948 Repositories
Python face-dataset Libraries
Repository for the Bias Benchmark for QA dataset.
BBQ Repository for the Bias Benchmark for QA dataset. Authors: Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Tho
 18 Nov 18, 2022
18 Nov 18, 2022
A Dataset for Direct Quotation Extraction and Attribution in News Articles.
DirectQuote - A Dataset for Direct Quotation Extraction and Attribution in News Articles DirectQuote is a corpus containing 19,760 paragraphs and 10,3
 9 Sep 23, 2022
9 Sep 23, 2022

ViSD4SA, a Vietnamese Span Detection for Aspect-based sentiment analysis dataset
UIT-ViSD4SA PACLIC 35 General Introduction This repository contains the data of the paper: Span Detection for Vietnamese Aspect-Based Sentiment Analys
 5 Nov 13, 2022
5 Nov 13, 2022
Repository for MuSiQue: Multi-hop Questions via Single-hop Question Composition
🎵 MuSiQue: Multi-hop Questions via Single-hop Question Composition This is the repository for our paper "MuSiQue: Multi-hop Questions via Single-hop
 21 Jan 2, 2023
21 Jan 2, 2023

Official implementation for paper: A Latent Transformer for Disentangled Face Editing in Images and Videos.
A Latent Transformer for Disentangled Face Editing in Images and Videos Official implementation for paper: A Latent Transformer for Disentangled Face
 108 Dec 9, 2022
108 Dec 9, 2022
Coarse implement of the paper "A Simultaneous Denoising and Dereverberation Framework with Target Decoupling", On DNS-2020 dataset, the DNSMOS of first stage is 3.42 and second stage is 3.47.
SDDNet Coarse implement of the paper "A Simultaneous Denoising and Dereverberation Framework with Target Decoupling", On DNS-2020 dataset, the DNSMOS
 43 Nov 21, 2022
43 Nov 21, 2022

We have a dataset of user performances. The project is to develop a machine learning model that will predict the salaries of baseball players.
Salary-Prediction-with-Machine-Learning 1. Business Problem Can a machine learning project be implemented to estimate the salaries of baseball players
 9 Oct 14, 2022
9 Oct 14, 2022
Method for facial emotion recognition compitition of Xunfei and Datawhale .
人脸情绪识别挑战赛-第3名-W03KFgNOc-源代码、模型以及说明文档 队名:W03KFgNOc 排名:3 正确率: 0.75564 队员:yyMoming,xkwang,RichardoMu。 比赛链接:人脸情绪识别挑战赛 文章地址:link emotion 该项目分别训练八个模型并生成csv文
 6 Oct 17, 2022
6 Oct 17, 2022
Official code for Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset
Official code for our Interspeech 2021 - Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset [1]*. Visually-grounded spoken language datasets c
 3 Jan 26, 2022
3 Jan 26, 2022

Food Drinks and groceries Images Multi Lingual (FooDI-ML) dataset.
Food Drinks and groceries Images Multi Lingual (FooDI-ML) dataset.
 41 Jan 4, 2023
41 Jan 4, 2023

💛 Code and Dataset for our EMNLP 2021 paper: "Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes"
Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes Official PyTorch implementation and EmoCause evaluatio
 51 Jan 6, 2023
51 Jan 6, 2023

Code and Data for NeurIPS2021 Paper "A Dataset for Answering Time-Sensitive Questions"
Time-Sensitive-QA The repo contains the dataset and code for NeurIPS2021 (dataset track) paper Time-Sensitive Question Answering dataset. The dataset
 35 Nov 14, 2022
35 Nov 14, 2022
Repository for the Bias Benchmark for QA dataset.
BBQ Repository for the Bias Benchmark for QA dataset. Authors: Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Tho
18 Nov 18, 2022
An Agnostic Computer Vision Framework - Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come
IceVision is the first agnostic computer vision framework to offer a curated collection with hundreds of high-quality pre-trained models from torchvision, MMLabs, and soon Pytorch Image Models. It orchestrates the end-to-end deep learning workflow allowing to train networks with easy-to-use robust high-performance libraries such as Pytorch-Lightning and Fastai
 789 Dec 29, 2022
789 Dec 29, 2022
A python program to block out your face
Readme This is a small program I threw together in about 6 hours to block out your face. It probably doesn't work very well, so be warned. By default,
 1 Oct 17, 2021
1 Oct 17, 2021

