232 Repositories
Python word-similarity Libraries
Package to compute Mauve, a similarity score between neural text and human text. Install with `pip install mauve-text`.
MAUVE MAUVE is a library built on PyTorch and HuggingFace Transformers to measure the gap between neural text and human text with the eponymous MAUVE
 182 Jan 2, 2023
182 Jan 2, 2023

(NeurIPS 2021) Pytorch implementation of paper "Re-ranking for image retrieval and transductive few-shot classification"
SSR (NeurIPS 2021) Pytorch implementation of paper "Re-ranking for image retrieval and transductivefew-shot classification" [Paper] [Project webpage]
 29 Dec 6, 2022
29 Dec 6, 2022
Official implementation of the paper "Steganographer Detection via a Similarity Accumulation Graph Convolutional Network"
SAGCN - Official PyTorch Implementation | Paper | Project Page This is the official implementation of the paper "Steganographer detection via a simila
 1 Nov 26, 2021
1 Nov 26, 2021
The codes and related files to reproduce the results for Image Similarity Challenge Track 2.
The codes and related files to reproduce the results for Image Similarity Challenge Track 2.
 28 Nov 24, 2021
28 Nov 24, 2021

Self-Supervised Document-to-Document Similarity Ranking via Contextualized Language Models and Hierarchical Inference
Self-Supervised Document Similarity Ranking (SDR) via Contextualized Language Models and Hierarchical Inference This repo is the implementation for SD
 36 Nov 28, 2022
36 Nov 28, 2022
A fast, efficient universal vector embedding utility package.
Magnitude: a fast, simple vector embedding utility library A feature-packed Python package and vector storage file format for utilizing vector embeddi
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
A library for efficient similarity search and clustering of dense vectors.
Faiss Faiss is a library for efficient similarity search and clustering of dense vectors. It contains algorithms that search in sets of vectors of any
 18.8k Jan 8, 2023
18.8k Jan 8, 2023
MinHash, LSH, LSH Forest, Weighted MinHash, HyperLogLog, HyperLogLog++, LSH Ensemble
datasketch: Big Data Looks Small datasketch gives you probabilistic data structures that can process and search very large amount of data super fast,
 1.9k Jan 7, 2023
1.9k Jan 7, 2023

