579 Repositories
Python large-scale-ITE-UM-benchmark Libraries

WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
WIT (Wikipedia-based Image Text) Dataset is a large multimodal multilingual dataset comprising 37M+ image-text sets with 11M+ unique images across 100+ languages.
 740 Dec 24, 2022
740 Dec 24, 2022

Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
Silero Models: pre-trained speech-to-text, text-to-speech models and benchmarks made embarrassingly simple
 3.2k Dec 31, 2022
3.2k Dec 31, 2022

Official code for 'Robust Siamese Object Tracking for Unmanned Aerial Manipulator' and offical introduction to UAMT100 benchmark
SiamSA: Robust Siamese Object Tracking for Unmanned Aerial Manipulator Demo video 📹 Our video on Youtube and bilibili demonstrates the evaluation of
 12 Dec 18, 2022
12 Dec 18, 2022
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files
wireguard-config-benchmark is a python script that benchmarks the download speeds for the connections defined in one or more wireguard config files. If multiple configs are benchmarked it will output a file ranking them from fastest to slowest.
 12 May 7, 2022
12 May 7, 2022
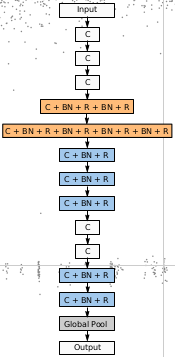
This implements one of result networks from Large-scale evolution of image classifiers
Exotic structured image classifier This implements one of result networks from Large-scale evolution of image classifiers by Esteban Real, et. al. Req
 54 Nov 25, 2022
54 Nov 25, 2022
Official implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT This repository is the official implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. ArXiv If
 168 Dec 29, 2022
168 Dec 29, 2022

Django helper application to easily and non-destructively crop arbitrarily large images in admin and frontend.
django-image-cropping django-image-cropping is an app for cropping uploaded images via Django's admin backend using Jcrop. Screenshot: django-image-cr
 546 Jan 3, 2023
546 Jan 3, 2023

This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking".
SCT This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking" The spatial-channel Transformer (SCT) enhan
27 Nov 23, 2022
IndoBERTweet is the first large-scale pretrained model for Indonesian Twitter. Published at EMNLP 2021 (main conference)
IndoBERTweet 🐦 🇮🇩 1. Paper Fajri Koto, Jey Han Lau, and Timothy Baldwin. IndoBERTweet: A Pretrained Language Model for Indonesian Twitter with Effe
 40 Nov 30, 2022
40 Nov 30, 2022

Phy-Q: A Benchmark for Physical Reasoning
Phy-Q: A Benchmark for Physical Reasoning Cheng Xue*, Vimukthini Pinto*, Chathura Gamage* Ekaterina Nikonova, Peng Zhang, Jochen Renz School of Comput
 29 Dec 19, 2022
29 Dec 19, 2022

Dynamic Multi-scale Filters for Semantic Segmentation (DMNet ICCV'2019)
Dynamic Multi-scale Filters for Semantic Segmentation (DMNet ICCV'2019) Introduction Official implementation of Dynamic Multi-scale Filters for Semant
 23 Oct 21, 2022
23 Oct 21, 2022

My published benchmark for a Kaggle Simulations Competition
Lux AI Working Title Bot Please refer to the Kaggle notebook for the comment section. The comment section contains my explanation on my code structure
 29 Aug 22, 2022
29 Aug 22, 2022
code for Multi-scale Matching Networks for Semantic Correspondence, ICCV
MMNet This repo is the official implementation of ICCV 2021 paper "Multi-scale Matching Networks for Semantic Correspondence.". Pre-requisite conda cr
 25 Dec 12, 2022
25 Dec 12, 2022

