2185 Repositories
Python image-to-recipe-transformers Libraries

The project is an official implementation of our paper "3D Human Pose Estimation with Spatial and Temporal Transformers".
3D Human Pose Estimation with Spatial and Temporal Transformers This repo is the official implementation for 3D Human Pose Estimation with Spatial and
 363 Dec 28, 2022
363 Dec 28, 2022

Official implementation of the paper DeFlow: Learning Complex Image Degradations from Unpaired Data with Conditional Flows
DeFlow: Learning Complex Image Degradations from Unpaired Data with Conditional Flows Official implementation of the paper DeFlow: Learning Complex Im
 86 Nov 16, 2022
86 Nov 16, 2022

Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models
Patch-Rotation(PatchRot) Patch Rotation: A Self-Supervised Auxiliary Task for Robustness and Accuracy of Supervised Models Submitted to Neurips2021 To
 4 Jul 12, 2021
4 Jul 12, 2021
Unbalanced Feature Transport for Exemplar-based Image Translation (CVPR 2021)
UNITE and UNITE+ Unbalanced Feature Transport for Exemplar-based Image Translation (CVPR 2021) Unbalanced Intrinsic Feature Transport for Exemplar-bas
 183 Nov 9, 2022
183 Nov 9, 2022

Isearch (OSINT) 🔎 Face recognition reverse image search on Instagram profile feed photos.
isearch is an OSINT tool on Instagram. Offers a face recognition reverse image search on Instagram profile feed photos.
 20 Oct 25, 2022
20 Oct 25, 2022
Jina allows you to build deep learning-powered search-as-a-service in just minutes
Cloud-native neural search framework for any kind of data
 17k Dec 31, 2022
17k Dec 31, 2022

PyTorch evaluation code for Delving Deep into the Generalization of Vision Transformers under Distribution Shifts.
Out-of-distribution Generalization Investigation on Vision Transformers This repository contains PyTorch evaluation code for Delving Deep into the Gen
 72 Dec 13, 2022
72 Dec 13, 2022

PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer
Official code Cross-Covariance Image Transformer (XCiT)
 605 Jan 2, 2023
605 Jan 2, 2023
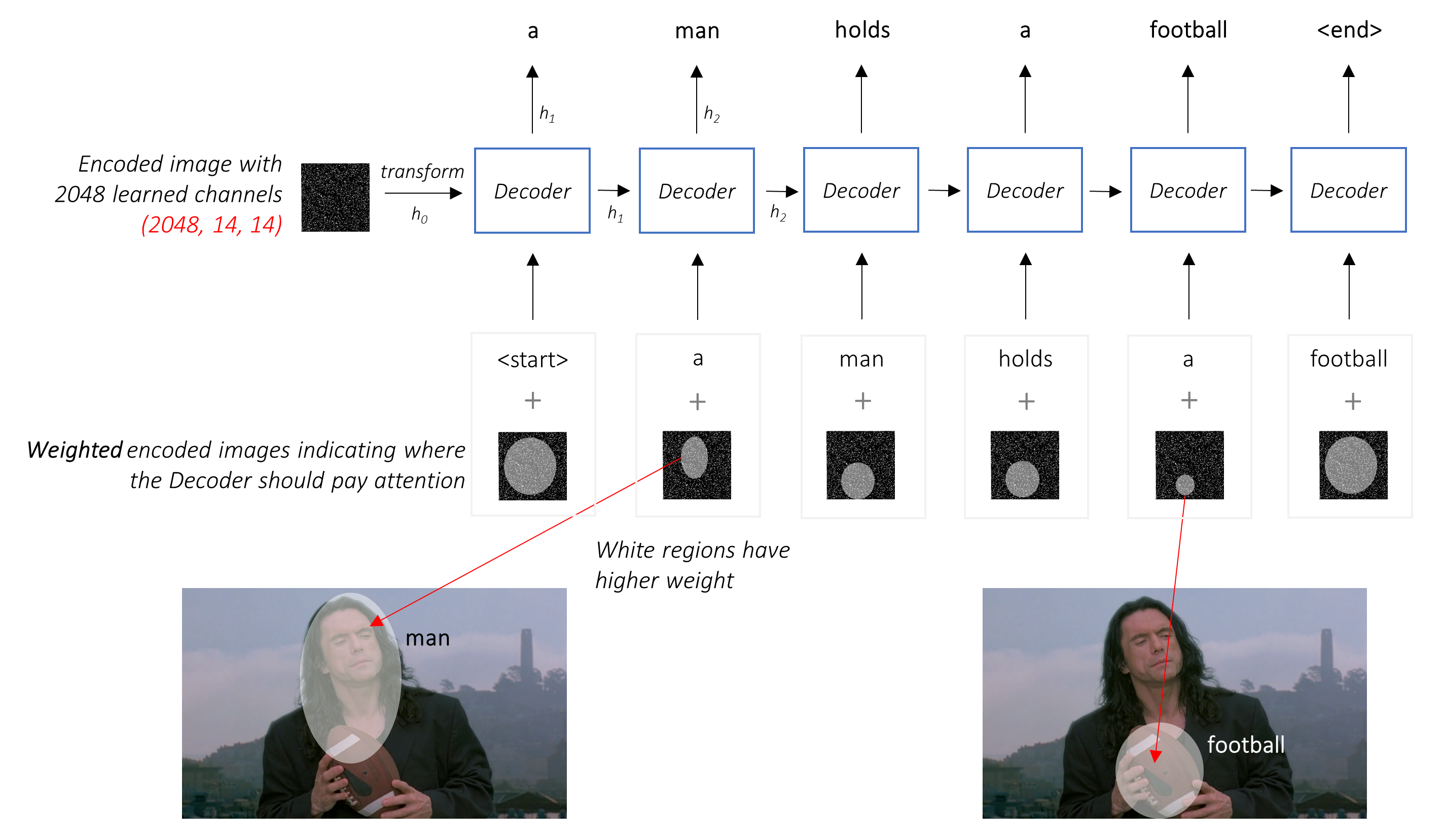
Pipeline for chemical image-to-text competition
BMS-Molecular-Translation Introduction This is a pipeline for Bristol-Myers Squibb – Molecular Translation by Vadim Timakin and Maksim Zhdanov. We got
 7 Sep 20, 2022
7 Sep 20, 2022

AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations
AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations. Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
4.6k Jan 9, 2023
PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer
Cross-Covariance Image Transformer (XCiT) PyTorch implementation and pretrained models for XCiT models. See XCiT: Cross-Covariance Image Transformer L
605 Jan 2, 2023

Implementation of Uformer, Attention-based Unet, in Pytorch
Uformer - Pytorch Implementation of Uformer, Attention-based Unet, in Pytorch. It will only offer the concat-cross-skip connection. This repository wi
 72 Dec 19, 2022
72 Dec 19, 2022

This is the PyTorch implementation of GANs N’ Roses: Stable, Controllable, Diverse Image to Image Translation
Official PyTorch repo for GAN's N' Roses. Diverse im2im and vid2vid selfie to anime translation.
 1.1k Jan 1, 2023
1.1k Jan 1, 2023
easySpeech is an open-source Python wrapper for google speech to text API that doesn't require PyAudio(So you especially windows user don't have to deal with the errors while installing PyAudio) and also works with hugging face transformers
easySpeech easySpeech is an open source python wrapper for google speech to text api that doesn't require PyAaudio(So you specially windows user don't
 14 May 24, 2022
14 May 24, 2022

Official PyTorch code for CVPR 2020 paper "Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision"
Deep Active Learning for Biased Datasets via Fisher Kernel Self-Supervision https://arxiv.org/abs/2003.00393 Abstract Active learning (AL) aims to min
 29 Nov 21, 2022
29 Nov 21, 2022
Official implementation of "SinIR: Efficient General Image Manipulation with Single Image Reconstruction" (ICML 2021)
SinIR (Official Implementation) Requirements To install requirements: pip install -r requirements.txt We used Python 3.7.4 and f-strings which are in
 47 Oct 11, 2022
47 Oct 11, 2022

