272 Repositories
Python document-embeddings Libraries

Learning Logic Rules for Document-Level Relation Extraction
LogiRE Learning Logic Rules for Document-Level Relation Extraction We propose to introduce logic rules to tackle the challenges of doc-level RE. Equip
 41 Dec 26, 2022
41 Dec 26, 2022

Self-Supervised Document-to-Document Similarity Ranking via Contextualized Language Models and Hierarchical Inference
Self-Supervised Document Similarity Ranking (SDR) via Contextualized Language Models and Hierarchical Inference This repo is the implementation for SD
 36 Nov 28, 2022
36 Nov 28, 2022
Switch spaces for knowledge graph embeddings
SwisE Switch spaces for knowledge graph embeddings. Requirements: python3 pytorch numpy tqdm Reproduce the results To reproduce the reported results,
 4 Dec 1, 2021
4 Dec 1, 2021
Exploring dimension-reduced embeddings
sleepwalk Exploring dimension-reduced embeddings This is the code repository. See here for the Sleepwalk web page. License and disclaimer This program
 91 Nov 29, 2022
91 Nov 29, 2022
A fast, efficient universal vector embedding utility package.
Magnitude: a fast, simple vector embedding utility library A feature-packed Python package and vector storage file format for utilizing vector embeddi
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Repo for the paper "DiLBERT: Cheap Embeddings for Disease Related Medical NLP"
DiLBERT Repo for the paper "DiLBERT: Cheap Embeddings for Disease Related Medical NLP" Pretrained Model The pretrained model presented in the paper is
 2 Dec 15, 2022
2 Dec 15, 2022

Detectron2 for Document Layout Analysis
Detectron2 trained on PubLayNet dataset This repo contains the training configurations, code and trained models trained on PubLayNet dataset using Det
 163 Nov 21, 2022
163 Nov 21, 2022
Code for the paper "A Simple but Tough-to-Beat Baseline for Sentence Embeddings".
Code for the paper "A Simple but Tough-to-Beat Baseline for Sentence Embeddings".
 1.1k Dec 27, 2022
1.1k Dec 27, 2022
AI-powered literature discovery and review engine for medical/scientific papers
AI-powered literature discovery and review engine for medical/scientific papers paperai is an AI-powered literature discovery and review engine for me
 819 Dec 30, 2022
819 Dec 30, 2022

Implementation of DocFormer: End-to-End Transformer for Document Understanding, a multi-modal transformer based architecture for the task of Visual Document Understanding (VDU)
DocFormer - PyTorch Implementation of DocFormer: End-to-End Transformer for Document Understanding, a multi-modal transformer based architecture for t
 171 Jan 6, 2023
171 Jan 6, 2023
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 A repository part of the MarIA project. Corpora 📃 Corpora Number of documents Number of tokens Size (GB) BNE 201,080,084
 203 Dec 20, 2022
203 Dec 20, 2022

This is the code used in the paper "Entity Embeddings of Categorical Variables".
This is the code used in the paper "Entity Embeddings of Categorical Variables". If you want to get the original version of the code used for the Kagg
 845 Nov 29, 2022
845 Nov 29, 2022
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL, and utterance id
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL
 3 Dec 26, 2022
3 Dec 26, 2022
Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings
Text2Music Emotion Embedding Text-to-Music Retrieval using Pre-defined/Data-driven Emotion Embeddings Reference Emotion Embedding Spaces for Matching
 50 Dec 5, 2022
50 Dec 5, 2022
This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text.
Text Summarizer This project uses word frequency and Term Frequency-Inverse Document Frequency to summarize a text. Team Members This mini-project was
 1 Nov 16, 2021
1 Nov 16, 2021

Code repository for EMNLP 2021 paper 'Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods'
Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods This is the code repository to accompany the EMNLP 2021 paper on ad
 7 Sep 25, 2022
7 Sep 25, 2022

