2602 Repositories
Python Data-Science-45min-Intros Libraries
Flexible time series feature extraction & processing
tsflex is a toolkit for flexible time series processing & feature extraction, that is efficient and makes few assumptions about sequence data. Useful
 206 Dec 28, 2022
206 Dec 28, 2022

DuBE: Duple-balanced Ensemble Learning from Skewed Data
DuBE: Duple-balanced Ensemble Learning from Skewed Data "Towards Inter-class and Intra-class Imbalance in Class-imbalanced Learning" (IEEE ICDE 2022 S
 6 Nov 12, 2022
6 Nov 12, 2022

Fast mesh denoising with data driven normal filtering using deep variational autoencoders
Fast mesh denoising with data driven normal filtering using deep variational autoencoders This is an implementation for the paper entitled "Fast mesh
 9 Dec 2, 2022
9 Dec 2, 2022

IMBENS: class-imbalanced ensemble learning in Python.
IMBENS: class-imbalanced ensemble learning in Python. Links: [Documentation] [Gallery] [PyPI] [Changelog] [Source] [Download] [知乎/Zhihu] [中文README] [a
 176 Jan 4, 2023
176 Jan 4, 2023
Research code for the paper "Variational Gibbs inference for statistical estimation from incomplete data".
Variational Gibbs inference (VGI) This repository contains the research code for Simkus, V., Rhodes, B., Gutmann, M. U., 2021. Variational Gibbs infer
 1 Apr 8, 2022
1 Apr 8, 2022

Deep Learning Emotion decoding using EEG data from Autism individuals
Deep Learning Emotion decoding using EEG data from Autism individuals This repository includes the python and matlab codes using for processing EEG 2D
 12 Dec 8, 2022
12 Dec 8, 2022

This repository contains all code and data for the Inside Out Visual Place Recognition task
Inside Out Visual Place Recognition This repository contains code and instructions to reproduce the results for the Inside Out Visual Place Recognitio
 15 May 21, 2022
15 May 21, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
Tool for running a high throughput data ingestion/transformation workload with MongoDB
Mongo Mangler The mongo-mangler tool is a lightweight Python utility, which you can run from a low-powered machine to execute a high throughput data i
 9 Jan 2, 2023
9 Jan 2, 2023
Gathering data of likes on Tinder within the past 7 days
tinder_likes_data Gathering data of Likes Sent on Tinder within the past 7 days. Versions November 25th, 2021 - Functionality to get the name and age
 12 Jan 5, 2023
12 Jan 5, 2023
Empresas do Brasil (CNPJs)
Biblioteca em Python que coleta informações cadastrais de empresas do Brasil (CNPJ) obtidas de fontes oficiais (Receita Federal) e exporta para um formato legível por humanos (CSV ou JSON).
 8 Aug 17, 2022
8 Aug 17, 2022
E-Commerce recommender demo with real-time data and a graph database
🔍 E-Commerce recommender demo 🔍 This is a simple stream setup that uses Memgraph to ingest real-time data from a simulated online store. Data is str
 3 Feb 23, 2022
3 Feb 23, 2022
Redis OM Python makes it easy to model Redis data in your Python applications.
Object mapping, and more, for Redis and Python Redis OM Python makes it easy to model Redis data in your Python applications. Redis OM Python | Redis
 568 Jan 2, 2023
568 Jan 2, 2023

A procedural Blender pipeline for photorealistic training image generation
BlenderProc2 A procedural Blender pipeline for photorealistic rendering. Documentation | Tutorials | Examples | ArXiv paper | Workshop paper Features
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
Open source platform for Data Science Management automation
Hydrosphere examples This repo contains demo scenarios and pre-trained models to show Hydrosphere capabilities. Data and artifacts management Some mod
 6 Aug 10, 2021
6 Aug 10, 2021
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate.
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate. Website • Key Features • How To Use • Docs •
 21.1k Jan 8, 2023
21.1k Jan 8, 2023
Learning from graph data using Keras
Steps to run = Download the cora dataset from this link : https://linqs.soe.ucsc.edu/data unzip the files in the folder input/cora cd code python eda
 64 Nov 16, 2022
64 Nov 16, 2022
Data pipelines built with polars
valves Warning: the project is very much work in progress. Valves is a collection of functions for your data .pipe()-lines. This project aimes to host
 14 Jan 3, 2023
14 Jan 3, 2023

