1080 Repositories
Python Computer-Vision Libraries

Exploring Image Deblurring via Blur Kernel Space (CVPR'21)
Exploring Image Deblurring via Encoded Blur Kernel Space About the project We introduce a method to encode the blur operators of an arbitrary dataset
 118 Dec 19, 2022
118 Dec 19, 2022

Official implementation of the paper Vision Transformer with Progressive Sampling, ICCV 2021.
Vision Transformer with Progressive Sampling This is the official implementation of the paper Vision Transformer with Progressive Sampling, ICCV 2021.
 123 Jan 1, 2023
123 Jan 1, 2023

Code for generating a single image pretraining dataset
Single Image Pretraining of Visual Representations As shown in the paper A critical analysis of self-supervision, or what we can learn from a single i
 12 Dec 19, 2022
12 Dec 19, 2022

Implementation for our ICCV2021 paper: Internal Video Inpainting by Implicit Long-range Propagation
Implicit Internal Video Inpainting Implementation for our ICCV2021 paper: Internal Video Inpainting by Implicit Long-range Propagation paper | project
 202 Dec 30, 2022
202 Dec 30, 2022
Video Contrastive Learning with Global Context
Video Contrastive Learning with Global Context (VCLR) This is the official PyTorch implementation of our VCLR paper. Install dependencies environments
 143 Dec 26, 2022
143 Dec 26, 2022
Scenic: A Jax Library for Computer Vision and Beyond
Scenic Scenic is a codebase with a focus on research around attention-based models for computer vision. Scenic has been successfully used to develop c
 1.6k Dec 27, 2022
1.6k Dec 27, 2022

code for our ICCV 2021 paper "DeepCAD: A Deep Generative Network for Computer-Aided Design Models"
DeepCAD This repository provides source code for our paper: DeepCAD: A Deep Generative Network for Computer-Aided Design Models Rundi Wu, Chang Xiao,
 85 Dec 31, 2022
85 Dec 31, 2022

FPGA: Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification
FPGA & FreeNet Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification by Zhuo Zheng, Yanfei Zhong, Ailong M
 92 Jan 3, 2023
92 Jan 3, 2023

Code for our CVPR 2021 Paper "Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes".
Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes (CVPR 2021) Project page | Paper | Colab | Colab for Drawing App Rethinking Style
 153 Jan 4, 2023
153 Jan 4, 2023

Open-World Entity Segmentation
Open-World Entity Segmentation Project Website Lu Qi*, Jason Kuen*, Yi Wang, Jiuxiang Gu, Hengshuang Zhao, Zhe Lin, Philip Torr, Jiaya Jia This projec
 410 Jan 3, 2023
410 Jan 3, 2023
TF2 implementation of knowledge distillation using the "function matching" hypothesis from the paper Knowledge distillation: A good teacher is patient and consistent by Beyer et al.
FunMatch-Distillation TF2 implementation of knowledge distillation using the "function matching" hypothesis from the paper Knowledge distillation: A g
 67 Dec 20, 2022
67 Dec 20, 2022

The code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention.
CrossFormer This repository is the code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention. Introduction Existin
 238 Jan 6, 2023
238 Jan 6, 2023

meProp: Sparsified Back Propagation for Accelerated Deep Learning
meProp The codes were used for the paper meProp: Sparsified Back Propagation for Accelerated Deep Learning with Reduced Overfitting (ICML 2017) [pdf]
 107 Nov 18, 2022
107 Nov 18, 2022

Image Deblurring using Generative Adversarial Networks
DeblurGAN arXiv Paper Version Pytorch implementation of the paper DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. Our netwo
 2.2k Jan 1, 2023
2.2k Jan 1, 2023

Synthesizing and manipulating 2048x1024 images with conditional GANs
pix2pixHD Project | Youtube | Paper Pytorch implementation of our method for high-resolution (e.g. 2048x1024) photorealistic image-to-image translatio
 6k Dec 27, 2022
6k Dec 27, 2022