The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
The best way to convert files on your computer, be it .pdf to .png, .pdf to .docx, .png to .ico, or anything you can imagine.
 2 Nov 20, 2021
2 Nov 20, 2021
The codes and related files to reproduce the results for Image Similarity Challenge Track 1.
ISC-Track1-Submission The codes and related files to reproduce the results for Image Similarity Challenge Track 1. Required dependencies To begin with
20 Nov 19, 2021
Python script to generate Vale linting rules from word usage guidance in the Red Hat Supplementary Style Guide
ssg-vale-rules-gen Python script to generate Vale linting rules from word usage guidance in the Red Hat Supplementary Style Guide. These rules are use
 1 Jan 13, 2022
1 Jan 13, 2022
Non-Metric Space Library (NMSLIB): An efficient similarity search library and a toolkit for evaluation of k-NN methods for generic non-metric spaces.
Non-Metric Space Library (NMSLIB) Important Notes NMSLIB is generic but fast, see the results of ANN benchmarks. A standalone implementation of our fa
 2.9k Jan 4, 2023
2.9k Jan 4, 2023
A socket script to obtain chinese phones-sequence for any english word
Foreign Pronunciation Generator (English-Chinese) We provide a simple socket script for acquiring Chinese pronunciation of English words (phones in ai
 5 Jul 25, 2022
5 Jul 25, 2022
This repository is maintained for the scientific paper tittled " Study of keyword extraction techniques for Electric Double Layer Capacitor domain using text similarity indexes: An experimental analysis "
kwd-extraction-study This repository is maintained for the scientific paper tittled " Study of keyword extraction techniques for Electric Double Layer
 1 Dec 5, 2022
1 Dec 5, 2022
The codes and related files to reproduce the results for Image Similarity Challenge Track 2.
ISC-Track2-Submission The codes and related files to reproduce the results for Image Similarity Challenge Track 2. Required dependencies To begin with
89 Jan 2, 2023
The codes and related files to reproduce the results for Image Similarity Challenge Track 1.
ISC-Track1-Submission The codes and related files to reproduce the results for Image Similarity Challenge Track 1. Required dependencies To begin with
115 Jan 2, 2023
Learning a mapping from images to psychological similarity spaces with neural networks.
LearningPsychologicalSpaces v0.1: v1.1: v1.2: v1.3: v1.4: v1.5: The code in this repository explores learning a mapping from images to psychological s
 8 Dec 12, 2022
8 Dec 12, 2022
This Project is based on NLTK It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
This Project is based on NLTK(Natural Language Toolkit) It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
 2 Nov 17, 2021
2 Nov 17, 2021
MASS (Mueen's Algorithm for Similarity Search) - a python 2 and 3 compatible library used for searching time series sub-sequences under z-normalized Euclidean distance for similarity.
Introduction MASS allows you to search a time series for a subquery resulting in an array of distances. These array of distances enable you to identif
 79 Dec 31, 2022
79 Dec 31, 2022
This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text.
Text Summarizer This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text. Team Members This mini-project was
 1 Nov 16, 2021
1 Nov 16, 2021
This repo is the code release of EMNLP 2021 conference paper "Connect-the-Dots: Bridging Semantics between Words and Definitions via Aligning Word Sense Inventories".
Connect-the-Dots: Bridging Semantics between Words and Definitions via Aligning Word Sense Inventories This repo is the code release of EMNLP 2021 con
 12 Nov 22, 2022
12 Nov 22, 2022
Grounding Representation Similarity with Statistical Testing
Grounding Representation Similarity with Statistical Testing This repo contains code to replicate the results in our paper, which evaluates representa
 26 Dec 2, 2022
26 Dec 2, 2022

An open-source online reverse dictionary.
An open-source online reverse dictionary.
 6.3k Jan 9, 2023
6.3k Jan 9, 2023
Rates how pog a word or user is. Not random and does have *some* kind of algorithm to it.
PogRater :D Rates how pogchamp a word is :D A fun project coded by JBYT27 using Python3 Have you ever wondered how pog a word is? Well, congrats, you
 2 Jun 25, 2022
2 Jun 25, 2022
Simple Reddit bot that replies to comments containing a certain word.
reddit-replier-bot Small comment reply bot based on PRAW. This script will scan the comments of a subreddit as they come in and look for a trigger wor
 0 Jun 4, 2022
0 Jun 4, 2022
🌸 fastText + Bloom embeddings for compact, full-coverage vectors with spaCy
floret: fastText + Bloom embeddings for compact, full-coverage vectors with spaCy floret is an extended version of fastText that can produce word repr
 222 Dec 16, 2022
222 Dec 16, 2022

WORD: Revisiting Organs Segmentation in the Whole Abdominal Region
WORD: Revisiting Organs Segmentation in the Whole Abdominal Region. This repository provides the codebase and dataset for our work WORD: Revisiting Or
 71 Jan 7, 2023
71 Jan 7, 2023
Interpretable-contrastive-word-mover-s-embedding
Interpretable-contrastive-word-mover-s-embedding Paper Datasets Here is a Dropbox link to the datasets used in the paper: https://www.dropbox.com/sh/n
 0 Nov 2, 2021
0 Nov 2, 2021
Cross-lingual Transfer for Speech Processing using Acoustic Language Similarity
Cross-lingual Transfer for Speech Processing using Acoustic Language Similarity Indic TTS Samples can be found at https://peter-yh-wu.github.io/cross-
 1 Nov 12, 2022
1 Nov 12, 2022

