1022 Repositories
Python Speech-recognition Libraries

Open-Source Toolkit for End-to-End Speech Recognition leveraging PyTorch-Lightning and Hydra.
OpenSpeech provides reference implementations of various ASR modeling papers and three languages recipe to perform tasks on automatic speech recogniti
 86 Jun 11, 2021
86 Jun 11, 2021

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
 142 Jan 6, 2023
142 Jan 6, 2023
Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. This Neural Network (NN) model recognizes the text contained in the images of segmented words.
Handwritten-Text-Recognition Handwritten Text Recognition (HTR) system implemented with TensorFlow (TF) and trained on the IAM off-line HTR dataset. T
 27 Jan 8, 2023
27 Jan 8, 2023
Open-Source Toolkit for End-to-End Speech Recognition leveraging PyTorch-Lightning and Hydra.
OpenSpeech provides reference implementations of various ASR modeling papers and three languages recipe to perform tasks on automatic speech recogniti
26 Dec 14, 2022

Official PyTorch implementation of "Adversarial Reciprocal Points Learning for Open Set Recognition"
Adversarial Reciprocal Points Learning for Open Set Recognition Official PyTorch implementation of "Adversarial Reciprocal Points Learning for Open Se
 78 Dec 28, 2022
78 Dec 28, 2022
Synthetic Humans for Action Recognition, IJCV 2021
SURREACT: Synthetic Humans for Action Recognition from Unseen Viewpoints Gül Varol, Ivan Laptev and Cordelia Schmid, Andrew Zisserman, Synthetic Human
 59 Dec 14, 2022
59 Dec 14, 2022
Ecommerce product title recognition package
revizor This package solves task of splitting product title string into components, like type, brand, model and article (or SKU or product code or you
 16 Mar 3, 2022
16 Mar 3, 2022

Pytorch Implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension)
DiffSinger - PyTorch Implementation PyTorch implementation of DiffSinger: Diffusion Acoustic Model for Singing Voice Synthesis (TTS Extension). Status
152 Jan 2, 2023

An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicity.
Fast Face Classification (F²C) This is the code of our paper An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicit
 33 Jun 27, 2021
33 Jun 27, 2021
Chinese clinical named entity recognition using pre-trained BERT model
Chinese clinical named entity recognition (CNER) using pre-trained BERT model Introduction Code for paper Chinese clinical named entity recognition wi
 109 Dec 14, 2022
109 Dec 14, 2022

This is the research repository for Vid2Doppler: Synthesizing Doppler Radar Data from Videos for Training Privacy-Preserving Activity Recognition.
Vid2Doppler: Synthesizing Doppler Radar Data from Videos for Training Privacy-Preserving Activity Recognition This is the research repository for Vid2
 26 Dec 24, 2022
26 Dec 24, 2022

Anonymize BLM Protest Images
Anonymize BLM Protest Images This repository automates @BLMPrivacyBot, a Twitter bot that shows the anonymized images to help keep protesters safe. Us
 40 Oct 13, 2022
40 Oct 13, 2022
This is an official implementation for "ResT: An Efficient Transformer for Visual Recognition".
ResT By Qing-Long Zhang and Yu-Bin Yang [State Key Laboratory for Novel Software Technology at Nanjing University] This repo is the official implement
 222 Dec 13, 2022
222 Dec 13, 2022
A PyTorch implementation of paper "Learning Shared Semantic Space for Speech-to-Text Translation", ACL (Findings) 2021
Chimera: Learning Shared Semantic Space for Speech-to-Text Translation This is a Pytorch implementation for the "Chimera" paper Learning Shared Semant
 43 Dec 28, 2022
43 Dec 28, 2022
Rest API Written In Python To Classify NSFW Images.
✨ NSFW Classifier API ✨ Rest API Written In Python To Classify NSFW Images. Fastest Solution If you don't want to selfhost it, there's already an inst
 23 Dec 30, 2022
23 Dec 30, 2022
Simple, hackable offline speech to text - using the VOSK-API.
Nerd Dictation Offline Speech to Text for Desktop Linux. This is a utility that provides simple access speech to text for using in Linux without being
 844 Jan 7, 2023
844 Jan 7, 2023
Conformer: Local Features Coupling Global Representations for Visual Recognition
Conformer: Local Features Coupling Global Representations for Visual Recognition (arxiv) This repository is built upon DeiT and timm Usage First, inst
 378 Jan 8, 2023
378 Jan 8, 2023