PyTorch implementation of the YOLO (You Only Look Once) v2
PyTorch implementation of the YOLO (You Only Look Once) v2 The YOLOv2 is one of the most popular one-stage object detector. This project adopts PyTorc
 433 Nov 24, 2022
433 Nov 24, 2022
PyTorch Implementation of Realtime Multi-Person Pose Estimation project.
PyTorch Realtime Multi-Person Pose Estimation This is a pytorch version of Realtime_Multi-Person_Pose_Estimation, origin code is here Realtime_Multi-P
 157 Nov 12, 2022
157 Nov 12, 2022

PyTorch implementation of 1712.06087 "Zero-Shot" Super-Resolution using Deep Internal Learning
Unofficial PyTorch implementation of "Zero-Shot" Super-Resolution using Deep Internal Learning Unofficial Implementation of 1712.06087 "Zero-Shot" Sup
 196 Nov 27, 2022
196 Nov 27, 2022
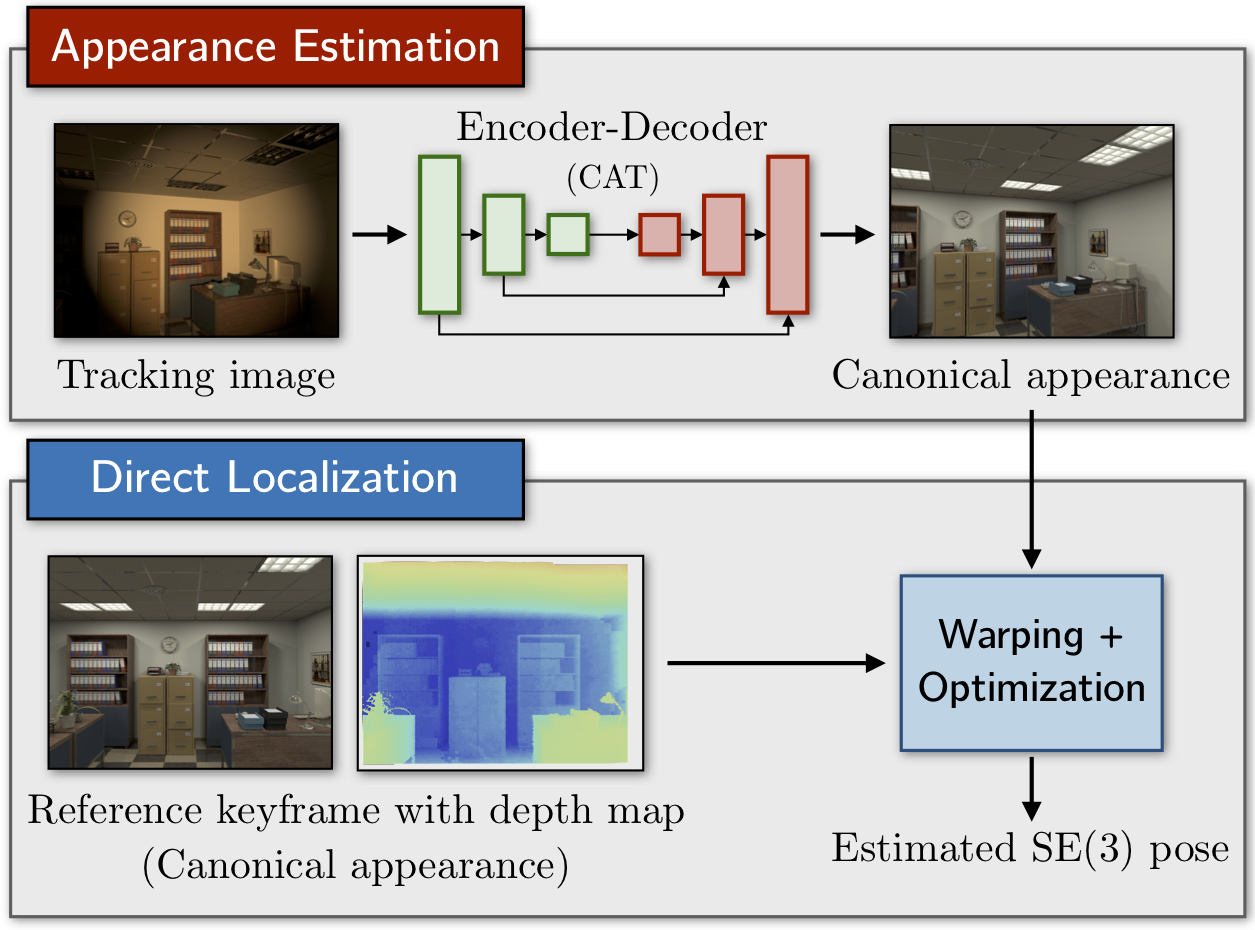
Canonical Appearance Transformations
CAT-Net: Learning Canonical Appearance Transformations Code to accompany our paper "How to Train a CAT: Learning Canonical Appearance Transformations
 54 Dec 24, 2022
54 Dec 24, 2022

