Semi-Supervised Semantic Segmentation with Cross-Consistency Training (CCT)
Paper, Project Page
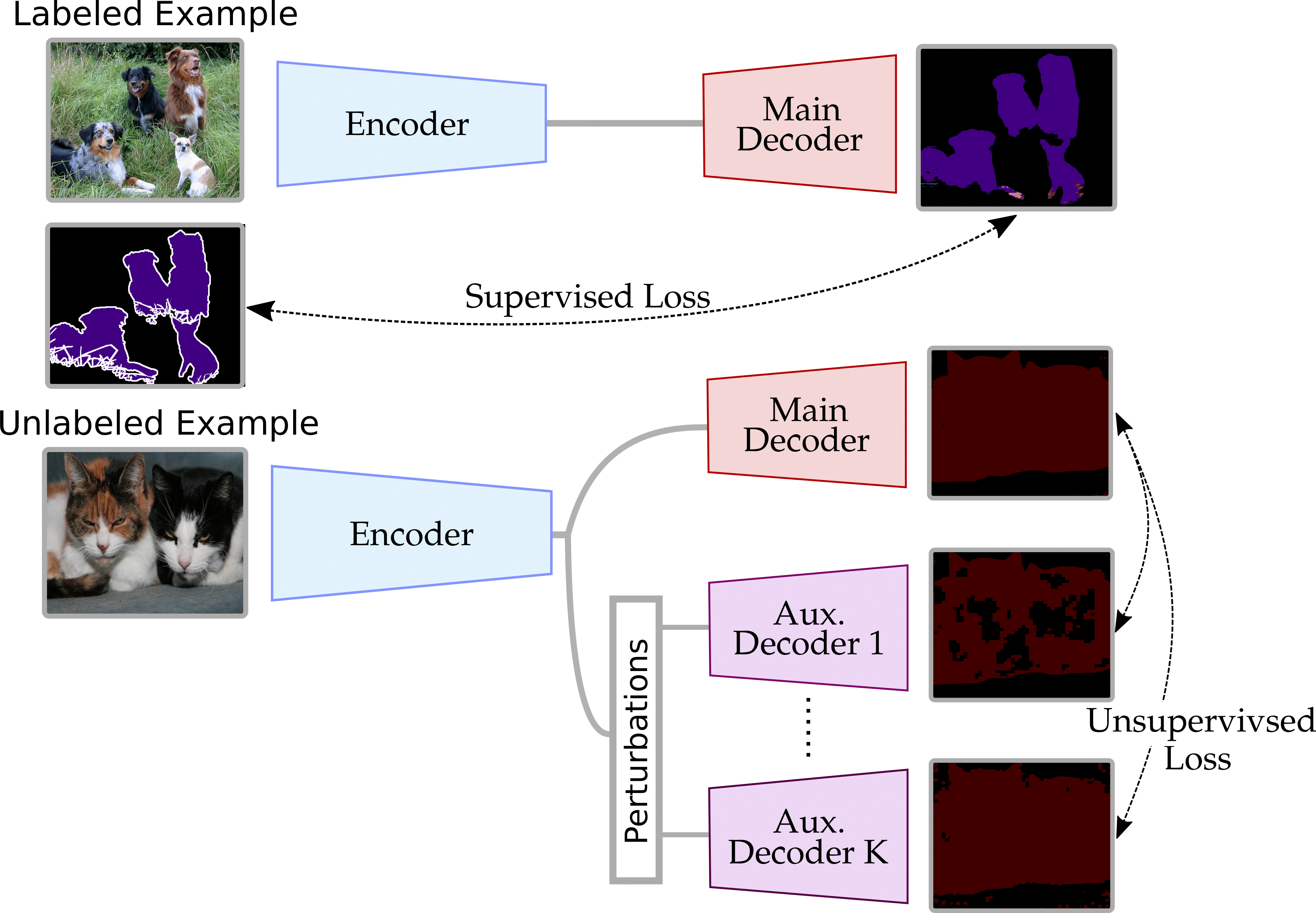
This repo contains the official implementation of CVPR 2020 paper: Semi-Supervised Semantic Segmentation with Cross-Consistecy Training, which adapts the traditional consistency training framework of semi-supervised learning for semantic segmentation, with an extension to weak-supervised learning and learning on multiple domains.
