1022 Repositories
Python Speech-recognition Libraries
StrengthNet: Deep Learning-based Emotion Strength Assessment for Emotional Speech Synthesis
StrengthNet Implementation of "StrengthNet: Deep Learning-based Emotion Strength Assessment for Emotional Speech Synthesis" https://arxiv.org/abs/2110
 21 Oct 11, 2021
21 Oct 11, 2021

A 10000+ hours dataset for Chinese speech recognition
WenetSpeech Official website | Paper A 10000+ Hours Multi-domain Chinese Corpus for Speech Recognition Download Please visit the official website, rea
 310 Jan 3, 2023
310 Jan 3, 2023

Speech Separation Using an Asynchronous Fully Recurrent Convolutional Neural Network
Speech Separation Using an Asynchronous Fully Recurrent Convolutional Neural Network This repository is the official implementation of Speech Separati
 116 Nov 9, 2022
116 Nov 9, 2022

PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
 279 Jan 4, 2023
279 Jan 4, 2023
Persian Kaldi profile for Rhasspy built from open speech data
Persian Kaldi Profile A Rhasspy profile for Persian (fa). Installation Get started by first installing Vosk: # Create virtual environment python3 -m v
 12 Aug 8, 2022
12 Aug 8, 2022

Shallow Convolutional Neural Networks for Human Activity Recognition using Wearable Sensors
-IEEE-TIM-2021-1-Shallow-CNN-for-HAR [IEEE TIM 2021-1] Shallow Convolutional Neural Networks for Human Activity Recognition using Wearable Sensors All
 1 May 17, 2022
1 May 17, 2022
Every Google, Azure & IBM text to speech voice for free
TTS-Grabber Quick thing i made about a year ago to download any text with any tts voice, over 630 voices to choose from currently. It will split the i
 16 Dec 7, 2022
16 Dec 7, 2022

text to speech toolkit. 好用的中文语音合成工具箱,包含语音编码器、语音合成器、声码器和可视化模块。
ttskit Text To Speech Toolkit: 语音合成工具箱。 安装 pip install -U ttskit 注意 可能需另外安装的依赖包:torch,版本要求torch=1.6.0,=1.7.1,根据自己的实际环境安装合适cuda或cpu版本的torch。 ttskit的
 483 Jan 4, 2023
483 Jan 4, 2023
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition
AdaMML: Adaptive Multi-Modal Learning for Efficient Video Recognition [ArXiv] [Project Page] This repository is the official implementation of AdaMML:
 43 Dec 26, 2022
43 Dec 26, 2022

Neural network for recognizing the gender of people in photos
Neural Network For Gender Recognition How to test it? Install requirements.txt file using pip install -r requirements.txt command Run nn.py using pyth
 1 Sep 18, 2022
1 Sep 18, 2022
Implementation of "StrengthNet: Deep Learning-based Emotion Strength Assessment for Emotional Speech Synthesis"
StrengthNet Implementation of "StrengthNet: Deep Learning-based Emotion Strength Assessment for Emotional Speech Synthesis" https://arxiv.org/abs/2110
65 Dec 20, 2022
EdiTTS: Score-based Editing for Controllable Text-to-Speech
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
 99 Jan 2, 2023
99 Jan 2, 2023
PortaSpeech - PyTorch Implementation
PortaSpeech - PyTorch Implementation PyTorch Implementation of PortaSpeech: Portable and High-Quality Generative Text-to-Speech. Model Size Module Nor
276 Dec 26, 2022

PyTorch implementation of Microsoft's text-to-speech system FastSpeech 2: Fast and High-Quality End-to-End Text to Speech.
An implementation of Microsoft's "FastSpeech 2: Fast and High-Quality End-to-End Text to Speech"
 1k Dec 30, 2022
1k Dec 30, 2022
Refactored version of FastSpeech2
Refactored version of FastSpeech2. An implementation of Microsoft's "FastSpeech 2: Fast and High-Quality End-to-End Text to Speech"
 10 May 26, 2022
10 May 26, 2022

An official reimplementation of the method described in the INTERSPEECH 2021 paper - Speech Resynthesis from Discrete Disentangled Self-Supervised Representations.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations Implementation of the method described in the Speech Resynthesis from Di
 253 Jan 6, 2023
253 Jan 6, 2023
VoiceFixer VoiceFixer is a framework for general speech restoration.
VoiceFixer VoiceFixer is a framework for general speech restoration. We aim at the restoration of severly degraded speech and historical speech. Paper
 174 Jan 6, 2023
174 Jan 6, 2023

