97 Repositories
Python legal-documents Libraries
A community-supported supercharged version of paperless: scan, index and archive all your physical documents
Paperless-ngx Paperless-ngx is a document management system that transforms your physical documents into a searchable online archive so you can keep,
 5.2k Jan 4, 2023
5.2k Jan 4, 2023

Plugin to manage site, circuit and device diagrams and documents in Netbox
Netbox Documents Plugin A plugin designed to faciliate the storage of site, circuit and device specific documents within NetBox Note: Netbox v3.2+ is
 38 Dec 24, 2022
38 Dec 24, 2022
Text classification is one of the popular tasks in NLP that allows a program to classify free-text documents based on pre-defined classes.
Deep-Learning-for-Text-Document-Classification Text classification is one of the popular tasks in NLP that allows a program to classify free-text docu
 2 Mar 17, 2022
2 Mar 17, 2022
This repository is used to simplify the process of cloning the SSM documents across the AWS regions.
SSM Cloner Introduction This module is created in order to simplify the process of copying the SSM documents from one region to another regions. As an
 6 Jun 4, 2022
6 Jun 4, 2022
Code To Tune or Not To Tune? Zero-shot Models for Legal Case Entailment.
COLIEE 2021 - task 2: Legal Case Entailment This repository contains the code to reproduce NeuralMind's submissions to COLIEE 2021 presented in the pa
 13 Dec 16, 2022
13 Dec 16, 2022
BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key Information Extraction from Documents
BROS (BERT Relying On Spatiality) is a pre-trained language model focusing on text and layout for better key information extraction from documents. Given the OCR results of the document image, which are text and bounding box pairs, it can perform various key information extraction tasks, such as extracting an ordered item list from receipts
 94 Dec 30, 2022
94 Dec 30, 2022
Expert Finding in Legal Community Question Answering
Expert Finding in Legal Community Question Answering Arian Askari, Suzan Verberne, and Gabriella Pasi. Expert Finding in Legal Community Question Answ
 3 Oct 31, 2022
3 Oct 31, 2022
This repository contains the scripts for downloading and validating scripts for the documents
HC4: HLTCOE CLIR Common-Crawl Collection This repository contains the scripts for downloading and validating scripts for the documents. Document ids,
 6 Jun 7, 2022
6 Jun 7, 2022

This repository compare a selfie with images from identity documents and response if the selfie match.
aws-rekognition-facecompare This repository compare a selfie with images from identity documents and response if the selfie match. This code was made
 1 Jan 27, 2022
1 Jan 27, 2022
A simple document management REST based API for collaboratively interacting with documents
documan_api A simple document management REST based API for collaboratively interacting with documents.
 1 Jan 22, 2022
1 Jan 22, 2022
Pytorch Implementation of Value Retrieval with Arbitrary Queries for Form-like Documents.
Value Retrieval with Arbitrary Queries for Form-like Documents Introduction Pytorch Implementation of Value Retrieval with Arbitrary Queries for Form-
 13 Sep 15, 2022
13 Sep 15, 2022
Blackstone is a spaCy model and library for processing long-form, unstructured legal text
Blackstone Blackstone is a spaCy model and library for processing long-form, unstructured legal text. Blackstone is an experimental research project f
 579 Jan 8, 2023
579 Jan 8, 2023
Auto-researching tool generating word documents.
About ResearchTE automates researching by generating document with answers to given questions. Supports getting results from: Google DuckDuckGo (with
 1 Feb 14, 2022
1 Feb 14, 2022
FileGenerator - File Generator for sites that accepts documents
File Generator for sites that accepts documents This code generates files as per
 2 Mar 19, 2022
2 Mar 19, 2022

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
Toolchain for project structure and documents optimisation
ritocco Toolchain for project structure and documents optimisation
 1 Jan 12, 2022
1 Jan 12, 2022