Official codes for the paper "Learning Hierarchical Discrete Linguistic Units from Visually-Grounded Speech"
ResDAVEnet-VQ Official PyTorch implementation of Learning Hierarchical Discrete Linguistic Units from Visually-Grounded Speech What is in this repo? M
 21 Aug 23, 2022
21 Aug 23, 2022

PyTorch code of my ICDAR 2021 paper Vision Transformer for Fast and Efficient Scene Text Recognition (ViTSTR)
Vision Transformer for Fast and Efficient Scene Text Recognition (ICDAR 2021) ViTSTR is a simple single-stage model that uses a pre-trained Vision Tra
 198 Dec 27, 2022
198 Dec 27, 2022

ERISHA is a mulitilingual multispeaker expressive speech synthesis framework. It can transfer the expressivity to the speaker's voice for which no expressive speech corpus is available.
ERISHA: Multilingual Multispeaker Expressive Text-to-Speech Library ERISHA is a multilingual multispeaker expressive speech synthesis framework. It ca
 43 Nov 27, 2022
43 Nov 27, 2022

Face Transformer for Recognition
Face-Transformer This is the code of Face Transformer for Recognition (https://arxiv.org/abs/2103.14803v2). Recently there has been great interests of
 153 Nov 30, 2022
153 Nov 30, 2022

voice2json is a collection of command-line tools for offline speech/intent recognition on Linux
Command-line tools for speech and intent recognition on Linux
 988 Jan 4, 2023
988 Jan 4, 2023

Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Parallel Tacotron2 Pytorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
170 Dec 27, 2022
Python codes for Lite Audio-Visual Speech Enhancement.
Lite Audio-Visual Speech Enhancement (Interspeech 2020) Introduction This is the PyTorch implementation of Lite Audio-Visual Speech Enhancement (LAVSE
 85 Dec 1, 2022
85 Dec 1, 2022

Keeping it safe - AI Based COVID-19 Tracker using Deep Learning and facial recognition
Keeping it safe - AI Based COVID-19 Tracker using Deep Learning and facial recognition
 15 Jun 17, 2021
15 Jun 17, 2021

EQFace: An implementation of EQFace: A Simple Explicit Quality Network for Face Recognition
EQFace: A Simple Explicit Quality Network for Face Recognition The first face recognition network that generates explicit face quality online.
 141 Dec 31, 2022
141 Dec 31, 2022
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
RepMLP RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition Released the code of RepMLP together with an example o
 260 Jan 3, 2023
260 Jan 3, 2023
TraND: Transferable Neighborhood Discovery for Unsupervised Cross-domain Gait Recognition.
TraND This is the code for the paper "Jinkai Zheng, Xinchen Liu, Chenggang Yan, Jiyong Zhang, Wu Liu, Xiaoping Zhang and Tao Mei: TraND: Transferable
 32 Apr 4, 2022
32 Apr 4, 2022

Radar-to-Lidar: Heterogeneous Place Recognition via Joint Learning
radar-to-lidar-place-recognition This page is the coder of a pre-print, implemented by PyTorch. If you have some questions on this project, please fee
 37 Oct 9, 2022
37 Oct 9, 2022
A list of papers about point cloud based place recognition, also known as loop closure detection in SLAM (processing)
A list of papers about point cloud based place recognition, also known as loop closure detection in SLAM (processing)
 17 May 16, 2021
17 May 16, 2021

Text to speech is a process to convert any text into voice. Text to speech project takes words on digital devices and convert them into audio. Here I have used Google-text-to-speech library popularly known as gTTS library to convert text file to .mp3 file. Hope you like my project!
Text to speech (using Python) Text to speech is a process to convert any text into voice. Text to speech project takes words on digital devices and co
 19 Jun 30, 2022
19 Jun 30, 2022