This's an implementation of deepmind Visual Interaction Networks paper using pytorch
Visual-Interaction-Networks An implementation of Deepmind visual interaction networks in Pytorch. Introduction For the purpose of understanding the ch
 166 Dec 6, 2022
166 Dec 6, 2022

A PyTorch Implementation of Neural IMage Assessment
NIMA: Neural IMage Assessment This is a PyTorch implementation of the paper NIMA: Neural IMage Assessment (accepted at IEEE Transactions on Image Proc
 418 Dec 29, 2022
418 Dec 29, 2022
NIMA: Neural IMage Assessment
PyTorch NIMA: Neural IMage Assessment PyTorch implementation of Neural IMage Assessment by Hossein Talebi and Peyman Milanfar. You can learn more from
 293 Dec 30, 2022
293 Dec 30, 2022
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks (SDPoint) This repository contains the cod
 17 Jul 4, 2022
17 Jul 4, 2022

CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped
CSWin-Transformer This repo is the official implementation of "CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows". Th
 409 Jan 6, 2023
409 Jan 6, 2023
Deep Two-View Structure-from-Motion Revisited
Deep Two-View Structure-from-Motion Revisited This repository provides the code for our CVPR 2021 paper Deep Two-View Structure-from-Motion Revisited.
 145 Jan 6, 2023
145 Jan 6, 2023
This is an official implementation for "AS-MLP: An Axial Shifted MLP Architecture for Vision".
AS-MLP architecture for Image Classification Model Zoo Image Classification on ImageNet-1K Network Resolution Top-1 (%) Params FLOPs Throughput (image
 106 Dec 12, 2022
106 Dec 12, 2022

A PyTorch implementation of ViTGAN based on paper ViTGAN: Training GANs with Vision Transformers.
ViTGAN: Training GANs with Vision Transformers A PyTorch implementation of ViTGAN based on paper ViTGAN: Training GANs with Vision Transformers. Refer
 127 Dec 23, 2022
127 Dec 23, 2022

A simple python tool for explore your object detection dataset
A simple tool for explore your object detection dataset. The goal of this library is to provide simple and intuitive visualizations from your dataset and automatically find the best parameters for generating a specific grid of anchors that can fit you data characteristics
 142 Dec 25, 2022
142 Dec 25, 2022
Implementation of the HMAX model of vision in PyTorch
PyTorch implementation of HMAX PyTorch implementation of the HMAX model that closely follows that of the MATLAB implementation of The Laboratory for C
 52 Oct 13, 2022
52 Oct 13, 2022

Pytorch implementation of the DeepDream computer vision algorithm
deep-dream-in-pytorch Pytorch (https://github.com/pytorch/pytorch) implementation of the deep dream (https://en.wikipedia.org/wiki/DeepDream) computer
 102 Dec 5, 2022
102 Dec 5, 2022

