Filter By
355 Repositories
Python Web Crawling

PaperRobot: a paper crawler that can quickly download numerous papers, facilitating paper studying and management
PaperRobot PaperRobot 是一个论文抓取工具,可以快速批量下载大量论文,方便后期进行持续的论文管理与学习。 PaperRobot通过多个接口抓取论文,目前抓取成功率维持在90%以上。通过配置Config文件,可以抓取任意计算机领域相关会议的论文。 Installation Down
 47 Nov 23, 2022
47 Nov 23, 2022
This repo has the source code for the crawler and data crawled from auto-data.net
This repo contains the source code for crawler and crawled data of cars specifications from autodata. The data has roughly 45k cars
 5 Nov 22, 2022
5 Nov 22, 2022

Goblyn is a Python tool focused to enumeration and capture of website files metadata.
Goblyn Metadata Enumeration What's Goblyn? Goblyn is a tool focused to enumeration and capture of website files metadata. How it works? Goblyn will se
 46 Nov 22, 2022
46 Nov 22, 2022
Pelican plugin that adds site search capability
Search: A Plugin for Pelican This plugin generates an index for searching content on a Pelican-powered site. Why would you want this? Static sites are
 22 Nov 21, 2022
22 Nov 21, 2022
Extract gene TSS site form gencode/ensembl/gencode database GTF file and export bed format file.
GetTss python Package extract gene TSS site form gencode/ensembl/gencode database GTF file and export bed format file. Install $ pip install GetTss Us
 6 Nov 21, 2022
6 Nov 21, 2022
Generate a repository with mirror links for DriveDroid app
DriveDroid Repository Generator Generate a repository for the app that allow boot a PC using ISO files stored on your Android phone Check also an offi
 11 Nov 19, 2022
11 Nov 19, 2022
jd_maotai rpa 基于selenium驱动的jd抢购rpa机器人
jd_maotai rpa 基于selenium驱动的jd抢购rpa机器人, 照顾我们这样的马大哈, 不会忘记抢购了, 祝大家过年都能喝上茅台. 特别声明: 本仓库发布的jd_maotai_rpa项目定义为自动化rpa项目, 是用于防止忘记参与jd茅台的活动(由于本人时常忘记), 而不是为了秒杀和抢
 35 Nov 18, 2022
35 Nov 18, 2022
👨🏼⚖️ reddit bot that turns comment chains into ace attorney scenes
Ace Attorney reddit bot 👨🏼⚖️ Reddit bot that turns comment chains into ace attorney scenes. You'll need to sign up for streamable and reddit and se
 763 Nov 17, 2022
763 Nov 17, 2022
FilmMikirAPI - A simple rest-api which is used for scrapping on the Kincir website using the Python and Flask package
FilmMikirAPI - A simple rest-api which is used for scrapping on the Kincir website using the Python and Flask package
 1 Nov 17, 2022
1 Nov 17, 2022
Script for scrape user data like "id,username,fullname,followers,tweets .. etc" by Twitter's search engine .
TwitterScraper Script for scrape user data like "id,username,fullname,followers,tweets .. etc" by Twitter's search engine . Screenshot Data Users Only
 19 Nov 17, 2022
19 Nov 17, 2022
Download images from forum threads
Forum Image Scraper Downloads images from forum threads Only works with forums which doesn't require a login to view and have an incremental paginatio
 9 Nov 16, 2022
9 Nov 16, 2022
An IpVanish Proxies Scraper
EzProxies Tired of searching for good proxies for hours? Just get an IpVanish account and get thousands of good proxies in few seconds! Showcase Watch
 11 Nov 13, 2022
11 Nov 13, 2022
A python module to parse the Open Graph Protocol
OpenGraph is a module of python for parsing the Open Graph Protocol, you can read more about the specification at http://ogp.me/ Installation $ pip in
 213 Nov 12, 2022
213 Nov 12, 2022
UdemyBot - A Simple Udemy Free Courses Scrapper
UdemyBot - A Simple Udemy Free Courses Scrapper
 112 Nov 12, 2022
112 Nov 12, 2022
对于有验证码的站点爆破,用于安全合法测试
使用方法 python3 main.py + 配置好的文件 python3 main.py Verify.json python3 main.py NoVerify.json 以上分别对应有验证码的demo和无验证码的demo Tips: 你可以以域名作为配置文件名字加载:python3 main
 47 Nov 9, 2022
47 Nov 9, 2022
Crawl the information of a given keyword on Google search engine
Crawl the information of a given keyword on Google search engine
 4 Nov 9, 2022
4 Nov 9, 2022
HappyScrapper - Google news web scrapper with python
HappyScrapper ~ Google news web scrapper INSTALLATION ♦ Clone the repository ♦ O
 0 Nov 7, 2022
0 Nov 7, 2022
Instagram profile scrapper with python
IG Profile Scrapper Instagram profile Scrapper Just type the username, and boo! :D Instalation clone this repo to your computer git clone https://gith
 6 Nov 7, 2022
6 Nov 7, 2022
Transistor, a Python web scraping framework for intelligent use cases.
Web data collection and storage for intelligent use cases. transistor About The web is full of data. Transistor is a web scraping framework for collec
 212 Nov 5, 2022
212 Nov 5, 2022
🤖 Threaded Scraper to get discord servers from disboard.org written in python3
Disboard-Scraper Threaded Scraper to get discord servers from disboard.org written in python3. Setup. One thread / tag If you whant to look for multip
 11 Nov 1, 2022
11 Nov 1, 2022
API to parse tibia.com content into python objects.
Tibia.py An API to parse Tibia.com content into object oriented data. No fetching is done by this module, you must provide the html content. Features:
 25 Oct 31, 2022
25 Oct 31, 2022