A PyTorch implementation of SlowFast based on ICCV 2019 paper "SlowFast Networks for Video Recognition"
SlowFast A PyTorch implementation of SlowFast based on ICCV 2019 paper SlowFast Networks for Video Recognition. Requirements Anaconda PyTorch conda in
 8 Dec 23, 2022
8 Dec 23, 2022
A web app to scan crypto markets based on candlestick pattern recognition from
Crypto_Scanner A web app to scan crypto markets based on candlestick pattern recognition from "Japanese Candlestick Charting Techniques: A Contemporar
 27 Jan 1, 2023
27 Jan 1, 2023
Deep Face Recognition in PyTorch
Face Recognition in PyTorch By Alexey Gruzdev and Vladislav Sovrasov Introduction A repository for different experimental Face Recognition models such
 141 Sep 11, 2022
141 Sep 11, 2022

🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
 3.1k Jan 2, 2023
3.1k Jan 2, 2023

Pytorch implementation for "Large-Scale Long-Tailed Recognition in an Open World" (CVPR 2019 ORAL)
Large-Scale Long-Tailed Recognition in an Open World [Project] [Paper] [Blog] Overview Open Long-Tailed Recognition (OLTR) is the author's re-implemen
 761 Dec 26, 2022
761 Dec 26, 2022
A 10000+ hours dataset for Chinese speech recognition
A 10000+ hours dataset for Chinese speech recognition
309 Dec 16, 2022
Voicefixer aims at the restoration of human speech regardless how serious its degraded.
Voicefixer aims at the restoration of human speech regardless how serious its degraded.
324 Dec 26, 2022
A GUI for Face Recognition, based upon Docker, Tkinter, GPU and a camera device.
Face Recognition GUI This repository is a GUI version of Face Recognition by Adam Geitgey, where e.g. Docker and Tkinter are utilized. All the materia
 6 Dec 5, 2022
6 Dec 5, 2022

This is the official implement of paper "ActionCLIP: A New Paradigm for Action Recognition"
This is an official pytorch implementation of ActionCLIP: A New Paradigm for Video Action Recognition [arXiv] Overview Content Prerequisites Data Prep
 32 Sep 25, 2021
32 Sep 25, 2021

GLaRA: Graph-based Labeling Rule Augmentation for Weakly Supervised Named Entity Recognition
GLaRA: Graph-based Labeling Rule Augmentation for Weakly Supervised Named Entity Recognition
 29 Dec 26, 2022
29 Dec 26, 2022

Unofficial Implementation of Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration
Zero-Shot Text-to-Speech for Text-Based Insertion in Audio Narration This repo contains only model Implementation of Zero-Shot Text-to-Speech for Text
 33 Sep 22, 2022
33 Sep 22, 2022

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
237 Jan 2, 2023
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
Lingvo is a framework for building neural networks in Tensorflow, particularly sequence models.
 2.7k Jan 5, 2023
2.7k Jan 5, 2023

Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation (SIGGRAPH Asia 2021)
Live Speech Portraits: Real-Time Photorealistic Talking-Head Animation This repository contains the implementation of the following paper: Live Speech
 575 Dec 31, 2022
575 Dec 31, 2022
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
 1.5k Jan 1, 2023
1.5k Jan 1, 2023
This is the official implement of paper "ActionCLIP: A New Paradigm for Action Recognition"
This is an official pytorch implementation of ActionCLIP: A New Paradigm for Video Action Recognition [arXiv] Overview Content Prerequisites Data Prep
268 Jan 9, 2023

Unofficial PyTorch implementation of Google AI's VoiceFilter system
VoiceFilter Note from Seung-won (2020.10.25) Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-sour
 883 Jan 7, 2023
883 Jan 7, 2023
A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis
WaveGlow A PyTorch implementation of the WaveGlow: A Flow-based Generative Network for Speech Synthesis Quick Start: Install requirements: pip install
 204 Jul 14, 2022
204 Jul 14, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained mo
 77.2k Jan 2, 2023
77.2k Jan 2, 2023