Shelf DB is a tiny document database for Python to stores documents or JSON-like data
Shelf DB Introduction Shelf DB is a tiny document database for Python to stores documents or JSON-like data. Get it $ pip install shelfdb shelfquery S
 35 Nov 3, 2022
35 Nov 3, 2022
This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents".
Introduction This code is the implementation of the paper "Coherence-Based Distributed Document Representation Learning for Scientific Documents". If
 0 Jan 11, 2022
0 Jan 11, 2022
An executor that wraps 3D mesh models and encodes 3D content documents to d-dimension vector.
3D Mesh Encoder An Executor that receives Documents containing point sets data in its blob attribute, with shape (N, 3) and encodes it to embeddings o
 11 Dec 14, 2022
11 Dec 14, 2022
Import Python modules from dicts and JSON formatted documents.
Paker Paker is module for importing Python packages/modules from dictionaries and JSON formatted documents. It was inspired by httpimporter. Important
 1 Sep 7, 2022
1 Sep 7, 2022
Python utility library for compositing PDF documents with reportlab.
pdfdoc-py Python utility library for compositing PDF documents with reportlab. Installation The pdfdoc-py package can be installed directly from the s
 1 Jan 6, 2022
1 Jan 6, 2022
Quantifiers and Negations in RE Documents
Quantifiers-and-Negations-in-RE-Documents This project was part of my work for a
 1 Feb 1, 2022
1 Feb 1, 2022

A supercharged version of paperless: scan, index and archive all your physical documents
Paperless-ng Paperless (click me) is an application by Daniel Quinn and contributors that indexes your scanned documents and allows you to easily sear
 5.3k Jan 9, 2023
5.3k Jan 9, 2023
A refresher for PowerBI Desktop documents
PowerBI_Refresher-NPP Informació Per executar el programa s'ha de tenir instalat el python versio 3 o mes. Requeriments a requirements.txt. El fitxer
 1 May 2, 2022
1 May 2, 2022
An executor that loads ONNX models and embeds documents using the ONNX runtime.
ONNXEncoder An executor that loads ONNX models and embeds documents using the ONNX runtime. Usage via Docker image (recommended) from jina import Flow
2 Mar 15, 2022

Legal text retrieval for python
legal-text-retrieval Overview This system contains 2 steps: generate training data containing negative sample found by mixture score of cosine(tfidf)
 22 Dec 6, 2022
22 Dec 6, 2022
Telegram Bot to store Posts and Documents and it can Access by Special Links.
Telegram Bot to store Posts and Documents and it can Access by Special Links. I Guess This Will Be Usefull For Many People..... 😇 . Features Fully cu
 1 Dec 23, 2021
1 Dec 23, 2021
minipdf is a package for creating simple, single-page PDF documents.
minipdf minipdf is a package for creating simple, single-page PDF documents. Installation You can install the development version from GitHub with: #
 41 Dec 19, 2022
41 Dec 19, 2022

LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021
LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021 We propose a cross encoder model (LTR_CrossEncoder) for information retrieval, re-retrie
 7 Jan 12, 2022
7 Jan 12, 2022
Program to extract signatures from documents.
Extracting Signatures from Bank Checks Introduction Ahmed et al. [1] suggest a connected components-based method for segmenting signatures in document
 9 Jan 26, 2022
9 Jan 26, 2022
Lex Rosetta: Transfer of Predictive Models Across Languages, Jurisdictions, and Legal Domains
Lex Rosetta: Transfer of Predictive Models Across Languages, Jurisdictions, and Legal Domains This is an accompanying repository to the ICAIL 2021 pap
 4 Dec 16, 2021
4 Dec 16, 2021

LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021
LTR_CrossEncoder: Legal Text Retrieval Zalo AI Challenge 2021 We propose a cross encoder model (LTR_CrossEncoder) for information retrieval, re-retrie
7 Jan 12, 2022