A simple app to scrap data from Twitter.
Twitter-Scraping-App A simple app to scrap data from Twitter. Available Features Search query. Select number of data you want to fetch from twitter. C
 2 Oct 31, 2022
2 Oct 31, 2022
Meme-videos - Scrapes memes and turn them into a video compilations
Meme Videos Scrapes memes from reddit using praw and request and then converts t
 12 Oct 28, 2022
12 Oct 28, 2022
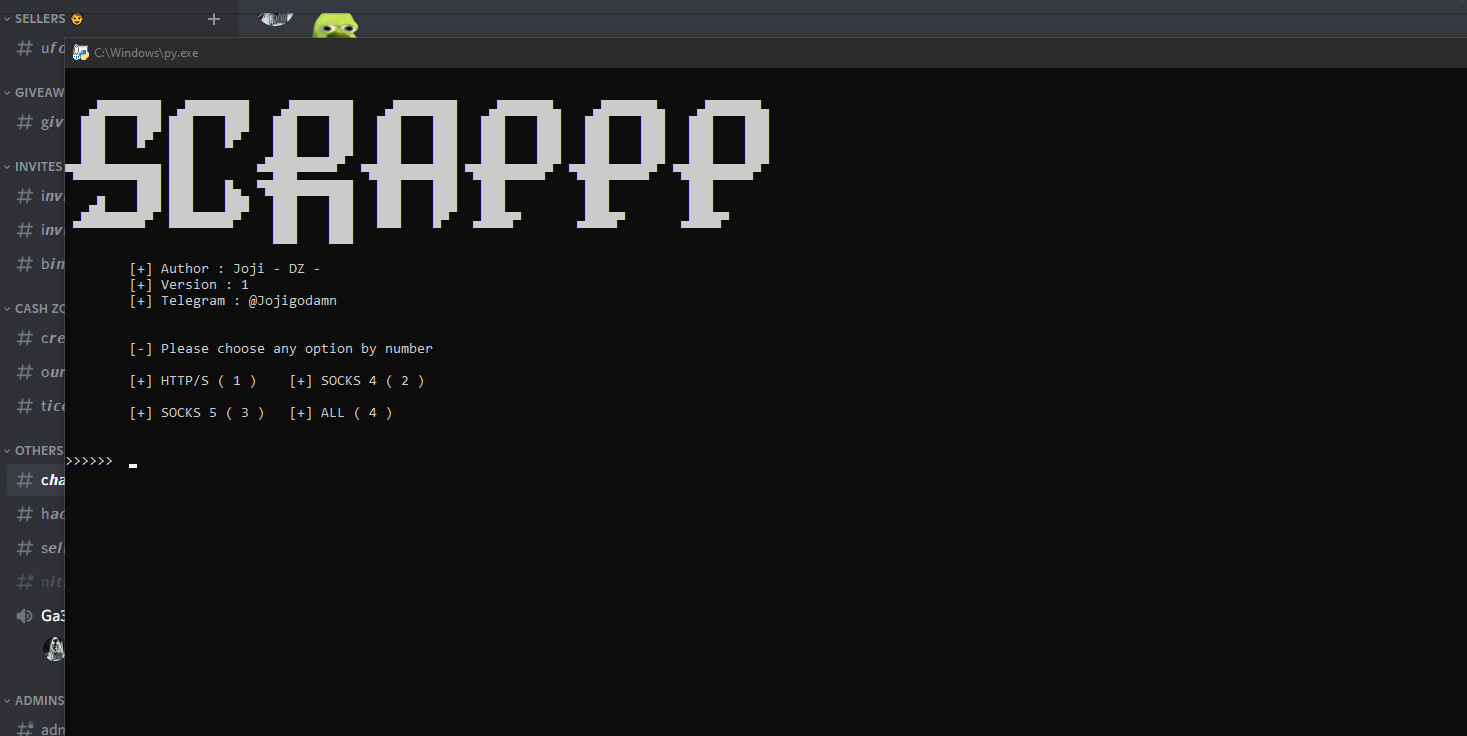
A Very simple free proxy list scraper.
Scrappp A Very simple free proxy list scraper, made in python The tool scrape proxy from diffrent sites and api's. Screenshots About the script !!! RE
 12 Oct 27, 2022
12 Oct 27, 2022
Demonstration on how to use async python to control multiple playwright browsers for web-scraping
Playwright Browser Pool This example illustrates how it's possible to use a pool of browsers to retrieve page urls in a single asynchronous process. i
 8 Oct 27, 2022
8 Oct 27, 2022