Keywords : Streamlit, BertTokenizer, BertForMaskedLM, Pytorch
Next Word Prediction Keywords : Streamlit, BertTokenizer, BertForMaskedLM, Pytorch 🎬 Project Demo ✔ Application is hosted on Streamlit. You can see t
 3 Aug 26, 2022
3 Aug 26, 2022
This code is for a bot which will find a Twitter user's most tweeted word and tweet that word, tagging said user
max_tweeted_word This code is for a bot which will find a Twitter user's most tweeted word and tweet that word, tagging said user The program uses twe
 1 Nov 29, 2021
1 Nov 29, 2021
Japanese Long-Unit-Word Tokenizer with RemBertTokenizerFast of Transformers
Japanese-LUW-Tokenizer Japanese Long-Unit-Word (国語研長単位) Tokenizer for Transformers based on 青空文庫 Basic Usage from transformers import RemBertToken
 3 Dec 22, 2021
3 Dec 22, 2021
Gradient representations in ReLU networks as similarity functions
Gradient representations in ReLU networks as similarity functions by Dániel Rácz and Bálint Daróczy. This repo contains the python code related to our
 1 Oct 8, 2021
1 Oct 8, 2021
[NeurIPS 2021] A weak-shot object detection approach by transferring semantic similarity and mask prior.
TransMaS This repository is the official pytorch implementation of the following paper: NIPS2021 Mixed Supervised Object Detection by TransferringMask
 39 Oct 30, 2021
39 Oct 30, 2021
[NeurIPS 2021] A weak-shot object detection approach by transferring semantic similarity and mask prior.
[NeurIPS 2021] A weak-shot object detection approach by transferring semantic similarity and mask prior.
49 Jul 27, 2022

(Python, R, C/C++) Isolation Forest and variations such as SCiForest and EIF, with some additions (outlier detection + similarity + NA imputation)
IsoTree Fast and multi-threaded implementation of Extended Isolation Forest, Fair-Cut Forest, SCiForest (a.k.a. Split-Criterion iForest), and regular
 141 Dec 29, 2022
141 Dec 29, 2022

Official implementation of NeurIPS 2021 paper "Contextual Similarity Aggregation with Self-attention for Visual Re-ranking"
CSA: Contextual Similarity Aggregation with Self-attention for Visual Re-ranking PyTorch training code for CSA (Contextual Similarity Aggregation). We
 19 Oct 21, 2022
19 Oct 21, 2022
Generate custom detailed survey paper with topic clustered sections and proper citations, from just a single query in just under 30 mins !!
Auto-Research A no-code utility to generate a detailed well-cited survey with topic clustered sections (draft paper format) and other interesting arti
 20 Dec 14, 2022
20 Dec 14, 2022
Count the frequency of letters or words in a text file and show a graph.
Word Counter By EBUS Coding Club Count the frequency of letters or words in a text file and show a graph. Requirements Python 3.9 or higher matplotlib
 0 Apr 9, 2022
0 Apr 9, 2022
Measure file similarity in a many-to-many fashion
Mesi Mesi is a tool to measure the similarity in a many-to-many fashion of long-form documents like Python source code or technical writing. The outpu
 3 Feb 2, 2022
3 Feb 2, 2022
Official implementation of NeurIPS 2021 paper "Contextual Similarity Aggregation with Self-attention for Visual Re-ranking"
CSA: Contextual Similarity Aggregation with Self-attention for Visual Re-ranking PyTorch training code for CSA (Contextual Similarity Aggregation). We
19 Oct 21, 2022
Implementation of TF-IDF algorithm to find documents similarity with cosine similarity
NLP learning Trying to learn NLP to use in my projects! Table of Contents About The Project Built With Getting Started Requirements Run Usage License
 3 Aug 25, 2022
3 Aug 25, 2022
Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR
Speech_38_ru_commands Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR Программа умеет распознавать 38 ключевы
 9 May 5, 2022
9 May 5, 2022
A Word Level Transformer layer based on PyTorch and 🤗 Transformers.
Transformer Embedder A Word Level Transformer layer based on PyTorch and 🤗 Transformers. How to use Install the library from PyPI: pip install transf
 27 Nov 20, 2022
27 Nov 20, 2022
On-device wake word detection powered by deep learning.
Porcupine Made in Vancouver, Canada by Picovoice Porcupine is a highly-accurate and lightweight wake word engine. It enables building always-listening
 2.8k Dec 29, 2022
2.8k Dec 29, 2022
Vector AI — A platform for building vector based applications. Encode, query and analyse data using vectors.
Vector AI is a framework designed to make the process of building production grade vector based applications as quickly and easily as possible. Create
 267 Dec 23, 2022
267 Dec 23, 2022

