1287 Repositories
Python computer-vision-opencv Libraries

VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training [Arxiv] VideoMAE: Masked Autoencoders are Data-Efficient Learne
 697 Jan 7, 2023
697 Jan 7, 2023

Temporally Efficient Vision Transformer for Video Instance Segmentation, CVPR 2022, Oral
Temporally Efficient Vision Transformer for Video Instance Segmentation Temporally Efficient Vision Transformer for Video Instance Segmentation (CVPR
 203 Dec 31, 2022
203 Dec 31, 2022

Official code for our CVPR '22 paper "Dataset Distillation by Matching Training Trajectories"
Dataset Distillation by Matching Training Trajectories Project Page | Paper This repo contains code for training expert trajectories and distilling sy
 256 Jan 5, 2023
256 Jan 5, 2023

Official MegEngine implementation of CREStereo(CVPR 2022 Oral).
[CVPR 2022] Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation This repository contains MegEngine implementation of ou
 309 Dec 30, 2022
309 Dec 30, 2022

The official repo for OC-SORT: Observation-Centric SORT on video Multi-Object Tracking. OC-SORT is simple, online and robust to occlusion/non-linear motion.
OC-SORT Observation-Centric SORT (OC-SORT) is a pure motion-model-based multi-object tracker. It aims to improve tracking robustness in crowded scenes
 325 Jan 5, 2023
325 Jan 5, 2023
![[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427](https://github.com/jiawei-ren/BalancedMSE/raw/main/figures/intro.png)
[CVPR 2022 Oral] Balanced MSE for Imbalanced Visual Regression https://arxiv.org/abs/2203.16427
Balanced MSE Code for the paper: Balanced MSE for Imbalanced Visual Regression Jiawei Ren, Mingyuan Zhang, Cunjun Yu, Ziwei Liu CVPR 2022 (Oral) News
 267 Jan 1, 2023
267 Jan 1, 2023

Implementation of Deformable Attention in Pytorch from the paper "Vision Transformer with Deformable Attention"
Deformable Attention Implementation of Deformable Attention from this paper in Pytorch, which appears to be an improvement to what was proposed in DET
 128 Dec 24, 2022
128 Dec 24, 2022

PyTorch implementation of U-TAE and PaPs for satellite image time series panoptic segmentation.
Panoptic Segmentation of Satellite Image Time Series with Convolutional Temporal Attention Networks (ICCV 2021) This repository is the official implem
 71 Jan 4, 2023
71 Jan 4, 2023

Official repository accompanying a CVPR 2022 paper EMOCA: Emotion Driven Monocular Face Capture And Animation. EMOCA takes a single image of a face as input and produces a 3D reconstruction. EMOCA sets the new standard on reconstructing highly emotional images in-the-wild
EMOCA: Emotion Driven Monocular Face Capture and Animation Radek Daněček · Michael J. Black · Timo Bolkart CVPR 2022 This repository is the official i
 339 Dec 30, 2022
339 Dec 30, 2022

Official source code of Fast Point Transformer, CVPR 2022
Fast Point Transformer Project Page | Paper This repository contains the official source code and data for our paper: Fast Point Transformer Chunghyun
 182 Dec 23, 2022
182 Dec 23, 2022

This repository contains the best Data Science free hand-picked resources to equip you with all the industry-driven skills and interview preparation kit.
Best Data Science Resources Hey, Data Enthusiasts out there! Finally, after lots of requests from the community I finally came up with the best free D
 415 Dec 31, 2022
415 Dec 31, 2022
HugsVision is a easy to use huggingface wrapper for state-of-the-art computer vision
HugsVision is an open-source and easy to use all-in-one huggingface wrapper for computer vision. The goal is to create a fast, flexible and user-frien
 166 Nov 27, 2022
166 Nov 27, 2022
🤗🖼️ HuggingPics: Fine-tune Vision Transformers for anything using images found on the web.
🤗 🖼️ HuggingPics Fine-tune Vision Transformers for anything using images found on the web. Check out the video below for a walkthrough of this proje
 185 Dec 21, 2022
185 Dec 21, 2022