Scrap the 42 Intranet's elearning videos in a single click
42intra_scraper Scrap the 42 Intranet's elearning videos in a single click. Why you would want to use it ? Adjust speed at your convenience. (The intr
 5 Oct 27, 2022
5 Oct 27, 2022
Danbooru scraper with python
Danbooru Version: 0.0.1 License under: MIT License Dependencies Python: = 3.9.7 beautifulsoup4 cloudscraper Example of use Danbooru from danbooru imp
 2 Oct 27, 2022
2 Oct 27, 2022
河南工业大学 完美校园 自动校外打卡
HAUT-checkin 河南工业大学自动校外打卡 由于github actions存在明显延迟,建议直接使用腾讯云函数 特点 多人打卡 使用简单,仅需账号密码以及用于微信推送的uid 自动获取上一次打卡信息用于打卡 向所有成员微信单独推送打卡状态 完美校园服务器繁忙时造成打卡失败会自动重新打卡
 36 Oct 27, 2022
36 Oct 27, 2022

This script is intended to crawl license information of repositories through the GitHub API.
GithubLicenseCrawler This script is intended to crawl license information of repositories through the GitHub API. Taking a csv file with requirements.
 4 Oct 25, 2022
4 Oct 25, 2022
A scrapy pipeline that provides an easy way to store files and images using various folder structures.
scrapy-folder-tree This is a scrapy pipeline that provides an easy way to store files and images using various folder structures. Supported folder str
 7 Oct 23, 2022
7 Oct 23, 2022
Basic-html-scraper - A complete how to of web scraping with Python for beginners
basic-html-scraper Code from YT Video This video includes a complete how to of w
 12 Oct 22, 2022
12 Oct 22, 2022
An automated, headless YouTube Watcher and Scraper
Searches YouTube, queries recommended videos and watches them. All fully automated and anonymised through the Tor network. The project consists of two independently usable components, the YouTube automation written in Python and the dockerized Tor Browser.
 44 Oct 18, 2022
44 Oct 18, 2022
Instagram_scrapper - This project allow you to scrape the list of followers, following or both from a public Instagram account, and create a csv or excel file easily.
Instagram_scrapper This project allow you to scrape the list of followers, following or both from a public Instagram account, and create a csv or exce
 5 Oct 17, 2022
5 Oct 17, 2022
Raspi-scraper is a configurable python webscraper that checks raspberry pi stocks from verified sellers
Raspi-scraper is a configurable python webscraper that checks raspberry pi stocks from verified sellers.
 13 Oct 15, 2022
13 Oct 15, 2022
Bulk download tool for the MyMedia platform
MyMedia Bulk Content Downloader This is a bulk download tool for the MyMedia platform. USE ONLY WHERE ALLOWED BY THE COPYRIGHT OWNER. NOT AFFILIATED W
 3 Oct 14, 2022
3 Oct 14, 2022

Web scrapping tool written in python3, using regex, to get CVEs, Source and URLs.
searchcve Web scrapping tool written in python3, using regex, to get CVEs, Source and URLs. Generates a CSV file in the current directory. Uses the NI
 32 Oct 10, 2022
32 Oct 10, 2022