Multiview 3D object detection on MultiviewC dataset through moft3d.
Multiview Orthographic Feature Transformation for 3D Object Detection Multiview 3D object detection on MultiviewC dataset through moft3d. Introduction
 20 Dec 21, 2022
20 Dec 21, 2022
Official code for Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset
Official code for our Interspeech 2021 - Spoken ObjectNet: A Bias-Controlled Spoken Caption Dataset [1]*. Visually-grounded spoken language datasets c
3 Jan 26, 2022

Human4D Dataset tools for processing and visualization
HUMAN4D: A Human-Centric Multimodal Dataset for Motions & Immersive Media HUMAN4D constitutes a large and multimodal 4D dataset that contains a variet
 15 Nov 9, 2022
15 Nov 9, 2022
Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset (CVPR'19)
Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset (CVPR'19) Tianyu Wang*, Xin Yang*, Ke Xu, Shaozhe Chen, Qiang Zhang, Ry
 177 Dec 1, 2022
177 Dec 1, 2022
Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers.
ConditionalQA Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers. Disclaimer This dataset
 2 Oct 14, 2021
2 Oct 14, 2021

Face Library is an open source package for accurate and real-time face detection and recognition
Face Library Face Library is an open source package for accurate and real-time face detection and recognition. The package is built over OpenCV and us
 52 Nov 9, 2022
52 Nov 9, 2022

This is a tool for making a every day video if you take a picture of you everyday
Face-Everyday-Maker-Studio Description This project is a tool for making a everyday video, which is timelapse video or slides video, of images but for
 9 Sep 6, 2022
9 Sep 6, 2022

Face Mask Detection on Image and Video using tensorflow and keras
Face-Mask-Detection Face Mask Detection on Image and Video using tensorflow and keras Train Neural Network on face-mask dataset using tensorflow and k
 12 Nov 11, 2022
12 Nov 11, 2022
PSML: A Multi-scale Time-series Dataset for Machine Learning in Decarbonized Energy Grids
PSML: A Multi-scale Time-series Dataset for Machine Learning in Decarbonized Energy Grids The electric grid is a key enabling infrastructure for the a
 19 Jan 7, 2023
19 Jan 7, 2023
Release of the ConditionalQA dataset
ConditionalQA Datasets accompanying the paper ConditionalQA: A Complex Reading Comprehension Dataset with Conditional Answers. Disclaimer This dataset
14 Oct 17, 2022
A cross-lingual COVID-19 fake news dataset
CrossFake An English-Chinese COVID-19 fake&real news dataset from the ICDMW 2021 paper below: Cross-lingual COVID-19 Fake News Detection. Jiangshu Du,
 11 Dec 1, 2022
11 Dec 1, 2022
Python Package for DataHerb: create, search, and load datasets.
The Python Package for DataHerb A DataHerb Core Service to Create and Load Datasets.
 4 Feb 11, 2022
4 Feb 11, 2022

A synthetic texture-invariant dataset for object detection of UAVs
A synthetic dataset for object detection of UAVs This repository contains a synthetic datasets accompanying the paper Sim2Air - Synthetic aerial datas
 10 Aug 13, 2022
10 Aug 13, 2022

Acute ischemic stroke dataset
AISD Acute ischemic stroke dataset contains 397 Non-Contrast-enhanced CT (NCCT) scans of acute ischemic stroke with the interval from symptom onset to
 21 Sep 6, 2022
21 Sep 6, 2022
TEACh is a dataset of human-human interactive dialogues to complete tasks in a simulated household environment.
TEACh is a dataset of human-human interactive dialogues to complete tasks in a simulated household environment.
 32 Oct 13, 2021
32 Oct 13, 2021
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation (NeurIPS2021 Benchmark and Dataset Track)
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation by Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zh
 174 Dec 22, 2022
174 Dec 22, 2022

This repository contains the files for running the Patchify GUI.
Repository Name Train-Test-Validation-Dataset-Generation App Name Patchify Description This app is designed for crop images and creating smal
 9 Feb 15, 2022
9 Feb 15, 2022