Face Detection & Age Gender & Expression & Recognition
Face Detection & Age Gender & Expression & Recognition
 188 Dec 28, 2022
188 Dec 28, 2022
A fast Text-to-Speech (TTS) model. Work well for English, Mandarin/Chinese, Japanese, Korean, Russian and Tibetan (so far). 快速语音合成模型,适用于英语、普通话/中文、日语、韩语、俄语和藏语(当前已测试)。
简体中文 | English 并行语音合成 [TOC] 新进展 2021/04/20 合并 wavegan 分支到 main 主分支,删除 wavegan 分支! 2021/04/13 创建 encoder 分支用于开发语音风格迁移模块! 2021/04/13 softdtw 分支 支持使用 Sof
 161 Dec 19, 2022
161 Dec 19, 2022
This repository describes our reproducible framework for assessing self-supervised representation learning from speech
LeBenchmark: a reproducible framework for assessing SSL from speech Self-Supervised Learning (SSL) using huge unlabeled data has been successfully exp
 49 Aug 24, 2022
49 Aug 24, 2022
Modular and extensible speech recognition library leveraging pytorch-lightning and hydra.
Lightning ASR Modular and extensible speech recognition library leveraging pytorch-lightning and hydra What is Lightning ASR • Installation • Get Star
40 Sep 19, 2022
Identify the emotion of multiple speakers in an Audio Segment
MevonAI - Speech Emotion Recognition
 111 Jan 7, 2023
111 Jan 7, 2023
Espresso: A Fast End-to-End Neural Speech Recognition Toolkit
Espresso Espresso is an open-source, modular, extensible end-to-end neural automatic speech recognition (ASR) toolkit based on the deep learning libra
 919 Jan 3, 2023
919 Jan 3, 2023
pytorch-kaldi is a project for developing state-of-the-art DNN/RNN hybrid speech recognition systems. The DNN part is managed by pytorch, while feature extraction, label computation, and decoding are performed with the kaldi toolkit.
The PyTorch-Kaldi Speech Recognition Toolkit PyTorch-Kaldi is an open-source repository for developing state-of-the-art DNN/HMM speech recognition sys
 2.3k Dec 27, 2022
2.3k Dec 27, 2022

Pytorch-Named-Entity-Recognition-with-BERT
BERT NER Use google BERT to do CoNLL-2003 NER ! Train model using Python and Inference using C++ ALBERT-TF2.0 BERT-NER-TENSORFLOW-2.0 BERT-SQuAD Requi
 1.1k Dec 25, 2022
1.1k Dec 25, 2022

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
 881 Jan 3, 2023
881 Jan 3, 2023
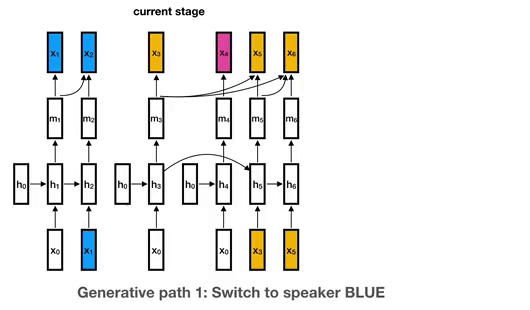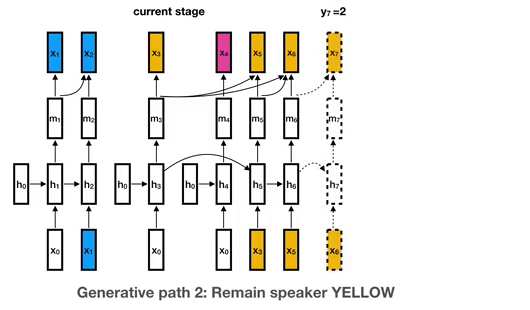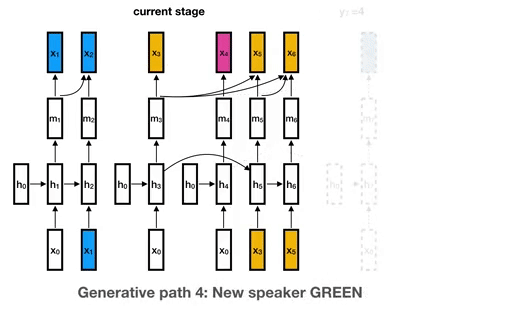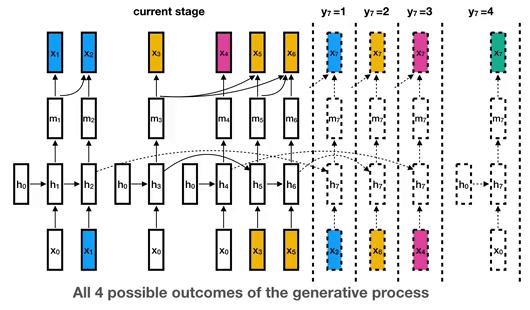
This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization.
UIS-RNN Overview This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm. UIS-RNN solves the problem of s
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.0.1 1.1.0 1.2.0 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 ubuntu18/python3.8/pip ubuntu18
 5.9k Jan 3, 2023
5.9k Jan 3, 2023
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
 2.2k Jan 9, 2023
2.2k Jan 9, 2023