CinnaMon is a Python library which offers a number of tools to detect, explain, and correct data drift in a machine learning system
CinnaMon is a Python library which offers a number of tools to detect, explain, and correct data drift in a machine learning system
 67 Dec 28, 2022
67 Dec 28, 2022
🗂️ 🔍 Geospatial Data Management and Search API - Django Apps
Geospatial Data API in Django Resonant GeoData (RGD) is a series of Django applications well suited for cataloging and searching annotated geospatial
 53 Nov 1, 2022
53 Nov 1, 2022
A package designed to scrape data from Yahoo Finance.
yahoostock A package designed to scrape data from Yahoo Finance. Installation The most simple installation method is through PIP. pip install yahoosto
 2 May 28, 2022
2 May 28, 2022
An index of algorithms for learning causality with data
awesome-causality-algorithms An index of algorithms for learning causality with data. Please cite our survey paper if this index is helpful. @article{
 2.3k Jan 8, 2023
2.3k Jan 8, 2023
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
Qlib is an AI-oriented quantitative investment platform
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment.
10.1k Dec 30, 2022
Automatically download the cwru data set, and then divide it into training data set and test data set
Automatically download the cwru data set, and then divide it into training data set and test data set.自动下载cwru数据集,然后分训练数据集和测试数据集
 6 Jun 27, 2022
6 Jun 27, 2022

Improve current data preprocessing for FTM's WOB data to analyze Shell and Dutch Governmental contacts.
We're the hackathon leftovers, but we are Too Good To Go ;-). A repo by Lukas Schubotz and Raymon van Dinter. We aim to improve current data preprocessing for FTM's WOB data to analyze Shell and Dutch Governmental contacts.
 5 Dec 9, 2021
5 Dec 9, 2021
Project under the certification "Data Analysis with Python" on FreeCodeCamp
Sea Level Predictor Assignment You will anaylize a dataset of the global average sea level change since 1880. You will use the data to predict the sea
 3 Jan 31, 2022
3 Jan 31, 2022
Tools for the analysis, simulation, and presentation of Lorentz TEM data.
ltempy ltempy is a set of tools for Lorentz TEM data analysis, simulation, and presentation. Features Single Image Transport of Intensity Equation (SI
 1 Dec 26, 2022
1 Dec 26, 2022
The FIRST GANs-based omics-to-omics translation framework
OmiTrans Please also have a look at our multi-omics multi-task DL freamwork 👀 : OmiEmbed The FIRST GANs-based omics-to-omics translation framework Xi
 6 Dec 14, 2022
6 Dec 14, 2022
Finds, downloads, parses, and standardizes public bikeshare data into a standard pandas dataframe format
Finds, downloads, parses, and standardizes public bikeshare data into a standard pandas dataframe format.
 2 Dec 1, 2021
2 Dec 1, 2021
NYCT-GTFS - Real-time NYC subway data parsing for humans
NYCT-GTFS - Real-time NYC subway data parsing for humans This python library provides a human-friendly, native python interface for dealing with the N
 37 Dec 27, 2022
37 Dec 27, 2022
Data and codes for ACL 2021 paper: Towards Emotional Support Dialog Systems
Emotional-Support-Conversation Copyright © 2021 CoAI Group, Tsinghua University. All rights reserved. Data and codes are for academic research use onl
 126 Dec 21, 2022
126 Dec 21, 2022
Gathers data and displays metrics related to climate change and resource depletion on a PowerBI report.
Apocalypse Status Dashboard Purpose Climate change and resource depletion are grave long-term dangers. The code in this repository will pull data from
 1 Nov 12, 2021
1 Nov 12, 2021
Compilation of resources and insights that helped me on my journey to data scientist
Compilation of resources and insights that helped me on my journey to data scientist
 1.5k Jan 2, 2023
1.5k Jan 2, 2023

