Filter By
355 Repositories
Python Web Crawling
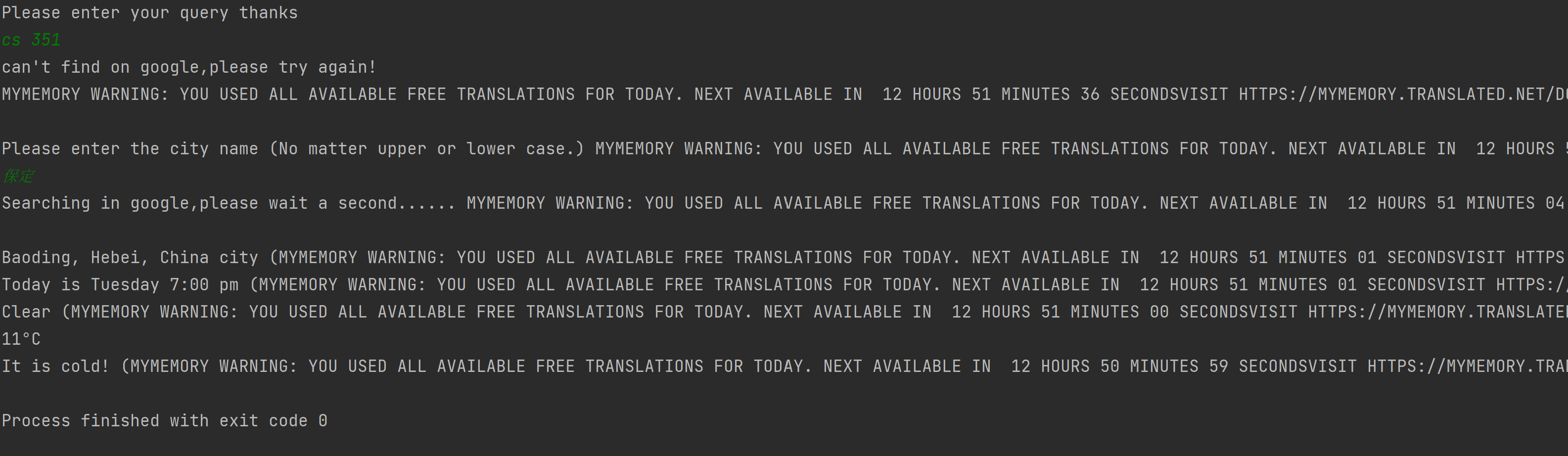
Searching info from Google using Python Scrapy
Python-Search-Engine-Scrapy || Python-爬虫-索引/利用爬虫获取谷歌信息**/ Searching info from Google using Python Scrapy /* 利用 PYTHON 爬虫获取天气信息,以及城市信息和资料**/ translatio
 1 Jan 6, 2022
1 Jan 6, 2022
A simple Discord scraper for discord bots
A simple Discord scraper for discord bots. That includes sending an guild members ids to an file, Mass inviter for joining servers your bot is in and Fetching all the servers of the bot (w/MemberCount) to the console.
 1 Jan 6, 2022
1 Jan 6, 2022
Bigdata - This Scrapy project uses Redis and Kafka to create a distributed on demand scraping cluster
Scrapy Cluster This Scrapy project uses Redis and Kafka to create a distributed
 0 Jan 6, 2022
0 Jan 6, 2022
Open Crawl Vietnamese Text
Open Crawl Vietnamese Text This repo contains crawled Vietnamese text from multiple sources. This list of a topic-centric public data sources in high
 4 Jan 5, 2022
4 Jan 5, 2022
Web-scraping - A bot using Python with BeautifulSoup that scraps IRS website by form number and returns the results as json
Web-scraping - A bot using Python with BeautifulSoup that scraps IRS website (prior form publication) by form number and returns the results as json. It provides the option to download pdfs over a range of years.
 1 Jan 4, 2022
1 Jan 4, 2022
Scraping Thailand COVID-19 data from the DDC's tableau dashboard
Scraping COVID-19 data from DDC Dashboard Scraping Thailand COVID-19 data from the DDC's tableau dashboard. Data is updated at 07:30 and 08:00 daily.
 5 Jan 4, 2022
5 Jan 4, 2022
Python Web Scrapper Project
Web Scrapper Projeto desenvolvido em python, sobre tudo com Selenium, BeautifulSoup e Pandas é um web scrapper que puxa uma tabela com as principais e
 2 Jan 4, 2022
2 Jan 4, 2022
CreamySoup - a helper script for automated SourceMod plugin updates management.
CreamySoup/"Creamy SourceMod Updater" (or just soup for short), a helper script for automated SourceMod plugin updates management.
 3 Jan 3, 2022
3 Jan 3, 2022
Poolbooru gelscraper - a simple python script for scraping images off gelbooru pools.
poolbooru_gelscraper a simple python script for scraping images off gelbooru pools. modules required:requests_html, and os by default saves files with
 1 Jan 2, 2022
1 Jan 2, 2022
Newsscraper - A simple Python 3 module to get crypto or news articles and their content from various RSS feeds.
NewsScraper A simple Python 3 module to get crypto or news articles and their content from various RSS feeds. 🔧 Installation Clone the repo locally.
 3 Jan 2, 2022
3 Jan 2, 2022
Lovely Scrapper
Lovely Scrapper
 2 Jan 1, 2022
2 Jan 1, 2022