🙌Kart of 210+ projects based on machine learning, deep learning, computer vision, natural language processing and all. Show your support by ✨ this repository.
ML-ProjectKart 📌 Repository This kart showcases the finest collection of all projects based on machine learning, deep learning, computer vision, natu
 203 Dec 28, 2022
203 Dec 28, 2022

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022
Official codebase used to develop Vision Transformer, MLP-Mixer, LiT and more.
Big Vision This codebase is designed for training large-scale vision models on Cloud TPU VMs. It is based on Jax/Flax libraries, and uses tf.data and
 701 Jan 3, 2023
701 Jan 3, 2023

BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training
BigDetection: A Large-scale Benchmark for Improved Object Detector Pre-training By Likun Cai, Zhi Zhang, Yi Zhu, Li Zhang, Mu Li, Xiangyang Xue. This
 290 Dec 29, 2022
290 Dec 29, 2022

Building a real-time environment using webcam frame division in OpenCV and classify cropped images using a fine-tuned vision transformers on hybryd datasets samples for facial emotion recognition.
Visual Transformer for Facial Emotion Recognition (FER) This project has the aim to build an efficient Visual Transformer for the Facial Emotion Recog
 8 Dec 12, 2022
8 Dec 12, 2022

Use Python, OpenCV, and MediaPipe to control a keyboard with facial gestures
CheekyKeys A Face-Computer Interface CheekyKeys lets you control your keyboard using your face. View a fuller demo and more background on the project
 69 Nov 9, 2022
69 Nov 9, 2022

Automatic number plate recognition using tech: Yolo, OCR, Scene text detection, scene text recognation, flask, torch
Automatic Number Plate Recognition Automatic Number Plate Recognition (ANPR) is the process of reading the characters on the plate with various optica
 52 Dec 22, 2022
52 Dec 22, 2022
SurfEmb (CVPR 2022) - SurfEmb: Dense and Continuous Correspondence Distributions
SurfEmb SurfEmb: Dense and Continuous Correspondence Distributions for Object Pose Estimation with Learnt Surface Embeddings Rasmus Laurvig Haugard, A
 56 Nov 19, 2022
56 Nov 19, 2022

Code for "Neural 3D Scene Reconstruction with the Manhattan-world Assumption" CVPR 2022 Oral
News 05/10/2022 To make the comparison on ScanNet easier, we provide all quantitative and qualitative results of baselines here, including COLMAP, COL
 365 Dec 30, 2022
365 Dec 30, 2022
A Python library that enables ML teams to share, load, and transform data in a collaborative, flexible, and efficient way :chestnut:
Squirrel Core Share, load, and transform data in a collaborative, flexible, and efficient way What is Squirrel? Squirrel is a Python library that enab
 249 Dec 7, 2022
249 Dec 7, 2022

ConvMAE: Masked Convolution Meets Masked Autoencoders
ConvMAE ConvMAE: Masked Convolution Meets Masked Autoencoders Peng Gao1, Teli Ma1, Hongsheng Li2, Jifeng Dai3, Yu Qiao1, 1 Shanghai AI Laboratory, 2 M
 345 Jan 8, 2023
345 Jan 8, 2023

Optical character recognition for Japanese text, with the main focus being Japanese manga
Manga OCR Optical character recognition for Japanese text, with the main focus being Japanese manga. It uses a custom end-to-end model built with Tran
 327 Jan 1, 2023
327 Jan 1, 2023

A simple interface to help lazy people like me to shutdown/reboot/sleep their computer remotely.
🦥 Lazy Helper ! A simple interface to help lazy people like me to shut down/reboot/sleep/lock/etc. their computer remotely. - USAGE If you're a lazy
 117 Nov 30, 2022
117 Nov 30, 2022

Repo for "Benchmarking Robustness of 3D Point Cloud Recognition against Common Corruptions" https://arxiv.org/abs/2201.12296
Benchmarking Robustness of 3D Point Cloud Recognition against Common Corruptions This repo contains the dataset and code for the paper Benchmarking Ro
 168 Dec 29, 2022
168 Dec 29, 2022

code for TCL: Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022
Vision-Language Pre-Training with Triple Contrastive Learning, CVPR 2022 News (03/16/2022) upload retrieval checkpoints finetuned on COCO and Flickr T
 187 Jan 2, 2023
187 Jan 2, 2023