FACIAL: Synthesizing Dynamic Talking Face With Implicit Attribute Learning. ICCV, 2021.
FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning PyTorch implementation for the paper: FACIAL: Synthesizing Dynamic Talking
 226 Jan 8, 2023
226 Jan 8, 2023
LIVECell - A large-scale dataset for label-free live cell segmentation
LIVECell dataset This document contains instructions of how to access the data associated with the submitted manuscript "LIVECell - A large-scale data
 112 Jan 7, 2023
112 Jan 7, 2023

Face Synthetics dataset is a collection of diverse synthetic face images with ground truth labels.
The Face Synthetics dataset Face Synthetics dataset is a collection of diverse synthetic face images with ground truth labels. It was introduced in ou
 608 Jan 2, 2023
608 Jan 2, 2023

Large Scale Multi-Illuminant (LSMI) Dataset for Developing White Balance Algorithm under Mixed Illumination
Large Scale Multi-Illuminant (LSMI) Dataset for Developing White Balance Algorithm under Mixed Illumination (ICCV 2021) Dataset License This work is l
 33 Jan 4, 2023
33 Jan 4, 2023

classification task on dataset-CIFAR10,by using Tensorflow/keras
CIFAR10-Tensorflow classification task on dataset-CIFAR10,by using Tensorflow/keras 在这一个库中,我使用Tensorflow与keras框架搭建了几个卷积神经网络模型,针对CIFAR10数据集进行了训练与测试。分别使
 3 Oct 17, 2021
3 Oct 17, 2021
PyTorch implementation of DUL (Data Uncertainty Learning in Face Recognition, CVPR2020)
PyTorch implementation of DUL (Data Uncertainty Learning in Face Recognition, CVPR2020)
 20 Nov 15, 2022
20 Nov 15, 2022

A 10000+ hours dataset for Chinese speech recognition
WenetSpeech Official website | Paper A 10000+ Hours Multi-domain Chinese Corpus for Speech Recognition Download Please visit the official website, rea
 310 Jan 3, 2023
310 Jan 3, 2023

 200 Dec 27, 2022
200 Dec 27, 2022
(CVPR 2021) Lifting 2D StyleGAN for 3D-Aware Face Generation
Lifting 2D StyleGAN for 3D-Aware Face Generation Official implementation of paper "Lifting 2D StyleGAN for 3D-Aware Face Generation". Requirements You
 66 Nov 29, 2022
66 Nov 29, 2022
TEACh is a dataset of human-human interactive dialogues to complete tasks in a simulated household environment.
TEACh Task-driven Embodied Agents that Chat Aishwarya Padmakumar*, Jesse Thomason*, Ayush Shrivastava, Patrick Lange, Anjali Narayan-Chen, Spandana Ge
98 Dec 9, 2022
Exploratory Data Analysis for Employee Retention Dataset
Exploratory Data Analysis for Employee Retention Dataset Employee turn-over is a very costly problem for companies. The cost of replacing an employee
 2 Oct 1, 2021
2 Oct 1, 2021
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
An easy-to-use Python module that helps you to extract the BERT embeddings for a large text dataset (Bengali/English) efficiently.
 37 Sep 5, 2022
37 Sep 5, 2022
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English ⚖️ 🏆 🧑🎓 👩⚖️ Dataset Summary Inspired by the recent widespread use of th
 95 Dec 8, 2022
95 Dec 8, 2022

This project contains an implemented version of Face Detection using OpenCV and Mediapipe. This is a code snippet and can be used in projects.
Live-Face-Detection Project Description: In this project, we will be using the live video feed from the camera to detect Faces. It will also detect so
 3 Oct 2, 2021
3 Oct 2, 2021
EMNLP 2021: Single-dataset Experts for Multi-dataset Question-Answering
MADE (Multi-Adapter Dataset Experts) This repository contains the implementation of MADE (Multi-adapter dataset experts), which is described in the pa
 39 Oct 5, 2021
39 Oct 5, 2021

TensorFlow implementation of "Variational Inference with Normalizing Flows"
[TensorFlow 2] Variational Inference with Normalizing Flows TensorFlow implementation of "Variational Inference with Normalizing Flows" [1] Concept Co
 7 Jun 8, 2022
7 Jun 8, 2022
Script to generate VAD dataset used in Asteroid recipe
About the dataset LibriVAD is an open source dataset for voice activity detection in noisy environments. It is derived from LibriSpeech signals (clean
 11 Sep 15, 2022
11 Sep 15, 2022

Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E. Evaluated on benchmark dataset Office31.
Deep-Unsupervised-Domain-Adaptation Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E.
 49 Dec 20, 2022
49 Dec 20, 2022
EMNLP 2021: Single-dataset Experts for Multi-dataset Question-Answering
MADE (Multi-Adapter Dataset Experts) This repository contains the implementation of MADE (Multi-adapter dataset experts), which is described in the pa
68 Jul 18, 2022
Deep Face Recognition in PyTorch
Face Recognition in PyTorch By Alexey Gruzdev and Vladislav Sovrasov Introduction A repository for different experimental Face Recognition models such
 141 Sep 11, 2022
141 Sep 11, 2022
GANimation: Anatomically-aware Facial Animation from a Single Image (ECCV'18 Oral) [PyTorch]
GANimation: Anatomically-aware Facial Animation from a Single Image [Project] [Paper] Official implementation of GANimation. In this work we introduce
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

🔥🔥High-Performance Face Recognition Library on PaddlePaddle & PyTorch🔥🔥
face.evoLVe: High-Performance Face Recognition Library based on PaddlePaddle & PyTorch Evolve to be more comprehensive, effective and efficient for fa
 3.1k Jan 2, 2023
3.1k Jan 2, 2023

A (PyTorch) imbalanced dataset sampler for oversampling low frequent classes and undersampling high frequent ones.
Imbalanced Dataset Sampler Introduction In many machine learning applications, we often come across datasets where some types of data may be seen more
 2k Jan 8, 2023
2k Jan 8, 2023
A 10000+ hours dataset for Chinese speech recognition
A 10000+ hours dataset for Chinese speech recognition
309 Dec 16, 2022

Quickly and easily create / train a custom DeepDream model
Dream-Creator This project aims to simplify the process of creating a custom DeepDream model by using pretrained GoogleNet models and custom image dat
 56 Jan 3, 2023
56 Jan 3, 2023
A GUI for Face Recognition, based upon Docker, Tkinter, GPU and a camera device.
Face Recognition GUI This repository is a GUI version of Face Recognition by Adam Geitgey, where e.g. Docker and Tkinter are utilized. All the materia
 6 Dec 5, 2022
6 Dec 5, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022
PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization using Augmented-Self Reference and Dense Semantic Correspondence) and pre-trained model on ImageNet dataset
Reference-Based-Sketch-Image-Colorization-ImageNet This is a PyTorch implementation of CVPR 2020 paper (Reference-Based Sketch Image Colorization usin
 11 Jul 28, 2022
11 Jul 28, 2022

Swapping face using Face Mesh with TensorFlow Lite
Swapping face using Face Mesh with TensorFlow Lite
 17 Apr 26, 2022
17 Apr 26, 2022
Add filters (background blur, etc) to your webcam on Linux.
Add filters (background blur, etc) to your webcam on Linux.
 480 Dec 14, 2022
480 Dec 14, 2022
PyTorch Language Model for 1-Billion Word (LM1B / GBW) Dataset
PyTorch Large-Scale Language Model A Large-Scale PyTorch Language Model trained on the 1-Billion Word (LM1B) / (GBW) dataset Latest Results 39.98 Perp
 114 Nov 4, 2022
114 Nov 4, 2022

CropImage is a simple toolkit for image cropping, detecting and cropping main body from pictures.
CropImage is a simple toolkit for image cropping, detecting and cropping main body from pictures. Support face and saliency detection.
 15 Dec 22, 2022
15 Dec 22, 2022

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022

The PASS dataset: pretrained models and how to get the data - PASS: Pictures without humAns for Self-Supervised Pretraining
The PASS dataset: pretrained models and how to get the data - PASS: Pictures without humAns for Self-Supervised Pretraining
 249 Dec 22, 2022
249 Dec 22, 2022
A crowdsourced dataset of dialogues grounded in social contexts involving utilization of commonsense.
A crowdsourced dataset of dialogues grounded in social contexts involving utilization of commonsense.
62 Dec 20, 2022

