KPACUBO
KPACUBO is a set Jupyter notebooks focused on the best practices in both software development and data science, namely,
- code reuse,
- explicit data gathering procedures,
- efficient data management,
- clear analysis validation criteria.
SETUP
- Create kpacubo environment:
conda env create -f environment.yml
- Add kpacubo environment to Jupyter:
python -m ipykernel install --user --name=kpacubo
ENVIRONMENT EXPORT
Windows: conda env export --no-builds | findstr -v "prefix" > environment.yml
Linux: conda env export --no-builds | grep -v "prefix" > environment.yml

 3 Oct 3, 2022
3 Oct 3, 2022
 2 Dec 12, 2021
2 Dec 12, 2021
 1 Dec 27, 2021
1 Dec 27, 2021
 11 Nov 24, 2022
11 Nov 24, 2022
 3 Mar 3, 2022
3 Mar 3, 2022
 102 Nov 10, 2022
102 Nov 10, 2022
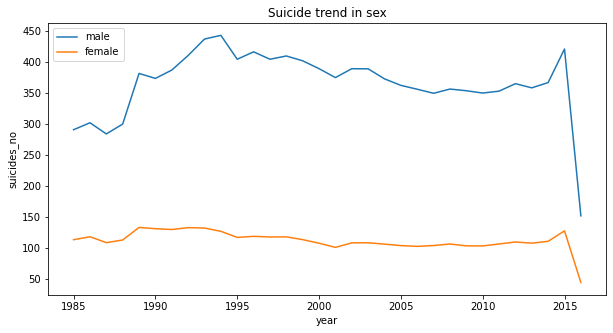
 1 Sep 3, 2022
1 Sep 3, 2022
 94 Jan 4, 2023
94 Jan 4, 2023
 24 Nov 29, 2022
24 Nov 29, 2022

 898 Jan 9, 2023
898 Jan 9, 2023
 97 Dec 8, 2022
97 Dec 8, 2022
 2 Nov 20, 2021
2 Nov 20, 2021
 1 Jan 19, 2022
1 Jan 19, 2022
 359 Dec 22, 2022
359 Dec 22, 2022
 1 Jan 16, 2022
1 Jan 16, 2022
 27 Nov 1, 2022
27 Nov 1, 2022
 791 Jan 4, 2023
791 Jan 4, 2023
 40 Dec 12, 2022
40 Dec 12, 2022
 184 Dec 27, 2022
184 Dec 27, 2022