Compare neural networks by their feature similarity
PyTorch Model Compare A tiny package to compare two neural networks in PyTorch. There are many ways to compare two neural networks, but one robust and
 181 Jan 4, 2023
181 Jan 4, 2023
 2 Jan 28, 2022
2 Jan 28, 2022
This repository contains the code for EMNLP-2021 paper "Word-Level Coreference Resolution"
Word-Level Coreference Resolution This is a repository with the code to reproduce the experiments described in the paper of the same name, which was a
 79 Dec 27, 2022
79 Dec 27, 2022

Code for the TIP 2021 Paper "Salient Object Detection with Purificatory Mechanism and Structural Similarity Loss"
PurNet Project for the TIP 2021 Paper "Salient Object Detection with Purificatory Mechanism and Structural Similarity Loss" Abstract Image-based salie
 4 Aug 25, 2022
4 Aug 25, 2022

Official PyTorch Implementation of Learning Self-Similarity in Space and Time as Generalized Motion for Video Action Recognition, ICCV 2021
Official PyTorch Implementation of Learning Self-Similarity in Space and Time as Generalized Motion for Video Action Recognition, ICCV 2021
 26 Dec 7, 2022
26 Dec 7, 2022

Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordcloud packages
Wikipedia WordCloud App Wikipedia WordCloud App generate Wikipedia word cloud art created using python's streamlit, matplotlib, wikipedia and wordclou
 5 Jan 2, 2022
5 Jan 2, 2022
Source code for the paper "SEPP: Similarity Estimation of Predicted Probabilities for Defending and Detecting Adversarial Text" PACLIC 2021
Adversarial text generator Refer to "adversarial_text_generator"[https://github.com/quocnsh/SEPP_generator] project for generating adversarial texts A
 0 Oct 5, 2021
0 Oct 5, 2021

PyTorch implementation of Weak-shot Fine-grained Classification via Similarity Transfer
SimTrans-Weak-Shot-Classification This repository contains the official PyTorch implementation of the following paper: Weak-shot Fine-grained Classifi
60 Dec 2, 2022
Official implementation of NeurIPS 2021 paper "One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning Objective"
Official implementation of NeurIPS 2021 paper "One Loss for All: Deep Hashing with a Single Cosine Similarity based Learning Objective"
 71 Dec 22, 2022
71 Dec 22, 2022
Telegram Group Management Bot based on phython !!!
How to setup/deploy. For easiest way to deploy this Bot click on the below button Mᴀᴅᴇ Bʏ Sᴜᴘᴘᴏʀᴛ Sᴏᴜʀᴄᴇ Find This Bot on Telegram A modular Telegram
 5 Nov 17, 2021
5 Nov 17, 2021
split Word file by chapter
split Word file by chapter we use the mircosoft word api to code this tool api url:https://docs.microsoft.com/zh-cn/dotnet/api/ if this tool is good f
 5 Nov 6, 2021
5 Nov 6, 2021
Code for ACL'2021 paper WARP 🌀 Word-level Adversarial ReProgramming
Code for ACL'2021 paper WARP 🌀 Word-level Adversarial ReProgramming. Outperforming `GPT-3` on SuperGLUE Few-Shot text classification.
 75 Nov 6, 2022
75 Nov 6, 2022