Document blur detection based on Laplacian operator and text detection.
Document Blur Detection For general blurred image, using the variance of Laplacian operator is a good solution. But as for the blur detection of docum
 5 Oct 20, 2022
5 Oct 20, 2022
🌸 fastText + Bloom embeddings for compact, full-coverage vectors with spaCy
floret: fastText + Bloom embeddings for compact, full-coverage vectors with spaCy floret is an extended version of fastText that can produce word repr
 222 Dec 16, 2022
222 Dec 16, 2022
Python-based tools for document analysis and OCR
ocropy OCRopus is a collection of document analysis programs, not a turn-key OCR system. In order to apply it to your documents, you may need to do so
 3.2k Dec 31, 2022
3.2k Dec 31, 2022
gtfs2vec - Learning GTFS Embeddings for comparing PublicTransport Offer in Microregions
gtfs2vec This is a companion repository for a gtfs2vec - Learning GTFS Embeddings for comparing PublicTransport Offer in Microregions publication. Vis
 5 Oct 10, 2022
5 Oct 10, 2022

A document scanner application for laptops/desktops developed using python, Tkinter and OpenCV.
DcoumentScanner A document scanner application for laptops/desktops developed using python, Tkinter and OpenCV. Directly install the .exe file to inst
 1 Oct 29, 2021
1 Oct 29, 2021
The code of paper ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs. Zhanqiu Zhang, Jie Wang, Jiajun Chen, Shuiwang Ji, Feng Wu. NeurIPS 2021.
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs This is the code of paper ConE: Cone Embeddings for Multi-Hop Reasoning over Knowl
 3 Oct 28, 2021
3 Oct 28, 2021
A PyTorch implementation of unsupervised SimCSE
A PyTorch implementation of unsupervised SimCSE
 99 Dec 23, 2022
99 Dec 23, 2022
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs
ConE: Cone Embeddings for Multi-Hop Reasoning over Knowledge Graphs This is the code of paper ConE: Cone Embeddings for Multi-Hop Reasoning over Knowl
33 Dec 7, 2022
Towhee is a flexible machine learning framework currently focused on computing deep learning embeddings over unstructured data.
Towhee is a flexible machine learning framework currently focused on computing deep learning embeddings over unstructured data.
 1.7k Jan 8, 2023
1.7k Jan 8, 2023
Unsupervised Document Expansion for Information Retrieval with Stochastic Text Generation
Unsupervised Document Expansion for Information Retrieval with Stochastic Text Generation Official Code Repository for the paper "Unsupervised Documen
 2 Oct 26, 2021
2 Oct 26, 2021
Generate custom detailed survey paper with topic clustered sections and proper citations, from just a single query in just under 30 mins !!
Auto-Research A no-code utility to generate a detailed well-cited survey with topic clustered sections (draft paper format) and other interesting arti
 20 Dec 14, 2022
20 Dec 14, 2022
Language Models for the legal domain in Spanish done @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish legal domain Language Model ⚖️ This repository contains the page for two main resources for the Spanish legal domain: A RoBERTa model: https:/
12 Nov 14, 2022
Table automatically extraction from PDF Document
PDF Table Extractor Table automatically extraction from PDF Document Our Icon 📌 Name : PDF Table Extractor 📌 Authors : Minku Koo Jiyong Park 📌 Deve
 1 Jan 10, 2022
1 Jan 10, 2022

Key information extraction from invoice document with Graph Convolution Network
Key Information Extraction from Scanned Invoices Key information extraction from invoice document with Graph Convolution Network Related blog post fro
 39 Dec 16, 2022
39 Dec 16, 2022
Bootstrapped Unsupervised Sentence Representation Learning (ACL 2021)
Install first pip3 install -e . Training python3 training/unsupervised_tuning.py python3 training/supervised_tuning.py python3 training/multilingual_
 26 Jul 22, 2022
26 Jul 22, 2022

Code for reproducing our paper: LMSOC: An Approach for Socially Sensitive Pretraining
LMSOC: An Approach for Socially Sensitive Pretraining Code for reproducing the paper LMSOC: An Approach for Socially Sensitive Pretraining to appear a
 11 Dec 20, 2022
11 Dec 20, 2022
A Word Level Transformer layer based on PyTorch and 🤗 Transformers.
Transformer Embedder A Word Level Transformer layer based on PyTorch and 🤗 Transformers. How to use Install the library from PyPI: pip install transf
 27 Nov 20, 2022
27 Nov 20, 2022

PICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks
Code for the paper "PICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks" (ICPR 2020)
 498 Dec 24, 2022
498 Dec 24, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
 114 Jan 6, 2023
114 Jan 6, 2023

Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
Finetuner allows one to tune the weights of any deep neural network for better embeddings on search tasks
 794 Dec 31, 2022
794 Dec 31, 2022
Vector AI — A platform for building vector based applications. Encode, query and analyse data using vectors.
Vector AI is a framework designed to make the process of building production grade vector based applications as quickly and easily as possible. Create
 267 Dec 23, 2022
267 Dec 23, 2022

EMNLP'2021: SimCSE: Simple Contrastive Learning of Sentence Embeddings
SimCSE: Simple Contrastive Learning of Sentence Embeddings This repository contains the code and pre-trained models for our paper SimCSE: Simple Contr
 2.5k Dec 29, 2022
2.5k Dec 29, 2022
The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization
PRIMER The official code for PRIMER: Pyramid-based Masked Sentence Pre-training for Multi-document Summarization. PRIMER is a pre-trained model for mu
111 Dec 18, 2022
One implementation of the paper "DMRST: A Joint Framework for Document-Level Multilingual RST Discourse Segmentation and Parsing".
Introduction One implementation of the paper "DMRST: A Joint Framework for Document-Level Multilingual RST Discourse Segmentation and Parsing". Users
 18 Dec 11, 2022
18 Dec 11, 2022
Code for ICML2019 Paper "Compositional Invariance Constraints for Graph Embeddings"
Dependencies NOTE: This code has been updated, if you were using this repo earlier and experienced issues that was due to an outaded codebase. Please
 43 Nov 25, 2022
43 Nov 25, 2022

Styled Handwritten Text Generation with Transformers (ICCV 21)
⚡ Handwriting Transformers [PDF] Ankan Kumar Bhunia, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Fahad Shahbaz Khan & Mubarak Shah Abstract: We
 85 Dec 22, 2022
85 Dec 22, 2022

Web Scraping, Document Deduplication & GPT-2 Fine-tuning with a newly created scam dataset.
Web Scraping, Document Deduplication & GPT-2 Fine-tuning with a newly created scam dataset.
 18 Nov 28, 2022
18 Nov 28, 2022
Using contrastive learning and OpenAI's CLIP to find good embeddings for images with lossy transformations
Creating Robust Representations from Pre-Trained Image Encoders using Contrastive Learning Sriram Ravula, Georgios Smyrnis This is the code for our pr
 26 Dec 10, 2022
26 Dec 10, 2022
A cross-document event and entity coreference resolution system, trained and evaluated on the ECB+ corpus.
A Comprehensive Comparison of Word Embeddings in Event & Entity Coreference Resolution. Introduction This repo contains experimental code derived from
 2 May 9, 2022
2 May 9, 2022
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia.
BPEmb is a collection of pre-trained subword embeddings in 275 languages, based on Byte-Pair Encoding (BPE) and trained on Wikipedia. Its intended use is as input for neural models in natural language processing.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023
Docbarcodes extracts 1D and 2D barcodes from scanned PDF documents or images. It can be used to automate extraction and processing of all kind of documents.
Intro Barcodes are being used in many documents or forms to enable machine reading capabilities and reduce manual processing effort. Simple 1D barcode
 3 Jun 18, 2022
3 Jun 18, 2022
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022

Document Web APIs made with Django Rest Framework
DRF Docs Document Web APIs made with Django Rest Framework. View Demo Contributors Wanted: Do you like this project? Using it? Let's make it better! S
 626 Nov 20, 2022
626 Nov 20, 2022
Mayan EDMS is a document management system.
Mayan EDMS is a document management system. Its main purpose is to store, introspect, and categorize files, with a strong emphasis on preserving the contextual and business information of documents. It can also OCR, preview, label, sign, send, and receive thoses files.
 3 Oct 2, 2021
3 Oct 2, 2021

Implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTorch
Neural Distance Embeddings for Biological Sequences Official implementation of Neural Distance Embeddings for Biological Sequences (NeuroSEED) in PyTo
 56 Dec 23, 2022
56 Dec 23, 2022
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
docTR by Mindee (Document Text Recognition) - a seamless, high-performing & accessible library for OCR-related tasks powered by Deep Learning.
 1.5k Jan 1, 2023
1.5k Jan 1, 2023