Highlights
(1) Consistency Training for semantic segmentation.
We observe that for semantic segmentation, due to the dense nature of the task, the cluster assumption is more easily enforced over the hidden representations rather than the inputs.
(2) Cross-Consistecy Training.
We propose CCT (Cross-Consistecy Training) for semi-supervised semantic segmentation, where we define a number of novel perturbations, and show the effectiveness of enforcing consistency over the encoder's outputs rather than the inputs.
(3) Using weak-labels and pixel-level labels from multiple domains.
The proposed method is quite simple and flexible, and can easily be extended to use image-level labels and pixel-level labels from multiple-domains.
Requirements
This repo was tested with Ubuntu 18.04.3 LTS, Python 3.7, PyTorch 1.1.0, and CUDA 10.0. But it should be runnable with recent PyTorch versions >=1.1.0.
The required packages are pytorch and torchvision, together with PIL and opencv for data-preprocessing and tqdm for showing the training progress. With some additional modules like dominate to save the results in the form of HTML files. To setup the necessary modules, simply run:
pip install -r requirements.txt
Dataset
In this repo, we use Pascal VOC, to obtain it, first download the original dataset, after extracting the files we'll end up with VOCtrainval_11-May-2012/VOCdevkit/VOC2012 containing the image sets, the XML annotation for both object detection and segmentation, and JPEG images.
The second step is to augment the dataset using the additionnal annotations provided by Semantic Contours from Inverse Detectors. Download the rest of the annotations SegmentationClassAug and add them to the path VOCtrainval_11-May-2012/VOCdevkit/VOC2012, now we're set, for training use the path to VOCtrainval_11-May-2012.
Training
To train a model, first download PASCAL VOC as detailed above, then set data_dir to the dataset path in the config file in configs/config.json and set the rest of the parameters, like the number of GPUs, cope size, data augmentation ... etc ,you can also change CCT hyperparameters if you wish, more details below. Then simply run:
python train.py --config configs/config.json
The log files and the .pth checkpoints will be saved in saved\EXP_NAME, to monitor the training using tensorboard, please run:
tensorboard --logdir saved
To resume training using a saved .pth model:
python train.py --config configs/config.json --resume saved/CCT/checkpoint.pth
Results: The results will be saved in saved as an html file, containing the validation results, and the name it will take is experim_name specified in configs/config.json.
Pseudo-labels
If you want to use image level labels to train the auxiliary labels as explained in section 3.3 of the paper. First generate the pseudo-labels using the code in pseudo_labels:
cd pseudo_labels
python run.py --voc12_root DATA_PATH
DATA_PATH must point to the folder containing JPEGImages in Pascal Voc dataset. The results will be saved in pseudo_labels/result/pseudo_labels as PNG files, the flag use_weak_labels needs to be set to True in the config file, and then we can train the model as detailed above.
Inference
For inference, we need a pretrained model, the jpg images we'd like to segment and the config used in training (to load the correct model and other parameters),
python inference.py --config config.json --model best_model.pth --images images_folder
The predictions will be saved as .png images in outputs\ is used, for Pacal VOC the default palette is:

Here are the flags available for inference:
--images Folder containing the jpg images to segment.
--model Path to the trained pth model.
--config The config file used for training the model.
Pre-trained models
Pre-trained models can be downloaded here.
Citation
✏️
📄
If you find this repo useful for your research, please consider citing the paper as follows:
@InProceedings{Ouali_2020_CVPR,
author = {Ouali, Yassine and Hudelot, Celine and Tami, Myriam},
title = {Semi-Supervised Semantic Segmentation With Cross-Consistency Training},
booktitle = {The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2020}
}
For any questions, please contact Yassine Ouali.