Official PyTorch implementation of "Proxy Synthesis: Learning with Synthetic Classes for Deep Metric Learning" (AAAI 2021)
Proxy Synthesis: Learning with Synthetic Classes for Deep Metric Learning Official PyTorch implementation of "Proxy Synthesis: Learning with Synthetic
 30 Dec 6, 2022
30 Dec 6, 2022

Pytorch implementation of the paper SPICE: Semantic Pseudo-labeling for Image Clustering
SPICE: Semantic Pseudo-labeling for Image Clustering By Chuang Niu and Ge Wang This is a Pytorch implementation of the paper. (In updating) SOTA on 5
 154 Dec 15, 2022
154 Dec 15, 2022
An interpreter for RASP as described in the ICML 2021 paper "Thinking Like Transformers"
RASP Setup Mac or Linux Run ./setup.sh . It will create a python3 virtual environment and install the dependencies for RASP. It will also try to insta
 141 Jan 3, 2023
141 Jan 3, 2023

Polyfoto - Create image mosaics.
Polyfoto Create image mosaics. Showcase "Before and After Science" by Brian Eno "Scott 3" by Scott Walker Installation Clone this repository to your l
 149 Dec 25, 2022
149 Dec 25, 2022
2021海华AI挑战赛·中文阅读理解·技术组·第三名
文字是人类用以记录和表达的最基本工具,也是信息传播的重要媒介。透过文字与符号,我们可以追寻人类文明的起源,可以传播知识与经验,读懂文字是认识与了解的第一步。对于人工智能而言,它的核心问题之一就是认知,而认知的核心则是语义理解。
 21 Dec 26, 2022
21 Dec 26, 2022

Official implementation of "SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers"
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers Figure 1: Performance of SegFormer-B0 to SegFormer-B5. Project page
 1.4k Dec 31, 2022
1.4k Dec 31, 2022

IMGUR5K handwriting set. It is a handwritten in-the-wild dataset, which contains challenging real world handwritten samples from different writers.The dataset is shared as a set of image urls with annotations. This code downloads the images and verifies the hash to the image to avoid data contamination.
IMGUR5K Handwriting Dataset To run the code for downloading the urls and generate corresponding annotations : Usage: python download_imgur5k.py --data
213 Dec 26, 2022
Text-to-Image generation
Generate vivid Images for Any (Chinese) text CogView is a pretrained (4B-param) transformer for text-to-image generation in general domain. Read our p
 1.3k Jan 5, 2023
1.3k Jan 5, 2023
This is the official implementation for "Do Transformers Really Perform Bad for Graph Representation?".
Graphormer By Chengxuan Ying, Tianle Cai, Shengjie Luo, Shuxin Zheng*, Guolin Ke, Di He*, Yanming Shen and Tie-Yan Liu. This repo is the official impl
 1.3k Dec 29, 2022
1.3k Dec 29, 2022
Code + pre-trained models for the paper Keeping Your Eye on the Ball Trajectory Attention in Video Transformers
Motionformer This is an official pytorch implementation of paper Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers. In this rep
192 Dec 23, 2022

Tensorflow implementation of MIRNet for Low-light image enhancement
MIRNet Tensorflow implementation of the MIRNet architecture as proposed by Learning Enriched Features for Real Image Restoration and Enhancement. Lanu
 91 Jan 6, 2023
91 Jan 6, 2023

Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals
LapDepth-release This repository is a Pytorch implementation of the paper "Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals" M
 205 Dec 30, 2022
205 Dec 30, 2022
Aerial Single-View Depth Completion with Image-Guided Uncertainty Estimation (RA-L/ICRA 2020)
Aerial Depth Completion This work is described in the letter "Aerial Single-View Depth Completion with Image-Guided Uncertainty Estimation", by Lucas
 70 Dec 22, 2022
70 Dec 22, 2022
Load What You Need: Smaller Multilingual Transformers for Pytorch and TensorFlow 2.0.
Smaller Multilingual Transformers This repository shares smaller versions of multilingual transformers that keep the same representations offered by t
 79 Dec 28, 2022
79 Dec 28, 2022
![[CVPR 2021] Teachers Do More Than Teach: Compressing Image-to-Image Models (CAT)](https://github.com/snap-research/CAT/raw/main/images/comparison.png)
[CVPR 2021] Teachers Do More Than Teach: Compressing Image-to-Image Models (CAT)
CAT arXiv Pytorch implementation of our method for compressing image-to-image models. Teachers Do More Than Teach: Compressing Image-to-Image Models Q
 160 Dec 9, 2022
160 Dec 9, 2022

CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation
CoCosNet v2: Full-Resolution Correspondence Learning for Image Translation (CVPR 2021, oral presentation) CoCosNet v2: Full-Resolution Correspondence
308 Dec 7, 2022

Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch
Segformer - Pytorch Implementation of Segformer, Attention + MLP neural network for segmentation, in Pytorch. Install $ pip install segformer-pytorch
208 Dec 25, 2022

Official repository for "On Improving Adversarial Transferability of Vision Transformers" (2021)
Improving-Adversarial-Transferability-of-Vision-Transformers Muzammal Naseer, Kanchana Ranasinghe, Salman Khan, Fahad Khan, Fatih Porikli arxiv link A
 47 Dec 2, 2022
47 Dec 2, 2022

Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers.
Less is More: Pay Less Attention in Vision Transformers Official PyTorch implementation of Less is More: Pay Less Attention in Vision Transformers. By
 73 Jan 1, 2023
73 Jan 1, 2023
This is a GUI based text and image messenger. Other functionalities will be added soon.
Pigeon-Messenger (Requires Python and Kivy) Pigeon is a GUI based text and image messenger using Kivy and Python. Currently the layout is built. Funct
 4 Jan 21, 2022
4 Jan 21, 2022

CATs: Semantic Correspondence with Transformers
CATs: Semantic Correspondence with Transformers For more information, check out the paper on [arXiv]. Training with different backbones and evaluation
 74 Dec 10, 2021
74 Dec 10, 2021
A Icon Maker GUI Made - Convert your image into icon ( .ico format ).
Icon-Maker-GUI A Icon Maker GUI Made Using Python 3.9.0 . It will take any image and convert it to ICO file, for web site favicon or Windows applicati
 12 Dec 15, 2021
12 Dec 15, 2021
Self-Attention Between Datapoints: Going Beyond Individual Input-Output Pairs in Deep Learning
We challenge a common assumption underlying most supervised deep learning: that a model makes a prediction depending only on its parameters and the features of a single input. To this end, we introduce a general-purpose deep learning architecture that takes as input the entire dataset instead of processing one datapoint at a time.
 360 Dec 28, 2022
360 Dec 28, 2022

PyTorch implementation of Pay Attention to MLPs
gMLP PyTorch implementation of Pay Attention to MLPs. Quickstart Clone this repository. git clone https://github.com/jaketae/g-mlp.git Navigate to th
 34 Dec 13, 2022
34 Dec 13, 2022

ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection
ImVoxelNet: Image to Voxels Projection for Monocular and Multi-View General-Purpose 3D Object Detection This repository contains implementation of the
 190 Dec 30, 2022
190 Dec 30, 2022
EDPN: Enhanced Deep Pyramid Network for Blurry Image Restoration
EDPN: Enhanced Deep Pyramid Network for Blurry Image Restoration Ruikang Xu, Zeyu Xiao, Jie Huang, Yueyi Zhang, Zhiwei Xiong. EDPN: Enhanced Deep Pyra
 69 Dec 15, 2022
69 Dec 15, 2022

DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification Created by Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, Ch
 414 Jan 1, 2023
414 Jan 1, 2023