A PyTorch implementation of "ANEMONE: Graph Anomaly Detection with Multi-Scale Contrastive Learning", CIKM-21
ANEMONE A PyTorch implementation of "ANEMONE: Graph Anomaly Detection with Multi-Scale Contrastive Learning", CIKM-21 Dependencies python==3.6.1 dgl==
 30 Dec 14, 2022
30 Dec 14, 2022
UniLM AI - Large-scale Self-supervised Pre-training across Tasks, Languages, and Modalities
Pre-trained (foundation) models across tasks (understanding, generation and translation), languages (100+ languages), and modalities (language, image, audio, vision + language, audio + language, etc.)
 7.6k Jan 1, 2023
7.6k Jan 1, 2023
Galileo library for large scale graph training by JD
近年来,图计算在搜索、推荐和风控等场景中获得显著的效果,但也面临超大规模异构图训练,与现有的深度学习框架Tensorflow和PyTorch结合等难题。 Galileo(伽利略)是一个图深度学习框架,具备超大规模、易使用、易扩展、高性能、双后端等优点,旨在解决超大规模图算法在工业级场景的落地难题,提
 128 Nov 29, 2022
128 Nov 29, 2022
Sail is a free CLI tool to deploy, manage and scale WordPress applications in the DigitalOcean cloud.
Deploy WordPress to DigitalOcean with Sail Sail is a free CLI tool to deploy, manage and scale WordPress applications in the DigitalOcean cloud. Conte
 159 Dec 12, 2022
159 Dec 12, 2022
Model Quantization Benchmark
MQBench Update V0.0.2 Fix academic prepare setting. More deployable prepare process. Fix setup.py. Fix deploy on SNPE. Fix convert_deploy bug. Add Qua
 500 Jan 6, 2023
500 Jan 6, 2023

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

Dataset and Code for ICCV 2021 paper "Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme"
Dataset and Code for RealVSR Real-world Video Super-resolution: A Benchmark Dataset and A Decomposition based Learning Scheme Xi Yang, Wangmeng Xiang,
 91 Nov 22, 2022
91 Nov 22, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022

A novel benchmark dataset for Monocular Layout prediction
AutoLay AutoLay: Benchmarking Monocular Layout Estimation Kaustubh Mani, N. Sai Shankar, J. Krishna Murthy, and K. Madhava Krishna Abstract In this pa
 39 Apr 26, 2022
39 Apr 26, 2022
This software's intent is to automate all activities related to manage Axie Infinity Scholars. It is specially aimed to mangers with large scholar roasters.
Axie Scholars Utilities This software's intent is to automate all activities related to manage Scholars. It is specially aimed to mangers with large s
 153 Nov 16, 2022
153 Nov 16, 2022
CPU benchmark by calculating Pi, powered by Python3
cpu-benchmark Info: CPU benchmark by calculating Pi, powered by Python 3. Algorithm The program calculates pi with an accuracy of 10,000 decimal place
 20 Jan 3, 2023
20 Jan 3, 2023