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Jan 8, 2023
1.8k Jan 8, 2023
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
279 Dec 9, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

A PyTorch implementation of Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks
SVHNClassifier-PyTorch A PyTorch implementation of Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks If
 182 Jan 3, 2023
182 Jan 3, 2023
Speech Recognition using DeepSpeech2.
deepspeech.pytorch Implementation of DeepSpeech2 for PyTorch using PyTorch Lightning. The repo supports training/testing and inference using the DeepS
 2k Jan 4, 2023
2k Jan 4, 2023

A PyTorch Implementation of Single Shot MultiBox Detector
SSD: Single Shot MultiBox Object Detector, in PyTorch A PyTorch implementation of Single Shot MultiBox Detector from the 2016 paper by Wei Liu, Dragom
 4.8k Jan 7, 2023
4.8k Jan 7, 2023
Accurately generate all possible forms of an English word e.g "election" -- "elect", "electoral", "electorate" etc.
Accurately generate all possible forms of an English word Word forms can accurately generate all possible forms of an English word. It can conjugate v
 570 Dec 31, 2022
570 Dec 31, 2022

Neural network models for joint POS tagging and dependency parsing (CoNLL 2017-2018)
Neural Network Models for Joint POS Tagging and Dependency Parsing Implementations of joint models for POS tagging and dependency parsing, as describe
 152 Sep 2, 2022
152 Sep 2, 2022
A facial recognition doorbell system using a Raspberry Pi
Facial Recognition Doorbell This project expands on the person-detecting doorbell system to allow it to identify faces, and announce names accordingly
 22 Apr 15, 2022
22 Apr 15, 2022
This project converts your human voice input to its text transcript and to an automated voice too.
Human Voice to Automated Voice & Text Introduction: In this project, whenever you'll speak, it will turn your voice into a robot voice and furthermore
 3 Oct 15, 2021
3 Oct 15, 2021
Codename generator using WordNet parts of speech database
codenames Codename generator using WordNet parts of speech database References: https://possiblywrong.wordpress.com/2021/09/13/code-name-generator/ ht
 27 Oct 30, 2022
27 Oct 30, 2022

A collection of SOTA Image Classification Models in PyTorch
A collection of SOTA Image Classification Models in PyTorch
 85 Dec 30, 2022
85 Dec 30, 2022
Code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition"
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
![[ICCV2021] Official code for](https://github.com/Uason-Chen/CTR-GCN/raw/main/src/framework.jpg)
[ICCV2021] Official code for "Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition"
CTR-GCN This repo is the official implementation for Channel-wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition. The pap
 148 Dec 16, 2022
148 Dec 16, 2022

Tool to add main subject to items on Wikidata using a WMFs CirrusSearch for named entity recognition or a manually supplied list of QIDs
ItemSubjector Tool made to add main subject statements to items based on the title using a home-brewed CirrusSearch-based Named Entity Recognition alg
 9 Nov 17, 2022
9 Nov 17, 2022
Channel Pruning for Accelerating Very Deep Neural Networks (ICCV'17)
Channel Pruning for Accelerating Very Deep Neural Networks (ICCV'17)
 1k Jan 3, 2023
1k Jan 3, 2023

“Data Augmentation for Cross-Domain Named Entity Recognition” (EMNLP 2021)
Data Augmentation for Cross-Domain Named Entity Recognition Authors: Shuguang Chen, Gustavo Aguilar, Leonardo Neves and Thamar Solorio This repository
 18 Sep 10, 2022
18 Sep 10, 2022

Desktop music recognition application for windows
MusicRecognizer Music recognition application for windows You can choose from which of the devices the recording will be made. If you choose speakers,
 28 Dec 13, 2022
28 Dec 13, 2022
[EMNLP 2021] Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training
RoSTER The source code used for Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training, p
 60 Dec 30, 2022
60 Dec 30, 2022

Official Pytorch implementation of Test-Agnostic Long-Tailed Recognition by Test-Time Aggregating Diverse Experts with Self-Supervision.
This repository is the official Pytorch implementation of Test-Agnostic Long-Tailed Recognition by Test-Time Aggregating Diverse Experts with Self-Supervision.
 101 Dec 30, 2022
101 Dec 30, 2022

Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition
Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition Official implementation of the Efficient Conforme
 145 Dec 30, 2022
145 Dec 30, 2022
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022

Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library.
GI-Pi Control the classic General Instrument SP0256-AL2 speech chip and AY-3-8910 sound generator with a Raspberry Pi and this Python library. The SP0
 8 Dec 15, 2021
8 Dec 15, 2021

Face Mask Detection is a project to determine whether someone is wearing mask or not, using deep neural network.
face-mask-detection Face Mask Detection is a project to determine whether someone is wearing mask or not, using deep neural network. It contains 3 scr
 13 Jan 18, 2022
13 Jan 18, 2022

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022

Realtime Face Anti Spoofing with Face Detector based on Deep Learning using Tensorflow/Keras and OpenCV
Realtime Face Anti-Spoofing Detection 🤖 Realtime Face Anti Spoofing Detection with Face Detector to detect real and fake faces Please star this repo
 86 Aug 3, 2022
86 Aug 3, 2022

This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on table detection and table structure recognition.
WTW-Dataset This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on ICCV 2021. Here, you can download the
 109 Dec 29, 2022
109 Dec 29, 2022
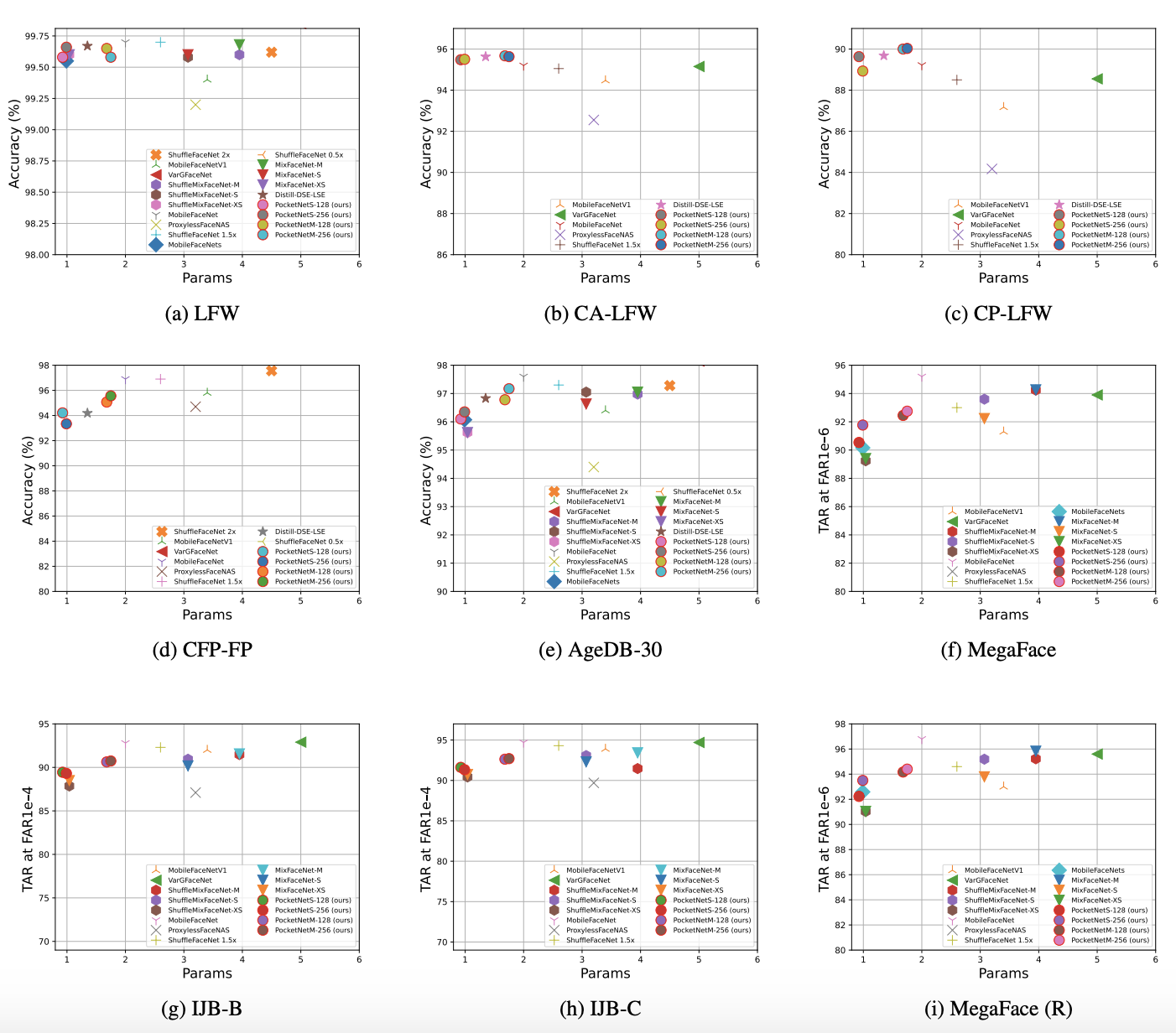
PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and Multi-Step Knowledge Distillation
PocketNet This is the official repository of the paper: PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and M
 40 Dec 22, 2022
40 Dec 22, 2022
Implementation of "A Deep Learning Loss Function based on Auditory Power Compression for Speech Enhancement" by pytorch
This repository is used to suspend the results of our paper "A Deep Learning Loss Function based on Auditory Power Compression for Speech Enhancement"
 19 Sep 30, 2022
19 Sep 30, 2022
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Cross Quality LFW: A database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Cross-Quality Labeled Faces in the Wild (XQLFW) Here, we release the database, evaluation protocol and code for the following paper: Cross Quality LFW
 10 Dec 12, 2022
10 Dec 12, 2022
Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
Pytorch-NLU,一个中文文本分类、序列标注工具包,支持中文长文本、短文本的多类、多标签分类任务,支持中文命名实体识别、词性标注、分词等序列标注任务。 Ptorch NLU, a Chinese text classification and sequence annotation toolkit, supports multi class and multi label classification tasks of Chinese long text and short text, and supports sequence annotation tasks such as Chinese named entity recognition, part of speech tagging and word segmentation.
 186 Dec 24, 2022
186 Dec 24, 2022
[ICCV 2021] Released code for Causal Attention for Unbiased Visual Recognition
CaaM This repo contains the codes of training our CaaM on NICO/ImageNet9 dataset. Due to my recent limited bandwidth, this codebase is still messy, wh
 66 Dec 31, 2022
66 Dec 31, 2022
Code for the ICASSP-2021 paper: Continuous Speech Separation with Conformer.
Continuous Speech Separation with Conformer Introduction We examine the use of the Conformer architecture for continuous speech separation. Conformer
 81 Nov 28, 2022
81 Nov 28, 2022

