosk G
 2 Jun 19, 2022
2 Jun 19, 2022
A simple program to make MSI Modern 15 speaker and microphone mute led work.
MSI Modern 15 sound led fixup for linux A simple program to fix the MSI Modern 15 speaker and microphone mute LEDs. Installation Requirements pulsectl
 4 Oct 18, 2022
4 Oct 18, 2022

Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning
Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning English | 中文 ❗ Now we provide inferencing code and pre-training models
 164 Jan 2, 2023
164 Jan 2, 2023

MakeItTalk: Speaker-Aware Talking-Head Animation
MakeItTalk: Speaker-Aware Talking-Head Animation This is the code repository implementing the paper: MakeItTalk: Speaker-Aware Talking-Head Animation
 285 Jan 8, 2023
285 Jan 8, 2023

User-friendly Voice Cloning Application
Multi-Language-RTVC stands for Multi-Language Real Time Voice Cloning and is a Voice Cloning Tool capable of transfering speaker-specific audio featur
 19 Dec 30, 2022
19 Dec 30, 2022

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: WavLM (arXiv): WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing UniSpeech (ICML 202
 281 Dec 15, 2022
281 Dec 15, 2022
A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities
MPT A Multi-modal Perception Tracker (MPT) for speaker tracking using both audio and visual modalities. Implementation for our AAAI 2022 paper: Multi-
 4 May 8, 2022
4 May 8, 2022
A complete speech segmentation system using Kaldi and x-vectors for voice activity detection (VAD) and speaker diarisation.
bbc-speech-segmenter: Voice Activity Detection & Speaker Diarization A complete speech segmentation system using Kaldi and x-vectors for voice activit
 16 Oct 27, 2022
16 Oct 27, 2022
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone In our recent paper we propose the YourTTS model. YourTTS bri
 390 Dec 29, 2022
390 Dec 29, 2022

Pytorch code for "Text-Independent Speaker Verification Using 3D Convolutional Neural Networks".
:speaker: Deep Learning & 3D Convolutional Neural Networks for Speaker Verification
 114 Dec 18, 2022
114 Dec 18, 2022

Deep Learning & 3D Convolutional Neural Networks for Speaker Verification
TensorFlow implementation of 3D Convolutional Neural Networks for Speaker Verification - Official Project Page - Pytorch Implementation This repositor
753 Dec 17, 2022

Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
 47 Dec 25, 2022
47 Dec 25, 2022
Research code for the paper "Fine-tuning wav2vec2 for speaker recognition"
Fine-tuning wav2vec2 for speaker recognition This is the code used to run the experiments in https://arxiv.org/abs/2109.15053. Detailed logs of each t
 103 Dec 26, 2022
103 Dec 26, 2022
This repo contains simple to use, pretrained/training-less models for speaker diarization.
PyDiar This repo contains simple to use, pretrained/training-less models for speaker diarization. Supported Models Binary Key Speaker Modeling Based o
 12 Jan 20, 2022
12 Jan 20, 2022
VGGVox models for Speaker Identification and Verification trained on the VoxCeleb (1 & 2) datasets
VGGVox models for speaker identification and verification This directory contains code to import and evaluate the speaker identification and verificat
 338 Dec 27, 2022
338 Dec 27, 2022

The project is associated with the recently-launched ICASSP 2022 Multi-channel Multi-party Meeting Transcription Challenge (M2MeT) to provide participants with baseline systems for speech recognition and speaker diarization in conference scenario.
M2MeT challenge baseline -- AliMeeting This project provides the baseline system recipes for the ICASSP 2020 Multi-channel Multi-party Meeting Transcr
 81 Dec 8, 2022
81 Dec 8, 2022

Efficient Speech Processing Tookit for Automatic Speaker Recognition
Sugar Efficient Speech Processing Tookit for Automatic Speaker Recognition | HuggingFace | What's New EfficientTDNN: Efficient Architecture Search for
 14 Sep 14, 2022
14 Sep 14, 2022
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL, and utterance id
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL
 3 Dec 26, 2022
3 Dec 26, 2022