Ongoing research training transformer language models at scale, including: BERT & GPT-2
Megatron (1 and 2) is a large, powerful transformer developed by the Applied Deep Learning Research team at NVIDIA.
 3.5k Dec 30, 2022
3.5k Dec 30, 2022
The CLRS Algorithmic Reasoning Benchmark
Learning representations of algorithms is an emerging area of machine learning, seeking to bridge concepts from neural networks with classical algorithms.
 251 Jan 5, 2023
251 Jan 5, 2023
TextDescriptives - A Python library for calculating a large variety of statistics from text
A Python library for calculating a large variety of statistics from text(s) using spaCy v.3 pipeline components and extensions. TextDescriptives can be used to calculate several descriptive statistics, readability metrics, and metrics related to dependency distance.
 150 Dec 30, 2022
150 Dec 30, 2022
CARLA: A Python Library to Benchmark Algorithmic Recourse and Counterfactual Explanation Algorithms
CARLA - Counterfactual And Recourse Library CARLA is a python library to benchmark counterfactual explanation and recourse models. It comes out-of-the
 200 Dec 28, 2022
200 Dec 28, 2022
Code used to generate the results appearing in "Train longer, generalize better: closing the generalization gap in large batch training of neural networks"
Train longer, generalize better - Big batch training This is a code repository used to generate the results appearing in "Train longer, generalize bet
 145 Sep 16, 2022
145 Sep 16, 2022
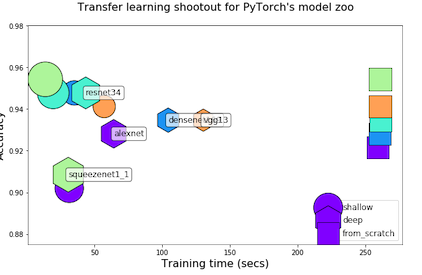
Transfer Learning Shootout for PyTorch's model zoo (torchvision)
pytorch-retraining Transfer Learning shootout for PyTorch's model zoo (torchvision). Load any pretrained model with custom final layer (num_classes) f
 169 Jun 29, 2022
169 Jun 29, 2022
WRENCH: Weak supeRvision bENCHmark
🔧 What is it? Wrench is a benchmark platform containing diverse weak supervision tasks. It also provides a common and easy framework for development
 176 Dec 28, 2022
176 Dec 28, 2022
![[Preprint]](https://github.com/VITA-Group/Deep_GCN_Benchmarking/raw/main/figs/combo.png)
[Preprint] "Bag of Tricks for Training Deeper Graph Neural Networks A Comprehensive Benchmark Study" by Tianlong Chen*, Kaixiong Zhou*, Keyu Duan, Wenqing Zheng, Peihao Wang, Xia Hu, Zhangyang Wang
Bag of Tricks for Training Deeper Graph Neural Networks: A Comprehensive Benchmark Study Codes for [Preprint] Bag of Tricks for Training Deeper Graph
 101 Dec 29, 2022
101 Dec 29, 2022
Pip-package for trajectory benchmarking from "Be your own Benchmark: No-Reference Trajectory Metric on Registered Point Clouds", ECMR'21
Map Metrics for Trajectory Quality Map metrics toolkit provides a set of metrics to quantitatively evaluate trajectory quality via estimating consiste
 31 Oct 28, 2022
31 Oct 28, 2022

A PyTorch implementation of "Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning", IJCAI-21
MERIT A PyTorch implementation of our IJCAI-21 paper Multi-Scale Contrastive Siamese Networks for Self-Supervised Graph Representation Learning. Depen
32 Jan 2, 2023
Evaluation suite for large-scale language models.
This repo contains code for running the evaluations and reproducing the results from the Jurassic-1 Technical Paper (see blog post), with current support for running the tasks through both the AI21 Studio API and OpenAI's GPT3 API.
 71 Dec 17, 2022
71 Dec 17, 2022

Compute descriptors for 3D point cloud registration using a multi scale sparse voxel architecture
MS-SVConv : 3D Point Cloud Registration with Multi-Scale Architecture and Self-supervised Fine-tuning Compute features for 3D point cloud registration
 42 Jul 25, 2022
42 Jul 25, 2022
A pytorch implementation of the CVPR2021 paper "VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild"
VSPW: A Large-scale Dataset for Video Scene Parsing in the Wild A pytorch implementation of the CVPR2021 paper "VSPW: A Large-scale Dataset for Video
 45 Nov 29, 2022
45 Nov 29, 2022
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data
Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data arXiv This is the code base for weakly supervised NER. We provide a
 92 Jan 4, 2023
92 Jan 4, 2023
Ongoing research training transformer language models at scale, including: BERT & GPT-2
What is this fork of Megatron-LM and Megatron-DeepSpeed This is a detached fork of https://github.com/microsoft/Megatron-DeepSpeed, which in itself is
 316 Jan 3, 2023
316 Jan 3, 2023

HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021)
Code for HDR Video Reconstruction HDR Video Reconstruction: A Coarse-to-fine Network and A Real-world Benchmark Dataset (ICCV 2021) Guanying Chen, Cha
 64 Nov 19, 2022
64 Nov 19, 2022
Large scale embeddings on a single machine.
Marius Marius is a system under active development for training embeddings for large-scale graphs on a single machine. Training on large scale graphs
 107 Jan 3, 2023
107 Jan 3, 2023

FedScale: Benchmarking Model and System Performance of Federated Learning
FedScale: Benchmarking Model and System Performance of Federated Learning (Paper) This repository contains scripts and instructions of building FedSca
 268 Jan 1, 2023
268 Jan 1, 2023