Unofficial implementation of One-Shot Free-View Neural Talking Head Synthesis
face-vid2vid Usage Dataset Preparation cd datasets wget https://yt-dl.org/downloads/latest/youtube-dl -O youtube-dl chmod a+rx youtube-dl python load_
 68 Dec 30, 2022
68 Dec 30, 2022
In this repository we have tested 3 VQA models on the ImageCLEF-2019 dataset.
Med-VQA In this repository we have tested 3 VQA models on the ImageCLEF-2019 dataset. Two of these are made on top of Facebook AI Reasearch's Multi-Mo
 8 Apr 14, 2022
8 Apr 14, 2022

A simple PyTorch Implementation of Generative Adversarial Networks, focusing on anime face drawing.
AnimeGAN A simple PyTorch Implementation of Generative Adversarial Networks, focusing on anime face drawing. Randomly Generated Images The images are
 1.2k Jan 3, 2023
1.2k Jan 3, 2023

Pixel-wise segmentation on VOC2012 dataset using pytorch.
PiWiSe Pixel-wise segmentation on the VOC2012 dataset using pytorch. FCN SegNet PSPNet UNet RefineNet For a more complete implementation of segmentati
 378 Dec 30, 2022
378 Dec 30, 2022

The tool to make NLP datasets ready to use
chazutsu photo from Kaikado, traditional Japanese chazutsu maker chazutsu is the dataset downloader for NLP. import chazutsu r = chazutsu.data
 243 Dec 29, 2022
243 Dec 29, 2022
Faker is a Python package that generates fake data for you.
Faker is a Python package that generates fake data for you. Whether you need to bootstrap your database, create good-looking XML documents, fill-in yo
 15.2k Jan 1, 2023
15.2k Jan 1, 2023
Official pytorch implementation of "Scaling-up Disentanglement for Image Translation", ICCV 2021.
Official pytorch implementation of "Scaling-up Disentanglement for Image Translation", ICCV 2021.
 41 Nov 29, 2022
41 Nov 29, 2022
Code and dataset for the EMNLP 2021 Finding paper "Can NLI Models Verify QA Systems’ Predictions?"
Code and dataset for the EMNLP 2021 Finding paper "Can NLI Models Verify QA Systems’ Predictions?"
 22 Oct 21, 2022
22 Oct 21, 2022

Learnable Multi-level Frequency Decomposition and Hierarchical Attention Mechanism for Generalized Face Presentation Attack Detection
LMFD-PAD Note This is the official repository of the paper: LMFD-PAD: Learnable Multi-level Frequency Decomposition and Hierarchical Attention Mechani
 28 Dec 2, 2022
28 Dec 2, 2022
💛 Code and Dataset for our EMNLP 2021 paper: "Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes"
Perspective-taking and Pragmatics for Generating Empathetic Responses Focused on Emotion Causes Official PyTorch implementation and EmoCause evaluatio
50 Dec 21, 2022
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
S3-plugin is a high performance PyTorch dataset library to efficiently access datasets stored in S3 buckets.
 138 Jan 3, 2023
138 Jan 3, 2023

Sample and Computation Redistribution for Efficient Face Detection
Introduction SCRFD is an efficient high accuracy face detection approach which initially described in Arxiv. Performance Precision, flops and infer ti
 13 Mar 5, 2022
13 Mar 5, 2022

Abstractive opinion summarization system (SelSum) and the largest dataset of Amazon product summaries (AmaSum). EMNLP 2021 conference paper.
Learning Opinion Summarizers by Selecting Informative Reviews This repository contains the codebase and the dataset for the corresponding EMNLP 2021
 39 Jan 1, 2023
39 Jan 1, 2023