Pytorch implementation of Tacotron
Tacotron-pytorch A pytorch implementation of Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model. Requirements Install python 3 Install pytorc
 203 Dec 2, 2022
203 Dec 2, 2022
Sequence-to-Sequence Framework in PyTorch
nmtpytorch allows training of various end-to-end neural architectures including but not limited to neural machine translation, image captioning and au
 395 Nov 21, 2022
395 Nov 21, 2022
A PyTorch Implementation of End-to-End Models for Speech-to-Text
speech Speech is an open-source package to build end-to-end models for automatic speech recognition. Sequence-to-sequence models with attention, Conne
 647 Dec 25, 2022
647 Dec 25, 2022

A method to generate speech across multiple speakers
VoiceLoop PyTorch implementation of the method described in the paper VoiceLoop: Voice Fitting and Synthesis via a Phonological Loop. VoiceLoop is a n
 873 Dec 15, 2022
873 Dec 15, 2022
Data manipulation and transformation for audio signal processing, powered by PyTorch
torchaudio: an audio library for PyTorch The aim of torchaudio is to apply PyTorch to the audio domain. By supporting PyTorch, torchaudio follows the
 1.9k Jan 8, 2023
1.9k Jan 8, 2023

AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data
AdaSpeech 2: Adaptive Text to Speech with Untranscribed Data [WIP] Unofficial Pytorch implementation of AdaSpeech 2. Requirements : All code written i
 63 Dec 28, 2022
63 Dec 28, 2022

HiFi-GAN: High Fidelity Denoising and Dereverberation Based on Speech Deep Features in Adversarial Networks
HiFiGAN Denoiser This is a Unofficial Pytorch implementation of the paper HiFi-GAN: High Fidelity Denoising and Dereverberation Based on Speech Deep F
134 Dec 27, 2022
Codes for our paper "SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge" (EMNLP 2020)
SentiLARE: Sentiment-Aware Language Representation Learning with Linguistic Knowledge Introduction SentiLARE is a sentiment-aware pre-trained language
 74 Dec 30, 2022
74 Dec 30, 2022
Learning Representational Invariances for Data-Efficient Action Recognition
Learning Representational Invariances for Data-Efficient Action Recognition Official PyTorch implementation for Learning Representational Invariances
 27 Nov 22, 2022
27 Nov 22, 2022
An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models.
DeepNER An Easy-to-use, Modular and Prolongable package of deep-learning based Named Entity Recognition Models. This repository contains complex Deep
 9 May 30, 2022
9 May 30, 2022

Location-Sensitive Visual Recognition with Cross-IOU Loss
The trained models are temporarily unavailable, but you can train the code using reasonable computational resource. Location-Sensitive Visual Recognit
 146 Dec 25, 2022
146 Dec 25, 2022
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
 107 Dec 2, 2022
107 Dec 2, 2022

Improving Calibration for Long-Tailed Recognition (CVPR2021)
Improving Calibration for Long-Tailed Recognition (CVPR2021)
 19 Apr 28, 2021
19 Apr 28, 2021
Speech Algorithms Collections
Speech Algorithms Collections
 498 Jan 6, 2023
498 Jan 6, 2023
Improving Calibration for Long-Tailed Recognition (CVPR2021)
MiSLAS Improving Calibration for Long-Tailed Recognition Authors: Zhisheng Zhong, Jiequan Cui, Shu Liu, Jiaya Jia [arXiv] [slide] [BibTeX] Introductio
116 Dec 20, 2022