Automate the case review on legal case documents and find the most critical cases using network analysis
Automation on Legal Court Cases Review This project is to automate the case review on legal case documents and find the most critical cases using netw
 7 Dec 28, 2022
7 Dec 28, 2022
Discovering Explanatory Sentences in Legal Case Decisions Using Pre-trained Language Models.
Statutory Interpretation Data Set This repository contains the data set created for the following research papers: Savelka, Jaromir, and Kevin D. Ashl
 17 Dec 23, 2022
17 Dec 23, 2022
The code of "Dependency Learning for Legal Judgment Prediction with a Unified Text-to-Text Transformer".
Code data_preprocess.py: preprocess data for Dependent-T5. parameters.py: define parameters of Dependent-T5. train_tools.py: traning and evaluation co
 1 Apr 21, 2022
1 Apr 21, 2022
A Python tool that parses JSON documents using JsonPath
A Python tool that parses JSON documents using JsonPath
 8 Dec 18, 2022
8 Dec 18, 2022
Jupyter Notebooks as Markdown Documents, Julia, Python or R scripts
Have you always wished Jupyter notebooks were plain text documents? Wished you could edit them in your favorite IDE? And get clear and meaningful diff
 5.7k Jan 4, 2023
5.7k Jan 4, 2023
This tool crawls a list of websites and download all PDF and office documents
This tool crawls a list of websites and download all PDF and office documents. Then it analyses the PDF documents and tries to detect accessibility issues.
 7 Sep 30, 2022
7 Sep 30, 2022
Library - Recent and favorite documents
Thingy Thingy is used to quickly access recent and favorite documents. It's an XApp so it can work in any distribution and many desktop environments (
 23 Sep 11, 2022
23 Sep 11, 2022
A deep learning based semantic search platform that computes similarity scores between provided query and documents
semanticsearch This is a deep learning based semantic search platform that computes similarity scores between provided query and documents. Documents
 1 Nov 30, 2021
1 Nov 30, 2021
Dominate is a Python library for creating and manipulating HTML documents using an elegant DOM API
Dominate Dominate is a Python library for creating and manipulating HTML documents using an elegant DOM API. It allows you to write HTML pages in pure
 1.5k Jan 9, 2023
1.5k Jan 9, 2023
File-sharing-Bot: Telegram Bot to store Posts and Documents and it can Access by Special Links.
File-sharing-Bot Telegram Bot to store Posts and Documents and it can Access by Special Links. I Guess This Will Be Usefull For Many People..... 😇 .
 1 Dec 17, 2021
1 Dec 17, 2021
A naive Bayes model for cancer classification using a set of documents
Naivebayes text classifcation model for cancer and noncancer documents Author: Alex King Purpose Requirements/files included How to use 1. Purpose The
 1 Nov 24, 2021
1 Nov 24, 2021

Apply different text recognition services to images of handwritten documents.
Handprint The Handwritten Page Recognition Test is a command-line program that invokes HTR (handwritten text recognition) services on images of docume
 117 Jan 2, 2023
117 Jan 2, 2023
Python Tool to Easily Generate Multiple Documents
Python Tool to Easily Generate Multiple Documents Running the script doesn't require internet Max Generation is set to 10k to avoid lagging/crashing R
 2 Apr 27, 2022
2 Apr 27, 2022
Code for DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents
DeepXML Code for DeepXML: A Deep Extreme Multi-Label Learning Framework Applied to Short Text Documents Architectures and algorithms DeepXML supports
 49 Nov 6, 2022
49 Nov 6, 2022

Converts a grading Excel sheet into Markdown documents.
GradeDocs Turns Excel worksheets into grade/score documents. Example Given such an Excel Worksheet (see examples/example.xlsx): The following commands
 1 Dec 19, 2021
1 Dec 19, 2021
An Indexer that works out-of-the-box when you have less than 100K stored Documents
U100KIndexer An Indexer that works out-of-the-box when you have less than 100K stored Documents. U100K means under 100K. At 100K stored Documents with
7 Mar 15, 2022
CiteURL is an extensible tool that parses legal citations and makes links to websites where you can read the cited language for free.
CiteURL is an extensible tool that parses legal citations and makes links to websites where you can read the cited language for free. It can be used t
 15 Dec 27, 2022
15 Dec 27, 2022
JTEX is a command line tool (CLI) for rendering LaTeX documents from jinja-style templates.
JTEX JTEX is a command line tool (CLI) for rendering LaTeX documents from jinja-style templates. This package uses Jinja2 as the template engine with
 15 Dec 21, 2022
15 Dec 21, 2022

Document blur detection based on Laplacian operator and text detection.
Document Blur Detection For general blurred image, using the variance of Laplacian operator is a good solution. But as for the blur detection of docum
 5 Oct 20, 2022
5 Oct 20, 2022

