Filter By
355 Repositories
Python Web Crawling
薅薅乐 - JD 测试脚本
薅薅乐 安裝 使用docker docker一键安装: docker run -d --name jd classmatelin/hhl:latest. 使用 进入容器: docker exec -it jd bash 获取JD_COOKIES: python get_jd_cookies.py,
 575 Dec 28, 2022
575 Dec 28, 2022
a small library for extracting rich content from urls
A small library for extracting rich content from urls. what does it do? micawber supplies a few methods for retrieving rich metadata about a variety o
 588 Dec 27, 2022
588 Dec 27, 2022
robobrowser - A simple, Pythonic library for browsing the web without a standalone web browser.
RoboBrowser: Your friendly neighborhood web scraper Homepage: http://robobrowser.readthedocs.org/ RoboBrowser is a simple, Pythonic library for browsi
 3.7k Dec 27, 2022
3.7k Dec 27, 2022

Python script to check if there is any differences in responses of an application when the request comes from a search engine's crawler.
crawlersuseragents This Python script can be used to check if there is any differences in responses of an application when the request comes from a se
 13 Dec 27, 2022
13 Dec 27, 2022
Command line program to download documents from web portals.
command line document download made easy Highlights list available documents in json format or download them filter documents using string matching re
 16 Dec 26, 2022
16 Dec 26, 2022
A high-level distributed crawling framework.
Cola: high-level distributed crawling framework Overview Cola is a high-level distributed crawling framework, used to crawl pages and extract structur
 1.5k Dec 24, 2022
1.5k Dec 24, 2022
A modern CSS selector implementation for BeautifulSoup
Soup Sieve Overview Soup Sieve is a CSS selector library designed to be used with Beautiful Soup 4. It aims to provide selecting, matching, and filter
 151 Dec 23, 2022
151 Dec 23, 2022

🥫 The simple, fast, and modern web scraping library
About gazpacho is a simple, fast, and modern web scraping library. The library is stable, actively maintained, and installed with zero dependencies. I