A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
 488 Nov 28, 2022
488 Nov 28, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
 586 Dec 24, 2022
586 Dec 24, 2022

PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
 1.6k Dec 25, 2022
1.6k Dec 25, 2022
Original implementation of the pooling method introduced in "Speaker embeddings by modeling channel-wise correlations"
Speaker-Embeddings-Correlation-Pooling This is the original implementation of the pooling method introduced in "Speaker embeddings by modeling channel
 10 Apr 30, 2022
10 Apr 30, 2022
Applying "Load What You Need: Smaller Versions of Multilingual BERT" to LaBSE
smaller-LaBSE LaBSE(Language-agnostic BERT Sentence Embedding) is a very good method to get sentence embeddings across languages. But it is hard to fi
 13 Sep 2, 2022
13 Sep 2, 2022

The project is investigating methods to extract human-marked data from document forms such as surveys and tests.
The project is investigating methods to extract human-marked data from document forms such as surveys and tests. They can read questions, multiple-choice exam papers, and grade.
 5 Mar 27, 2022
5 Mar 27, 2022

Embeddinghub is a database built for machine learning embeddings.
Embeddinghub is a database built for machine learning embeddings.
 1.2k Jan 1, 2023
1.2k Jan 1, 2023

CDLA: A Chinese document layout analysis (CDLA) dataset
CDLA: A Chinese document layout analysis (CDLA) dataset 介绍 CDLA是一个中文文档版面分析数据集,面向中文文献类(论文)场景。包含以下10个label: 正文 标题 图片 图片标题 表格 表格标题 页眉 页脚 注释 公式 Text Title
 84 Dec 28, 2022
84 Dec 28, 2022
NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking
pretrain4ir_tutorial NLPIR tutorial: pretrain for IR. pre-train on raw textual corpus, fine-tune on MS MARCO Document Ranking 用作NLPIR实验室, Pre-training
 12 Apr 7, 2022
12 Apr 7, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
7.6k Jan 1, 2023
This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced in the paper titled "BanglaBERT: Combating Embedding Barrier in Multilingual Models for Low-Resource Language Understanding".
BanglaBERT This repository contains the official release of the model "BanglaBERT" and associated downstream finetuning code and datasets introduced i
 197 Dec 25, 2022
197 Dec 25, 2022
🍊 PAUSE (Positive and Annealed Unlabeled Sentence Embedding), accepted by EMNLP'2021 🌴
PAUSE: Positive and Annealed Unlabeled Sentence Embedding Sentence embedding refers to a set of effective and versatile techniques for converting raw
 21 Dec 15, 2022
21 Dec 15, 2022

Document processing using transformers
Doc Transformers Document processing using transformers. This is still in developmental phase, currently supports only extraction of form data i.e (ke
 13 Dec 21, 2022
13 Dec 21, 2022
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
txtai executes machine-learning workflows to transform data and build AI-powered semantic search applications.
3.1k Dec 31, 2022
PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
Improving Visual-Semantic Embeddings with Hard Negatives Code for the image-caption retrieval methods from VSE++: Improving Visual-Semantic Embeddings
 441 Dec 5, 2022
441 Dec 5, 2022

Korean Simple Contrastive Learning of Sentence Embeddings using SKT KoBERT and kakaobrain KorNLU dataset
KoSimCSE Korean Simple Contrastive Learning of Sentence Embeddings implementation using pytorch SimCSE Installation git clone https://github.com/BM-K/
 34 Nov 24, 2022
34 Nov 24, 2022

Learning Compatible Embeddings, ICCV 2021
LCE Learning Compatible Embeddings, ICCV 2021 by Qiang Meng, Chixiang Zhang, Xiaoqiang Xu and Feng Zhou Paper: Arxiv We cannot release source codes pu
 25 Dec 17, 2022
25 Dec 17, 2022
Large scale embeddings on a single machine.
Marius Marius is a system under active development for training embeddings for large-scale graphs on a single machine. Training on large scale graphs
 107 Jan 3, 2023
107 Jan 3, 2023

Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
Genalog is an open source, cross-platform python package allowing generation of synthetic document images with custom degradations and text alignment capabilities.
235 Dec 22, 2022