ALFRED - A Benchmark for Interpreting Grounded Instructions for Everyday Tasks
ALFRED A Benchmark for Interpreting Grounded Instructions for Everyday Tasks Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han,
 204 Dec 15, 2022
204 Dec 15, 2022
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark
MQBench: Towards Reproducible and Deployable Model Quantization Benchmark We propose a benchmark to evaluate different quantization algorithms on vari
494 Dec 29, 2022
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Disfl-QA is a targeted dataset for contextual disfluencies in an information seeking setting, namely question answering over Wikipedia passages. Disfl-QA builds upon the SQuAD-v2 (Rajpurkar et al., 2018) dataset, where each question in the dev set is annotated to add a contextual disfluency using the paragraph as a source of distractors.
52 Jun 21, 2022
The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question IntentionClassification Benchmark for Text-to-SQL"
TriageSQL The dataset and source code for our paper: "Did You Ask a Good Question? A Cross-Domain Question Intention Classification Benchmark for Text
 22 Nov 9, 2022
22 Nov 9, 2022

Benchmark for evaluating open-ended generation
OpenMEVA Contributed by Jian Guan, Zhexin Zhang. Thank Jiaxin Wen for DeBugging. OpenMEVA is a benchmark for evaluating open-ended story generation me
 25 Nov 15, 2022
25 Nov 15, 2022
ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge (ManiSkill Challenge), a large-scale learning-from-demonstrations benchmark for object manipulation.
ManiSkill-Learn ManiSkill-Learn is a framework for training agents on SAPIEN Open-Source Manipulation Skill Challenge, a large-scale learning-from-dem
 48 Dec 30, 2022
48 Dec 30, 2022
Run Effective Large Batch Contrastive Learning on Limited Memory GPU
Gradient Cache Gradient Cache is a simple technique for unlimitedly scaling contrastive learning batch far beyond GPU memory constraint. This means tr
 198 Dec 29, 2022
198 Dec 29, 2022
KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark.
KLUE Baseline Korean(한국어) KLUE-baseline contains the baseline code for the Korean Language Understanding Evaluation (KLUE) benchmark. See our paper fo
 74 Dec 13, 2022
74 Dec 13, 2022

The code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention.
CrossFormer This repository is the code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention. Introduction Existin
 238 Jan 6, 2023
238 Jan 6, 2023

A central task in drug discovery is searching, screening, and organizing large chemical databases
A central task in drug discovery is searching, screening, and organizing large chemical databases. Here, we implement clustering on molecular similarity. We support multiple methods to provide a interactive exploration of chemical space.
124 Jan 7, 2023

A PyTorch Implementation of Single Shot Scale-invariant Face Detector.
S³FD: Single Shot Scale-invariant Face Detector A PyTorch Implementation of Single Shot Scale-invariant Face Detector. Eval python wider_eval_pytorch.
 235 Jan 7, 2023
235 Jan 7, 2023

SAPIEN Manipulation Skill Benchmark
ManiSkill Benchmark SAPIEN Manipulation Skill Benchmark (abbreviated as ManiSkill, pronounced as "Many Skill") is a large-scale learning-from-demonstr
107 Jan 8, 2023

Official Implementation of LARGE: Latent-Based Regression through GAN Semantics
LARGE: Latent-Based Regression through GAN Semantics [Project Website] [Google Colab] [Paper] LARGE: Latent-Based Regression through GAN Semantics Yot
 83 Dec 6, 2022
83 Dec 6, 2022
Few-shot NLP benchmark for unified, rigorous eval
FLEX FLEX is a benchmark and framework for unified, rigorous few-shot NLP evaluation. FLEX enables: First-class NLP support Support for meta-training
 85 Dec 3, 2022
85 Dec 3, 2022
![[IJCAI-2021] A benchmark of data-free knowledge distillation from paper](https://github.com/zju-vipa/DataFree/raw/main/assets/cmi.png)
[IJCAI-2021] A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation"
DataFree A benchmark of data-free knowledge distillation from paper "Contrastive Model Inversion for Data-Free Knowledge Distillation" Authors: Gongfa
 47 Jan 9, 2023
47 Jan 9, 2023