A tool can scrape product in aliexpress: Title, Price, and URL Product.
Scrape-Product-Aliexpress A tool can scrape product in aliexpress: Title, Price, and URL Product. Usage: 1. Install Python 3.8 3.9 padahal halaman ins
 1 Dec 30, 2021
1 Dec 30, 2021
Rottentomatoes, Goodreads and IMDB sites crawler. Semantic Web final project.
Crawler Rottentomatoes, Goodreads and IMDB sites crawler. Crawler written by beautifulsoup, selenium and lxml to gather books and films information an
 1 Dec 30, 2021
1 Dec 30, 2021
Get-web-images - A python code that get images from any site
image retrieval This is a python code to retrieve an image from the internet, a
 1 Dec 30, 2021
1 Dec 30, 2021
Minecraft Item Scraper
Minecraft Item Scraper To run, first ensure you have the BeautifulSoup module: pip install bs4 Then run, python minecraft_items.py folder-to-save-ima
 1 Dec 29, 2021
1 Dec 29, 2021
Use Flask API to wrap Facebook data. Grab the wapper of Facebook public pages without an API key.
Facebook Scraper Use Flask API to wrap Facebook data. Grab the wapper of Facebook public pages without an API key. (Currently working 2021) Setup Befo
 2 Dec 27, 2021
2 Dec 27, 2021
Amazon scraper using scrapy, a python framework for crawling websites.
#Amazon-web-scraper This is a python program, which use scrapy python framework to crawl all pages of the product and scrap products data. This progra
 1 Dec 26, 2021
1 Dec 26, 2021
Scrape plants scientific name information from Agroforestry Species Switchboard 2.0.
Agroforestry Species Switchboard 2.0 Scraper Scrape plants scientific name information from Species Switchboard 2.0. Requirements python = 3.10 (you
 2 Dec 23, 2021
2 Dec 23, 2021
Scrapes proxies and saves them to a text file
Proxy Scraper Scrapes proxies from https://proxyscrape.com and saves them to a file. Also has a customizable theme system Made by nell and Lamp
 2 Dec 22, 2021
2 Dec 22, 2021
API which uses discord to scrape NameMC searches/droptime/dropping status of minecraft names
NameMC Scrape API This is an api to scrape NameMC using message previews generated by discord. NameMC makes it a pain to scrape their website, but som
 2 Dec 22, 2021
2 Dec 22, 2021
This is a web crawler that works on employ email data by gmane.org and visualizes it in different ways.
crawler_to_visual_gmane Analyzing an EMAIL Archive from gmane and vizualizing the data using the D3 JavaScript library. This is a set of tools that al
 1 Dec 20, 2021
1 Dec 20, 2021
A simple django-rest-framework api using web scraping
Apicell You can use this api to search in google, bing, pypi and subscene and get results Method : POST Parameter : query Example import request url =
 1 Dec 19, 2021
1 Dec 19, 2021
Python web scrapper
Website scrapper Web scrapping project in Python. Created for learning purposes. Start Install python Update configuration with websites Launch script
 1 Dec 19, 2021
1 Dec 19, 2021
A simple python script to fetch the latest covid info
covid-tracker-script A simple python script to fetch the latest covid info How it works First, get the current date in MM-DD-YYYY format. Check if the
 0 Dec 15, 2021
0 Dec 15, 2021
A simple, configurable and expandable combined shop scraper to minimize the costs of ordering several items
combined-shop-scraper A simple, configurable and expandable combined shop scraper to minimize the costs of ordering several items. Features Define an
 2 Dec 13, 2021
2 Dec 13, 2021
This is a webscraper for a specific website
This is a webscraper for a specific website. It is tuned to extract the headlines of that website. With some little adjustments the webscraper is able to extract any part of the website.
 1 Dec 13, 2021
1 Dec 13, 2021