Developing and Comparing Vision-based Algorithms for Vision-based Agile Flight
DodgeDrone: Vision-based Agile Drone Flight (ICRA 2022 Competition) Would you like to push the boundaries of drone navigation? Then participate in the
 115 Dec 10, 2022
115 Dec 10, 2022
Interactive class notebooks for ECE4076 Computer Vision, weeks 1 - 6
ECE4076 Interactive class notebooks for ECE4076 Computer Vision, weeks 1 - 6. ECE4076 is a computer vision unit at Monash University, covering both cl
 9 Jun 16, 2022
9 Jun 16, 2022

Instance-wise Occlusion and Depth Orders in Natural Scenes (CVPR 2022)
Instance-wise Occlusion and Depth Orders in Natural Scenes Official source code. Appears at CVPR 2022 This repository provides a new dataset, named In
27 Dec 27, 2022

Implementation of CaiT models in TensorFlow and ImageNet-1k checkpoints. Includes code for inference and fine-tuning.
CaiT-TF (Going deeper with Image Transformers) This repository provides TensorFlow / Keras implementations of different CaiT [1] variants from Touvron
 9 Jun 26, 2022
9 Jun 26, 2022
DLO8012: Natural Language Processing & CSL804: Computational Lab - II Semester VIII
NATURAL-LANGUAGE-PROCESSING-AND-COMPUTATIONAL-LAB-II DLO8012: NLP & CSL804: CL-II [SEMESTER VIII] Syllabus NLP - Reference Books THE WALL MEGA SATISH
 7 Apr 28, 2022
7 Apr 28, 2022

A Persian Image Captioning model based on Vision Encoder Decoder Models of the transformers🤗.
Persian-Image-Captioning We fine-tuning the Vision Encoder Decoder Model for the task of image captioning on the coco-flickr-farsi dataset. The implem
 15 Aug 25, 2022
15 Aug 25, 2022

As-ViT: Auto-scaling Vision Transformers without Training
As-ViT: Auto-scaling Vision Transformers without Training [PDF] Wuyang Chen, Wei Huang, Xianzhi Du, Xiaodan Song, Zhangyang Wang, Denny Zhou In ICLR 2
 68 Sep 5, 2022
68 Sep 5, 2022

PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI
data2vec-pytorch PyTorch implementation of "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language" from Meta AI (F
 105 Jan 4, 2023
105 Jan 4, 2023

QuadTree Attention for Vision Transformers (ICLR2022)
This repository contains codes for quadtree attention. This repo contains codes for feature matching, image classficiation, object detection and seman
 222 Dec 28, 2022
222 Dec 28, 2022
AI Summer's complete catalog of articles
Learn Deep Learning with AI Summer A collection of all articles (almost 100) written for the AI Summer blog organized by topic. Deep Learning Theory M
 95 Dec 29, 2022
95 Dec 29, 2022
ICON: Implicit Clothed humans Obtained from Normals (CVPR 2022)
ICON: Implicit Clothed humans Obtained from Normals Yuliang Xiu · Jinlong Yang · Dimitrios Tzionas · Michael J. Black CVPR 2022 News 🚩 [2022/04/26] H
 1.1k Jan 4, 2023
1.1k Jan 4, 2023

Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Paper | Blog OFA is a unified multimodal pretrained model that unifies modalities (i.e., cross-modality, vision, language) and tasks (e.g., image gene
 1.4k Jan 8, 2023
1.4k Jan 8, 2023
KoCLIP: Korean port of OpenAI CLIP, in Flax
KoCLIP This repository contains code for KoCLIP, a Korean port of OpenAI's CLIP. This project was conducted as part of Hugging Face's Flax/JAX communi
 100 Jan 2, 2023
100 Jan 2, 2023
Includes PyTorch - Keras model porting code for ConvNeXt family of models with fine-tuning and inference notebooks.
ConvNeXt-TF This repository provides TensorFlow / Keras implementations of different ConvNeXt [1] variants. It also provides the TensorFlow / Keras mo
87 Dec 6, 2022
An ever-growing playground of notebooks showcasing CLIP's impressive zero-shot capabilities.
Playground for CLIP-like models Demo Colab Link GradCAM Visualization Naive Zero-shot Detection Smarter Zero-shot Detection Captcha Solver Changelog 2
 101 Dec 30, 2022
101 Dec 30, 2022
Course about deep learning for computer vision and graphics co-developed by YSDA and Skoltech.
Deep Vision and Graphics This repo supplements course "Deep Vision and Graphics" taught at YSDA @fall'21. The course is the successor of "Deep Learnin
 160 Jan 2, 2023
160 Jan 2, 2023