Config file details
⚙️
Bellow we detail the CCT parameters that can be controlled in the config file configs/config.json, the rest of the parameters are self-explanatory.
{
"name": "CCT",
"experim_name": "CCT", // The name the results will take (html and the folder in /saved)
"n_gpu": 1, // Number of GPUs
"n_labeled_examples": 1000, // Number of labeled examples (choices are 60, 100, 200,
// 300, 500, 800, 1000, 1464, and the splits are in dataloaders/voc_splits)
"diff_lrs": true,
"ramp_up": 0.1, // The unsupervised loss will be slowly scaled up in the first 10% of Training time
"unsupervised_w": 30, // Weighting of the unsupervised loss
"ignore_index": 255,
"lr_scheduler": "Poly",
"use_weak_labels": false, // If the pseudo-labels were generated, we can use them to train the aux. decoders
"weakly_loss_w": 0.4, // Weighting of the weakly-supervised loss
"pretrained": true,
"model":{
"supervised": true, // Supervised setting (training only on the labeled examples)
"semi": false, // Semi-supervised setting
"supervised_w": 1, // Weighting of the supervised loss
"sup_loss": "CE", // supervised loss, choices are CE and ab-CE = ["CE", "ABCE"]
"un_loss": "MSE", // unsupervised loss, choices are CE and KL-divergence = ["MSE", "KL"]
"softmax_temp": 1,
"aux_constraint": false, // Pair-wise loss (sup. mat.)
"aux_constraint_w": 1,
"confidence_masking": false, // Confidence masking (sup. mat.)
"confidence_th": 0.5,
"drop": 6, // Number of DropOut decoders
"drop_rate": 0.5, // Dropout probability
"spatial": true,
"cutout": 6, // Number of G-Cutout decoders
"erase": 0.4, // We drop 40% of the area
"vat": 2, // Number of I-VAT decoders
"xi": 1e-6, // VAT parameters
"eps": 2.0,
"context_masking": 2, // Number of Con-Msk decoders
"object_masking": 2, // Number of Obj-Msk decoders
"feature_drop": 6, // Number of F-Drop decoders
"feature_noise": 6, // Number of F-Noise decoders
"uniform_range": 0.3 // The range of the noise
},
Acknowledgements
- Pseudo-labels generation is based on Jiwoon Ahn's implementation irn.
- Code structure was based on Pytorch-Template
- ResNet backbone was downloaded from torchcv

 I ran multiple tests, using semi and weakly supervised settings, the results are unpredictable and often show 0.0 for the object classes. Only the background has good results.
Is there something I need to adjust in the code?
I ran multiple tests, using semi and weakly supervised settings, the results are unpredictable and often show 0.0 for the object classes. Only the background has good results.
Is there something I need to adjust in the code?


 Do you have any idea what causes this and how to avoid it?
Do you have any idea what causes this and how to avoid it?






 25 Nov 9, 2022
25 Nov 9, 2022
 387 Jan 8, 2023
387 Jan 8, 2023
 147 Jan 3, 2023
147 Jan 3, 2023
 132 Dec 21, 2022
132 Dec 21, 2022
 125 Jan 3, 2023
125 Jan 3, 2023
 110 Dec 7, 2022
110 Dec 7, 2022
 45 Dec 12, 2022
45 Dec 12, 2022
 268 Dec 24, 2022
268 Dec 24, 2022
 132 Jan 3, 2023
132 Jan 3, 2023
 106 Jan 3, 2023
106 Jan 3, 2023
 337 Dec 15, 2022
337 Dec 15, 2022
 7 Feb 10, 2022
7 Feb 10, 2022
 11 Nov 3, 2022
11 Nov 3, 2022
 32 Sep 21, 2022
32 Sep 21, 2022
 44 Dec 12, 2022
44 Dec 12, 2022
 49 Jan 2, 2023
49 Jan 2, 2023
 2 Dec 17, 2021
2 Dec 17, 2021
 5 Dec 10, 2022
5 Dec 10, 2022
 42 Dec 9, 2022
42 Dec 9, 2022