CDLA: A Chinese document layout analysis (CDLA) dataset
CDLA: A Chinese document layout analysis (CDLA) dataset 介绍 CDLA是一个中文文档版面分析数据集,面向中文文献类(论文)场景。包含以下10个label: 正文 标题 图片 图片标题 表格 表格标题 页眉 页脚 注释 公式 Text Title
 84 Dec 28, 2022
84 Dec 28, 2022
A daily updated JSON dataset of all the Open House London venues, events, and metadata
Open House London listings data All of it. Automatically scraped hourly with updates committed to git, autogenerated per-day CSV's, and autogenerated
 4 Jan 1, 2022
4 Jan 1, 2022
A set of tools for converting a darknet dataset to COCO format working with YOLOX
darknet格式数据→COCO darknet训练数据目录结构(详情参见dataset/darknet): darknet ├── class.names ├── gen_config.data ├── gen_train.txt ├── gen_valid.txt └── images
 148 Jan 3, 2023
148 Jan 3, 2023
![[Official] Exploring Temporal Coherence for More General Video Face Forgery Detection(ICCV 2021)](https://github.com/yinglinzheng/FTCN/raw/master/examples/shining.gif)
[Official] Exploring Temporal Coherence for More General Video Face Forgery Detection(ICCV 2021)
Exploring Temporal Coherence for More General Video Face Forgery Detection(FTCN) Yinglin Zheng, Jianmin Bao, Dong Chen, Ming Zeng, Fang Wen Accepted b
 57 Dec 28, 2022
57 Dec 28, 2022
A multilingual version of MS MARCO passage ranking dataset
mMARCO A multilingual version of MS MARCO passage ranking dataset This repository presents a neural machine translation-based method for translating t
 75 Dec 27, 2022
75 Dec 27, 2022
We protect the privacy of the data on your computer by using the camera of your Debian based Pardus operating system. 🕵️
Pardus Lookout We protect the privacy of the data on your computer by using the camera of your Debian based Pardus operating system. The application i
 19 Nov 18, 2022
19 Nov 18, 2022
The FinQA dataset from paper: FinQA: A Dataset of Numerical Reasoning over Financial Data
Data and code for EMNLP 2021 paper "FinQA: A Dataset of Numerical Reasoning over Financial Data"
 114 Dec 29, 2022
114 Dec 29, 2022

Face Mask Detection is a project to determine whether someone is wearing mask or not, using deep neural network.
face-mask-detection Face Mask Detection is a project to determine whether someone is wearing mask or not, using deep neural network. It contains 3 scr
 13 Jan 18, 2022
13 Jan 18, 2022

Realtime Face Anti Spoofing with Face Detector based on Deep Learning using Tensorflow/Keras and OpenCV
Realtime Face Anti-Spoofing Detection 🤖 Realtime Face Anti Spoofing Detection with Face Detector to detect real and fake faces Please star this repo
 86 Aug 3, 2022
86 Aug 3, 2022
PIZZA - a task-oriented semantic parsing dataset
The PIZZA dataset continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents.
 17 Dec 14, 2022
17 Dec 14, 2022