In this tutorial, you will perform inference across 10 well-known pre-trained object detectors and fine-tune on a custom dataset. Design and train your own object detector.
Object Detection Object detection is a computer vision task for locating instances of predefined objects in images or videos. In this tutorial, you wi
 62 Dec 25, 2022
62 Dec 25, 2022

A collection of educational notebooks on multi-view geometry and computer vision.
Multiview notebooks This is a collection of educational notebooks on multi-view geometry and computer vision. Subjects covered in these notebooks incl
 65 Dec 9, 2022
65 Dec 9, 2022

Code for Ditto: Building Digital Twins of Articulated Objects from Interaction
Ditto: Building Digital Twins of Articulated Objects from Interaction Zhenyu Jiang, Cheng-Chun Hsu, Yuke Zhu CVPR 2022, Oral Project | arxiv News 2022
 78 Dec 22, 2022
78 Dec 22, 2022
Ego4d dataset repository. Download the dataset, visualize, extract features & example usage of the dataset
Ego4D EGO4D is the world's largest egocentric (first person) video ML dataset and benchmark suite, with 3,600 hrs (and counting) of densely narrated v
 118 Jan 7, 2023
118 Jan 7, 2023

Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology (LMRL Workshop, NeurIPS 2021)
Self-Supervised Vision Transformers Learn Visual Concepts in Histopathology Self-Supervised Vision Transformers Learn Visual Concepts in Histopatholog
 95 Dec 24, 2022
95 Dec 24, 2022

Soomvaar is the repo which 🏩 contains different collection of 👨💻🚀code in Python and 💫✨Machine 👬🏼 learning algorithms📗📕 that is made during 📃 my practice and learning of ML and Python✨💥
Soomvaar 📌 Introduction Soomvaar is the collection of various codes implement in machine learning and machine learning algorithms with python on coll
 42 Dec 30, 2022
42 Dec 30, 2022
🍷 Gracefully claim weekly free games and monthly content from Epic Store.
EPIC 免费人 🚀 优雅地领取 Epic 免费游戏 Introduction 👋 Epic AwesomeGamer 帮助玩家优雅地领取 Epic 免费游戏。 使用 「Epic免费人」可以实现如下需求: get:搬空游戏商店,获取所有常驻免费游戏与免费附加内容; claim:领取周免游戏及其免
 571 Dec 28, 2022
571 Dec 28, 2022
![[CVPR 2022] Pytorch implementation of](https://github.com/nv-nguyen/template-pose/raw/main/figures/method.png)
[CVPR 2022] Pytorch implementation of "Templates for 3D Object Pose Estimation Revisited: Generalization to New objects and Robustness to Occlusions" paper
template-pose Pytorch implementation of "Templates for 3D Object Pose Estimation Revisited: Generalization to New objects and Robustness to Occlusions
 92 Dec 28, 2022
92 Dec 28, 2022
[CVPR 2022 Oral] TubeDETR: Spatio-Temporal Video Grounding with Transformers
TubeDETR: Spatio-Temporal Video Grounding with Transformers Website • STVG Demo • Paper This repository provides the code for our paper. This includes
 108 Dec 27, 2022
108 Dec 27, 2022

(CVPR 2022 - oral) Multi-View Depth Estimation by Fusing Single-View Depth Probability with Multi-View Geometry
Multi-View Depth Estimation by Fusing Single-View Depth Probability with Multi-View Geometry Official implementation of the paper Multi-View Depth Est
 138 Dec 28, 2022
138 Dec 28, 2022