The PyTorch improved version of TPAMI 2017 paper: Face Alignment in Full Pose Range: A 3D Total Solution.
Face Alignment in Full Pose Range: A 3D Total Solution By Jianzhu Guo. [Updates] 2020.8.30: The pre-trained model and code of ECCV-20 are made public
 3.4k Jan 2, 2023
3.4k Jan 2, 2023

Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
This is the official PyTorch implementation of the ALBEF paper [Blog]. This repository supports pre-training on custom datasets, as well as finetuning on VQA, SNLI-VE, NLVR2, Image-Text Retrieval on MSCOCO and Flickr30k, and visual grounding on RefCOCO+. Pre-trained and finetuned checkpoints are released.
 805 Jan 9, 2023
805 Jan 9, 2023

The Hailo Model Zoo includes pre-trained models and a full building and evaluation environment
Hailo Model Zoo The Hailo Model Zoo provides pre-trained models for high-performance deep learning applications. Using the Hailo Model Zoo you can mea
 50 Dec 7, 2022
50 Dec 7, 2022
PIX is an image processing library in JAX, for JAX.
PIX PIX is an image processing library in JAX, for JAX. Overview JAX is a library resulting from the union of Autograd and XLA for high-performance ma
 294 Jan 8, 2023
294 Jan 8, 2023
Code for ViTAS_Vision Transformer Architecture Search
Vision Transformer Architecture Search This repository open source the code for ViTAS: Vision Transformer Architecture Search. ViTAS aims to search fo
 46 Dec 17, 2022
46 Dec 17, 2022

EsViT: Efficient self-supervised Vision Transformers
Efficient Self-Supervised Vision Transformers (EsViT) PyTorch implementation for EsViT, built with two techniques: A multi-stage Transformer architect
352 Dec 25, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 43 Nov 21, 2022
43 Nov 21, 2022
Official PyTorch Implementation of Convolutional Hough Matching Networks, CVPR 2021 (oral)
Convolutional Hough Matching Networks This is the implementation of the paper "Convolutional Hough Matching Network" by J. Min and M. Cho. Implemented
 70 Nov 22, 2022
70 Nov 22, 2022
A PyTorch implementation of "DGC-Net: Dense Geometric Correspondence Network"
DGC-Net: Dense Geometric Correspondence Network This is a PyTorch implementation of our work "DGC-Net: Dense Geometric Correspondence Network" TL;DR A
 191 Dec 16, 2022
191 Dec 16, 2022

Amazon Forest Computer Vision: Satellite Image tagging code using PyTorch / Keras with lots of PyTorch tricks
Amazon Forest Computer Vision Satellite Image tagging code using PyTorch / Keras Here is a sample of images we had to work with Source: https://www.ka
 360 Dec 10, 2022
360 Dec 10, 2022
Torchreid: Deep learning person re-identification in PyTorch.
Torchreid Torchreid is a library for deep-learning person re-identification, written in PyTorch. It features: multi-GPU training support both image- a
 3.7k Jan 5, 2023
3.7k Jan 5, 2023
HyperPose is a library for building high-performance custom pose estimation applications.
HyperPose is a library for building high-performance custom pose estimation applications.
 1.2k Jan 4, 2023
1.2k Jan 4, 2023

Real-time multi-object tracker using YOLO v5 and deep sort
This repository contains a two-stage-tracker. The detections generated by YOLOv5, a family of object detection architectures and models pretrained on the COCO dataset, are passed to a Deep Sort algorithm which tracks the objects. It can track any object that your Yolov5 model was trained to detect.
 3.6k Jan 5, 2023
3.6k Jan 5, 2023

A PyTorch Reimplementation of TecoGAN: Temporally Coherent GAN for Video Super-Resolution
TecoGAN-PyTorch Introduction This is a PyTorch reimplementation of TecoGAN: Temporally Coherent GAN for Video Super-Resolution (VSR). Please refer to
 165 Dec 17, 2022
165 Dec 17, 2022