A collection of online resources to help you on your Tech journey.
Everything Tech Resources & Projects About The Project Coming from an engineering background and looking to up skill yourself on a new field can be di
 396 Dec 31, 2022
396 Dec 31, 2022

This is Assignment1 code for the Web Data Processing System.
This is a Python program to Entity Linking by processing WARC files. We recognize entities from web pages and link them to a Knowledge Base(Wikidata).
 3 Dec 4, 2022
3 Dec 4, 2022
In the case of your data having only 1 channel while want to use timm models
timm_custom Description In the case of your data having only 1 channel while want to use timm models (with or without pretrained weights), run the fol
 2 Nov 26, 2021
2 Nov 26, 2021
Minimum Bounding Box of Geospatial data
BBOX Problem definition: The spatial data users often are required to obtain the coordinates of the minimum bounding box of vector and raster data in
 1 Sep 8, 2022
1 Sep 8, 2022
A logical, reasonably standardized, but flexible project structure for doing and sharing data science work.
Cookiecutter Data Science A logical, reasonably standardized, but flexible project structure for doing and sharing data science work. Project homepage
 6.4k Jan 2, 2023
6.4k Jan 2, 2023
Advanced Pandas Vault — Utilities, Functions and Snippets (by @firmai).
PandasVault — Advanced Pandas Functions and Code Snippets The only Pandas utility package you would ever need. It has no exotic external dependencies
 374 Jan 7, 2023
374 Jan 7, 2023

PandaPy has the speed of NumPy and the usability of Pandas 10x to 50x faster (by @firmai)
PandaPy "I came across PandaPy last week and have already used it in my current project. It is a fascinating Python library with a lot of potential to
527 Jan 2, 2023
Automatically visualize your pandas dataframe via a single print! 📊 💡
A Python API for Intelligent Visual Discovery Lux is a Python library that facilitate fast and easy data exploration by automating the visualization a
 4.3k Dec 28, 2022
4.3k Dec 28, 2022
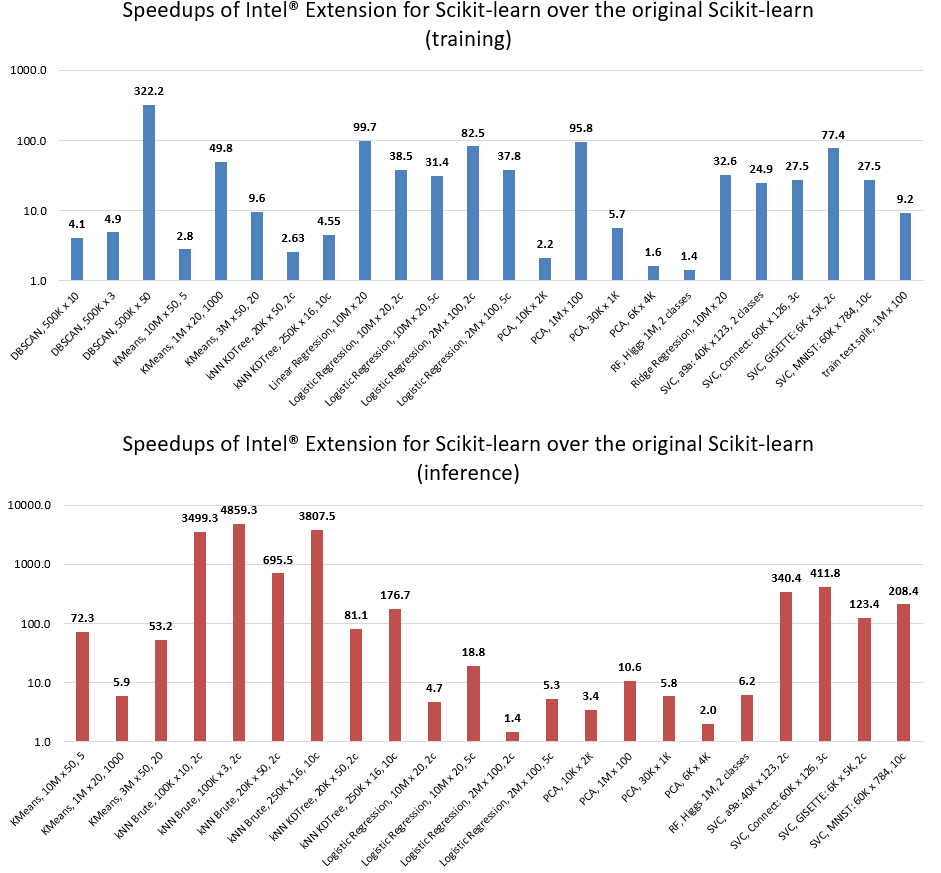
Intel(R) Extension for Scikit-learn is a seamless way to speed up your Scikit-learn application
Intel(R) Extension for Scikit-learn* Installation | Documentation | Examples | Support | FAQ With Intel(R) Extension for Scikit-learn you can accelera
 858 Dec 25, 2022
858 Dec 25, 2022
Finding project directories in Python (data science) projects, just like there R rprojroot and here packages
Find relative paths from a project root directory Finding project directories in Python (data science) projects, just like there R here and rprojroot
 102 Nov 16, 2022
102 Nov 16, 2022
Intake is a lightweight package for finding, investigating, loading and disseminating data.
Intake: A general interface for loading data Intake is a lightweight set of tools for loading and sharing data in data science projects. Intake helps
 851 Jan 1, 2023
851 Jan 1, 2023
Mars is a tensor-based unified framework for large-scale data computation which scales numpy, pandas, scikit-learn and Python functions.
Mars is a tensor-based unified framework for large-scale data computation which scales numpy, pandas, scikit-learn and many other libraries. Documenta
 2.5k Jan 7, 2023
2.5k Jan 7, 2023