原神爬虫 抓取原神界面圣遗物信息
原神圣遗物半自动爬虫 说明 直接抓取原神界面中的圣遗物数据 目前只适配了背包页面的抓取 准确率:97.5%(普通通用接口,对 40 件随机圣遗物识别,统计完全正确的数量为 39) 准确率:100%(4k 屏幕,普通通用接口,对 110 件圣遗物识别,统计完全正确的数量为 110) 不排除还有小错误的
 28 Oct 10, 2022
28 Oct 10, 2022
Anonymously scrapes onlinesim.ru for new usable phone numbers.
phone-scraper Anonymously scrapes onlinesim.ru for new usable phone numbers. Usage Clone the repository $ git clone https://github.com/thomasgruebl/ph
 16 Oct 8, 2022
16 Oct 8, 2022
Binance harvester - A Python 3 script to harvest data from the Binance socket stream and calculate popular TA indicators and produce lists of top trending coins
Binance harvester - A Python 3 script to harvest data from the Binance socket stream and calculate popular TA indicators and produce lists of top trending coins
 68 Oct 8, 2022
68 Oct 8, 2022
Crawler do site Fundamentus.com com o uso do framework scrapy, tanto da aba detalhada como a de resumo.
Crawler do site Fundamentus.com com o uso do framework scrapy, tanto da aba detalhada como a de resumo. (Todas as infomações)
 3 Oct 4, 2022
3 Oct 4, 2022
Script used to download data for stocks.
This script is useful for downloading stock market data for a wide range of companies specified by their respective tickers. The script reads in the d
 71 Oct 4, 2022
71 Oct 4, 2022
This tool crawls a list of websites and download all PDF and office documents
This tool crawls a list of websites and download all PDF and office documents. Then it analyses the PDF documents and tries to detect accessibility issues.
 7 Sep 30, 2022
7 Sep 30, 2022

Web Scraping OLX with Python and Bsoup.
webScrap WebScraping first step. Authors: Paulo, Claudio M. First steps in Web Scraping. Project carried out for training in Web Scrapping. The export
 5 Sep 25, 2022
5 Sep 25, 2022
New World Market Scraper
Bean Seller A New Worlds market scraper. Deployment This must be installed on Windows as it uses the Windows api to do its stuff Install Prerequisites
 4 Sep 21, 2022
4 Sep 21, 2022
Python scraper to check for earlier appointments in Clalit Health Services
clalit-appt-checker Python scraper to check for earlier appointments in Clalit Health Services Some background If you ever needed to schedule a doctor
 16 Sep 17, 2022
16 Sep 17, 2022

自动完成每日体温上报(Github Actions)
体温上报助手 简介 每天 10:30 GMT+8 自动完成体温上报,如想修改定时运行的时间,可修改 .github/workflows/SduHealthReport.yml 中 schedule 属性。 如果当日有异常,请手动在小程序端/PC 端填写!
 23 Sep 15, 2022
23 Sep 15, 2022
Introduction to WebScraping Workshop - Semcomp 24 Beta
Extrair informações da internet de forma automatizada. Existem diversas maneiras de fazer isso, nesse tutorial vamos ver algumas delas, por meio de bibliotecas de python.
 19 Sep 11, 2022
19 Sep 11, 2022

Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data.
Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data. Then used Yahoo Finance to get the related stock data and displayed them in the form of charts.
 3 Sep 9, 2022
3 Sep 9, 2022
An arxiv spider
An Arxiv Spider 做为一个cser,杰出男孩深知内核对连接到计算机上的硬件设备进行管理的高效方式是中断而不是轮询。每当小伙伴发来一篇刚挂在arxiv上的”热乎“好文章时,杰出男孩都会感叹道:”师兄这是每天都挂在arxiv上呀,跑的好快~“。于是杰出男孩找了找 github,借鉴了一下其
 11 Sep 9, 2022
11 Sep 9, 2022

A module for CME that spiders hashes across the domain with a given hash.
hash_spider A module for CME that spiders hashes across the domain with a given hash. Installation Simply copy hash_spider.py to your CME module folde
 37 Sep 8, 2022
37 Sep 8, 2022
茅台抢购最新优化版本,茅台秒杀,优化了抢购协程队列
茅台抢购最新优化版本,茅台秒杀,优化了抢购协程队列
 33 Sep 3, 2022
33 Sep 3, 2022

crypto currency scraping
SCRYPTO What ? Crypto currencies scraping (At the moment, only bitcoin and ethereum crypto currencies are supported) How ? A python script is running
 15 Sep 1, 2022
15 Sep 1, 2022
Python script for crawling ResearchGate.net papers✨⭐️📎
ResearchGate Crawler Python script for crawling ResearchGate.net papers About the script This code start crawling process by urls in start.txt and giv
 4 Aug 30, 2022
4 Aug 30, 2022
让中国用户使用git从github下载的速度提高1000倍!
序言 github上有很多好项目,但是国内用户连github却非常的慢.每次都要用插件或者其他工具来解决. 这次自己做一个小工具,输入github原地址后,就可以自动替换为代理地址,方便大家更快速的下载. 安装 pip install cit 主要功能与用法 主要功能 change 将目标地址转换为
 35 Aug 29, 2022
35 Aug 29, 2022