Small python-gtk application, which helps the user to merge or split pdf documents and rotate, crop and rearrange their pages using an interactive and intuitive graphical interface
Small python-gtk application, which helps the user to merge or split pdf documents and rotate, crop and rearrange their pages using an interactive and intuitive graphical interface
 1.8k Dec 29, 2022
1.8k Dec 29, 2022
LegalNLP - Natural Language Processing Methods for the Brazilian Legal Language
LegalNLP - Natural Language Processing Methods for the Brazilian Legal Language ⚖️ The library of Natural Language Processing for Brazilian legal lang
 125 Dec 20, 2022
125 Dec 20, 2022

DocumentPy is a Python application that runs in a command-line interface environment, made for creating HTML documents.
DocumentPy DocumentPy is a Python application that runs in a command-line interface environment, made for creating HTML documents. Usage DocumentPy, a
 0 Jul 15, 2021
0 Jul 15, 2021
Language Models for the legal domain in Spanish done @ BSC-TEMU within the "Plan de las Tecnologías del Lenguaje" (Plan-TL).
Spanish legal domain Language Model ⚖️ This repository contains the page for two main resources for the Spanish legal domain: A RoBERTa model: https:/
 12 Nov 14, 2022
12 Nov 14, 2022
Implementation of TF-IDF algorithm to find documents similarity with cosine similarity
NLP learning Trying to learn NLP to use in my projects! Table of Contents About The Project Built With Getting Started Requirements Run Usage License
 3 Aug 25, 2022
3 Aug 25, 2022
This is REST-API for Indonesian Text Summarization using Non-Negative Matrix Factorization for the algorithm to summarize documents and FastAPI for the framework.
Indonesian Text Summarization Using FastAPI This is REST-API for Indonesian Text Summarization using Non-Negative Matrix Factorization for the algorit
 2 Nov 3, 2022
2 Nov 3, 2022

PICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks
Code for the paper "PICK: Processing Key Information Extraction from Documents using Improved Graph Learning-Convolutional Networks" (ICPR 2020)
 498 Dec 24, 2022
498 Dec 24, 2022
A Telegram bot to all media and documents files to web link .
FileStreamBot A Telegram bot to all media and documents files to web link . Report a Bug | Request Feature 🍁 About This Bot : This bot will give you
 129 Jan 3, 2023
129 Jan 3, 2023
Docbarcodes extracts 1D and 2D barcodes from scanned PDF documents or images. It can be used to automate extraction and processing of all kind of documents.
Intro Barcodes are being used in many documents or forms to enable machine reading capabilities and reduce manual processing effort. Simple 1D barcode
 3 Jun 18, 2022
3 Jun 18, 2022
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English ⚖️ 🏆 🧑🎓 👩⚖️ Dataset Summary Inspired by the recent widespread use of th
 95 Dec 8, 2022
95 Dec 8, 2022

x-ray is a Python library for finding bad redactions in PDF documents.
A tool to detect whether a PDF has a bad redaction
 73 Dec 19, 2022
73 Dec 19, 2022

Download YOUR files, documents from vk.
vk-documents-downloader Кароч эта симпл херня качает все ВАШИ документы с вк. Или я еблан, но в гх и тмб гугле я подобного не нашел. py main.py Login:
 4 Jun 10, 2022
4 Jun 10, 2022
WeasyPrint is a smart solution helping web developers to create PDF documents.
WeasyPrint is a smart solution helping web developers to create PDF documents. It turns simple HTML pages into gorgeous statistical reports, invoices, tickets…
 5.4k Jan 8, 2023
5.4k Jan 8, 2023
Generate YARA rules for OOXML documents using ZIP local header metadata.
apooxml Generate YARA rules for OOXML documents using ZIP local header metadata. To learn more about this tool and the methodology behind it, check ou
 34 Jan 26, 2022
34 Jan 26, 2022
Command line program to download documents from web portals.
command line document download made easy Highlights list available documents in json format or download them filter documents using string matching re
 16 Dec 26, 2022
16 Dec 26, 2022
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
document organizer with tags and full-text-search, in a simple and clean sqlite3 schema
 152 Oct 29, 2022
152 Oct 29, 2022
Extracting Summary Knowledge Graphs from Long Documents
GraphSum This repo contains the data and code for the G2G model in the paper: Extracting Summary Knowledge Graphs from Long Documents. The other basel
 10 Oct 21, 2022
10 Oct 21, 2022

Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
Markup is an online annotation tool that can be used to transform unstructured documents into structured formats for NLP and ML tasks, such as named-entity recognition. Markup learns as you annotate in order to predict and suggest complex annotations. Markup also provides integrated access to existing and custom ontologies, enabling the prediction and suggestion of ontology mappings based on the text you're annotating.
 146 Dec 18, 2022
146 Dec 18, 2022

Implementation of legal QA system based on SentenceKoBART
LegalQA using SentenceKoBART Implementation of legal QA system based on SentenceKoBART How to train SentenceKoBART Based on Neural Search Engine Jina
 75 Dec 27, 2022
75 Dec 27, 2022

PyMuPDF is a Python binding with support for MuPDF
PyMuPDF is a Python binding with support for MuPDF (current version 1.18.*), a lightweight PDF, XPS, and E-book viewer, renderer, and toolkit, which is maintained and developed by Artifex Software, Inc.
 1.9k Jan 3, 2023
1.9k Jan 3, 2023

When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holdings
When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset of 53,000+ Legal Holdings This is the repository for t
 39 Jan 7, 2023
39 Jan 7, 2023
This is a script to forward forward large number of documents to another telegram channel.
ChannelForward 😇 This is a Script to Forward Large Number of Documents to Another Telegram Channel. If You Try to Forward Very Large Number of Files
 10 Jun 8, 2021
10 Jun 8, 2021
Telegram Bot to store Posts and Documents and it can Access by Special Links.
File-sharing-Bot Telegram Bot to store Posts and Documents and it can Access by Special Links. I Guess This Will Be Usefull For Many People..... 😇 .
 1.2k Jan 8, 2023
1.2k Jan 8, 2023
ScanTailor Advanced is the version that merges the features of the ScanTailor Featured and ScanTailor Enhanced versions, brings new ones and fixes.
ScanTailor Advanced The ScanTailor version that merges the features of the ScanTailor Featured and ScanTailor Enhanced versions, brings new ones and f
 952 Dec 31, 2022
952 Dec 31, 2022
A machine learning software for extracting information from scholarly documents
GROBID GROBID documentation Visit the GROBID documentation for more detailed information. Summary GROBID (or Grobid, but not GroBid nor GroBiD) means
 1.9k Jan 8, 2023
1.9k Jan 8, 2023
A tool for extracting text from scanned documents (via OCR), with user-defined post-processing.
The project is based on older versions of tesseract and other tools, and is now superseded by another project which allows for more granular control o
 32 Jul 24, 2022
32 Jul 24, 2022
Deskew is a command line tool for deskewing scanned text documents. It uses Hough transform to detect "text lines" in the image. As an output, you get an image rotated so that the lines are horizontal.
Deskew by Marek Mauder https://galfar.vevb.net/deskew https://github.com/galfar/deskew v1.30 2019-06-07 Overview Deskew is a command line tool for des
 127 Dec 3, 2022
127 Dec 3, 2022
An application of high resolution GANs to dewarp images of perturbed documents
Docuwarp This project is focused on dewarping document images through the usage of pix2pixHD, a GAN that is useful for general image to image translat
 97 Dec 25, 2022
97 Dec 25, 2022

CUAD
Contract Understanding Atticus Dataset This repository contains code for the Contract Understanding Atticus Dataset (CUAD), a dataset for legal contra
 273 Dec 17, 2022
273 Dec 17, 2022
Contract Understanding Atticus Dataset
Contract Understanding Atticus Dataset This repository contains code for the Contract Understanding Atticus Dataset (CUAD), a dataset for legal contra
273 Dec 17, 2022