A columnar data container that can be compressed.
Unmaintained Package Notice Unfortunately, and due to lack of resources, the Blosc Development Team is unable to maintain this package anymore. During
 944 Dec 9, 2022
944 Dec 9, 2022
Metrics to evaluate quality and efficacy of synthetic datasets.
An Open Source Project from the Data to AI Lab, at MIT Metrics for Synthetic Data Generation Projects Website: https://sdv.dev Documentation: https://
 129 Jan 3, 2023
129 Jan 3, 2023
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
 880 Jan 7, 2023
880 Jan 7, 2023

A DSL for data-driven computational pipelines
"Dataflow variables are spectacularly expressive in concurrent programming" Henri E. Bal , Jennifer G. Steiner , Andrew S. Tanenbaum Quick overview Ne
 1.9k Jan 3, 2023
1.9k Jan 3, 2023

Integrate bus data from a variety of sources (batch processing and real time processing).
Purpose: This is integrate bus data from a variety of sources such as: csv, json api, sensor data ... into Relational Database (batch processing and r
 1 Nov 25, 2021
1 Nov 25, 2021
Python script for diving image data to train test and val
dataset-division-to-train-val-test-python python script for dividing image data to train test and val If you have an image dataset in the following st
 1 Nov 14, 2022
1 Nov 14, 2022
Data repo for one-among.us
Our Data Data repo for one-among.us File Structure Directory /people/userid/: Data for a specific person info.json5: Profile information page.md: Pr
 55 Dec 30, 2022
55 Dec 30, 2022
Pydantic based mock data generation
This library offers powerful mock data generation capabilities for pydantic based models. It can also be used with other libraries that use pydantic as a foundation, for example SQLModel, Beanie and ormar.
 396 Dec 28, 2022
396 Dec 28, 2022