An implementation of "MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing" (ICML 2019).
MixHop and N-GCN ⠀ A PyTorch implementation of "MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing" (ICML 2019)
 393 Dec 13, 2022
393 Dec 13, 2022
A Python library to utilize AWS API Gateway's large IP pool as a proxy to generate pseudo-infinite IPs for web scraping and brute forcing.
A Python library to utilize AWS API Gateway's large IP pool as a proxy to generate pseudo-infinite IPs for web scraping and brute forcing.
 929 Jan 1, 2023
929 Jan 1, 2023

FactSeg: Foreground Activation Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery (TGRS)
FactSeg: Foreground Activation Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery by Ailong Ma, Junjue Wang*, Yanfei Zhon
 43 Jan 5, 2023
43 Jan 5, 2023

A PyTorch implementation of "Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks" (KDD 2019).
ClusterGCN ⠀⠀ A PyTorch implementation of "Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Networks" (KDD 2019). A
697 Dec 27, 2022
code and data for paper "GIANT: Scalable Creation of a Web-scale Ontology"
GIANT Code and data for paper "GIANT: Scalable Creation of a Web-scale Ontology" https://arxiv.org/pdf/2004.02118.pdf Please cite our paper if this pr
 39 Dec 29, 2022
39 Dec 29, 2022

The Power of Scale for Parameter-Efficient Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning Implementation of soft embeddings from https://arxiv.org/abs/2104.08691v1 using Pytorch and H
 208 Dec 30, 2022
208 Dec 30, 2022

Official repository for the paper, MidiBERT-Piano: Large-scale Pre-training for Symbolic Music Understanding.
MidiBERT-Piano Authors: Yi-Hui (Sophia) Chou, I-Chun (Bronwin) Chen Introduction This is the official repository for the paper, MidiBERT-Piano: Large-
 137 Dec 15, 2022
137 Dec 15, 2022
An open-access benchmark and toolbox for electricity price forecasting
epftoolbox The epftoolbox is the first open-access library for driving research in electricity price forecasting. Its main goal is to make available a
 97 Dec 5, 2022
97 Dec 5, 2022
MVP Benchmark for Multi-View Partial Point Cloud Completion and Registration
MVP Benchmark: Multi-View Partial Point Clouds for Completion and Registration [NEWS] 2021-07-12 [NEW 🎉 ] The submission on Codalab starts! 2021-07-1
 93 Dec 21, 2022
93 Dec 21, 2022

A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
A Large-Scale Dataset for Spinal Vertebrae Segmentation in Computed Tomography
 75 Dec 26, 2022
75 Dec 26, 2022

An algorithm that handles large-scale aerial photo co-registration, based on SURF, RANSAC and PyTorch autograd.
An algorithm that handles large-scale aerial photo co-registration, based on SURF, RANSAC and PyTorch autograd.
 41 Oct 29, 2022
41 Oct 29, 2022
Large dataset storage format for Pytorch
H5Record Large dataset ( 100G, = 1T) storage format for Pytorch (wip) Support python 3 pip install h5record Why? Writing large dataset is still a
 43 Oct 22, 2022
43 Oct 22, 2022
Generic Event Boundary Detection: A Benchmark for Event Segmentation
Generic Event Boundary Detection: A Benchmark for Event Segmentation We release our data annotation & baseline codes for detecting generic event bound
 47 Nov 22, 2022
47 Nov 22, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
 190 Jan 3, 2023
190 Jan 3, 2023

ACL'2021: Learning Dense Representations of Phrases at Scale
DensePhrases DensePhrases is an extractive phrase search tool based on your natural language inputs. From 5 million Wikipedia articles, it can search
 540 Dec 30, 2022
540 Dec 30, 2022