A Pytorch implementation of "Splitter: Learning Node Representations that Capture Multiple Social Contexts" (WWW 2019).
Splitter ⠀⠀ A PyTorch implementation of Splitter: Learning Node Representations that Capture Multiple Social Contexts (WWW 2019). Abstract Recent inte
 201 Nov 9, 2022
201 Nov 9, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022

TensorFlow Similarity is a python package focused on making similarity learning quick and easy.
TensorFlow Similarity is a python package focused on making similarity learning quick and easy.
 912 Jan 8, 2023
912 Jan 8, 2023
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
 3.1k Dec 31, 2022
3.1k Dec 31, 2022
This repository contains the code for EMNLP-2021 paper "Word-Level Coreference Resolution"
Word-Level Coreference Resolution This is a repository with the code to reproduce the experiments described in the paper of the same name, which was a
79 Dec 27, 2022

MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving.
MWPToolkit is a PyTorch-based toolkit for Math Word Problem (MWP) solving. It is a comprehensive framework for research purpose that integrates popular MWP benchmark datasets and typical deep learning-based MWP algorithms.
 119 Jan 4, 2023
119 Jan 4, 2023
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022

Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS)
TOPSIS implementation in Python Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS) CHING-LAI Hwang and Yoon introduced TOPSIS
 8 Dec 10, 2022
8 Dec 10, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022
从flomo导出的笔记中生成词云
flomo-word-cloud 从flomo导出的笔记中生成词云 如何使用? 将本项目克隆到你的电脑上,使用如下的命令,安装所需python库 pip install -r requirements.txt 在项目里新建一个file文件夹,把所有从flomo导出的html文件放入其中 运行main
 9 Dec 30, 2022
9 Dec 30, 2022
This is the official pytorch implementation for the paper: Instance Similarity Learning for Unsupervised Feature Representation.
ISL This is the official pytorch implementation for the paper: Instance Similarity Learning for Unsupervised Feature Representation, which is accepted
 19 May 4, 2022
19 May 4, 2022
emoji-math computes the given python expression and returns either the value or the nearest 5 emojis as measured by cosine similarity.
emoji-math computes the given python expression and returns either the value or the nearest 5 emojis as measured by cosine similarity.
 13 Dec 11, 2022
13 Dec 11, 2022
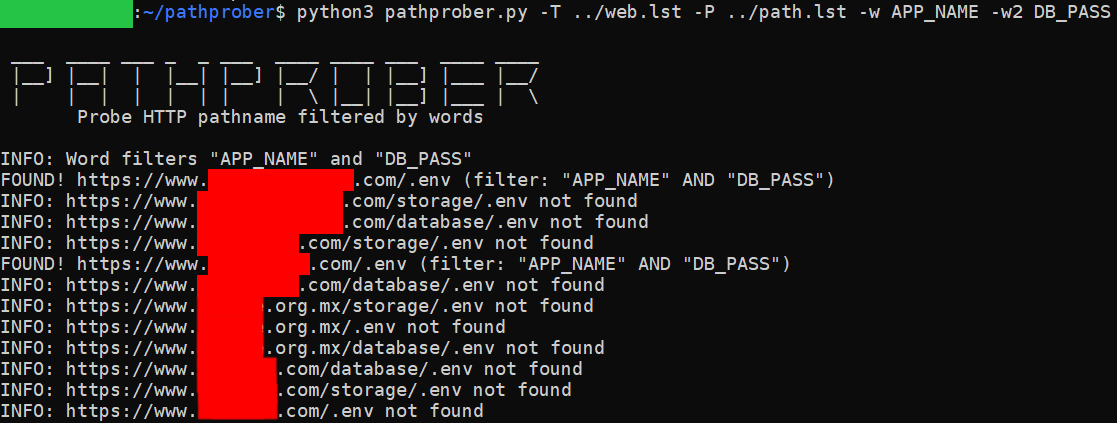
Probe and discover HTTP pathname using brute-force methodology and filtered by specific word or 2 words at once
pathprober Probe and discover HTTP pathname using brute-force methodology and filtered by specific word or 2 words at once. Purpose Brute-forcing webs
 41 Jul 6, 2022
41 Jul 6, 2022
RapidFuzz is a fast string matching library for Python and C++
RapidFuzz is a fast string matching library for Python and C++, which is using the string similarity calculations from FuzzyWuzzy
 1.7k Jan 4, 2023
1.7k Jan 4, 2023