VD-BERT: A Unified Vision and Dialog Transformer with BERT
VD-BERT: A Unified Vision and Dialog Transformer with BERT PyTorch Code for the following paper at EMNLP2020: Title: VD-BERT: A Unified Vision and Dia
44 Nov 1, 2022
General Multi-label Image Classification with Transformers
General Multi-label Image Classification with Transformers Jack Lanchantin, Tianlu Wang, Vicente Ordóñez Román, Yanjun Qi Conference on Computer Visio
 154 Dec 21, 2022
154 Dec 21, 2022
![[Preprint]](https://github.com/VITA-Group/SViTE/raw/main/Figs/res.png)
[Preprint] "Chasing Sparsity in Vision Transformers: An End-to-End Exploration" by Tianlong Chen, Yu Cheng, Zhe Gan, Lu Yuan, Lei Zhang, Zhangyang Wang
Chasing Sparsity in Vision Transformers: An End-to-End Exploration Codes for [Preprint] Chasing Sparsity in Vision Transformers: An End-to-End Explora
 64 Dec 8, 2022
64 Dec 8, 2022
Pose Detection and Machine Learning for real-time body posture analysis during exercise to provide audiovisual feedback on improvement of form.
Posture: Pose Tracking and Machine Learning for prescribing corrective suggestions to improve posture and form while exercising. This repository conta
 10 Nov 11, 2022
10 Nov 11, 2022

TensorRT examples (Jetson, Python/C++)(object detection)
TensorRT examples (Jetson, Python/C++)(object detection)
 53 Dec 22, 2022
53 Dec 22, 2022
VD-BERT: A Unified Vision and Dialog Transformer with BERT
VD-BERT: A Unified Vision and Dialog Transformer with BERT PyTorch Code for the following paper at EMNLP2020: Title: VD-BERT: A Unified Vision and Dia
44 Nov 1, 2022
View part of your screen in grayscale or simulated color vision deficiency.
monolens View part of your screen in grayscale or filtered to simulate color vision deficiency. Watch the demo on YouTube. Install with pip install mo
 31 Oct 11, 2022
31 Oct 11, 2022

Global Filter Networks for Image Classification
Global Filter Networks for Image Classification Created by Yongming Rao, Wenliang Zhao, Zheng Zhu, Jiwen Lu, Jie Zhou This repository contains PyTorch
 273 Dec 26, 2022
273 Dec 26, 2022
[CVPR 2021] Pytorch implementation of Hijack-GAN: Unintended-Use of Pretrained, Black-Box GANs
Hijack-GAN: Unintended-Use of Pretrained, Black-Box GANs In this work, we propose a framework HijackGAN, which enables non-linear latent space travers
 46 Sep 5, 2022
46 Sep 5, 2022

Unofficial implementation of "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows" (https://arxiv.org/abs/2103.14030)
Swin-Transformer-Tensorflow A direct translation of the official PyTorch implementation of "Swin Transformer: Hierarchical Vision Transformer using Sh
 52 Dec 29, 2022
52 Dec 29, 2022

Here is my Senior Design Project that I implemented to graduate from Computer Engineering.
Here is my Senior Design Project that I implemented to graduate from Computer Engineering. It is a chatbot made in RASA and helps the user to plan their vacation in the Turkish language. In order to plan the user's vacation, it provides reservations by asking various questions for hotel, flight, or event.
 25 May 31, 2022
25 May 31, 2022

CLIP: Connecting Text and Image (Learning Transferable Visual Models From Natural Language Supervision)
CLIP (Contrastive Language–Image Pre-training) Experiments (Evaluation) Model Dataset Acc (%) ViT-B/32 (Paper) CIFAR100 65.1 ViT-B/32 (Our) CIFAR100 6
 52 Jan 7, 2023
52 Jan 7, 2023
A neuroanatomy-based augmented reality experience powered by computer vision. Features 3D visuals of the Atlas Brain Map slices.
Brain Augmented Reality (AR) A neuroanatomy-based augmented reality experience powered by computer vision that features 3D visuals of the Atlas Brain
 10 Oct 6, 2022
10 Oct 6, 2022