 692 Dec 22, 2022
692 Dec 22, 2022
抢京东茅台脚本,定时自动触发,自动预约,自动停止
jd_maotai 抢京东茅台脚本,定时自动触发,自动预约,自动停止 小白信用 99.6,暂时还没抢到过,朋友 80 多抢到了一瓶,所以我感觉是跟信用分没啥关系,完全是看运气的。
 117 Dec 22, 2022
117 Dec 22, 2022
Simple Web scrapper Bot to scrap webpages using Requests, html5lib and Beautifulsoup.
WebScrapperRoBot Simple Web scrapper Bot to scrap webpages using Requests, html5lib and Beautifulsoup. Mark your Star ⭐ ⭐ What is Web Scraping ? Web s
 53 Dec 21, 2022
53 Dec 21, 2022
Pro Football Reference Game Data Webscraper
Pro Football Reference Game Data Webscraper Code Copyright Yeetzsche This is a simple Pro Football Reference Webscraper that can either collect all ga
 6 Dec 21, 2022
6 Dec 21, 2022
An Automated udemy coupons scraper which scrapes coupons and autopost the result in blogspot post
Autoscraper-n-blogger An Automated udemy coupons scraper which scrapes coupons and autopost the result in blogspot post and notifies via Telegram bot
 13 Dec 21, 2022
13 Dec 21, 2022
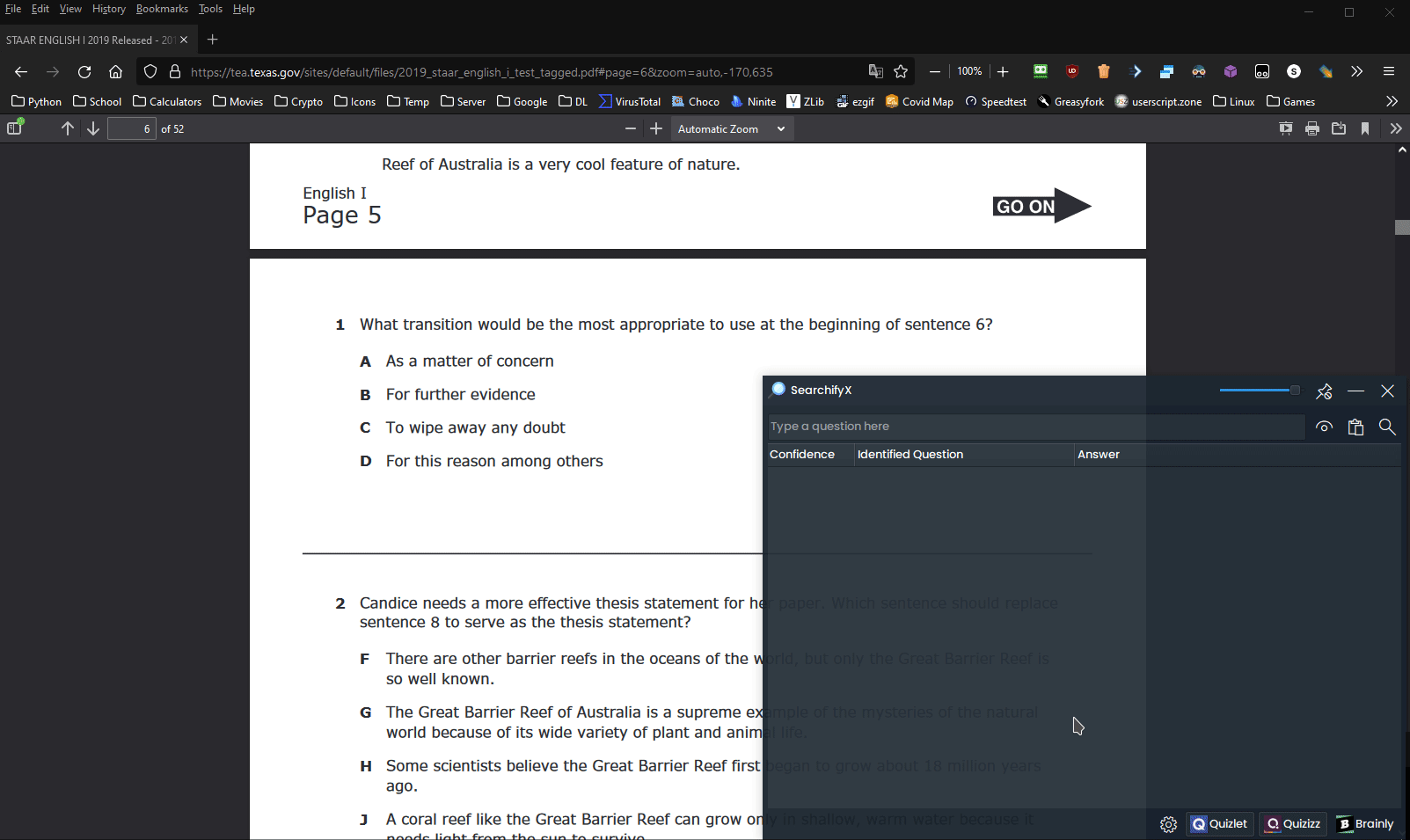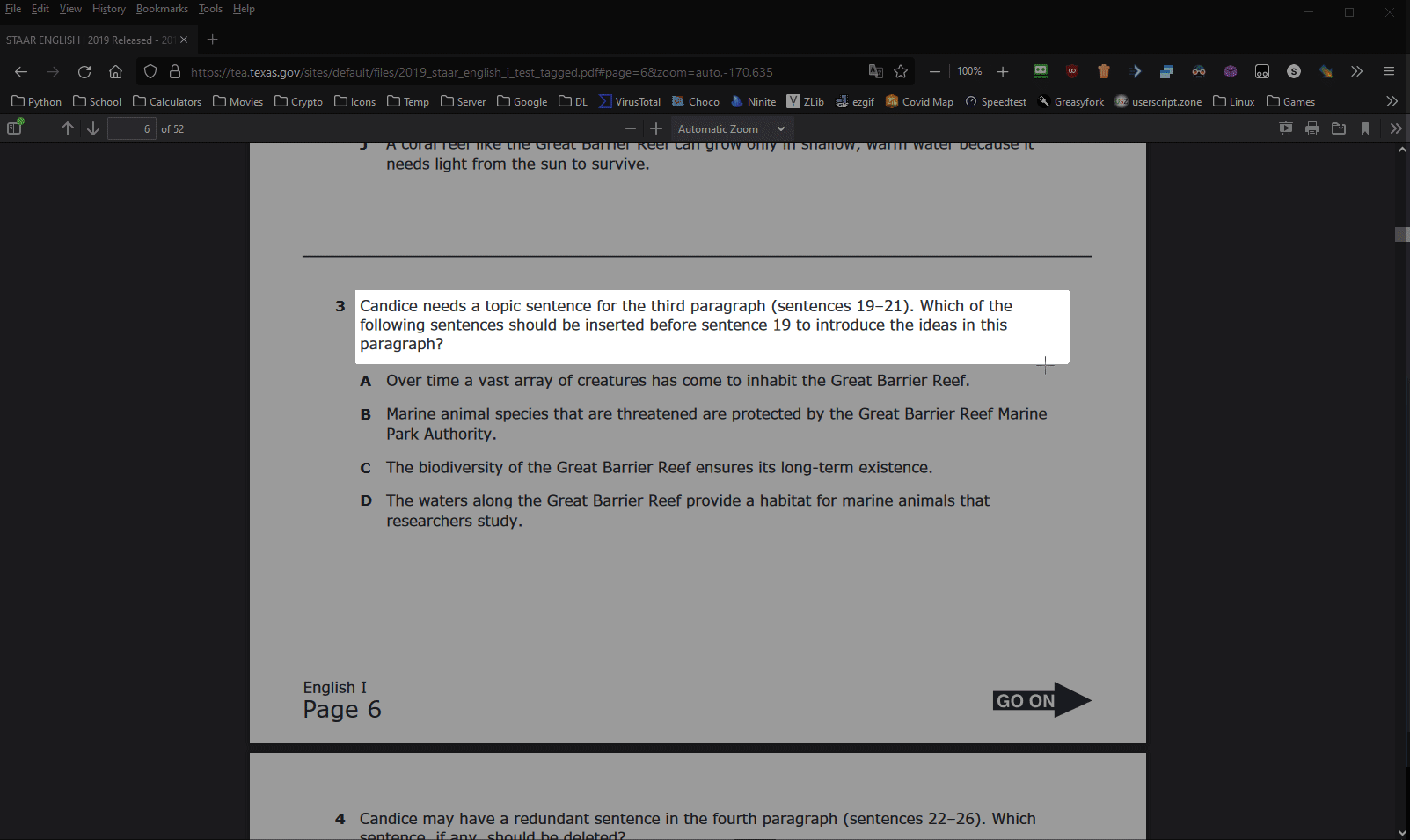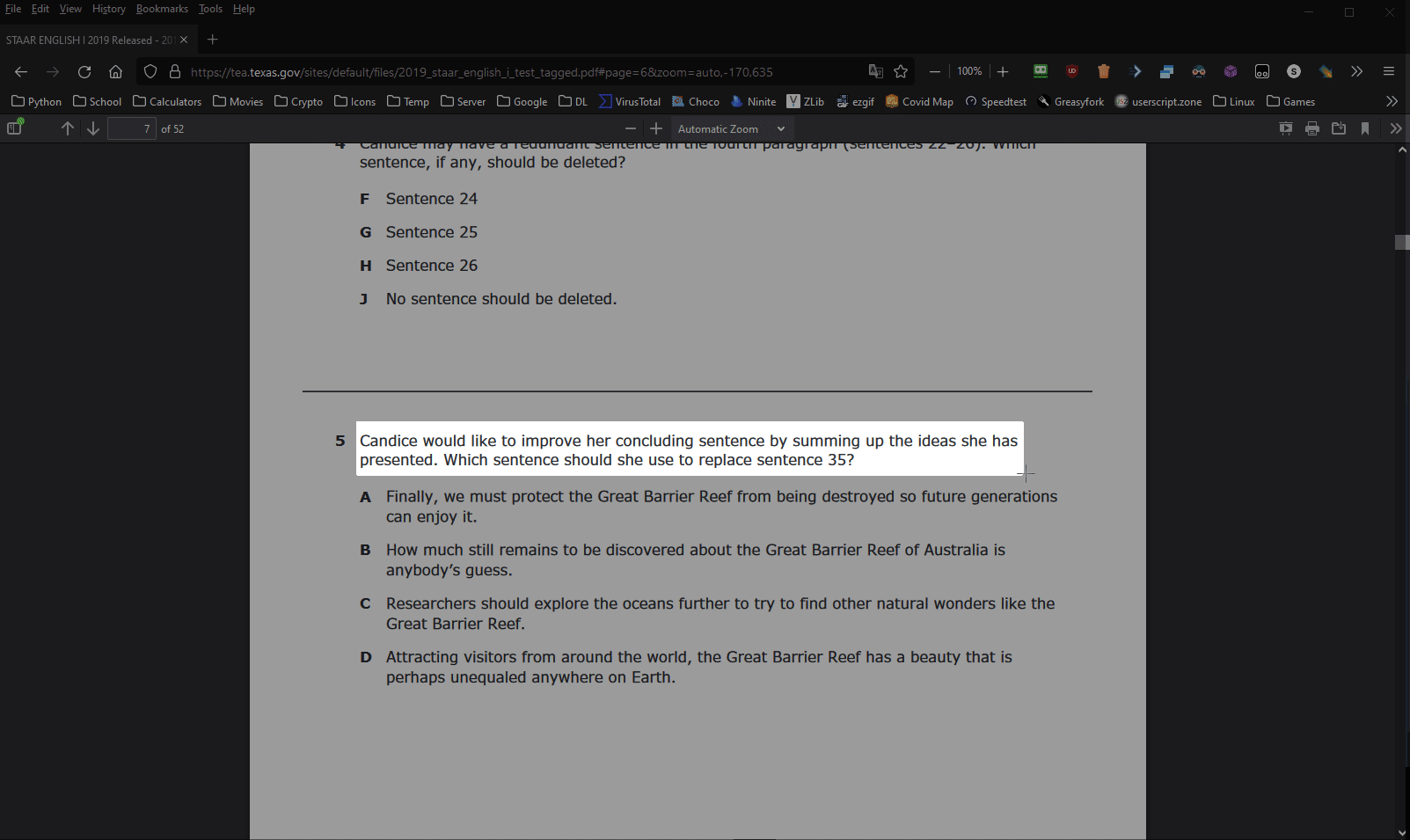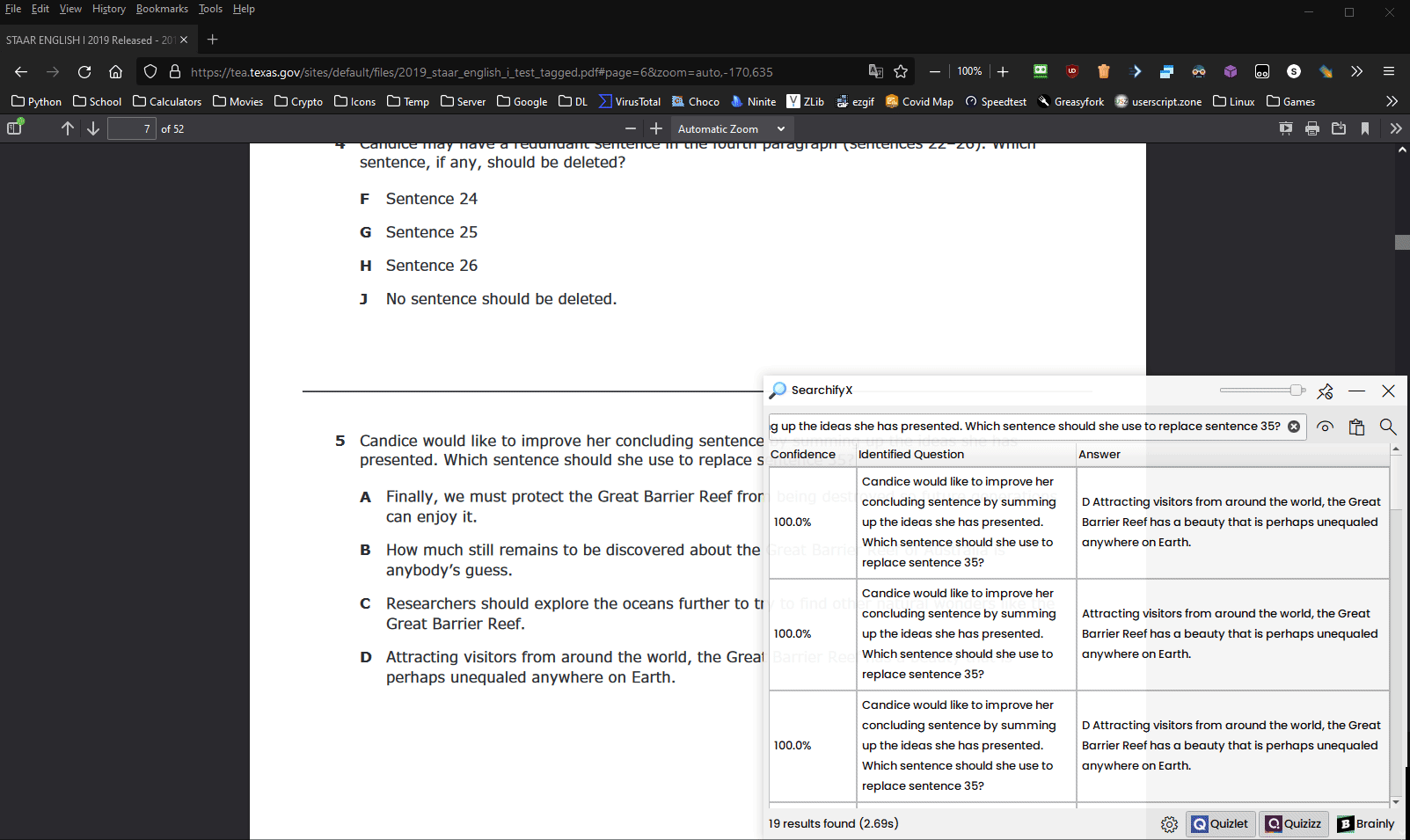
SearchifyX, predecessor to Searchify, is a fast Quizlet, Quizizz, and Brainly webscraper with various stealth features.