An implementation of DeepMind's Relational Recurrent Neural Networks in PyTorch.
relational-rnn-pytorch An implementation of DeepMind's Relational Recurrent Neural Networks (Santoro et al. 2018) in PyTorch. Relational Memory Core (
 241 Nov 18, 2022
241 Nov 18, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
114 Nov 4, 2022

A PyTorch implementation of "SimGNN: A Neural Network Approach to Fast Graph Similarity Computation" (WSDM 2019).
SimGNN ⠀⠀⠀ A PyTorch implementation of SimGNN: A Neural Network Approach to Fast Graph Similarity Computation (WSDM 2019). Abstract Graph similarity s
534 Dec 25, 2022
A Pytorch implementation of "Splitter: Learning Node Representations that Capture Multiple Social Contexts" (WWW 2019).
Splitter ⠀⠀ A PyTorch implementation of Splitter: Learning Node Representations that Capture Multiple Social Contexts (WWW 2019). Abstract Recent inte
201 Nov 9, 2022
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022
Code for the Image similarity challenge.
ISC 2021 This repository contains code for the Image Similarity Challenge 2021. Getting started The docs subdirectory has step-by-step instructions on
173 Dec 12, 2022

The AugNet Python module contains functions for the fast computation of image similarity.
AugNet AugNet: End-to-End Unsupervised Visual Representation Learning with Image Augmentation arxiv link In our work, we propose AugNet, a new deep le
 74 Dec 28, 2022
74 Dec 28, 2022
Code for the ACL2021 paper "Combining Static Word Embedding and Contextual Representations for Bilingual Lexicon Induction"
CSCBLI Code for our ACL Findings 2021 paper, "Combining Static Word Embedding and Contextual Representations for Bilingual Lexicon Induction". Require
 12 Oct 8, 2022
12 Oct 8, 2022
Code for Graph-to-Tree Learning for Solving Math Word Problems (ACL 2020)
Graph-to-Tree Learning for Solving Math Word Problems PyTorch implementation of Graph based Math Word Problem solver described in our ACL 2020 paper G
 66 Nov 23, 2022
66 Nov 23, 2022
Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021)
L1-Refinement Paddle implementation for "Cross-Lingual Word Embedding Refinement by ℓ1 Norm Optimisation" (NAACL 2021) 🙈 A more detailed readme is co
 4 Jun 9, 2021
4 Jun 9, 2021
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
A curated list of awesome resources related to Semantic Search🔎 and Semantic Similarity tasks.
 224 Jan 4, 2023
224 Jan 4, 2023

Code for our paper "Mask-Align: Self-Supervised Neural Word Alignment" in ACL 2021
Mask-Align: Self-Supervised Neural Word Alignment This is the implementation of our work Mask-Align: Self-Supervised Neural Word Alignment. @inproceed
 46 Dec 15, 2022
46 Dec 15, 2022
Code for the paper "Adapting Monolingual Models: Data can be Scarce when Language Similarity is High"
Wietse de Vries • Martijn Bartelds • Malvina Nissim • Martijn Wieling Adapting Monolingual Models: Data can be Scarce when Language Similarity is High
 5 Aug 2, 2021
5 Aug 2, 2021
Minimal implementation of PAWS (https://arxiv.org/abs/2104.13963) in TensorFlow.
PAWS-TF 🐾 Implementation of Semi-Supervised Learning of Visual Features by Non-Parametrically Predicting View Assignments with Support Samples (PAWS)
 43 Jan 8, 2023
43 Jan 8, 2023