Official code of ICCV2021 paper "Residual Attention: A Simple but Effective Method for Multi-Label Recognition"
CSRA This is the official code of ICCV 2021 paper: Residual Attention: A Simple But Effective Method for Multi-Label Recoginition Demo, Train and Vali
 163 Dec 22, 2022
163 Dec 22, 2022

This repo implements a Topological SLAM: Deep Visual Odometry with Long Term Place Recognition (Loop Closure Detection)
This repo implements a topological SLAM system. Deep Visual Odometry (DF-VO) and Visual Place Recognition are combined to form the topological SLAM system.
 32 Jun 23, 2022
32 Jun 23, 2022

Unofficial PyTorch Implementation of UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
UnivNet UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation This is an unofficial PyTorch
54 Aug 30, 2021
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
 24 Sep 7, 2022
24 Sep 7, 2022

AdaFocus (ICCV 2021) Adaptive Focus for Efficient Video Recognition
AdaFocus (ICCV 2021) This repo contains the official code and pre-trained models for AdaFocus. Adaptive Focus for Efficient Video Recognition Referenc
 115 Dec 21, 2022
115 Dec 21, 2022
Source Code For Template-Based Named Entity Recognition Using BART
Template-Based NER Source Code For Template-Based Named Entity Recognition Using BART Training Training train.py Inference inference.py Corpus ATIS (h
 174 Dec 19, 2022
174 Dec 19, 2022
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion Yinghao Aaron Li, Ali Zare, Nima Mesgarani We pres
 282 Jan 1, 2023
282 Jan 1, 2023