PromptDet: Expand Your Detector Vocabulary with Uncurated Images
PromptDet: Expand Your Detector Vocabulary with Uncurated Images Paper Website Introduction The goal of this work is to establish a scalable pipeline
 103 Dec 20, 2022
103 Dec 20, 2022

Code for CVPR'2022 paper ✨ "Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-Language Model"
PPE ✨ Repository for our CVPR'2022 paper: Predict, Prevent, and Evaluate: Disentangled Text-Driven Image Manipulation Empowered by Pre-Trained Vision-
 34 Nov 28, 2022
34 Nov 28, 2022
![[CVPR22] Official codebase of Semantic Segmentation by Early Region Proxy.](https://github.com/YiF-Zhang/RegionProxy/raw/master/.github/perf-gflops-param.jpg)
[CVPR22] Official codebase of Semantic Segmentation by Early Region Proxy.
RegionProxy Figure 2. Performance vs. GFLOPs on ADE20K val split. Semantic Segmentation by Early Region Proxy Yifan Zhang, Bo Pang, Cewu Lu CVPR 2022
 54 Nov 29, 2022
54 Nov 29, 2022

Realtime micro-expression recognition using OpenCV and PyTorch
Micro-expression Recognition Realtime micro-expression recognition from scratch using OpenCV and PyTorch Try it out with a webcam or video using the e
 35 Dec 5, 2022
35 Dec 5, 2022

Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
beyond masking Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers The code is coming Figure 1: Pipeline of token-based pre-
 23 Sep 27, 2022
23 Sep 27, 2022

Stuff related to Ben Eater's 8bit breadboard computer
8bit breadboard computer simulator This is an assembler + simulator/emulator of Ben Eater's 8bit breadboard computer. For a version with its RAM upgra
 29 Dec 29, 2022
29 Dec 29, 2022
![[ICCV2021] 3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds](https://github.com/zlccccc/3DVG-Transformer/raw/main/demo/Model.png)
[ICCV2021] 3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds
3DVG-Transformer This repository is for the ICCV 2021 paper "3DVG-Transformer: Relation Modeling for Visual Grounding on Point Clouds" Our method "3DV
 22 Dec 11, 2022
22 Dec 11, 2022

Python scripts performing class agnostic object localization using the Object Localization Network model in ONNX.
ONNX Object Localization Network Python scripts performing class agnostic object localization using the Object Localization Network model in ONNX. Ori
 15 Oct 14, 2022
15 Oct 14, 2022
Official codebase for ICLR oral paper Unsupervised Vision-Language Grammar Induction with Shared Structure Modeling
CLIORA This is the official codebase for ICLR oral paper: Unsupervised Vision-Language Grammar Induction with Shared Structure Modeling. We introduce
 32 Dec 23, 2022
32 Dec 23, 2022

Converts an image into funny, smaller amongus characters
SussyImage Converts an image into funny, smaller amongus characters Demo Mona Lisa | Lona Misa (Made up of AmongUs characters) API I've also added an
 14 Aug 18, 2022
14 Aug 18, 2022
Train CNNs for the fruits360 data set in NTOU CS「Machine Vision」class.
CNNs fruits360 Train CNNs for the fruits360 data set in NTOU CS「Machine Vision」class. CNN on a pretrained model Build a CNN on a pretrained model, Res
 1 Mar 7, 2022
1 Mar 7, 2022

Under the hood working of transformers, fine-tuning GPT-3 models, DeBERTa, vision models, and the start of Metaverse, using a variety of NLP platforms: Hugging Face, OpenAI API, Trax, and AllenNLP
Transformers-for-NLP-2nd-Edition @copyright 2022, Packt Publishing, Denis Rothman Contact me for any question you have on LinkedIn Get the book on Ama
 150 Dec 23, 2022
150 Dec 23, 2022

Python scripts for performing road segemtnation and car detection using the HybridNets multitask model in ONNX.
ONNX-HybridNets-Multitask-Road-Detection Python scripts for performing road segemtnation and car detection using the HybridNets multitask model in ONN
45 Jan 1, 2023

