BERTGEN
This repository is the implementation of the paper "BERTGEN: Multi-task Generation through BERT" (https://arxiv.org/abs/2106.03484). The codebase is based on the VL-BERT official repository (https://github.com/jackroos/VL-BERT) presented in the paper VL-BERT: Pre-training of Generic Visual-Linguistic Representations.
Introduction
BERTGEN extends the VL-BERT model by making it multilingual, inheriting multilingual pretraining from multilingual BERT (https://github.com/google-research/bert/blob/master/multilingual.md. The BERTGEN model produces multilingual, multimodal embeddings usede for visual-linguistic generation tasks.
BERTGEN takes advantage of large-scale training of VL-BERT and M-BERT but is also further trained, in a generative setting as described in the paper.

Figure 1: Overview of the BERTGEN architecture
Special thanks to VL-BERT, PyTorch and its 3rd-party libraries and BERT. This codebase also uses the following features inherited from VL-BERT:
- Distributed Training
- Various Optimizers and Learning Rate Schedulers
- Gradient Accumulation
- Monitoring the Training Using TensorboardX
Prepare
Environment
- Ubuntu 16.04, CUDA 9.0, GCC 4.9.4
- Python 3.6.x
# We recommend you to use Anaconda/Miniconda to create a conda environment conda create -n bertgen python=3.6 pip conda activate bertgen - PyTorch 1.0.0 or 1.1.0
conda install pytorch=1.1.0 cudatoolkit=9.0 -c pytorch
- Apex (optional, for speed-up and fp16 training)
git clone https://github.com/jackroos/apex cd ./apex pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./
- Other requirements:
pip install Cython pip install -r requirements.txt
- Compile
./scripts/init.sh
Data
The datasets used for training and evaluating BERTGEN can be found in this zenodo link. After checking out the code repository, simply extract the .tar.gz file downloaded from zenodo to <github checkout folder>/data. A README file is included in the download with more information on the structure of the datasets.
Pre-trained Models
See PREPARE_PRETRAINED_MODELS.md.
Training
Distributed Training on Single-Machine
./scripts/dist_run_single.sh <num_gpus> <task>/train_end2end.py <path_to_cfg> <dir_to_store_checkpoint>
<num_gpus>: number of gpus to use.<task>: LanguageGeneration.<path_to_cfg>: config yaml file under./cfgs/<task>.<dir_to_store_checkpoint>: root directory to store checkpoints.
Following is a more concrete example:
./scripts/dist_run_single.sh 4 LanguageGeneration/train_end2end.py ./cfgs/multitask_training/base_prec_multitask_train_global.yaml ./checkpoints
Distributed Training on Multi-Machine
For example, on 2 machines (A and B), each with 4 GPUs,
run following command on machine A:
./scripts/dist_run_multi.sh 2 0 <ip_addr_of_A> 4 <task>/train_end2end.py <path_to_cfg> <dir_to_store_checkpoint>
run following command on machine B:
./scripts/dist_run_multi.sh 2 1 <ip_addr_of_A> 4 <task>/train_end2end.py <path_to_cfg> <dir_to_store_checkpoint>
- Training:
- multitask training: "MODULE: BERTGENMultitaskTraining"
Non-Distributed Training
./scripts/nondist_run.sh <task>/train_end2end.py <path_to_cfg> <dir_to_store_checkpoint>
Note:
-
In yaml files under
./cfgs, we set batch size for GPUs with at least 32G memory, you may need to adapt the batch size and gradient accumulation steps according to your actual case, e.g., if you decrease the batch size, you should also increase the gradient accumulation steps accordingly to keep 'actual' batch size for SGD unchanged. Note that for the multitask training of 13 tasks the batch size is set to the minimum of 1 sample from each dataset per task. You would have to reduce the number of datasets to fit on a GPU with smaller memory than 32G. -
For efficiency, we recommend you to use distributed training even on single-machine.
Evaluation
Language Generation tasks (MT, MMT, IC)
- Generate prediction results on selected test dataset (specified in yaml). The task is also specified in the .yaml file (MT, MMT, IC):
python LanguageGeneration/test.py \ --cfg <cfg_of_downstream_task> \ --ckpt <checkpoint_of_pretrained_model> \ --gpus <indexes_of_gpus_to_use> \ --result-path <dir_to_save_result> --result-name <result_file_name>
- Inference:
- Machine Translation: "MODULE: BERTGENGenerateMMT"
- Multimodal Machine Translation: "MODULE: BERTGENGenerateMT"
- Image Captioning: "MODULE: BERTGENGenerateImageOnly"
Evaluation Metrics
- After generating results, the generated text file can be compared with the ground truth in tokenised format. We have used the nmtpytoch tool for generating these metrics. An example is shown below
nmtpy-coco-metrics -l de "./checkpoints/generated/ENDEIMG.txt" -r "./data/ground_truths/ENDEIMG.txt.tok
Acknowledgements
Many thanks to following codebases that have been essential while building this codebase:
 16 Feb 24, 2022
16 Feb 24, 2022
 14 Aug 24, 2022
14 Aug 24, 2022