Render reMarkable documents to PDF
rmrl: reMarkable Rendering Library rmrl is a Python library for rendering reMarkable documents to PDF files. It takes the original PDF document and th
 95 Dec 25, 2022
95 Dec 25, 2022
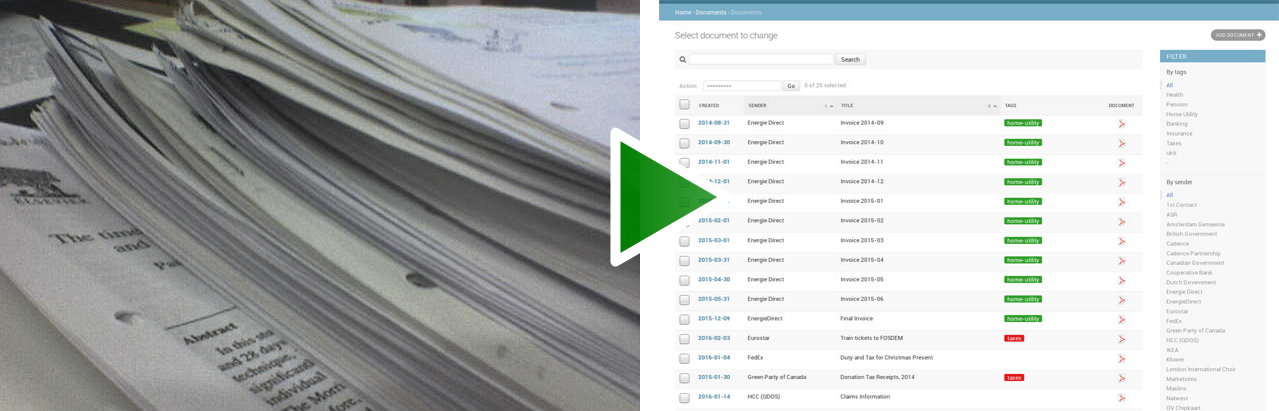
Scan, index, and archive all of your paper documents
[ en | de | el ] Important news about the future of this project It's been more than 5 years since I started this project on a whim as an effort to tr
 7.8k Jan 6, 2023
7.8k Jan 6, 2023
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
 831 Feb 17, 2021
831 Feb 17, 2021

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
 1.4k Feb 17, 2021
1.4k Feb 17, 2021
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
 2.5k Feb 17, 2021
2.5k Feb 17, 2021
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
1.3k Jan 3, 2023

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
1.9k Jan 6, 2023
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
3k Jan 8, 2023
Parsel lets you extract data from XML/HTML documents using XPath or CSS selectors
Parsel Parsel is a BSD-licensed Python library to extract and remove data from HTML and XML using XPath and CSS selectors, optionally combined with re
 859 Dec 29, 2022
859 Dec 29, 2022
Provides syntax for Python-Markdown which allows for the inclusion of the contents of other Markdown documents.
Markdown-Include This is an extension to Python-Markdown which provides an "include" function, similar to that found in LaTeX (and also the C pre-proc
 85 Dec 30, 2022
85 Dec 30, 2022
On Generating Extended Summaries of Long Documents
ExtendedSumm This repository contains the implementation details and datasets used in On Generating Extended Summaries of Long Documents paper at the
 76 Sep 5, 2022
76 Sep 5, 2022
texlive expressions for documents
tex2nix Generate Texlive environment containing all dependencies for your document rather than downloading gigabytes of texlive packages. Installation
 70 Dec 26, 2022
70 Dec 26, 2022
Search for documents in a domain through Google. The objective is to extract metadata
MetaFinder - Metadata search through Google _____ __ ___________ .__ .___ / \
 85 Dec 16, 2022
85 Dec 16, 2022
Module for automatic summarization of text documents and HTML pages.
Automatic text summarizer Simple library and command line utility for extracting summary from HTML pages or plain texts. The package also contains sim
3k Jan 3, 2023
Create Open XML PowerPoint documents in Python
python-pptx is a Python library for creating and updating PowerPoint (.pptx) files. A typical use would be generating a customized PowerPoint presenta
 1.7k Jan 5, 2023
1.7k Jan 5, 2023
Standards-compliant library for parsing and serializing HTML documents and fragments in Python
html5lib html5lib is a pure-python library for parsing HTML. It is designed to conform to the WHATWG HTML specification, as is implemented by all majo
 1k Dec 27, 2022
1k Dec 27, 2022