Maze generator and solver with python
Procedural-Maze-Generator-Algorithms Check out my youtube channel : Auctux Ressources Thanks to Jamis Buck Book : Mazes for programmers Requirements P
 19 Dec 7, 2022
19 Dec 7, 2022

Helping you manage your data science projects sanely.
PyDS CLI Helping you manage your data science projects sanely. Requirements Anaconda/Miniconda/Miniforge/Mambaforge (Mambaforge recommended!) git on y
 16 Apr 25, 2022
16 Apr 25, 2022

Source files for the data lake demo video using the AWS TICKIT database
Data Lake Demo Source code for video demonstration detailed in the post, Building a Simple Data Lake on AWS . Build a simple data lake on AWS using a
 97 Dec 23, 2022
97 Dec 23, 2022

The official PyTorch code for NeurIPS 2021 ML4AD Paper, "Does Thermal data make the detection systems more reliable?"
MultiModal-Collaborative (MMC) Learning Framework for integrating RGB and Thermal spectral modalities This is the official code for NeurIPS 2021 Machi
 5 Nov 25, 2021
5 Nov 25, 2021

This repository contains part of the code used to make the images visible in the article "How does an AI Imagine the Universe?" published on Towards Data Science.
Generative Adversarial Network - Generating Universe This repository contains part of the code used to make the images visible in the article "How doe
 9 Dec 18, 2022
9 Dec 18, 2022
eBay's TSV Utilities: Command line tools for large, tabular data files. Filtering, statistics, sampling, joins and more.
Command line utilities for tabular data files This is a set of command line utilities for manipulating large tabular data files. Files of numeric and
 1.4k Jan 9, 2023
1.4k Jan 9, 2023

Desafio proposto pela IGTI em seu bootcamp de Cloud Data Engineer
Desafio Modulo 4 - Cloud Data Engineer Bootcamp - IGTI Objetivos Criar infraestrutura como código Utuilizando um cluster Kubernetes na Azure Ingestão
 4 Jan 23, 2022
4 Jan 23, 2022

Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data.
Web scraped S&P 500 Data from Wikipedia using Pandas and performed Exploratory Data Analysis on the data. Then used Yahoo Finance to get the related stock data and displayed them in the form of charts.
 3 Sep 9, 2022
3 Sep 9, 2022
The fastai book, published as Jupyter Notebooks
English / Spanish / Korean / Chinese / Bengali / Indonesian The fastai book These notebooks cover an introduction to deep learning, fastai, and PyTorc
 17k Jan 7, 2023
17k Jan 7, 2023

Extension to fastai for volumetric medical data
FAIMED 3D use fastai to quickly train fully three-dimensional models on radiological data Classification from faimed3d.all import * Load data in vari
 26 Aug 22, 2022
26 Aug 22, 2022

Compare MLOps Platforms. Breakdowns of SageMaker, VertexAI, AzureML, Dataiku, Databricks, h2o, kubeflow, mlflow...
Compare MLOps Platforms. Breakdowns of SageMaker, VertexAI, AzureML, Dataiku, Databricks, h2o, kubeflow, mlflow...
 318 Jan 2, 2023
318 Jan 2, 2023