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on table detection and table structure recognition.
WTW-Dataset This is an official implementation for the WTW Dataset in "Parsing Table Structures in the Wild " on ICCV 2021. Here, you can download the
 109 Dec 29, 2022
109 Dec 29, 2022
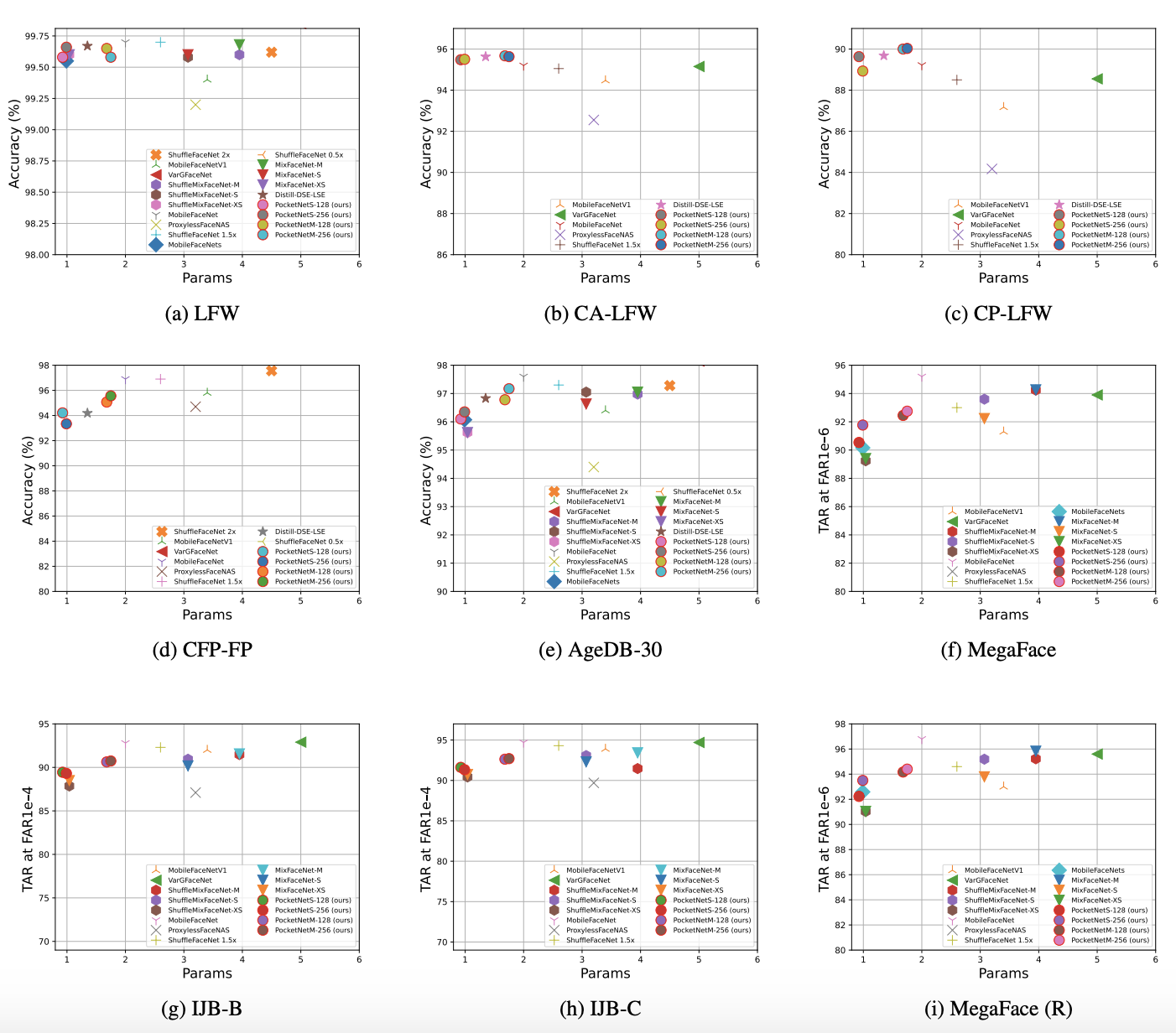
PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and Multi-Step Knowledge Distillation
PocketNet This is the official repository of the paper: PocketNet: Extreme Lightweight Face Recognition Network using Neural Architecture Search and M
 40 Dec 22, 2022
40 Dec 22, 2022
The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal and to generate far-field speech data using room impulse response data from BUT Speech@FIT Reverb Database.
Add_noise_and_rir_to_speech The purpose of this code base is to add a specified signal-to-noise ratio noise from MUSAN dataset to a pure speech signal
 7 Oct 30, 2022
7 Oct 30, 2022

Python scripts for performing stereo depth estimation using the HITNET Tensorflow model.
HITNET-Stereo-Depth-estimation Python scripts for performing stereo depth estimation using the HITNET Tensorflow model from Google Research. Stereo de
 76 Jan 2, 2023
76 Jan 2, 2023

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 91 Nov 22, 2022
91 Nov 22, 2022
Cross Quality LFW: A database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Cross-Quality Labeled Faces in the Wild (XQLFW) Here, we release the database, evaluation protocol and code for the following paper: Cross Quality LFW
 10 Dec 12, 2022
10 Dec 12, 2022
This repo uses a combination of logits and feature distillation method to teach the PSPNet model of ResNet18 backbone with the PSPNet model of ResNet50 backbone. All the models are trained and tested on the PASCAL-VOC2012 dataset.
PSPNet-logits and feature-distillation Introduction This repository is based on PSPNet and modified from semseg and Pixelwise_Knowledge_Distillation_P
 6 Dec 1, 2022
6 Dec 1, 2022
Add filters (background blur, etc) to your webcam on Linux.
webcam-filters Add filters (background blur, etc) to your webcam on Linux. Video conferencing applications tend to either lack video effects altogethe
480 Dec 14, 2022

A novel benchmark dataset for Monocular Layout prediction
AutoLay AutoLay: Benchmarking Monocular Layout Estimation Kaustubh Mani, N. Sai Shankar, J. Krishna Murthy, and K. Madhava Krishna Abstract In this pa
 39 Apr 26, 2022
39 Apr 26, 2022