This is an implementation for the CVPR2020 paper "Learning Invariant Representation for Unsupervised Image Restoration"
Learning Invariant Representation for Unsupervised Image Restoration (CVPR 2020) Introduction This is an implementation for the paper "Learning Invari
 88 Nov 7, 2022
88 Nov 7, 2022
Official repository for "Intriguing Properties of Vision Transformers" (2021)
Intriguing Properties of Vision Transformers Muzammal Naseer, Kanchana Ranasinghe, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, & Ming-Hsuan Yang P
155 Dec 27, 2022

An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C.
vizh An esoteric visual language that takes image files as input based on a multi-tape turing machine, designed for compatibility with C. Overview Her
 228 Dec 17, 2022
228 Dec 17, 2022
A simple programming language for manipulating images.
f-stop A simple programming language for manipulating images. Examples OPEN "image.png" AS image RESIZE image (300, 300) SAVE image "out.jpg" CLOSE im
 6 Oct 27, 2022
6 Oct 27, 2022

Rubik's cube assistant on Flask webapp
webcube Rubik's cube assistant on Flask webapp. This webapp accepts the six faces of your cube and gives you the voice instructions as a response. Req
 56 Nov 22, 2022
56 Nov 22, 2022
Official repository for HOTR: End-to-End Human-Object Interaction Detection with Transformers (CVPR'21, Oral Presentation)
Official PyTorch Implementation for HOTR: End-to-End Human-Object Interaction Detection with Transformers (CVPR'2021, Oral Presentation) HOTR: End-to-
 114 Nov 28, 2022
114 Nov 28, 2022
This is an official implementation of CvT: Introducing Convolutions to Vision Transformers.
Introduction This is an official implementation of CvT: Introducing Convolutions to Vision Transformers. We present a new architecture, named Convolut
 175 Jan 8, 2023
175 Jan 8, 2023

simpleT5 is built on top of PyTorch-lightning⚡️ and Transformers🤗 that lets you quickly train your T5 models.
Quickly train T5 models in just 3 lines of code + ONNX support simpleT5 is built on top of PyTorch-lightning ⚡️ and Transformers 🤗 that lets you quic
 220 Dec 30, 2022
220 Dec 30, 2022
SparseML is a libraries for applying sparsification recipes to neural networks with a few lines of code, enabling faster and smaller models
SparseML is a toolkit that includes APIs, CLIs, scripts and libraries that apply state-of-the-art sparsification algorithms such as pruning and quantization to any neural network. General, recipe-driven approaches built around these algorithms enable the simplification of creating faster and smaller models for the ML performance community at large.
 1.5k Dec 30, 2022
1.5k Dec 30, 2022
Learned image compression
Overview Pytorch code of our recent work A Unified End-to-End Framework for Efficient Deep Image Compression. We first release the code for Variationa
 163 Dec 4, 2022
163 Dec 4, 2022
Code for CVPR2021 "Visualizing Adapted Knowledge in Domain Transfer". Visualization for domain adaptation. #explainable-ai
Visualizing Adapted Knowledge in Domain Transfer @inproceedings{hou2021visualizing, title={Visualizing Adapted Knowledge in Domain Transfer}, auth
 80 Dec 25, 2022
80 Dec 25, 2022
Deep Image Search - AI-Based Image Search Engine
Deep Image Search is an AI-based image search engine that includes deep transfer learning features Extraction and tree-based vectorized search technique.
 144 Jan 5, 2023
144 Jan 5, 2023

Framework for joint representation learning, evaluation through multimodal registration and comparison with image translation based approaches
CoMIR: Contrastive Multimodal Image Representation for Registration Framework 🖼 Registration of images in different modalities with Deep Learning 🤖
 55 Dec 9, 2022
55 Dec 9, 2022
Code of U2Fusion: a unified unsupervised image fusion network for multiple image fusion tasks, including multi-modal, multi-exposure and multi-focus image fusion.
U2Fusion Code of U2Fusion: a unified unsupervised image fusion network for multiple image fusion tasks, including multi-modal (VIS-IR, medical), multi
 129 Dec 11, 2022
129 Dec 11, 2022

Implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT : Cross-Attention Multi-Scale Vision Transformer for Image Classification This is an unofficial PyTorch implementation of CrossViT: Cross-Att
 103 Nov 25, 2022
103 Nov 25, 2022

Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch
12.6k Jan 9, 2023
This is an official implementation of CvT: Introducing Convolutions to Vision Transformers.
Introduction This is an official implementation of CvT: Introducing Convolutions to Vision Transformers. We present a new architecture, named Convolut
408 Dec 30, 2022

Research code for CVPR 2021 paper "End-to-End Human Pose and Mesh Reconstruction with Transformers"
MeshTransformer ✨ This is our research code of End-to-End Human Pose and Mesh Reconstruction with Transformers. MEsh TRansfOrmer is a simple yet effec
473 Dec 31, 2022
Third party Pytorch implement of Image Processing Transformer (Pre-Trained Image Processing Transformer arXiv:2012.00364v2)
ImageProcessingTransformer Third party Pytorch implement of Image Processing Transformer (Pre-Trained Image Processing Transformer arXiv:2012.00364v2)
 61 Jan 1, 2023
61 Jan 1, 2023
Medical Image Segmentation using Squeeze-and-Expansion Transformers
Medical Image Segmentation using Squeeze-and-Expansion Transformers Introduction This repository contains the code of the IJCAI'2021 paper 'Medical Im
 172 Dec 20, 2022
172 Dec 20, 2022
A list of hyperspectral image super-solution resources collected by Junjun Jiang
A list of hyperspectral image super-resolution resources collected by Junjun Jiang. If you find that important resources are not included, please feel free to contact me.
 301 Jan 5, 2023
301 Jan 5, 2023
This is the official implementation of TrivialAugment and a mini-library for the application of multiple image augmentation strategies including RandAugment and TrivialAugment.
Trivial Augment This is the official implementation of TrivialAugment (https://arxiv.org/abs/2103.10158), as was used for the paper. TrivialAugment is
 94 Dec 30, 2022
94 Dec 30, 2022
Deep Image Search is an AI-based image search engine that includes deep transfor learning features Extraction and tree-based vectorized search.
Deep Image Search - AI-Based Image Search Engine Deep Image Search is an AI-based image search engine that includes deep transfer learning features Ex
139 Jan 1, 2023
Extract MNIST handwritten digits dataset binary file into bmp images
MNIST-dataset-extractor Extract MNIST handwritten digits dataset binary file into bmp images More info at http://yann.lecun.com/exdb/mnist/ Dependenci
 6 May 24, 2021
6 May 24, 2021
Code for reproducing our analysis in the paper titled: Image Cropping on Twitter: Fairness Metrics, their Limitations, and the Importance of Representation, Design, and Agency
Image Crop Analysis This is a repo for the code used for reproducing our Image Crop Analysis paper as shared on our blog post. If you plan to use this
 239 Jan 2, 2023
239 Jan 2, 2023

Non-Official Pytorch implementation of "Face Identity Disentanglement via Latent Space Mapping" https://arxiv.org/abs/2005.07728 Using StyleGAN2 instead of StyleGAN
Face Identity Disentanglement via Latent Space Mapping - Implement in pytorch with StyleGAN 2 Description Pytorch implementation of the paper Face Ide
 58 Dec 24, 2022
58 Dec 24, 2022
PyTorch code for our paper "Attention in Attention Network for Image Super-Resolution"
Under construction... Attention in Attention Network for Image Super-Resolution (A2N) This repository is an PyTorch implementation of the paper "Atten
 71 Dec 30, 2022
71 Dec 30, 2022
Image data augmentation scheduler for albumentations transforms
albu_scheduler Scheduler for albumentations transforms based on PyTorch schedulers interface Usage TransformMultiStepScheduler import albumentations a
 19 Aug 4, 2021
19 Aug 4, 2021