Dewarping Document Image By Displacement Flow Estimation with Fully Convolutional Network
Dewarping Document Image By Displacement Flow Estimation with Fully Convolutional Network
 39 Aug 2, 2021
39 Aug 2, 2021
Hierarchical Metadata-Aware Document Categorization under Weak Supervision (WSDM'21)
Hierarchical Metadata-Aware Document Categorization under Weak Supervision This project provides a weakly supervised framework for hierarchical metada
 53 Sep 17, 2022
53 Sep 17, 2022
Versatile Generative Language Model
Versatile Generative Language Model This is the implementation of the paper: Exploring Versatile Generative Language Model Via Parameter-Efficient Tra
 17 Dec 2, 2022
17 Dec 2, 2022
PyTorch implementation of the NIPS-17 paper "Poincaré Embeddings for Learning Hierarchical Representations"
Poincaré Embeddings for Learning Hierarchical Representations PyTorch implementation of Poincaré Embeddings for Learning Hierarchical Representations
1.6k Dec 29, 2022
Convolutional 2D Knowledge Graph Embeddings resources
ConvE Convolutional 2D Knowledge Graph Embeddings resources. Paper: Convolutional 2D Knowledge Graph Embeddings Used in the paper, but do not use thes
586 Dec 24, 2022
A Structured Self-attentive Sentence Embedding
Structured Self-attentive sentence embeddings Implementation for the paper A Structured Self-Attentive Sentence Embedding, which was published in ICLR
488 Nov 28, 2022
organize - The file management automation tool
organize - The file management automation tool
 1.5k Jan 1, 2023
1.5k Jan 1, 2023
REST API for sentence tokenization and embedding using Multilingual Universal Sentence Encoder.
MUSE stands for Multilingual Universal Sentence Encoder - multilingual extension (supports 16 languages) of Universal Sentence Encoder (USE).
 47 Sep 5, 2022
47 Sep 5, 2022

A PyTorch Implementation of "Watch Your Step: Learning Node Embeddings via Graph Attention" (NeurIPS 2018).
Attention Walk ⠀⠀ A PyTorch Implementation of Watch Your Step: Learning Node Embeddings via Graph Attention (NIPS 2018). Abstract Graph embedding meth
 303 Dec 9, 2022
303 Dec 9, 2022
Official source for spanish Language Models and resources made @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish Language Models 💃🏻 Corpora 📃 Corpora Number of documents Size (GB) BNE 201,080,084 570GB Models 🤖 RoBERTa-base BNE: https://huggingface.co
203 Dec 20, 2022
Command line program to download documents from web portals.
command line document download made easy Highlights list available documents in json format or download them filter documents using string matching re
 16 Dec 26, 2022
16 Dec 26, 2022
DRIFT is a tool for Diachronic Analysis of Scientific Literature.
About DRIFT is a tool for Diachronic Analysis of Scientific Literature. The application offers user-friendly and customizable utilities for two modes:
 108 Dec 12, 2022
108 Dec 12, 2022
Dewarping Document Image By Displacement Flow Estimation with Fully Convolutional Network.
Dewarping Document Image By Displacement Flow Estimation with Fully Convolutional Network
111 Dec 27, 2022
Implementation of Rotary Embeddings, from the Roformer paper, in Pytorch
Rotary Embeddings - Pytorch A standalone library for adding rotary embeddings to transformers in Pytorch, following its success as relative positional
 110 Dec 30, 2022
110 Dec 30, 2022
Code and dataset for ACL2018 paper "Exploiting Document Knowledge for Aspect-level Sentiment Classification"
Aspect-level Sentiment Classification Code and dataset for ACL2018 [paper] ‘‘Exploiting Document Knowledge for Aspect-level Sentiment Classification’’
 146 Nov 29, 2022
146 Nov 29, 2022
🤖 A Python library for learning and evaluating knowledge graph embeddings
PyKEEN PyKEEN (Python KnowlEdge EmbeddiNgs) is a Python package designed to train and evaluate knowledge graph embedding models (incorporating multi-m
 1.1k Jan 9, 2023
1.1k Jan 9, 2023