MLP-Like Vision Permutator for Visual Recognition (PyTorch)
Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition (arxiv) This is a Pytorch implementation of our paper. We present Vision
 162 Nov 28, 2022
162 Nov 28, 2022

The implementation of "Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer"
Shuffle Transformer The implementation of "Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer" Introduction Very recently, window-
 87 Nov 29, 2022
87 Nov 29, 2022

VOLO: Vision Outlooker for Visual Recognition
VOLO: Vision Outlooker for Visual Recognition, arxiv This is a PyTorch implementation of our paper. We present Vision Outlooker (VOLO). We show that o
 876 Dec 9, 2022
876 Dec 9, 2022

Learning to Reconstruct 3D Non-Cuboid Room Layout from a Single RGB Image
NonCuboidRoom Paper Learning to Reconstruct 3D Non-Cuboid Room Layout from a Single RGB Image Cheng Yang*, Jia Zheng*, Xili Dai, Rui Tang, Yi Ma, Xiao
 67 Dec 15, 2022
67 Dec 15, 2022

Official project website for the CVPR 2021 paper "Exploring intermediate representation for monocular vehicle pose estimation"
EgoNet Official project website for the CVPR 2021 paper "Exploring intermediate representation for monocular vehicle pose estimation". This repo inclu
 138 Dec 9, 2022
138 Dec 9, 2022
![[CVPR 2021] Region-aware Adaptive Instance Normalization for Image Harmonization](https://github.com/junleen/RainNet/raw/main/Doc/sample.png)
[CVPR 2021] Region-aware Adaptive Instance Normalization for Image Harmonization
RainNet — Official Pytorch Implementation Region-aware Adaptive Instance Normalization for Image Harmonization Jun Ling, Han Xue, Li Song*, Rong Xie,
 130 Dec 11, 2022
130 Dec 11, 2022
CVPR 2021 Official Pytorch Code for UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training
UC2 UC2: Universal Cross-lingual Cross-modal Vision-and-Language Pre-training Mingyang Zhou, Luowei Zhou, Shuohang Wang, Yu Cheng, Linjie Li, Zhou Yu,
 28 Dec 30, 2022
28 Dec 30, 2022

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022

The AugNet Python module contains functions for the fast computation of image similarity.
AugNet AugNet: End-to-End Unsupervised Visual Representation Learning with Image Augmentation arxiv link In our work, we propose AugNet, a new deep le
 74 Dec 28, 2022
74 Dec 28, 2022

Official Code for ICML 2021 paper "Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline"
Revisiting Point Cloud Shape Classification with a Simple and Effective Baseline Ankit Goyal, Hei Law, Bowei Liu, Alejandro Newell, Jia Deng Internati
 115 Jan 4, 2023
115 Jan 4, 2023

Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models
Patch-Rotation(PatchRot) Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models Submitted to Neurips2021 To
 4 Jul 12, 2021
4 Jul 12, 2021
A PyTorch Implementation of ViT (Vision Transformer)
ViT - Vision Transformer This is an implementation of ViT - Vision Transformer by Google Research Team through the paper "An Image is Worth 16x16 Word
 7 May 11, 2022
7 May 11, 2022
A script for performing OTA update over BLE on ESP32
A script for performing OTA update over BLE on ESP32
 18 Dec 15, 2022
18 Dec 15, 2022

Python code to crawl computer vision papers from top CV conferences. Currently it supports CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, SIGGRAPH
Python code to crawl computer vision papers from top CV conferences. Currently it supports CVPR, ICCV, ECCV, NeurIPS, ICML, ICLR, SIGGRAPH. It leverages selenium, a website testing framework to crawl the titles and pdf urls from the conference website, and download them one by one with some simple anti-anti-crawler tricks.
 39 Nov 21, 2022
39 Nov 21, 2022
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

Episodic Transformer (E.T.) is a novel attention-based architecture for vision-and-language navigation. E.T. is based on a multimodal transformer that encodes language inputs and the full episode history of visual observations and actions.
Episodic Transformers (E.T.) Episodic Transformer for Vision-and-Language Navigation Alexander Pashevich, Cordelia Schmid, Chen Sun Episodic Transform
 62 Dec 24, 2022
62 Dec 24, 2022