A large dataset of 100k Google Satellite and matching Map images, resembling pix2pix's Google Maps dataset.
Larger Google Sat2Map dataset This dataset extends the aerial ⟷ Maps dataset used in pix2pix (Isola et al., CVPR17). The provide script download_sat2m
 34 Dec 28, 2022
34 Dec 28, 2022
This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages" published in Findings of the Association for Computational Linguistics: ACL 2021.
XL-Sum This repository contains the code, data, and models of the paper titled "XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Lang
189 Jan 2, 2023

Square Root Bundle Adjustment for Large-Scale Reconstruction
RootBA: Square Root Bundle Adjustment Project Page | Paper | Poster | Video | Code Table of Contents Citation Dependencies Installing dependencies on
 205 Dec 20, 2022
205 Dec 20, 2022

Official Implement of CVPR 2021 paper “Cross-Modal Collaborative Representation Learning and a Large-Scale RGBT Benchmark for Crowd Counting”
RGBT Crowd Counting Lingbo Liu, Jiaqi Chen, Hefeng Wu, Guanbin Li, Chenglong Li, Liang Lin. "Cross-Modal Collaborative Representation Learning and a L
 37 Dec 8, 2022
37 Dec 8, 2022
Code to train models from "Paraphrastic Representations at Scale".
Paraphrastic Representations at Scale Code to train models from "Paraphrastic Representations at Scale". The code is written in Python 3.7 and require
 71 Dec 19, 2022
71 Dec 19, 2022
Compositional and Parameter-Efficient Representations for Large Knowledge Graphs
NodePiece - Compositional and Parameter-Efficient Representations for Large Knowledge Graphs NodePiece is a "tokenizer" for reducing entity vocabulary
 107 Jan 4, 2023
107 Jan 4, 2023

Code for the CVPR2021 paper "Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition"
Patch-NetVLAD: Multi-Scale Fusion of Locally-Global Descriptors for Place Recognition This repository contains code for the CVPR2021 paper "Patch-NetV
 368 Jan 6, 2023
368 Jan 6, 2023

This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard evaluation metric to measure the accuracy and robustness of 3D face reconstruction methods from a single image under variations in viewing angle, lighting, and common occlusions.
NoW Evaluation This is the official repository for evaluation on the NoW Benchmark Dataset. The goal of the NoW benchmark is to introduce a standard e
 71 Dec 30, 2022
71 Dec 30, 2022

Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020)
GraspNet Baseline Baseline model for "GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping" (CVPR 2020). [paper] [dataset] [API] [do
 209 Dec 29, 2022
209 Dec 29, 2022

SCALE: Modeling Clothed Humans with a Surface Codec of Articulated Local Elements (CVPR 2021)
SCALE: Modeling Clothed Humans with a Surface Codec of Articulated Local Elements (CVPR 2021) This repository contains the official PyTorch implementa
 133 Jan 5, 2023
133 Jan 5, 2023

Human POSEitioning System (HPS): 3D Human Pose Estimation and Self-localization in Large Scenes from Body-Mounted Sensors, CVPR 2021
Human POSEitioning System (HPS): 3D Human Pose Estimation and Self-localization in Large Scenes from Body-Mounted Sensors Human POSEitioning System (H
 66 Dec 21, 2022
66 Dec 21, 2022
Secure Distributed Training at Scale
Secure Distributed Training at Scale This repository contains the implementation of experiments from the paper "Secure Distributed Training at Scale"
 9 Jul 11, 2022
9 Jul 11, 2022
DistML is a Ray extension library to support large-scale distributed ML training on heterogeneous multi-node multi-GPU clusters
DistML is a Ray extension library to support large-scale distributed ML training on heterogeneous multi-node multi-GPU clusters
 27 Aug 19, 2022
27 Aug 19, 2022

A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation models. It contains 17 different amateur subjects performing 30 sports-related actions each, for a total of 510 action clips.
 25 Jun 20, 2021
25 Jun 20, 2021
A large-scale video dataset for the training and evaluation of 3D human pose estimation models
ASPset-510 ASPset-510 (Australian Sports Pose Dataset) is a large-scale video dataset for the training and evaluation of 3D human pose estimation mode
36 Oct 30, 2022