GSoC'2021 | TensorFlow implementation of Wav2Vec2
GSoC'2021 | TensorFlow implementation of Wav2Vec2
 73 Nov 28, 2022
73 Nov 28, 2022
Temporal Segment Networks (TSN) in PyTorch
TSN-Pytorch We have released MMAction, a full-fledged action understanding toolbox based on PyTorch. It includes implementation for TSN as well as oth
 1k Jan 3, 2023
1k Jan 3, 2023
PyTorch implementation of Tacotron speech synthesis model.
tacotron_pytorch PyTorch implementation of Tacotron speech synthesis model. Inspired from keithito/tacotron. Currently not as much good speech quality
279 Dec 9, 2022

This is the offical website for paper ''Category-consistent deep network learning for accurate vehicle logo recognition''
The Pytorch Implementation of Category-consistent deep network learning for accurate vehicle logo recognition This is the offical website for paper ''
 28 Oct 29, 2022
28 Oct 29, 2022
This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab.
Speech-Backbones This is the main repository of open-sourced speech technology by Huawei Noah's Ark Lab. Grad-TTS Official implementation of the Grad-
 295 Jan 7, 2023
295 Jan 7, 2023

Jittor Medical Segmentation Lib -- The assignment of Pattern Recognition course (2021 Spring) in Tsinghua University
THU模式识别2021春 -- Jittor 医学图像分割 模型列表 本仓库收录了课程作业中同学们采用jittor框架实现的如下模型: UNet SegNet DeepLab V2 DANet EANet HarDNet及其改动HarDNet_alter PSPNet OCNet OCRNet DL
 48 Dec 26, 2022
48 Dec 26, 2022

Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions
Deploy an inference API on AWS (EC2) using FastAPI Docker and Github Actions To learn more about this project: medium blog post The goal of this proje
 60 Dec 17, 2022
60 Dec 17, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022
Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning
structshot Code and data for paper "Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning", Yi Yang and Arz
47 Dec 27, 2022
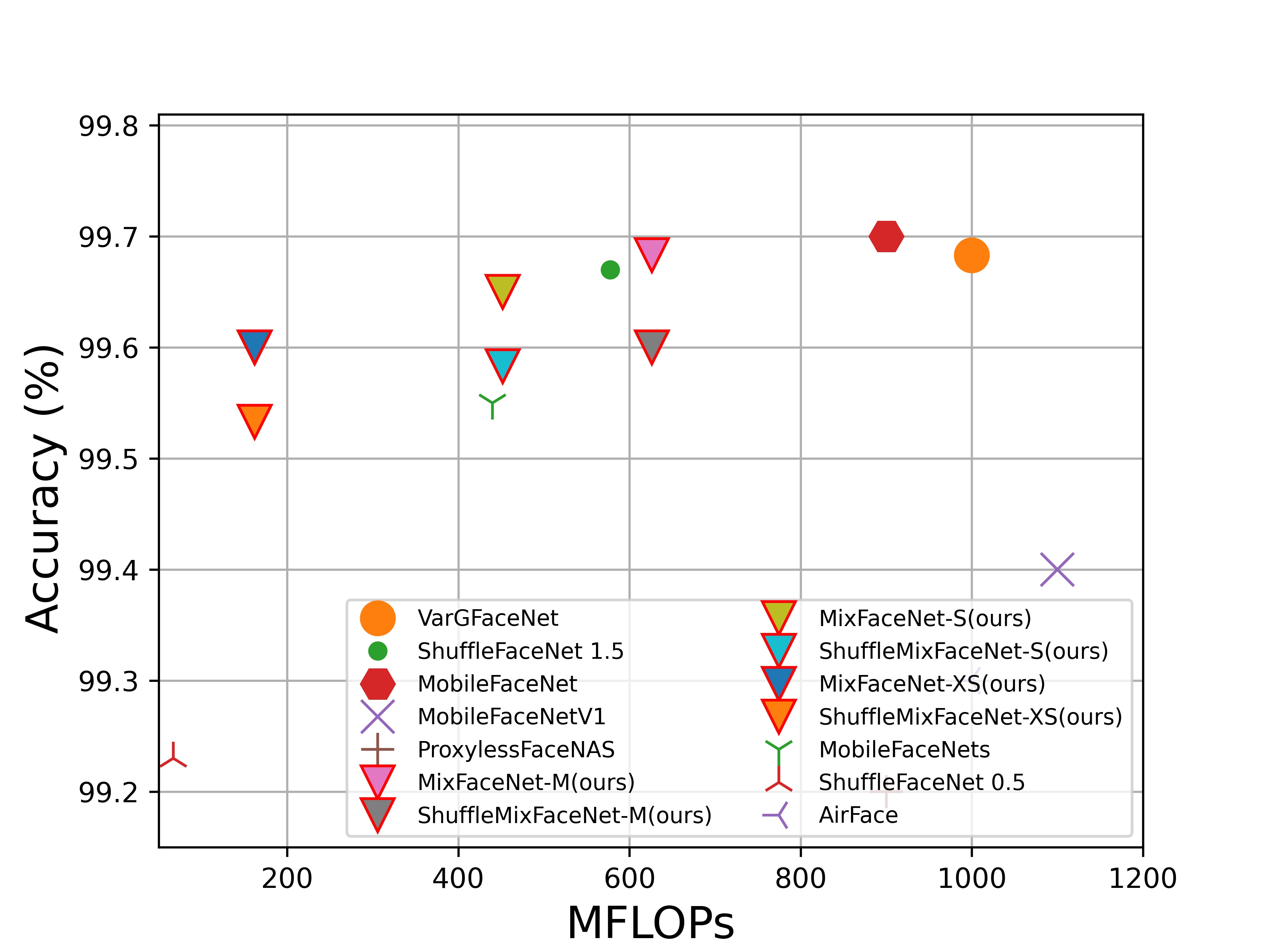
Official repository for MixFaceNets: Extremely Efficient Face Recognition Networks
MixFaceNets This is the official repository of the paper: MixFaceNets: Extremely Efficient Face Recognition Networks. (Accepted in IJCB2021) https://i
51 Dec 13, 2022
3D ResNets for Action Recognition (CVPR 2018)
3D ResNets for Action Recognition Update (2020/4/13) We published a paper on arXiv. Hirokatsu Kataoka, Tenga Wakamiya, Kensho Hara, and Yutaka Satoh,
 3.5k Jan 6, 2023
3.5k Jan 6, 2023

IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models
IMS-Toucan is a toolkit to train state-of-the-art Speech Synthesis models. Everything is pure Python and PyTorch based to keep it as simple and beginner-friendly, yet powerful as possible.
 247 Jan 5, 2023
247 Jan 5, 2023

Learning Compatible Embeddings, ICCV 2021
LCE Learning Compatible Embeddings, ICCV 2021 by Qiang Meng, Chixiang Zhang, Xiaoqiang Xu and Feng Zhou Paper: Arxiv We cannot release source codes pu
 25 Dec 17, 2022
25 Dec 17, 2022
Parametric Contrastive Learning (ICCV2021)
Parametric-Contrastive-Learning This repository contains the implementation code for ICCV2021 paper: Parametric Contrastive Learning (https://arxiv.or
 156 Dec 21, 2022
156 Dec 21, 2022
![[NeurIPS 2020] Official repository for the project](https://github.com/henryxrl/Listening-to-Sound-of-Silence-for-Speech-Denoising/raw/main/assets/network.png)
[NeurIPS 2020] Official repository for the project "Listening to Sound of Silence for Speech Denoising"
Listening to Sounds of Silence for Speech Denoising Introduction This is the repository of the "Listening to Sounds of Silence for Speech Denoising" p
 40 Dec 20, 2022
40 Dec 20, 2022
ExKaldi-RT: An Online Speech Recognition Extension Toolkit of Kaldi
ExKaldi-RT is an online ASR toolkit for Python language. It reads realtime streaming audio and do online feature extraction, probability computation, and online decoding.
 31 Aug 16, 2021
31 Aug 16, 2021
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 169 Jan 5, 2023
169 Jan 5, 2023
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023

Pytorch implementation for Semantic Segmentation/Scene Parsing on MIT ADE20K dataset
Semantic Segmentation on MIT ADE20K dataset in PyTorch This is a PyTorch implementation of semantic segmentation models on MIT ADE20K scene parsing da
 4.5k Jan 8, 2023
4.5k Jan 8, 2023

Code release for The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification (TIP 2020)
The Devil is in the Channels: Mutual-Channel Loss for Fine-Grained Image Classification Code release for The Devil is in the Channels: Mutual-Channel
 230 Dec 31, 2022
230 Dec 31, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
47 Dec 18, 2022
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition (PyTorch) Paper: https://arxiv.org/abs/2105.01883 Citation: @
 260 Jan 3, 2023
260 Jan 3, 2023