A Joint Video and Image Encoder for End-to-End Retrieval
Frozen️ in Time ❄️ ️️️️ ⏳ A Joint Video and Image Encoder for End-to-End Retrieval (arXiv) Repository to contain the code, models, data for end-to-end
 225 Dec 25, 2022
225 Dec 25, 2022
MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Resolution (CVPR2021)
MASA-SR Official PyTorch implementation of our CVPR2021 paper MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Re
 126 Dec 20, 2022
126 Dec 20, 2022

Learning to Reconstruct 3D Manhattan Wireframes from a Single Image
Learning to Reconstruct 3D Manhattan Wireframes From a Single Image This repository contains the PyTorch implementation of the paper: Yichao Zhou, Hao
 50 Dec 27, 2022
50 Dec 27, 2022
Pytorch code for ICRA'21 paper: "Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation"
Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation This repository is the pytorch implementation of our paper: Hierarchical Cr
 44 Jan 6, 2023
44 Jan 6, 2023
Finding an Unsupervised Image Segmenter in each of your Deep Generative Models
Finding an Unsupervised Image Segmenter in each of your Deep Generative Models Description Recent research has shown that numerous human-interpretable
 61 Oct 17, 2022
61 Oct 17, 2022
Contains code for the paper "Vision Transformers are Robust Learners".
Vision Transformers are Robust Learners This repository contains the code for the paper Vision Transformers are Robust Learners by Sayak Paul* and Pin
 103 Jan 5, 2023
103 Jan 5, 2023
![[CVPRW 2021] Code for Region-Adaptive Deformable Network for Image Quality Assessment](https://github.com/IIGROUP/RADN/raw/main/Figures/architecture.png)
[CVPRW 2021] Code for Region-Adaptive Deformable Network for Image Quality Assessment
RADN [CVPRW 2021] Code for Region-Adaptive Deformable Network for Image Quality Assessment [Paper on arXiv] Overview Update [2021/5/7] add codes for W
 53 Dec 28, 2022
53 Dec 28, 2022

Text to Image Generation with Semantic-Spatial Aware GAN
text2image This repository includes the implementation for Text to Image Generation with Semantic-Spatial Aware GAN This repo is not completely. Netwo
 124 Dec 30, 2022
124 Dec 30, 2022
Standalone pre-training recipe with JAX+Flax
Sabertooth Sabertooth is standalone pre-training recipe based on JAX+Flax, with data pipelines implemented in Rust. It runs on CPU, GPU, and/or TPU, b
 26 Nov 28, 2022
26 Nov 28, 2022
Train 🤗transformers with DeepSpeed: ZeRO-2, ZeRO-3
Fork from https://github.com/huggingface/transformers/tree/86d5fb0b360e68de46d40265e7c707fe68c8015b/examples/pytorch/language-modeling at 2021.05.17.
 12 Oct 26, 2022
12 Oct 26, 2022
XtremeDistil framework for distilling/compressing massive multilingual neural network models to tiny and efficient models for AI at scale
XtremeDistilTransformers for Distilling Massive Multilingual Neural Networks ACL 2020 Microsoft Research [Paper] [Video] Releasing [XtremeDistilTransf
125 Jan 4, 2023

Code for Referring Image Segmentation via Cross-Modal Progressive Comprehension, CVPR2020.
CMPC-Refseg Code of our CVPR 2020 paper Referring Image Segmentation via Cross-Modal Progressive Comprehension. Shaofei Huang*, Tianrui Hui*, Si Liu,
 55 Dec 1, 2022
55 Dec 1, 2022

Implementation of gMLP, an all-MLP replacement for Transformers, in Pytorch
Implementation of gMLP, an all-MLP replacement for Transformers, in Pytorch
383 Jan 2, 2023