Pytorch implementation of our paper LIMUSE: LIGHTWEIGHT MULTI-MODAL SPEAKER EXTRACTION.
LiMuSE Overview Pytorch implementation of our paper LIMUSE: LIGHTWEIGHT MULTI-MODAL SPEAKER EXTRACTION. LiMuSE explores group communication on a multi
 17 Oct 26, 2022
17 Oct 26, 2022

Unofficial implement with paper SpeakerGAN: Speaker identification with conditional generative adversarial network
Introduction This repository is about paper SpeakerGAN , and is unofficially implemented by Mingming Huang ([email protected]), Tiezheng Wang (wtz920729
 7 Jan 3, 2023
7 Jan 3, 2023
SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch.
The SpeechBrain Toolkit SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch. The goal is to create a single, flexible, and us
 5.1k Jan 2, 2023
5.1k Jan 2, 2023
Unofficial reimplementation of ECAPA-TDNN for speaker recognition (EER=0.86 for Vox1_O when train only in Vox2)
Introduction This repository contains my unofficial reimplementation of the standard ECAPA-TDNN, which is the speaker recognition in VoxCeleb2 dataset
 277 Dec 31, 2022
277 Dec 31, 2022

PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Cross-Speaker-Emotion-Transfer - PyTorch Implementation PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Conditio
114 Jan 8, 2023
L-SpEx: Localized Target Speaker Extraction
L-SpEx: Localized Target Speaker Extraction The data configuration and simulation of L-SpEx. The code scripts will be released in the future. Data Gen
 20 Jan 2, 2023
20 Jan 2, 2023
UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: UniSpeech (ICML 2021): Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR UniSpeech-
33 Oct 14, 2021
Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
47 Dec 25, 2022

SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
 24 May 20, 2022
24 May 20, 2022

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
237 Jan 2, 2023

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Jan 8, 2023
1.8k Jan 8, 2023
Original implementation of the pooling method introduced in "Speaker embeddings by modeling channel-wise correlations"
Speaker-Embeddings-Correlation-Pooling This is the original implementation of the pooling method introduced in "Speaker embeddings by modeling channel
 10 Apr 30, 2022
10 Apr 30, 2022

Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
 187 Jan 6, 2023
187 Jan 6, 2023
Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
185 Jan 1, 2023

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
 24 Sep 7, 2022
24 Sep 7, 2022
Look Who’s Talking: Active Speaker Detection in the Wild
Look Who's Talking: Active Speaker Detection in the Wild Dependencies pip install -r requirements.txt In addition to the Python dependencies, ffmpeg
 60 Dec 8, 2022
60 Dec 8, 2022

Let Xiao Ai speakers control third-party devices
A stupid way to extend miot/xiaoai. Demo for Panasonic Bath Bully FV-RB20VL1 逆向 Panasonic Smart China,获得控制浴霸的请求信息(HTTP 请求),详见 apps/panasonic.py; 2. 通过
 14 Jul 7, 2022
14 Jul 7, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
47 Dec 18, 2022
neural network based speaker embedder
Content What is deepaudio-speaker? Installation Get Started Model Architecture How to contribute to deepaudio-speaker? Acknowledge What is deepaudio-s
 20 Dec 29, 2022
20 Dec 29, 2022
PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
1.8k Dec 30, 2022

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
142 Dec 14, 2022

PyTorch implementation of Densely Connected Time Delay Neural Network
Densely Connected Time Delay Neural Network PyTorch implementation of Densely Connected Time Delay Neural Network (D-TDNN) in our paper "Densely Conne
 64 Oct 11, 2022
64 Oct 11, 2022

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022
Use android as mic/speaker for ubuntu
Pulse Audio Control Panel Platforms Requirements sudo apt install ffmpeg pactl (already installed) Download Download the AppImage from release page ch
 19 Dec 1, 2022
19 Dec 1, 2022
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
 38.5k Jan 3, 2023
38.5k Jan 3, 2023

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
140 Dec 21, 2022
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 6, 2023