NAS Benchmark in "Prioritized Architecture Sampling with Monto-Carlo Tree Search", CVPR2021
NAS-Bench-Macro This repository includes the benchmark and code for NAS-Bench-Macro in paper "Prioritized Architecture Sampling with Monto-Carlo Tree
 35 Jan 3, 2023
35 Jan 3, 2023

Code for "LoRA: Low-Rank Adaptation of Large Language Models"
LoRA: Low-Rank Adaptation of Large Language Models This repo contains the implementation of LoRA in GPT-2 and steps to replicate the results in our re
394 Jan 8, 2023

A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/casual, active/passive, and many more. Created by Prithiviraj Damodaran. Open to pull requests and other forms of collaboration.
Styleformer A Neural Language Style Transfer framework to transfer natural language text smoothly between fine-grained language styles like formal/cas
 431 Dec 19, 2022
431 Dec 19, 2022

modelvshuman is a Python library to benchmark the gap between human and machine vision
modelvshuman is a Python library to benchmark the gap between human and machine vision. Using this library, both PyTorch and TensorFlow models can be evaluated on 17 out-of-distribution datasets with high-quality human comparison data.
 244 Jan 3, 2023
244 Jan 3, 2023
EPSANet:An Efficient Pyramid Split Attention Block on Convolutional Neural Network
EPSANet:An Efficient Pyramid Split Attention Block on Convolutional Neural Network This repo contains the official Pytorch implementaion code and conf
 175 Jan 7, 2023
175 Jan 7, 2023
中文医疗信息处理基准CBLUE: A Chinese Biomedical LanguageUnderstanding Evaluation Benchmark
English | 中文说明 CBLUE AI (Artificial Intelligence) is playing an indispensabe role in the biomedical field, helping improve medical technology. For fur
 452 Dec 30, 2022
452 Dec 30, 2022

Intruder detection systems are common place now, and readily available in industry, but how do they work? They must detect people and large animals, but not generate false alarms in the presence of small animals, changes in lighting, environmental motion such as trees, or melting snow. To work correctly, the system must learn the background, in order to differentiate foreground objects.
Intruder-Detection Intruder detection systems are common place now, and readily available in industry, but how do they work? They must detect people a
 4 Jul 18, 2021
4 Jul 18, 2021

DeepLM: Large-scale Nonlinear Least Squares on Deep Learning Frameworks using Stochastic Domain Decomposition (CVPR 2021)
DeepLM DeepLM: Large-scale Nonlinear Least Squares on Deep Learning Frameworks using Stochastic Domain Decomposition (CVPR 2021) Run Please install th
 130 Dec 2, 2022
130 Dec 2, 2022

3D AffordanceNet is a 3D point cloud benchmark consisting of 23k shapes from 23 semantic object categories, annotated with 56k affordance annotations and covering 18 visual affordance categories.
3D AffordanceNet This repository is the official experiment implementation of 3D AffordanceNet benchmark. 3D AffordanceNet is a 3D point cloud benchma
 49 Dec 1, 2022
49 Dec 1, 2022

An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicity.
Fast Face Classification (F²C) This is the code of our paper An Efficient Training Approach for Very Large Scale Face Recognition or F²C for simplicit
 33 Jun 27, 2021
33 Jun 27, 2021

Implementation of CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
CrossViT : Cross-Attention Multi-Scale Vision Transformer for Image Classification This is an unofficial PyTorch implementation of CrossViT: Cross-Att
 103 Nov 25, 2022
103 Nov 25, 2022
City-Scale Multi-Camera Vehicle Tracking Guided by Crossroad Zones Code
City-Scale Multi-Camera Vehicle Tracking Guided by Crossroad Zones Requirements Python 3.8 or later with all requirements.txt dependencies installed,
 88 Dec 12, 2022
88 Dec 12, 2022

Multi-Scale Aligned Distillation for Low-Resolution Detection (CVPR2021)
MSAD Multi-Scale Aligned Distillation for Low-Resolution Detection Lu Qi*, Jason Kuen*, Jiuxiang Gu, Zhe Lin, Yi Wang, Yukang Chen, Yanwei Li, Jiaya J
 115 Dec 23, 2022
115 Dec 23, 2022