This is the first released system towards complex meters` detection and recognition, which is implemented by computer vision techniques.
A three-stage detection and recognition pipeline of complex meters in wild This is the first released system towards detection and recognition of comp
 19 Nov 28, 2022
19 Nov 28, 2022
![[CVPR 2022]](https://github.com/VITA-Group/Diverse-ViT/raw/main/Figs/Diversity_overview.png)
[CVPR 2022] "The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy" by Tianlong Chen, Zhenyu Zhang, Yu Cheng, Ahmed Awadallah, Zhangyang Wang
The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy Codes for this paper: [CVPR 2022] The Pr
16 Nov 26, 2022
A 100% python file organizer. Keep your computer always organized!
PythonOrganizer A 100% python file organizer. Keep your computer always organized! To run the project, just clone the folder and run the installation
 3 Dec 2, 2022
3 Dec 2, 2022
![[CVPR 2022] Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels](https://github.com/Haochen-Wang409/U2PL/raw/main/img/pipeline.png)
[CVPR 2022] Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
Using Unreliable Pseudo Labels Official PyTorch implementation of Semi-Supervised Semantic Segmentation Using Unreliable Pseudo Labels, CVPR 2022. Ple
 268 Dec 24, 2022
268 Dec 24, 2022

Comparison-of-OCR (KerasOCR, PyTesseract,EasyOCR)
Optical Character Recognition OCR (Optical Character Recognition) is a technology that enables the conversion of document types such as scanned paper
21 Dec 25, 2022

A simple, high level, easy-to-use open source Computer Vision library for Python.
ZoomVision : Slicing Aid Detection A simple, high level, easy-to-use open source Computer Vision library for Python. Installation Installing dependenc
 2 Mar 4, 2022
2 Mar 4, 2022

Implementation of the state-of-the-art vision transformers with tensorflow
ViT Tensorflow This repository contains the tensorflow implementation of the state-of-the-art vision transformers (a category of computer vision model
 2 Mar 16, 2022
2 Mar 16, 2022

Image Lowpoly based on Centroid Voronoi Diagram via python-opencv and taichi
CVTLowpoly: Image Lowpoly via Centroid Voronoi Diagram Image Sharp Feature Extraction using Guide Filter's Local Linear Theory via opencv-python. The
 4 Jul 29, 2022
4 Jul 29, 2022
Udacity's CS101: Intro to Computer Science - Building a Search Engine
Udacity's CS101: Intro to Computer Science - Building a Search Engine All soluti
 0 Feb 26, 2022
0 Feb 26, 2022
Comp445 project - Data Communications & Computer Networks
COMP-445 Data Communications & Computer Networks Change Python version in Conda
 2 Oct 3, 2022
2 Oct 3, 2022

TargetAllDomainObjects - A python wrapper to run a command on against all users/computers/DCs of a Windows Domain
TargetAllDomainObjects A python wrapper to run a command on against all users/co
 19 Dec 13, 2022
19 Dec 13, 2022
Digitalizing-Prescription-Image - PIRDS - Prescription Image Recognition and Digitalizing System is a OCR make with Tensorflow
Digitalizing-Prescription-Image PIRDS - Prescription Image Recognition and Digit
 2 May 11, 2022
2 May 11, 2022

Python code for ICLR 2022 spotlight paper EViT: Expediting Vision Transformers via Token Reorganizations
Expediting Vision Transformers via Token Reorganizations This repository contain
 101 Dec 26, 2022
101 Dec 26, 2022

Breaching - Breaching privacy in federated learning scenarios for vision and text
Breaching - A Framework for Attacks against Privacy in Federated Learning This P
 139 Jan 3, 2023
139 Jan 3, 2023

HashNeRF-pytorch - Pure PyTorch Implementation of NVIDIA paper on Instant Training of Neural Graphics primitives
HashNeRF-pytorch Instant-NGP recently introduced a Multi-resolution Hash Encodin
 616 Jan 6, 2023
616 Jan 6, 2023

SafePicking: Learning Safe Object Extraction via Object-Level Mapping, ICRA 2022
SafePicking Learning Safe Object Extraction via Object-Level Mapping Kentaro Wad
 49 Oct 24, 2022
49 Oct 24, 2022
General Vision Benchmark, a project from OpenGVLab
Introduction We build GV-B(General Vision Benchmark) on Classification, Detection, Segmentation and Depth Estimation including 26 datasets for model e
 174 Dec 27, 2022
174 Dec 27, 2022