Graph Convolutional Neural Networks with Data-driven Graph Filter (GCNN-DDGF)
Graph Convolutional Gated Recurrent Neural Network (GCGRNN) Improved from Graph Convolutional Neural Networks with Data-driven Graph Filter (GCNN-DDGF
 21 Dec 18, 2022
21 Dec 18, 2022
Project5 Data processing system
Project5-Data-processing-system User just needed to copy both these file to a folder and open Project5.py using cmd or using any python ide. It is to
 1 Nov 23, 2021
1 Nov 23, 2021
Epidemiology analysis package
zEpid zEpid is an epidemiology analysis package, providing easy to use tools for epidemiologists coding in Python 3.5+. The purpose of this library is
 111 Jan 8, 2023
111 Jan 8, 2023
Explorative Data Analysis Guidelines
Explorative Data Analysis Get data into a usable format! Find out if the following predictive modeling phase will be successful! Combine everything in
 18 Dec 26, 2022
18 Dec 26, 2022
cleanlab is the data-centric ML ops package for machine learning with noisy labels.
cleanlab is the data-centric ML ops package for machine learning with noisy labels. cleanlab cleans labels and supports finding, quantifying, and lear
 51 Nov 28, 2022
51 Nov 28, 2022
Data imputations library to preprocess datasets with missing data
Impyute is a library of missing data imputation algorithms. This library was designed to be super lightweight, here's a sneak peak at what impyute can do.
 329 Dec 5, 2022
329 Dec 5, 2022
Kaggler is a Python package for lightweight online machine learning algorithms and utility functions for ETL and data analysis.
Kaggler is a Python package for lightweight online machine learning algorithms and utility functions for ETL and data analysis. It is distributed under the MIT License.
 720 Dec 25, 2022
720 Dec 25, 2022
Skoot is a lightweight python library of machine learning transformer classes that interact with scikit-learn and pandas.
Skoot is a lightweight python library of machine learning transformer classes that interact with scikit-learn and pandas. Its objective is to ex
 54 Aug 20, 2022
54 Aug 20, 2022
dirty_cat is a Python module for machine-learning on dirty categorical variables.
dirty_cat dirty_cat is a Python module for machine-learning on dirty categorical variables.
 637 Dec 29, 2022
637 Dec 29, 2022

Pypeln is a simple yet powerful Python library for creating concurrent data pipelines.
Pypeln Pypeln (pronounced as "pypeline") is a simple yet powerful Python library for creating concurrent data pipelines. Main Features Simple: Pypeln
 1.4k Dec 31, 2022
1.4k Dec 31, 2022

A Guide for Feature Engineering and Feature Selection, with implementations and examples in Python.
Feature Engineering & Feature Selection A comprehensive guide [pdf] [markdown] for Feature Engineering and Feature Selection, with implementations and
 968 Dec 29, 2022
968 Dec 29, 2022
apricot implements submodular optimization for the purpose of selecting subsets of massive data sets to train machine learning models quickly.
Please consider citing the manuscript if you use apricot in your academic work! You can find more thorough documentation here. apricot implements subm
 457 Dec 20, 2022
457 Dec 20, 2022
MCML is a toolkit for semi-supervised dimensionality reduction and quantitative analysis of Multi-Class, Multi-Label data
MCML is a toolkit for semi-supervised dimensionality reduction and quantitative analysis of Multi-Class, Multi-Label data. We demonstrate its use
 26 Nov 29, 2022
26 Nov 29, 2022
Dump Data from FTDI Serial Port to Binary File on MacOS
Dump Data from FTDI Serial Port to Binary File on MacOS
 1 Nov 24, 2021
1 Nov 24, 2021