MILES is a multilingual text simplifier inspired by LSBert - A BERT-based lexical simplification approach proposed in 2018. Unlike LSBert, MILES uses the bert-base-multilingual-uncased model, as well as simple language-agnostic approaches to complex word identification (CWI) and candidate ranking.
MILES Multilingual Lexical Simplifier Explore the docs » Read LSBert Paper · Report Bug · Request Feature About The Project MILES is a multilingual te
 45 Oct 19, 2022
45 Oct 19, 2022
Automatically create Faiss knn indices with the most optimal similarity search parameters.
It selects the best indexing parameters to achieve the highest recalls given memory and query speed constraints.
 419 Jan 1, 2023
419 Jan 1, 2023

A library for Multilingual Unsupervised or Supervised word Embeddings
MUSE: Multilingual Unsupervised and Supervised Embeddings MUSE is a Python library for multilingual word embeddings, whose goal is to provide the comm
3k Jan 6, 2023
Official repository for Jia, Raghunathan, Göksel, and Liang, "Certified Robustness to Adversarial Word Substitutions" (EMNLP 2019)
Certified Robustness to Adversarial Word Substitutions This is the official GitHub repository for the following paper: Certified Robustness to Adversa
 38 Oct 16, 2022
38 Oct 16, 2022

Quasi-Dense Similarity Learning for Multiple Object Tracking, CVPR 2021 (Oral)
Quasi-Dense Tracking This is the offical implementation of paper Quasi-Dense Similarity Learning for Multiple Object Tracking. We present a trailer th
 327 Dec 27, 2022
327 Dec 27, 2022
![The code of “Similarity Reasoning and Filtration for Image-Text Matching” [AAAI2021]](https://github.com/Paranioar/SGRAF/raw/main/fig/model.png)
The code of “Similarity Reasoning and Filtration for Image-Text Matching” [AAAI2021]
SGRAF PyTorch implementation for AAAI2021 paper of “Similarity Reasoning and Filtration for Image-Text Matching”. It is built on top of the SCAN and C
 149 Dec 22, 2022
149 Dec 22, 2022
Scene Text Retrieval via Joint Text Detection and Similarity Learning
This is the code of "Scene Text Retrieval via Joint Text Detection and Similarity Learning". For more details, please refer to our CVPR2021 paper.
 79 Nov 29, 2022
79 Nov 29, 2022

PyTorch Implementation of Region Similarity Representation Learning (ReSim)
ReSim This repository provides the PyTorch implementation of Region Similarity Representation Learning (ReSim) described in this paper: @Article{xiao2
 74 Jan 3, 2023
74 Jan 3, 2023

Top2Vec is an algorithm for topic modeling and semantic search.
Top2Vec is an algorithm for topic modeling and semantic search. It automatically detects topics present in text and generates jointly embedded topic, document and word vectors.
 2.4k Jan 6, 2023
2.4k Jan 6, 2023
Code for paper "A Critical Assessment of State-of-the-Art in Entity Alignment" (https://arxiv.org/abs/2010.16314)
A Critical Assessment of State-of-the-Art in Entity Alignment This repository contains the source code for the paper A Critical Assessment of State-of
 16 Oct 14, 2022
16 Oct 14, 2022

Official implementation of Monocular Quasi-Dense 3D Object Tracking
Monocular Quasi-Dense 3D Object Tracking Monocular Quasi-Dense 3D Object Tracking (QD-3DT) is an online framework detects and tracks objects in 3D usi
441 Dec 20, 2022

This is a c++ project deploying a deep scene text reading pipeline with tensorflow. It reads text from natural scene images. It uses frozen tensorflow graphs. The detector detect scene text locations. The recognizer reads word from each detected bounding box.
DeepSceneTextReader This is a c++ project deploying a deep scene text reading pipeline. It reads text from natural scene images. Prerequsites The proj
 49 Sep 10, 2022
49 Sep 10, 2022