This is a module that I had created along with my friend. It's a basic web scraping module
QuickInfo PYPI link : https://pypi.org/project/quickinfo/ This is the library that you've all been searching for, it's built for developers and allows
 2 Dec 13, 2021
2 Dec 13, 2021
Google Scholar Web Scraping
Google Scholar Web Scraping This is a python script that asks for a user to input the url for a google scholar profile, and then it writes publication
 1 Dec 12, 2021
1 Dec 12, 2021

A spider for Universal Online Judge(UOJ) system, converting problem pages to PDFs.
Universal Online Judge Spider Introduction This is a spider for Universal Online Judge (UOJ) system (https://uoj.ac/). It also works for all other Onl
 1 Dec 7, 2021
1 Dec 7, 2021
A leetcode scraper to compile all questions in leetcode free tier to text file. pdf also available.
A leetcode scraper to compile all questions in leetcode free tier to text file, pdf also available. if new questions get added, run again to get new questions.
 3 Dec 7, 2021
3 Dec 7, 2021
This project was created using Python technology and flask tools to scrape a music site
python-scrapping This project was created using Python technology and flask tools to scrape a music site You need to install the following packages to
 1 Dec 7, 2021
1 Dec 7, 2021
Get paper names from dblp.org
scraper-dblp Get paper names from dblp.org and store them in a .txt file Useful for a related literature :) Install libraries pip3 install -r requirem
 1 Dec 7, 2021
1 Dec 7, 2021
Snowflake database loading utility with Scrapy integration
Snowflake Stage Exporter Snowflake database loading utility with Scrapy integration. Meant for streaming ingestion of JSON serializable objects into S
 0 Dec 6, 2021
0 Dec 6, 2021

👁️ Tool for Data Extraction and Web Requests.
httpmapper 👁️ Project • Technologies • Installation • How it works • License Project 🚧 For educational purposes. This is a project that I developed,
 15 Dec 5, 2021
15 Dec 5, 2021

A Scrapper with python
Scrapper-en-python Scrapper des données signifie récuperer des données pour les traiter ou les analyser. En python, il y'a 2 grands moyens de scrapper
 1 Dec 5, 2021
1 Dec 5, 2021
This program scrapes information and images for movies and TV shows.
Media-WebScraper This program scrapes information and images for movies and TV shows. Summary For more information on the program, read the WebScrape_
 1 Dec 5, 2021
1 Dec 5, 2021
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
 1 Nov 30, 2021
1 Nov 30, 2021
Consulta de CPF e CNPJ na Receita Federal com Web-Scraping
Repositório contendo scripts Python que realizam a consulta de CPF e CNPJ diretamente no site da Receita Federal.
 5 Nov 29, 2021
5 Nov 29, 2021
Scraping script for stats on covid19 pandemic status in Chiba prefecture, Japan
About 千葉県の地域別の詳細感染者統計(Excelファイル) をCSVに変換し、かつ地域別の日時感染者集計値を出力するスクリプトです。 Requirement POSIX互換なシェル, e.g. GNU Bash (1) curl (1) python = 3.8 pandas = 1.1.
 1 Nov 29, 2021
1 Nov 29, 2021
A Simple Web Scraper made to Extract Download Links from Todaytvseries2.com
TDTV2-Direct Version 1.00.1 • A Simple Web Scraper made to Extract Download Links from Todaytvseries2.com :) How to Works?? install all dependancies v
 1 Nov 28, 2021
1 Nov 28, 2021
Automated Linkedin bot that will improve your visibility and increase your network.
LinkedinSpider LinkedinSpider is a small project using browser automating to increase your visibility and network of connections on Linkedin. DISCLAIM
 2 Nov 26, 2021
2 Nov 26, 2021