This repo contains the official code of our work SAM-SLR which won the CVPR 2021 Challenge on Large Scale Signer Independent Isolated Sign Language Recognition.
Skeleton Aware Multi-modal Sign Language Recognition By Songyao Jiang, Bin Sun, Lichen Wang, Yue Bai, Kunpeng Li and Yun Fu. Smile Lab @ Northeastern
 128 Dec 8, 2022
128 Dec 8, 2022

Implementation of "Distribution Alignment: A Unified Framework for Long-tail Visual Recognition"(CVPR 2021)
Implementation of "Distribution Alignment: A Unified Framework for Long-tail Visual Recognition"(CVPR 2021)
 105 Nov 7, 2022
105 Nov 7, 2022
Binaural Speech Synthesis
Binaural Speech Synthesis This repository contains code to train a mono-to-binaural neural sound renderer. If you use this code or the provided datase
 135 Dec 18, 2022
135 Dec 18, 2022
SpikeX - SpaCy Pipes for Knowledge Extraction
SpikeX is a collection of pipes ready to be plugged in a spaCy pipeline. It aims to help in building knowledge extraction tools with almost-zero effort.
 384 Dec 12, 2022
384 Dec 12, 2022
TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Prediction.
TalkNet 2 [WIP] TalkNet 2: Non-Autoregressive Depth-Wise Separable Convolutional Model for Speech Synthesis with Explicit Pitch and Duration Predictio
69 Dec 17, 2022
DVG-Face: Dual Variational Generation for Heterogeneous Face Recognition, TPAMI 2021
DVG-Face: Dual Variational Generation for HFR This repo is a PyTorch implementation of DVG-Face: Dual Variational Generation for Heterogeneous Face Re
 52 Dec 30, 2022
52 Dec 30, 2022
PyTorch Lightning implementation of Automatic Speech Recognition
lasr Lightening Automatic Speech Recognition An MIT License ASR research library, built on PyTorch-Lightning, for developing end-to-end ASR models. In
40 Sep 19, 2022
OpenMMLab Text Detection, Recognition and Understanding Toolbox
Introduction English | 简体中文 MMOCR is an open-source toolbox based on PyTorch and mmdetection for text detection, text recognition, and the correspondi
 3k Jan 7, 2023
3k Jan 7, 2023
Official implementation of ACTION-Net: Multipath Excitation for Action Recognition (CVPR'21).
ACTION-Net Official implementation of ACTION-Net: Multipath Excitation for Action Recognition (CVPR'21). Getting Started EgoGesture data folder struct
 171 Dec 26, 2022
171 Dec 26, 2022
OpenMMLab's Next Generation Video Understanding Toolbox and Benchmark
Introduction English | 简体中文 MMAction2 is an open-source toolbox for video understanding based on PyTorch. It is a part of the OpenMMLab project. The m
2.7k Jan 7, 2023

Pretrained Pytorch face detection (MTCNN) and recognition (InceptionResnet) models
Face Recognition Using Pytorch Python 3.7 3.6 3.5 Status This is a repository for Inception Resnet (V1) models in pytorch, pretrained on VGGFace2 and
 3.3k Jan 4, 2023
3.3k Jan 4, 2023

Tool which allow you to detect and translate text.
Text detection and recognition This repository contains tool which allow to detect region with text and translate it one by one. Description Two pretr
 176 Nov 28, 2022
176 Nov 28, 2022

Official PyTorch implementation of "IntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos", CVPRW 2021
IntegralAction: Pose-driven Feature Integration for Robust Human Action Recognition in Videos Introduction This repo is official PyTorch implementatio
 29 Sep 24, 2022
29 Sep 24, 2022