SDL: Synthetic Document Layout dataset
SDL is the project that synthesizes document images. It facilitates multiple-level labeling on document images and can generate in multiple languages.
 0 Oct 7, 2021
0 Oct 7, 2021
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
This is my reading list for my PhD in AI, NLP, Deep Learning and more.
 156 Dec 21, 2022
156 Dec 21, 2022
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
 152 Oct 29, 2022
152 Oct 29, 2022
Shared code for training sentence embeddings with Flax / JAX
flax-sentence-embeddings This repository will be used to share code for the Flax / JAX community event to train sentence embeddings on 1B+ training pa
 23 Dec 30, 2022
23 Dec 30, 2022

Implementation for our AAAI2021 paper (Entity Structure Within and Throughout: Modeling Mention Dependencies for Document-Level Relation Extraction).
SSAN Introduction This is the pytorch implementation of the SSAN model (see our AAAI2021 paper: Entity Structure Within and Throughout: Modeling Menti
 69 Nov 15, 2022
69 Nov 15, 2022
中文无监督SimCSE Pytorch实现
A PyTorch implementation of unsupervised SimCSE SimCSE: Simple Contrastive Learning of Sentence Embeddings 1. 用法 无监督训练 python train_unsup.py ./data/ne
99 Dec 23, 2022

UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus
UmlsBERT: Clinical Domain Knowledge Augmentation of Contextual Embeddings Using the Unified Medical Language System Metathesaurus General info This is
 71 Oct 25, 2022
71 Oct 25, 2022