This is a sport analytics project that combines the knowledge of OOP and Webscraping
This is a sport analytics project that combines the knowledge of Object Oriented Programming (OOP) and Webscraping, the weekly scraping of the English Premier league table is carried out to assess the performance of each club from the beginning of the season to the end.
 1 Nov 26, 2021
1 Nov 26, 2021
AssistScraper - program for /r/nba to use to find list of all players a player assisted and how many assists each player recieved
AssistScraper - program for /r/nba to use to find list of all players a player assisted and how many assists each player recieved
 5 Nov 25, 2021
5 Nov 25, 2021
Web scraper for Zillow
Zillow-Scraper Instructions All terminal commands are highlighted. Make sure you first have python 3 installed. You can check this by running "python
 1 Nov 23, 2021
1 Nov 23, 2021
Semplice scraper realizzato in Python tramite la libreria BeautifulSoup
Semplice scraper realizzato in Python tramite la libreria BeautifulSoup
 2 Nov 22, 2021
2 Nov 22, 2021

This is a script that scrapes the longitude and latitude on food.grab.com
grab This is a script that scrapes the longitude and latitude for any restaurant in Manila on food.grab.com, location can be adjusted. Search Result p
 0 Nov 22, 2021
0 Nov 22, 2021

此脚本为 python 脚本,实现原理为利用 selenium 定位相关元素,再配合点击事件完成浏览器的自动化.
此脚本为 python 脚本,实现原理为利用 selenium 定位相关元素,再配合点击事件完成浏览器的自动化.
 5 Nov 19, 2021
5 Nov 19, 2021
Scrapes all articles and their headlines from theonion.com
The Onion Article Scraper Scrapes all articles and their headlines from the satirical news website https://www.theonion.com Also see Clickhole Article
 0 Nov 17, 2021
0 Nov 17, 2021
A simple reddit scraper to get memes (only images) from r/ProgrammerHumor.
memey A simple reddit scraper to get memes (only images) from r/ProgrammerHumor. Note Only works if you have firefox installed (yet). Instructions foo
 2 Nov 16, 2021
2 Nov 16, 2021
simple http & https proxy scraper and checker
simple http & https proxy scraper and checker
 11 Nov 15, 2021
11 Nov 15, 2021
A Pixiv web crawler module
Pixiv-spider A Pixiv spider module WARNING It's an unfinished work, browsing the code carefully before using it. Features 0004 - Readme.md updated, co
 1 Nov 14, 2021
1 Nov 14, 2021
A Python Covid-19 cases tracker that scrapes data off the web and presents the number of Cases, Recovered Cases, and Deaths that occurred because of the pandemic.
A Python Covid-19 cases tracker that scrapes data off the web and presents the number of Cases, Recovered Cases, and Deaths that occurred because of the pandemic.
 1 Nov 13, 2021
1 Nov 13, 2021
Here I provide the source code for doing web scraping using the python library, it is Selenium.
Here I provide the source code for doing web scraping using the python library, it is Selenium.
 1 Nov 13, 2021
1 Nov 13, 2021
Web-Scrapper using Python and Flask
Web-Scrapper "[초급]Python으로 웹 스크래퍼 만들기" 코스 -NomadCoders 기초적인 Python 문법강의부터 시작하여 웹사이트의 html파일에서 원하는 내용을 Scrapping해서 출력, csv 파일로 저장, flask를 이용한 간단한 웹페이지
 1 Nov 10, 2021
1 Nov 10, 2021