Social Distancing Detector
Computer vision has opened up a lot of opportunities to explore into AI domain that were earlier highly limited. Here is an application of haarcascade classifier and OpenCV to develop a social distancing violation detector. I am passing the algo through a video feed where it first detects people using 'haarcascade_fullbody.xml' classifier algo. OpenCV and some mathematical operations then allow us to make code the social distancing violation logic
 2 Jul 18, 2022
2 Jul 18, 2022

RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation
RIFE - Real-Time Intermediate Flow Estimation for Video Frame Interpolation YouTube | BiliBili 16X interpolation results from two input images: Introd
 28 Dec 9, 2022
28 Dec 9, 2022
Object detection evaluation metrics using Python.
Object detection evaluation metrics using Python.
 2 Sep 6, 2022
2 Sep 6, 2022
The visual framework is designed on the idea of module and implemented by mixin method
Visual Framework The visual framework is designed on the idea of module and implemented by mixin method. Its biggest feature is the mixins module whic
 9 Sep 19, 2022
9 Sep 19, 2022
JARVIS PC Assistant is an assisting program to make your computer easier to use
JARVIS-PC-Assistant JARVIS PC Assistant is an assisting program to make your computer easier to use Welcome to the J.A.R.V.I.S. PC Assistant help file
 2 Dec 2, 2022
2 Dec 2, 2022

DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers
DALL-Eval: Probing the Reasoning Skills and Social Biases of Text-to-Image Generative Transformers Authors: Jaemin Cho, Abhay Zala, and Mohit Bansal (
 36 Feb 13, 2022
36 Feb 13, 2022

Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
Official repository of OFA. Paper: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework
1.4k Jan 8, 2023

CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors In order to facilitate the res
 11 Dec 12, 2022
11 Dec 12, 2022
Interact remotely with the computer using Python and MQTT protocol 💻
Comandos_Remotos Interagir remotamento com o computador através do Python e protocolo MQTT. 💻 Status: em desenvolvimento 🚦 Objetivo: Interagir com o
 6 May 10, 2022
6 May 10, 2022
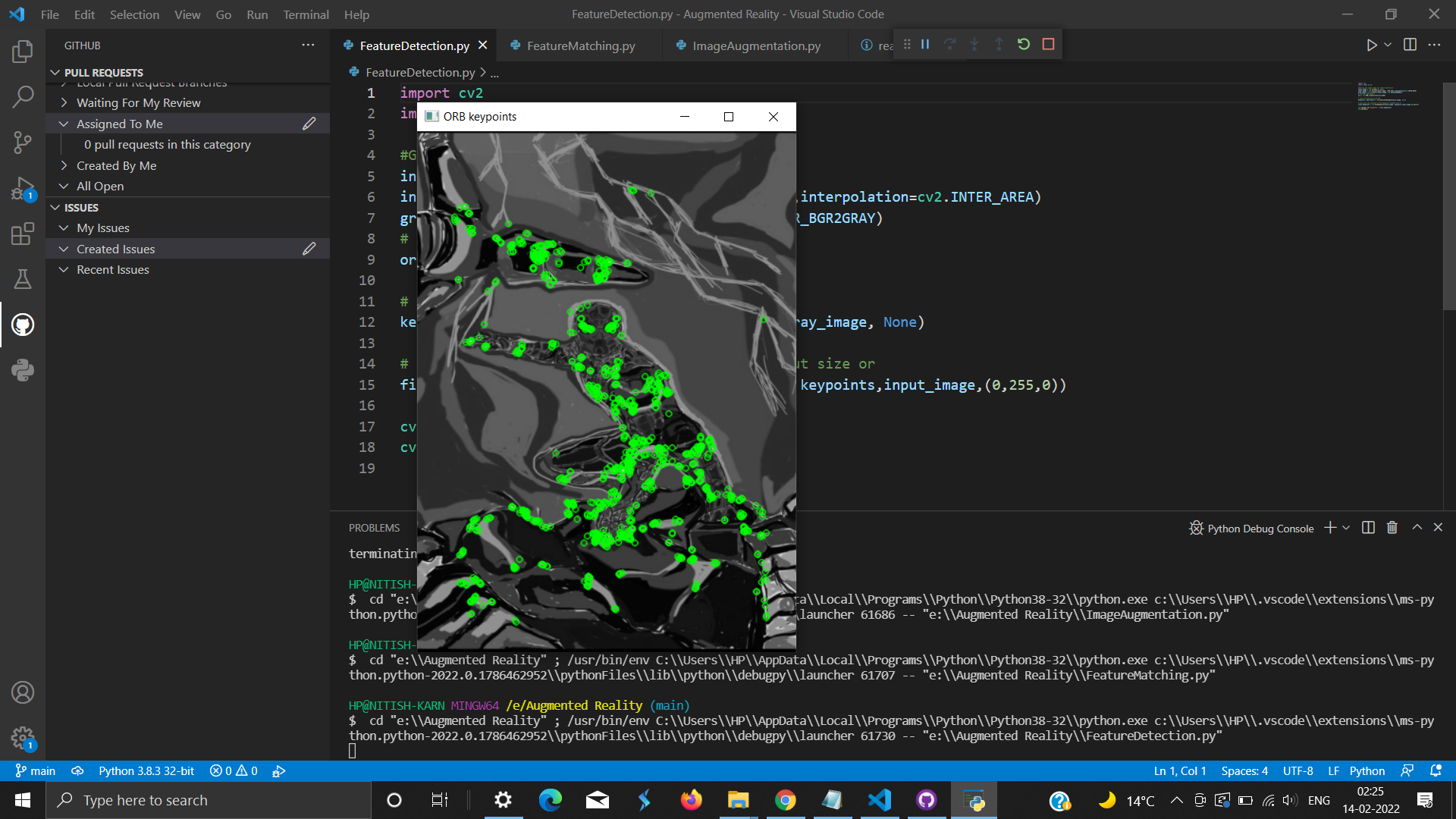
Using Opencv ,based on Augmental Reality(AR) and will show the feature matching of image and then by finding its matching
Using Opencv ,this project is based on Augmental Reality(AR) and will show the feature matching of image and then by finding its matching ,it will just mask that image . This project ,if used in cctv then it will detect black listed people if mentioned properly with their images.
 1 Feb 13, 2022
1 Feb 13, 2022