This repository contains PyTorch code for Robust Vision Transformers.
This repository contains PyTorch code for Robust Vision Transformers.
 117 Dec 7, 2022
117 Dec 7, 2022
A PaddlePaddle version image model zoo.
Paddle-Image-Models English | 简体中文 A PaddlePaddle version image model zoo. Install Package Install by pip: $ pip install ppim Install by wheel package
 131 Dec 7, 2022
131 Dec 7, 2022
Implementation of Stochastic Image-to-Video Synthesis using cINNs.
Stochastic Image-to-Video Synthesis using cINNs Official PyTorch implementation of Stochastic Image-to-Video Synthesis using cINNs accepted to CVPR202
 135 Dec 28, 2022
135 Dec 28, 2022

HINet: Half Instance Normalization Network for Image Restoration
HINet: Half Instance Normalization Network for Image Restoration Liangyu Chen, Xin Lu, Jie Zhang, Xiaojie Chu, Chengpeng Chen Paper: https://arxiv.org
 303 Dec 31, 2022
303 Dec 31, 2022

PyMatting: A Python Library for Alpha Matting
Given an input image and a hand-drawn trimap (top row), alpha matting estimates the alpha channel of a foreground object which can then be composed onto a different background (bottom row).
 1.4k Dec 30, 2022
1.4k Dec 30, 2022

Unofficial implementation of MLP-Mixer: An all-MLP Architecture for Vision
MLP-Mixer: An all-MLP Architecture for Vision This repo contains PyTorch implementation of MLP-Mixer: An all-MLP Architecture for Vision. Usage : impo
175 Dec 23, 2022
RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition
RepMLP RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition Released the code of RepMLP together with an example o
 260 Jan 3, 2023
260 Jan 3, 2023

Official implement of Paper:A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sening images
A deeply supervised image fusion network for change detection in high resolution bi-temporal remote sensing images 深度监督影像融合网络DSIFN用于高分辨率双时相遥感影像变化检测 Of
 135 Dec 19, 2022
135 Dec 19, 2022

Unofficial implementation of Google's FNet: Mixing Tokens with Fourier Transforms
FNet: Mixing Tokens with Fourier Transforms Pytorch implementation of Fnet : Mixing Tokens with Fourier Transforms. Citation: @misc{leethorp2021fnet,
218 Jan 5, 2023

CellProfiler is a open-source application for biological image analysis
CellProfiler is a free open-source software designed to enable biologists without training in computer vision or programming to quantitatively measure phenotypes from thousands of images automatically.
 732 Dec 23, 2022
732 Dec 23, 2022

Implementation of ResMLP, an all MLP solution to image classification, in Pytorch
ResMLP - Pytorch Implementation of ResMLP, an all MLP solution to image classification out of Facebook AI, in Pytorch Install $ pip install res-mlp-py
178 Dec 2, 2022
This is the codebase for Diffusion Models Beat GANS on Image Synthesis.
This is the codebase for Diffusion Models Beat GANS on Image Synthesis.
 3k Dec 26, 2022
3k Dec 26, 2022
This is a Computer vision package that makes its easy to run Image processing and AI functions. At the core it uses OpenCV and Mediapipe libraries.
CVZone This is a Computer vision package that makes its easy to run Image processing and AI functions. At the core it uses OpenCV and Mediapipe librar
 648 Dec 30, 2022
648 Dec 30, 2022

Vision Transformer for 3D medical image registration (Pytorch).
ViT-V-Net: Vision Transformer for Volumetric Medical Image Registration keywords: vision transformer, convolutional neural networks, image registratio
 192 Dec 20, 2022
192 Dec 20, 2022

TrackFormer: Multi-Object Tracking with Transformers
TrackFormer: Multi-Object Tracking with Transformers This repository provides the official implementation of the TrackFormer: Multi-Object Tracking wi
 321 Dec 29, 2022
321 Dec 29, 2022

Exploring whether attention is necessary for vision transformers
Do You Even Need Attention? A Stack of Feed-Forward Layers Does Surprisingly Well on ImageNet Paper/Report TL;DR We replace the attention layer in a v
461 Jan 7, 2023