SearchifyX SearchifyX, predecessor to Searchify, is a fast Quizlet, Quizizz, and Brainly webscraper with various stealth features. SearchifyX lets you
 28 Dec 20, 2022
28 Dec 20, 2022
UsernameScraperTool - Username Scraper Tool With Python
UsernameScraperTool Username Scraper for 40+ Social sites. How To use git clone
 1 Dec 20, 2022
1 Dec 20, 2022
Web Content Retrieval for Humans™
Lassie Lassie is a Python library for retrieving basic content from websites. Usage import lassie lassie.fetch('http://www.youtube.com/watch?v
 570 Dec 19, 2022
570 Dec 19, 2022
TikTok Username Swapper/Claimer/etc
TikTok-Turbo TikTok Username Swapper/Claimer/etc I wanted to create it as fast as possible but i eventually gave up and recoded it many many many many
 12 Dec 19, 2022
12 Dec 19, 2022
A Python Oriented tool to Scrap WhatsApp Group Link using Google Dork it Scraps Whatsapp Group Links From Google Results And Gives Working Links.
WaGpScraper A Python Oriented tool to Scrap WhatsApp Group Link using Google Dork it Scraps Whatsapp Group Links From Google Results And Gives Working
 27 Dec 18, 2022
27 Dec 18, 2022
Google Maps crawler using Selenium
Google Maps Crawler using Selenium Built as part of the Antifragile Dev Project Selenium crawler that browses Google Maps as a regular user and stores
 46 Dec 16, 2022
46 Dec 16, 2022
script to scrape direct download links (ddls) from google drive index.
bhadoo Google Personal/Shared Drive Index scraper. A small script to scrape direct download links (ddls) of downloadable files from bhadoo google driv
 53 Dec 16, 2022
53 Dec 16, 2022
淘宝茅台抢购最新优化版本,淘宝茅台秒杀,优化了茅台抢购线程队列
淘宝茅台抢购最新优化版本,淘宝茅台秒杀,优化了茅台抢购线程队列
 118 Dec 16, 2022
118 Dec 16, 2022
A universal package of scraper scripts for humans
Scrapera is a completely Chromedriver free package that provides access to a variety of scraper scripts for most commonly used machine learning and data science domains.
 299 Dec 15, 2022
299 Dec 15, 2022

Dude is a very simple framework for writing web scrapers using Python decorators
Dude is a very simple framework for writing web scrapers using Python decorators. The design, inspired by Flask, was to easily build a web scraper in just a few lines of code. Dude has an easy-to-learn syntax.
 326 Dec 15, 2022
326 Dec 15, 2022
Subscrape - A Python scraper for substrate chains
subscrape A Python scraper for substrate chains that uses Subscan. Usage copy co
 14 Dec 15, 2022
14 Dec 15, 2022
Find papers by keywords and venues. Then download it automatically
paper finder Find papers by keywords and venues. Then download it automatically. How to use this? Search CLI python search.py -k "knowledge tracing,kn
 2 Dec 15, 2022
2 Dec 15, 2022
This is a python api to scrape search results from a url.
googlescrape Installation Installation is simple! # Stable version pip install googlescrape Examples from googlescrape import client scrapeClient=cli
 1 Dec 15, 2022
1 Dec 15, 2022

The open-source web scrapers that feed the Los Angeles Times California coronavirus tracker.
The open-source web scrapers that feed the Los Angeles Times' California coronavirus tracker. Processed data ready for analysis is available at datade
 51 Dec 14, 2022
51 Dec 14, 2022
Scrapes Every Email Address of Every Society in Every University
society-email-scrape Site Live at https://kcsoc.github.io/society-email-scrape/ How to automatically generate new data Go to unis.yml Add your uni Cre
 18 Dec 14, 2022
18 Dec 14, 2022
A Web Scraping Program.