Python+Numpy+OpenGL: fast, scalable and beautiful scientific visualization
Python+Numpy+OpenGL: fast, scalable and beautiful scientific visualization
 1.1k Jan 5, 2023
1.1k Jan 5, 2023
Crypto Stats and Tweets Data Pipeline using Airflow
Crypto Stats and Tweets Data Pipeline using Airflow Introduction Project Overview This project was brought upon through Udacity's nanodegree program.
 1 Nov 24, 2021
1 Nov 24, 2021
A package to predict protein inter-residue geometries from sequence data
trRosetta This package is a part of trRosetta protein structure prediction protocol developed in: Improved protein structure prediction using predicte
 185 Jan 7, 2023
185 Jan 7, 2023
An optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models.
An optimization and data collection toolbox for convenient and fast prototyping of computationally expensive models. Hyperactive: is very easy to lear
 422 Jan 4, 2023
422 Jan 4, 2023
68 keypoint annotations for COFW test data
68 keypoint annotations for COFW test data This repository contains manually annotated 68 keypoints for COFW test data (original annotation of CFOW da
 31 Dec 6, 2022
31 Dec 6, 2022
Centralized whale instance using github actions, sourcing metadata from bigquery-public-data.
Whale Demo Instance: Bigquery Public Data This is a fully-functioning demo instance of the whale data catalog, actively scraping data from Bigquery's
 17 Dec 14, 2022
17 Dec 14, 2022
Fast Fourier Transform-accelerated Interpolation-based t-SNE (FIt-SNE)
FFT-accelerated Interpolation-based t-SNE (FIt-SNE) Introduction t-Stochastic Neighborhood Embedding (t-SNE) is a highly successful method for dimensi
 547 Dec 21, 2022
547 Dec 21, 2022
An interactive UMAP visualization of the MNIST data set.
Code for an interactive UMAP visualization of the MNIST data set. Demo at https://grantcuster.github.io/umap-explorer/. You can read more about the de
 70 Dec 27, 2022
70 Dec 27, 2022
A high-performance topological machine learning toolbox in Python
giotto-tda is a high-performance topological machine learning toolbox in Python built on top of scikit-learn and is distributed under the G
 632 Dec 29, 2022
632 Dec 29, 2022
Single-Cell Analysis in Python. Scales to 1M cells.
Scanpy – Single-Cell Analysis in Python Scanpy is a scalable toolkit for analyzing single-cell gene expression data built jointly with anndata. It inc
 1.4k Jan 5, 2023
1.4k Jan 5, 2023

3D rendered visualization of the austrian monuments registry
Visualization of the Austrian Monuments Visualization of the monument landscape of the austrian monuments registry (Bundesdenkmalamt Denkmalverzeichni
 3 Oct 24, 2019
3 Oct 24, 2019
Falcon: Interactive Visual Analysis for Big Data
Falcon: Interactive Visual Analysis for Big Data Crossfilter millions of records without latencies. This project is work in progress and not documente
 803 Dec 27, 2022
803 Dec 27, 2022

A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Torch and Numpy.
Visdom A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Python. Overview Concepts Setup Usage API To
 9.4k Jan 7, 2023
9.4k Jan 7, 2023
Complex heatmaps are efficient to visualize associations between different sources of data sets and reveal potential patterns.
Make Complex Heatmaps Complex heatmaps are efficient to visualize associations between different sources of data sets and reveal potential patterns. H
 973 Jan 9, 2023
973 Jan 9, 2023
A set of useful perceptually uniform colormaps for plotting scientific data
Colorcet: Collection of perceptually uniform colormaps Build Status Coverage Latest dev release Latest release Docs What is it? Colorcet is a collecti
 590 Dec 31, 2022
590 Dec 31, 2022

Streamlit — The fastest way to build data apps in Python
Welcome to Streamlit 👋 The fastest way to build and share data apps. Streamlit lets you turn data scripts into sharable web apps in minutes, not week
 22k Jan 6, 2023
22k Jan 6, 2023
The purpose of this project is to share knowledge on how awesome Streamlit is and can be
Awesome Streamlit The fastest way to build Awesome Tools and Apps! Powered by Python! The purpose of this project is to share knowledge on how Awesome
 1.5k Jan 7, 2023
1.5k Jan 7, 2023
A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Torch and Numpy.
Visdom A flexible tool for creating, organizing, and sharing visualizations of live, rich data. Supports Python. Overview Concepts Setup Usage API To
9.4k Jan 7, 2023
Select, weight and analyze complex sample data
Sample Analytics In large-scale surveys, often complex random mechanisms are used to select samples. Estimates derived from such samples must reflect
 37 Dec 15, 2022
37 Dec 15, 2022
Datashader is a data rasterization pipeline for automating the process of creating meaningful representations of large amounts of data.
Datashader is a data rasterization pipeline for automating the process of creating meaningful representations of large amounts of data.
2.9k Jan 6, 2023
PyCaret is an open-source, low-code machine learning library in Python that automates machine learning workflows.
An open-source, low-code machine learning library in Python 🚀 Version 2.3.5 out now! Check out the release notes here. Official • Docs • Install • Tu
 6.7k Jan 8, 2023
6.7k Jan 8, 2023