 540 Dec 30, 2022
540 Dec 30, 2022
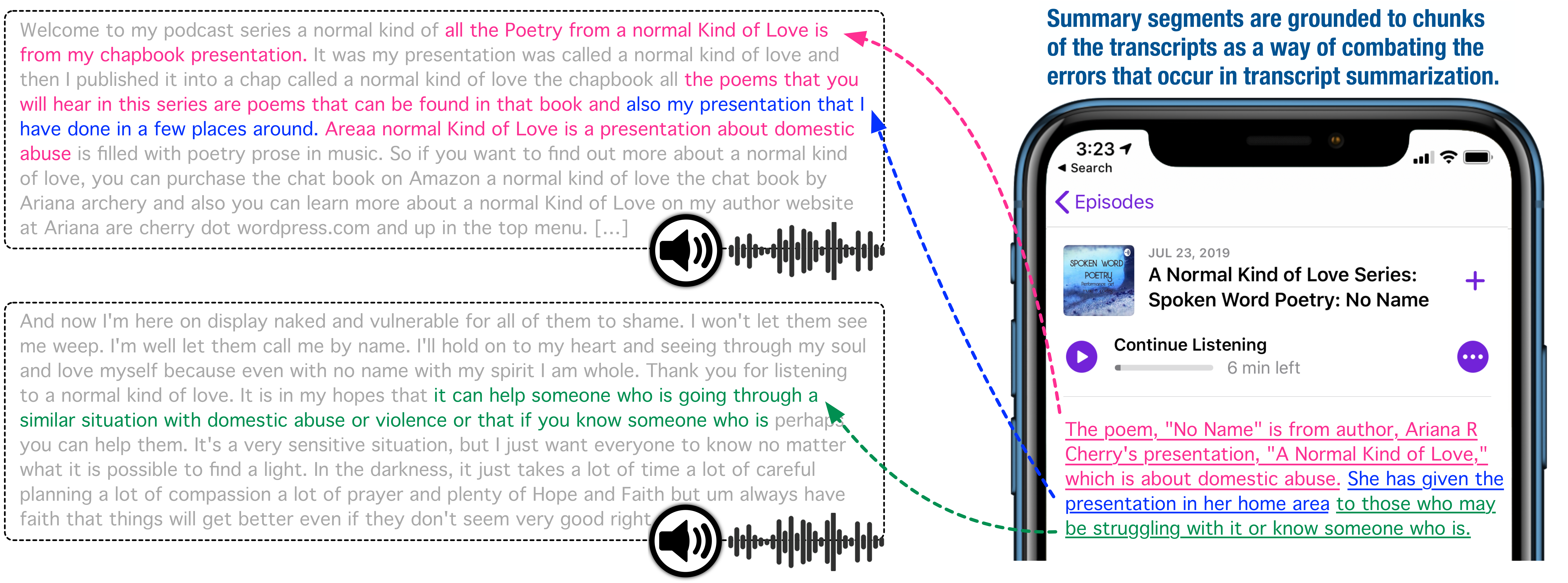
 10 Jul 1, 2022
10 Jul 1, 2022
 14 Jan 3, 2023
14 Jan 3, 2023
 29 Oct 16, 2022
29 Oct 16, 2022
 914 Jan 7, 2023
914 Jan 7, 2023
 78 Dec 12, 2022
78 Dec 12, 2022
 6 Apr 29, 2022
6 Apr 29, 2022

 20 Dec 12, 2022
20 Dec 12, 2022
 189 Jan 2, 2023
189 Jan 2, 2023
 90 Dec 27, 2022
90 Dec 27, 2022
 46 Dec 15, 2022
46 Dec 15, 2022
 43 Dec 28, 2022
43 Dec 28, 2022
 478 Dec 25, 2022
478 Dec 25, 2022
 5 Sep 13, 2022
5 Sep 13, 2022
 49 Dec 26, 2022
49 Dec 26, 2022