Web Scraping AUTHOR: Saurabh G. MTech Information Security, IIT Jammu. If you find this repository useful. I would appreciate if you Star it and Fork
 2 Dec 14, 2022
2 Dec 14, 2022
京东茅台抢购 2021年4月最新版
Jd_Seckill 特别声明: 本仓库发布的jd_seckill项目中涉及的任何脚本,仅用于测试和学习研究,禁止用于商业用途,不能保证其合法性,准确性,完整性和有效性,请根据情况自行判断。 本项目内所有资源文件,禁止任何公众号、自媒体进行任何形式的转载、发布。 huanghyw 对任何脚本问题概不
 45 Dec 14, 2022
45 Dec 14, 2022
京东茅台抢购最新优化版本,京东茅台秒杀,优化了茅台抢购进程队列
京东茅台抢购最新优化版本,京东茅台秒杀,优化了茅台抢购进程队列
129 Dec 14, 2022

Twitter Eye is a Twitter Information Gathering Tool With Twitter Eye
Twitter Eye is a Twitter Information Gathering Tool With Twitter Eye, you can search with various keywords and usernames on Twitter.
 19 Dec 12, 2022
19 Dec 12, 2022
中国大学生在线 四史自动答题刷分(现仅支持英雄篇)
中国大学生在线 “四史”学习教育竞答 自动答题 刷分 (现仅支持英雄篇,已更新可用) 若对您有所帮助,记得点个Star 🌟 !!! 中国大学生在线 “四史”学习教育竞答 自动答题 刷分 (现仅支持英雄篇,已更新可用) 🥰 🥰 🥰 依赖 本项目依赖的第三方库: requests 在终端执行以下
 229 Dec 12, 2022
229 Dec 12, 2022

LSpider 一个为被动扫描器定制的前端爬虫
LSpider LSpider - 一个为被动扫描器定制的前端爬虫 什么是LSpider? 一款为被动扫描器而生的前端爬虫~ 由Chrome Headless、LSpider主控、Mysql数据库、RabbitMQ、被动扫描器5部分组合而成。
 321 Dec 12, 2022
321 Dec 12, 2022

京东云无线宝积分推送,支持查看多设备积分使用情况
JDRouterPush 项目简介 本项目调用京东云无线宝API,可每天定时推送积分收益情况,帮助你更好的观察主要信息 更新日志 2021-03-02: 查询绑定的京东账户 通知排版优化 脚本检测更新 支持Server酱Turbo版 2021-02-25: 实现多设备查询 查询今
 199 Dec 12, 2022
199 Dec 12, 2022
Auto Join: A GitHub action script to automatically invite everyone to the organization who star your repository.
Auto Invite To The Organization By Star A GitHub Action script to automatically invite everyone to your organization that stars your repository. What
 11 Dec 11, 2022
11 Dec 11, 2022

Binance Smart Chain Contract Scraper + Contract Evaluator
Pulls Binance Smart Chain feed of newly-verified contracts every 30 seconds, then checks their contract code for links to socials.Returns only those with socials information included, and then submits the contract address to TokenSniffer to evaluate contract legitimacy
 14 Dec 9, 2022
14 Dec 9, 2022
Binance Smart Chain Contract Scraper + Contract Evaluator
Pulls Binance Smart Chain feed of newly-verified contracts every 30 seconds, then checks their contract code for links to socials.Returns only those with socials information included, and then submits the contract address to TokenSniffer to evaluate contract legitimacy
14 Dec 9, 2022
Using Python and Pushshift.io to Track stocks on the WallStreetBets subreddit
wallstreetbets-tracker Using Python and Pushshift.io to Track stocks on the WallStreetBets subreddit.
 91 Dec 8, 2022
91 Dec 8, 2022
 28 Dec 8, 2022
28 Dec 8, 2022
Proxy scraper. Format: IP | PORT | COUNTRY | TYPE
proxy scraper 🔎 Installation: git clone https://github.com/ebankoff/proxy_scraper Required pip libraries (pip install library name): lxml beautifulso
 19 Dec 7, 2022
19 Dec 7, 2022

Python script that reads Aliexpress offers urls from a Excel filename (.csv) and post then in a Telegram channel using a bot
Aliexpress to telegram post Python script that reads Aliexpress offers urls from a Excel filename (.csv) and post then in a Telegram channel using a b
 6 Dec 6, 2022
6 Dec 6, 2022
A tool to easily scrape youtube data using the Google API
YouTube data scraper To easily scrape any data from the youtube homepage, a youtube channel/user, search results, playlists, and a single video itself
 7 Dec 3, 2022
7 Dec 3, 2022
🐞 Douban Movie / Douban Book Scarpy
Python3-based Douban Movie/Douban Book Scarpy crawler for cover downloading + data crawling + review entry.