Reliable probability face embeddings
ProbFace, arxiv This is a demo code of training and testing [ProbFace] using Tensorflow. ProbFace is a reliable Probabilistic Face Embeddging (PFE) me
 34 Dec 31, 2022
34 Dec 31, 2022
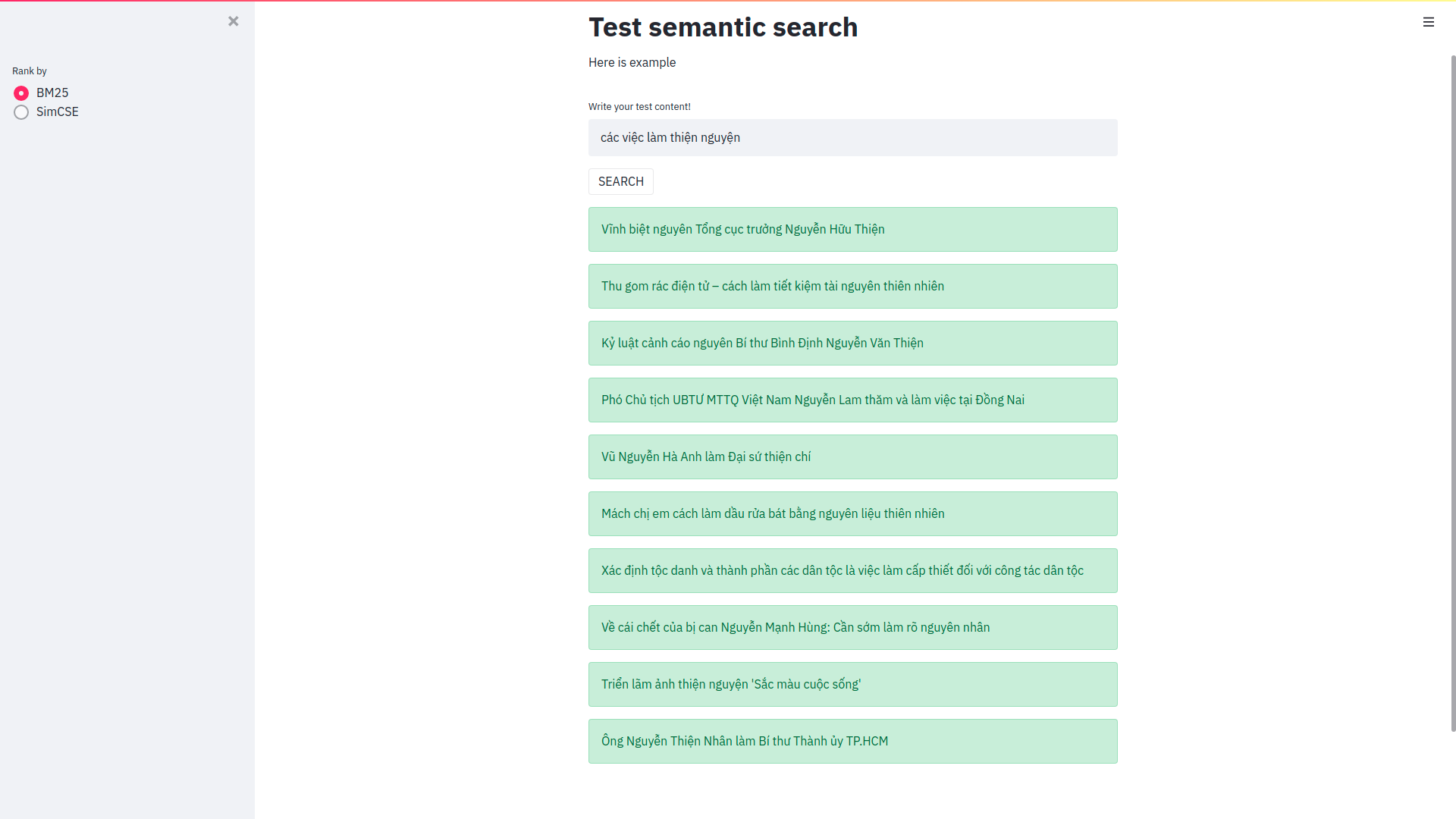
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings
Cải thiện Elasticsearch trong bài toán semantic search sử dụng phương pháp Sentence Embeddings Trong bài viết này mình sẽ sử dụng pretrain model SimCS
 18 Nov 25, 2022
18 Nov 25, 2022
Cross-Document Coreference Resolution
Cross-Document Coreference Resolution This repository contains code and models for end-to-end cross-document coreference resolution, as decribed in ou
 29 Nov 28, 2022
29 Nov 28, 2022
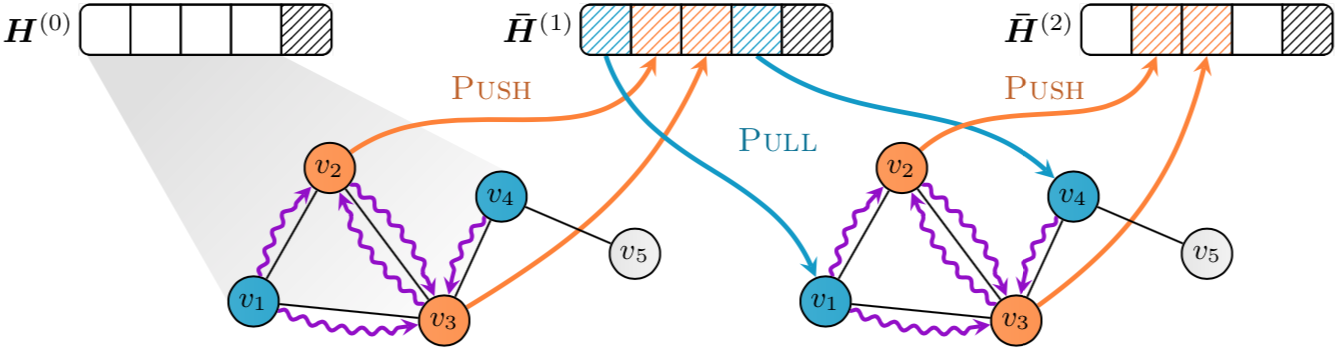
Implementation of "GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings" in PyTorch
PyGAS: Auto-Scaling GNNs in PyG PyGAS is the practical realization of our G NN A uto S cale (GAS) framework, which scales arbitrary message-passing GN
 139 Dec 25, 2022
139 Dec 25, 2022
A embed able annotation tool for end to end cross document co-reference
CoRefi CoRefi is an emebedable web component and stand alone suite for exaughstive Within Document and Cross Document Coreference Anntoation. For a de
 39 Dec 12, 2022
39 Dec 12, 2022
Source code for paper "Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling", AAAI 2021
ATLOP Code for AAAI 2021 paper Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling. If you make use of this co
 146 Nov 29, 2022
146 Nov 29, 2022