PyTorch evaluation code for Delving Deep into the Generalization of Vision Transformers under Distribution Shifts.
Out-of-distribution Generalization Investigation on Vision Transformers This repository contains PyTorch evaluation code for Delving Deep into the Gen
 72 Dec 13, 2022
72 Dec 13, 2022
![[CVPR 21] Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting, IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2021.](https://github.com/AyanKumarBhunia/Self-Supervised-Learning-for-Sketch/raw/main/sample_images/outline.png)
[CVPR 21] Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting, IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2021.
Vectorization and Rasterization: Self-Supervised Learning for Sketch and Handwriting, CVPR 2021. Ayan Kumar Bhunia, Pinaki nath Chowdhury, Yongxin Yan
 44 Dec 12, 2022
44 Dec 12, 2022
Aggragrating Nested Transformer Official Jax Implementation
NesT is a simple method, which aggragrates nested local transformers on image blocks. The idea makes vision transformers attain better accuracy, data efficiency, and convergence on the ImageNet benchmark. NesT can be scaled to small datasets to match convnet accuracy.
169 Dec 20, 2022

A task-agnostic vision-language architecture as a step towards General Purpose Vision
Towards General Purpose Vision Systems By Tanmay Gupta, Amita Kamath, Aniruddha Kembhavi, and Derek Hoiem Overview Welcome to the official code base f
 79 Dec 23, 2022
79 Dec 23, 2022
learn how to use Gesture Control to change the volume of a computer
Volume-Control-using-gesture In this project we are going to learn how to use Gesture Control to change the volume of a computer. We first look into h
 49 Sep 22, 2022
49 Sep 22, 2022

modelvshuman is a Python library to benchmark the gap between human and machine vision
modelvshuman is a Python library to benchmark the gap between human and machine vision. Using this library, both PyTorch and TensorFlow models can be evaluated on 17 out-of-distribution datasets with high-quality human comparison data.
 244 Jan 3, 2023
244 Jan 3, 2023
Backdoor is a term that refers to the access of the software or hardware of a computer system without being detected.
This program is an non-object oriented opensource, hidden and undetectable backdoor/reverse shell/RAT for Windows made in Python 3 which contains many features such as multi-client support and cross-platform server.
 35 Apr 17, 2022
35 Apr 17, 2022

Tensorflow implementation of MIRNet for Low-light image enhancement
MIRNet Tensorflow implementation of the MIRNet architecture as proposed by Learning Enriched Features for Real Image Restoration and Enhancement. Lanu
 91 Jan 6, 2023
91 Jan 6, 2023

Official implement of "CAT: Cross Attention in Vision Transformer".
CAT: Cross Attention in Vision Transformer This is official implement of "CAT: Cross Attention in Vision Transformer". Abstract Since Transformer has
 100 Dec 15, 2022
100 Dec 15, 2022

Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals
LapDepth-release This repository is a Pytorch implementation of the paper "Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals" M
 205 Dec 30, 2022
205 Dec 30, 2022

CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation
CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation (CVPR 2021, oral presentation) CoCosNet v2: Full-Resolution Correspondence
308 Dec 7, 2022
It's final year project of Diploma Engineering. This project is based on Computer Vision.
Face-Recognition-Based-Attendance-System It's final year project of Diploma Engineering. This project is based on Computer Vision. Brief idea about ou
 10 Nov 2, 2022
10 Nov 2, 2022
Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation
STCN Rethinking Space-Time Networks with Improved Memory Coverage for Efficient Video Object Segmentation Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang [a
 456 Dec 12, 2022
456 Dec 12, 2022

Official repository for "On Improving Adversarial Transferability of Vision Transformers" (2021)
Improving-Adversarial-Transferability-of-Vision-Transformers Muzammal Naseer, Kanchana Ranasinghe, Salman Khan, Fahad Khan, Fatih Porikli arxiv link A
 47 Dec 2, 2022
47 Dec 2, 2022

Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers.
Less is More: Pay Less Attention in Vision Transformers Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers. By
 73 Jan 1, 2023
73 Jan 1, 2023

Statistics and Visualization of acceptance rate, main keyword of CVPR 2021 accepted papers for the main Computer Vision conference (CVPR)
Statistics and Visualization of acceptance rate, main keyword of CVPR 2021 accepted papers for the main Computer Vision conference (CVPR)
 78 Aug 23, 2022
78 Aug 23, 2022
Sharpness-Aware Minimization for Efficiently Improving Generalization
Sharpness-Aware-Minimization-TensorFlow This repository provides a minimal implementation of sharpness-aware minimization (SAM) (Sharpness-Aware Minim
54 Dec 8, 2022

Pytorch implementation of MaskFlownet
MaskFlownet-Pytorch Unofficial PyTorch implementation of MaskFlownet (https://github.com/microsoft/MaskFlownet). Tested with: PyTorch 1.5.0 CUDA 10.1
 84 Nov 2, 2022
84 Nov 2, 2022
A framework for analyzing computer vision models with simulated data
3DB: A framework for analyzing computer vision models with simulated data Paper Quickstart guide Blog post Installation Follow instructions on: https:
 112 Jan 1, 2023
112 Jan 1, 2023

DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification Created by Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, Ch
414 Jan 1, 2023
![[CVPR 2021] Monocular depth estimation using wavelets for efficiency](https://github.com/nianticlabs/wavelet-monodepth/raw/main/assets/combo_kitti.gif)
[CVPR 2021] Monocular depth estimation using wavelets for efficiency
Single Image Depth Prediction with Wavelet Decomposition Michaël Ramamonjisoa, Michael Firman, Jamie Watson, Vincent Lepetit and Daniyar Turmukhambeto
 205 Jan 2, 2023
205 Jan 2, 2023
![[ICML 2021, Long Talk] Delving into Deep Imbalanced Regression](https://github.com/YyzHarry/imbalanced-regression/raw/main/teaser/overview.gif)
[ICML 2021, Long Talk] Delving into Deep Imbalanced Regression
Delving into Deep Imbalanced Regression This repository contains the implementation code for paper: Delving into Deep Imbalanced Regression Yuzhe Yang
 568 Dec 30, 2022
568 Dec 30, 2022
![[CVPR 2021]](https://github.com/VITA-Group/CV_LTH_Pre-training/raw/main/Figs/Teaser.png)
[CVPR 2021] "The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models" Tianlong Chen, Jonathan Frankle, Shiyu Chang, Sijia Liu, Yang Zhang, Michael Carbin, Zhangyang Wang
The Lottery Tickets Hypothesis for Supervised and Self-supervised Pre-training in Computer Vision Models Codes for this paper The Lottery Tickets Hypo
59 Dec 28, 2022
Official repository for "Intriguing Properties of Vision Transformers" (2021)
Intriguing Properties of Vision Transformers Muzammal Naseer, Kanchana Ranasinghe, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, & Ming-Hsuan Yang P
155 Dec 27, 2022
Using context-free grammar formalism to parse English sentences to determine their structure to help computer to better understand the meaning of the sentence.
Sentance Parser Executing the Program Make sure Python 3.6+ is installed. Install requirements $ pip install requirements.txt Run the program:
 12 Sep 28, 2022
12 Sep 28, 2022

Implementation for paper MLP-Mixer: An all-MLP Architecture for Vision
MLP Mixer Implementation for paper MLP-Mixer: An all-MLP Architecture for Vision. Give us a star if you like this repo. Author: Github: bangoc123 Emai
 86 Dec 10, 2022
86 Dec 10, 2022
This is an official implementation of CvT: Introducing Convolutions to Vision Transformers.
Introduction This is an official implementation of CvT: Introducing Convolutions to Vision Transformers. We present a new architecture, named Convolut
 175 Jan 8, 2023
175 Jan 8, 2023