PRTR: Pose Recognition with Cascade Transformers
PRTR: Pose Recognition with Cascade Transformers Introduction This repository is the official implementation for Pose Recognition with Cascade Transfo
 133 Dec 30, 2022
133 Dec 30, 2022
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model Edresson Casanova, Christopher Shulby, Eren Gölge, Nicolas Michael Müller, Frede
 92 Dec 9, 2022
92 Dec 9, 2022
Code for the paper "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021)
MASTER-PyTorch PyTorch reimplementation of "MASTER: Multi-Aspect Non-local Network for Scene Text Recognition" (Pattern Recognition 2021). This projec
 255 Dec 29, 2022
255 Dec 29, 2022
A Paper List for Speech Translation
Keyword: Speech Translation, Spoken Language Processing, Natural Language Processing
 138 Dec 24, 2022
138 Dec 24, 2022

TTS is a library for advanced Text-to-Speech generation.
TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.
 6.5k Jan 8, 2023
6.5k Jan 8, 2023
PyTorch reimplementation of the paper Involution: Inverting the Inherence of Convolution for Visual Recognition [CVPR 2021].
Involution: Inverting the Inherence of Convolution for Visual Recognition Unofficial PyTorch reimplementation of the paper Involution: Inverting the I
 100 Dec 1, 2022
100 Dec 1, 2022

Learning recognition/segmentation models without end-to-end training. 40%-60% less GPU memory footprint. Same training time. Better performance.
InfoPro-Pytorch The Information Propagation algorithm for training deep networks with local supervision. (ICLR 2021) Revisiting Locally Supervised Lea
 78 Dec 27, 2022
78 Dec 27, 2022
![[AAAI 2021] MVFNet: Multi-View Fusion Network for Efficient Video Recognition](https://github.com/whwu95/MVFNet/raw/main/mvfnet.png)
[AAAI 2021] MVFNet: Multi-View Fusion Network for Efficient Video Recognition
MVFNet: Multi-View Fusion Network for Efficient Video Recognition (AAAI 2021) Overview We release the code of the MVFNet (Multi-View Fusion Network).
 114 Nov 27, 2022
114 Nov 27, 2022

Chinese Mandarin tts text-to-speech 中文 (普通话) 语音 合成 , by fastspeech 2 , implemented in pytorch, using waveglow as vocoder,
Chinese mandarin text to speech based on Fastspeech2 and Unet This is a modification and adpation of fastspeech2 to mandrin(普通话). Many modifications t
 291 Jan 2, 2023
291 Jan 2, 2023
Spontaneous Facial Micro Expression Recognition using 3D Spatio-Temporal Convolutional Neural Networks
Spontaneous Facial Micro Expression Recognition using 3D Spatio-Temporal Convolutional Neural Networks Abstract Facial expression recognition in video
 103 Dec 29, 2022
103 Dec 29, 2022

STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech
STYLER: Style Factor Modeling with Rapidity and Robustness via Speech Decomposition for Expressive and Controllable Neural Text to Speech Keon Lee, Ky
114 Dec 12, 2022

This is the official PyTorch implementation of the paper "TransFG: A Transformer Architecture for Fine-grained Recognition" (Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, Changhu Wang, Alan Yuille).
TransFG: A Transformer Architecture for Fine-grained Recognition Official PyTorch code for the paper: TransFG: A Transformer Architecture for Fine-gra
 307 Jan 3, 2023
307 Jan 3, 2023
This is the official PyTorch implementation of the paper "TransFG: A Transformer Architecture for Fine-grained Recognition" (Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, Changhu Wang, Alan Yuille).
TransFG: A Transformer Architecture for Fine-grained Recognition Official PyTorch code for the paper: TransFG: A Transformer Architecture for Fine-gra
307 Jan 3, 2023

Polaris is a Face recognition attendance system .
Support Me 🚀 About Polaris 📄 Polaris is a system based on facial recognition with a futuristic GUI design, Can easily find people informations store
 215 Dec 26, 2022
215 Dec 26, 2022