An interactive document scanner built in Python using OpenCV
The scanner takes a poorly scanned image, finds the corners of the document, applies the perspective transformation to get a top-down view of the document, sharpens the image, and applies an adaptive color threshold to clean up the image.
 1 Feb 12, 2022
1 Feb 12, 2022

Memory Defense: More Robust Classificationvia a Memory-Masking Autoencoder
Memory Defense: More Robust Classificationvia a Memory-Masking Autoencoder Authors: - Eashan Adhikarla - Dan Luo - Dr. Brian D. Davison Abstract Many
 4 Dec 25, 2022
4 Dec 25, 2022

Open-Source board for converting RaspberryPI to Brain-computer interface
The easiest way to the neuroscience world with the shield for RaspberryPi - PIEEG (website). Open-source. Crowdsupply This project is the result of se
 436 Jan 1, 2023
436 Jan 1, 2023

A lane detection integrated Real-time Instance Segmentation based on YOLACT (You Only Look At CoefficienTs)
Real-time Instance Segmentation and Lane Detection This is a lane detection integrated Real-time Instance Segmentation based on YOLACT (You Only Look
 4 Dec 30, 2022
4 Dec 30, 2022
Uses OpenCV and Python Code to detect a face on the screen
Simple-Face-Detection This code uses OpenCV and Python Code to detect a face on the screen. This serves as an example program. Important prerequisites
 1 Feb 12, 2022
1 Feb 12, 2022
PyTorch implementation of DD3D: Is Pseudo-Lidar needed for Monocular 3D Object detection?
PyTorch implementation of DD3D: Is Pseudo-Lidar needed for Monocular 3D Object detection? (ICCV 2021), Dennis Park*, Rares Ambrus*, Vitor Guizilini, Jie Li, and Adrien Gaidon.
 364 Dec 27, 2022
364 Dec 27, 2022