ERISHA is a mulitilingual multispeaker expressive speech synthesis framework. It can transfer the expressivity to the speaker's voice for which no expressive speech corpus is available.
ERISHA: Multilingual Multispeaker Expressive Text-to-Speech Library ERISHA is a multilingual multispeaker expressive speech synthesis framework. It ca
 43 Nov 27, 2022
43 Nov 27, 2022
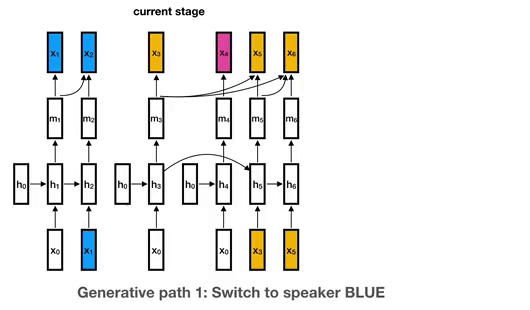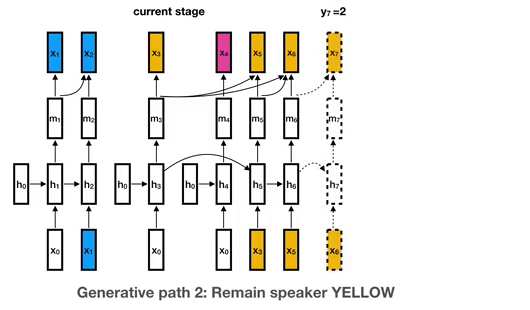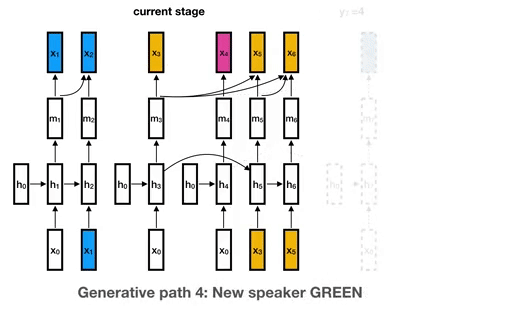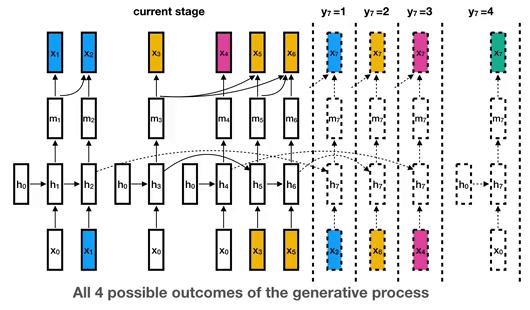
This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization.
UIS-RNN Overview This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm. UIS-RNN solves the problem of s
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
 2.2k Jan 9, 2023
2.2k Jan 9, 2023
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model Edresson Casanova, Christopher Shulby, Eren Gölge, Nicolas Michael Müller, Frede
92 Dec 9, 2022

TTS is a library for advanced Text-to-Speech generation.
TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.
 6.5k Jan 8, 2023
6.5k Jan 8, 2023
kaldi-asr/kaldi is the official location of the Kaldi project.
Kaldi Speech Recognition Toolkit To build the toolkit: see ./INSTALL. These instructions are valid for UNIX systems including various flavors of Linux
 12.3k Jan 5, 2023
12.3k Jan 5, 2023
TensorFlowTTS: Real-Time State-of-the-art Speech Synthesis for Tensorflow 2 (supported including English, Korean, Chinese, German and Easy to adapt for other languages)
🤪 TensorFlowTTS provides real-time state-of-the-art speech synthesis architectures such as Tacotron-2, Melgan, Multiband-Melgan, FastSpeech, FastSpeech2 based-on TensorFlow 2. With Tensorflow 2, we can speed-up training/inference progress, optimizer further by using fake-quantize aware and pruning, make TTS models can be run faster than real-time and be able to deploy on mobile devices or embedded systems.
 3k Jan 4, 2023
3k Jan 4, 2023
Conference planning tool: CfP, scheduling, speaker management
pretalx is a conference planning tool focused on providing the best experience for organisers, speakers, reviewers, and attendees alike. It handles th
 496 Dec 31, 2022
496 Dec 31, 2022
Conference planning tool: CfP, scheduling, speaker management
pretalx is a conference planning tool focused on providing the best experience for organisers, speakers, reviewers, and attendees alike. It handles th
492 Dec 28, 2022
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
 1.4k Feb 17, 2021
1.4k Feb 17, 2021
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
2.1k Dec 31, 2022
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
1.5k Dec 26, 2022