Tracking Progress in Natural Language Processing
Repository to track the progress in Natural Language Processing (NLP), including the datasets and the current state-of-the-art for the most common NLP tasks.
 21.2k Dec 30, 2022
21.2k Dec 30, 2022
Implementation of LambdaNetworks, a new approach to image recognition that reaches SOTA with less compute
Lambda Networks - Pytorch Implementation of λ Networks, a new approach to image recognition that reaches SOTA on ImageNet. The new method utilizes λ l
 1.5k Jan 7, 2023
1.5k Jan 7, 2023
![[CVPR2021 Oral] FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation.](https://github.com/ethnhe/FFB6D/raw/master/figs/FFB6D_overview.png)
[CVPR2021 Oral] FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation.
FFB6D This is the official source code for the CVPR2021 Oral work, FFB6D: A Full Flow Biderectional Fusion Network for 6D Pose Estimation. (Arxiv) Tab
 201 Dec 28, 2022
201 Dec 28, 2022

When Age-Invariant Face Recognition Meets Face Age Synthesis: A Multi-Task Learning Framework (CVPR 2021 oral)
MTLFace This repository contains the PyTorch implementation and the dataset of the paper: When Age-Invariant Face Recognition Meets Face Age Synthesis
 120 Jan 5, 2023
120 Jan 5, 2023

Convolutional Recurrent Neural Networks(CRNN) for Scene Text Recognition
CRNN_Tensorflow This is a TensorFlow implementation of a Deep Neural Network for scene text recognition. It is mainly based on the paper "An End-to-En
 1000 Dec 27, 2022
1000 Dec 27, 2022
Open Source research tool to search, browse, analyze and explore large document collections by Semantic Search Engine and Open Source Text Mining & Text Analytics platform (Integrates ETL for document processing, OCR for images & PDF, named entity recognition for persons, organizations & locations, metadata management by thesaurus & ontologies, search user interface & search apps for fulltext search, faceted search & knowledge graph)
Open Semantic Search https://opensemanticsearch.org Integrated search server, ETL framework for document processing (crawling, text extraction, text a
 684 Jan 6, 2023
684 Jan 6, 2023

Text recognition (optical character recognition) with deep learning methods.
What Is Wrong With Scene Text Recognition Model Comparisons? Dataset and Model Analysis | paper | training and evaluation data | failure cases and cle
 3.2k Jan 4, 2023
3.2k Jan 4, 2023
A curated list of awesome synthetic data for text location and recognition
awesome-SynthText A curated list of awesome synthetic data for text location and recognition and OCR datasets. Text location SynthText SynthText_Chine
 283 Jan 5, 2023
283 Jan 5, 2023

A synthetic data generator for text recognition
TextRecognitionDataGenerator A synthetic data generator for text recognition What is it for? Generating text image samples to train an OCR software. N
 2.5k Jan 4, 2023
2.5k Jan 4, 2023
Geometric Augmentation for Text Image
Text Image Augmentation A general geometric augmentation tool for text images in the CVPR 2020 paper "Learn to Augment: Joint Data Augmentation and Ne
 440 Jan 5, 2023
440 Jan 5, 2023

Total Text Dataset. It consists of 1555 images with more than 3 different text orientations: Horizontal, Multi-Oriented, and Curved, one of a kind.
Total-Text-Dataset (Official site) Updated on April 29, 2020 (Detection leaderboard is updated - highlighted E2E methods. Thank you shine-lcy.) Update
 671 Dec 27, 2022
671 Dec 27, 2022
OCR, Scene-Text-Understanding, Text Recognition
Scene-Text-Understanding Survey [2015-PAMI] Text Detection and Recognition in Imagery: A Survey paper [2014-Front.Comput.Sci] Scene Text Detection and
 354 Dec 12, 2022
354 Dec 12, 2022
Tracking the latest progress in Scene Text Detection and Recognition: Must-read papers well organized
SceneTextPapers Tracking the latest progress in Scene Text Detection and Recognition: must-read papers well organized Information about this repositor
 763 Jan 1, 2023
763 Jan 1, 2023
A collection of resources (including the papers and datasets) of OCR (Optical Character Recognition).
OCR Resources This repository contains a collection of resources (including the papers and datasets) of OCR (Optical Character Recognition). Contents
 363 Jan 3, 2023
363 Jan 3, 2023
A curated list of papers and resources for scene text detection and recognition
Awesome Scene Text A curated list of papers and resources for scene text detection and recognition The year when a paper was first published, includin
 43 Mar 15, 2022
43 Mar 15, 2022