 1 Dec 3, 2022
1 Dec 3, 2022
京东茅台抢购
截止 2021/2/1 日,该项目已无法使用! 京东:约满即止,仅限京东实名认证用户APP端抢购,2月1日10:00开始预约,2月1日12:00开始抢购(京东APP需升级至8.5.6版本及以上) 写在前面 本项目来自 huanghyw - jd_seckill,作者的项目地址我找不到了,找到了再贴上
 73 Dec 3, 2022
73 Dec 3, 2022

Audio media crawler for lbry.
Audio media crawler for lbry. Requirements Python 3.8 Poetry 1.1.7 Elasticsearch 7.14.0 Lbry-sdk 0.99.0 Development This project uses poetry as a depe
 4 Dec 3, 2022
4 Dec 3, 2022
A powerful annex BUBT, BUBT Soft, and BUBT website scraping script.
Annex Bubt Scraping Script I think this is the first public repository that provides free annex-BUBT, BUBT-Soft, and BUBT website scraping API script
 4 Dec 3, 2022
4 Dec 3, 2022

Telegram Group Scrapper
this programe is make your work so much easy on telegrame. do you want to send messages on everyone to your group or others group. use this script it will do your work automatically with one click. and sit down and watch the screen. if you want to add members on your group then jest use this script it will do your work.
 3 Dec 3, 2022
3 Dec 3, 2022
download NCERT books using scrapy
download_ncert_books download NCERT books using scrapy Downloading Books: You can either use the spider by cloning this repo and following the instruc
 1 Dec 2, 2022
1 Dec 2, 2022
A web service for scanning media hosted by a Matrix media repository
Matrix Content Scanner A web service for scanning media hosted by a Matrix media repository Installation TODO Development In a virtual environment wit
 5 Dec 1, 2022
5 Dec 1, 2022
Shopee Scraper - A web scraper in python that extract sales, price, avaliable stock, location and more of a given seller in Brazil
Shopee Scraper A web scraper in python that extract sales, price, avaliable stock, location and more of a given seller in Brazil. The project was crea
 5 Nov 29, 2022
5 Nov 29, 2022
Simple library for exploring/scraping the web or testing a website you’re developing
Robox is a simple library with a clean interface for exploring/scraping the web or testing a website you’re developing. Robox can fetch a page, click on links and buttons, and fill out and submit forms.
 79 Nov 27, 2022
79 Nov 27, 2022
a Scrapy spider that utilizes Postgres as a DB, Squid as a proxy server, Redis for de-duplication and Splash to render JavaScript. All in a microservices architecture utilizing Docker and Docker Compose
This is George's Scraping Project To get started cd into the theZoo file and run: chmod +x script.sh then: ./script.sh This will spin up a Postgres co
 7 Nov 27, 2022
7 Nov 27, 2022
基于Github Action的定时HITsz疫情上报脚本,开箱即用
HITsz Daily Report 基于 GitHub Actions 的「HITsz 疫情系统」访问入口 定时自动上报脚本,开箱即用。 感谢 @JellyBeanXiewh 提供原始脚本和 idea。 感谢 @bugstop 对脚本进行重构并新增 Easy Connect 校内代理访问。
 56 Nov 27, 2022
56 Nov 27, 2022

A web scraper for nomadlist.com, made to avoid website restrictions.
Gypsylist gypsylist.py is a web scraper for nomadlist.com, made to avoid website restrictions. nomadlist.com is a website with a lot of information fo
 5 Nov 24, 2022
5 Nov 24, 2022