1073 Repositories
Python night-vision-camera Libraries

This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking".
SCT This is the official code for the paper "Tracker Meets Night: A Transformer Enhancer for UAV Tracking" The spatial-channel Transformer (SCT) enhan
 27 Nov 23, 2022
27 Nov 23, 2022
Certifiable Outlier-Robust Geometric Perception
Certifiable Outlier-Robust Geometric Perception About This repository holds the implementation for certifiably solving outlier-robust geometric percep
 83 Dec 31, 2022
83 Dec 31, 2022

Polyp-PVT: Polyp Segmentation with Pyramid Vision Transformers (arXiv2021)
Polyp-PVT by Bo Dong, Wenhai Wang, Deng-Ping Fan, Jinpeng Li, Huazhu Fu, & Ling Shao. This repo is the official implementation of "Polyp-PVT: Polyp Se
 102 Jan 5, 2023
102 Jan 5, 2023
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
ROSITA News & Updates (24/08/2021) Release the demo to perform fine-grained semantic alignments using the pretrained ROSITA model. (15/08/2021) Releas
 48 Dec 23, 2022
48 Dec 23, 2022
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless.
Roboflow makes managing, preprocessing, augmenting, and versioning datasets for computer vision seamless. This is the official Roboflow python package that interfaces with the Roboflow API.
 52 Dec 23, 2022
52 Dec 23, 2022
A Python 2.7/3.x module for Amcrest Cameras using the SDK HTTP API.
A Python 2.7/3.x module for Amcrest Cameras using the SDK HTTP API. Amcrest and Dahua devices share similar firmwares. Dahua Cameras and NVRs also work with this module.
 176 Dec 21, 2022
176 Dec 21, 2022

Code and data for "Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning" (EMNLP 2021).
GD-VCR Code for Broaden the Vision: Geo-Diverse Visual Commonsense Reasoning (EMNLP 2021). Research Questions and Aims: How well can a model perform o
 24 Oct 13, 2022
24 Oct 13, 2022
Earth Vision Foundation
EVer - A Library for Earth Vision Researcher EVer is a Pytorch-based Python library to simplify the training and inference of the deep learning model.
 34 Nov 26, 2022
34 Nov 26, 2022
![[Preprint] ConvMLP: Hierarchical Convolutional MLPs for Vision, 2021](https://github.com/SHI-Labs/Convolutional-MLPs/raw/master/images/comparison.png)
[Preprint] ConvMLP: Hierarchical Convolutional MLPs for Vision, 2021
Convolutional MLP ConvMLP: Hierarchical Convolutional MLPs for Vision Preprint link: ConvMLP: Hierarchical Convolutional MLPs for Vision By Jiachen Li
 143 Jan 3, 2023
143 Jan 3, 2023
The First Python Compatible Camera Hacking Tool
ZCam Hack webcam using python by sending malicious link. FEATURES : [+] Real-time Camera hacking [+] Python compatible [+] URL Shortener using bitly [
 109 Dec 28, 2022
109 Dec 28, 2022
We protect the privacy of the data on your computer by using the camera of your Debian based Pardus operating system. 🕵️
Pardus Lookout We protect the privacy of the data on your computer by using the camera of your Debian based Pardus operating system. The application i
 19 Nov 18, 2022
19 Nov 18, 2022
A PyTorch library for Vision Transformers
VFormer A PyTorch library for Vision Transformers Getting Started Read the contributing guidelines in CONTRIBUTING.rst to learn how to start contribut
 142 Nov 28, 2022
142 Nov 28, 2022

Realtime Face Anti Spoofing with Face Detector based on Deep Learning using Tensorflow/Keras and OpenCV
Realtime Face Anti-Spoofing Detection 🤖 Realtime Face Anti Spoofing Detection with Face Detector to detect real and fake faces Please star this repo
 86 Aug 3, 2022
86 Aug 3, 2022

Implementation for our ICCV 2021 paper: Dual-Camera Super-Resolution with Aligned Attention Modules
DCSR: Dual Camera Super-Resolution Implementation for our ICCV 2021 oral paper: Dual-Camera Super-Resolution with Aligned Attention Modules paper | pr
 110 Dec 20, 2022
110 Dec 20, 2022
MegFlow - Efficient ML solutions for long-tailed demands.
Efficient ML solutions for long-tailed demands.
 371 Dec 21, 2022
371 Dec 21, 2022
Bridging Vision and Language Model
BriVL BriVL (Bridging Vision and Language Model) 是首个中文通用图文多模态大规模预训练模型。BriVL模型在图文检索任务上有着优异的效果,超过了同期其他常见的多模态预训练模型(例如UNITER、CLIP)。 BriVL论文:WenLan: Bridgi
 235 Dec 27, 2022
235 Dec 27, 2022

CTRL-C: Camera calibration TRansformer with Line-Classification
CTRL-C: Camera calibration TRansformer with Line-Classification This repository contains the official code and pretrained models for CTRL-C (Camera ca
 57 Nov 14, 2022
57 Nov 14, 2022

CMT: Convolutional Neural Networks Meet Vision Transformers
CMT: Convolutional Neural Networks Meet Vision Transformers [arxiv] 1. Introduction This repo is the CMT model which impelement with pytorch, no refer
 83 Dec 30, 2022
83 Dec 30, 2022

Image Captioning using CNN and Transformers
Image-Captioning Keras/Tensorflow Image Captioning application using CNN and Transformer as encoder/decoder. In particulary, the architecture consists
 24 Dec 28, 2022
24 Dec 28, 2022

TorchIO is a Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
Medical image preprocessing and augmentation toolkit for deep learning. Part of the PyTorch Ecosystem.
 1.6k Jan 6, 2023
1.6k Jan 6, 2023

Lightweight stereo matching network based on MobileNetV1 and MobileNetV2
MobileStereoNet: Towards Lightweight Deep Networks for Stereo Matching
 139 Nov 30, 2022
139 Nov 30, 2022

Prototype for Baby Action Detection and Classification
Baby Action Detection Table of Contents About Install Run Predictions Demo About An attempt to harness the power of Deep Learning to come up with a so
 30 Dec 16, 2022
30 Dec 16, 2022

Python scripts for performing stereo depth estimation using the HITNET Tensorflow model.
HITNET-Stereo-Depth-estimation Python scripts for performing stereo depth estimation using the HITNET Tensorflow model from Google Research. Stereo de
 76 Jan 2, 2023
76 Jan 2, 2023

Code for "Searching for Efficient Multi-Stage Vision Transformers"
Searching for Efficient Multi-Stage Vision Transformers This repository contains the official Pytorch implementation of "Searching for Efficient Multi
 62 Oct 25, 2022
62 Oct 25, 2022

GeDML is an easy-to-use generalized deep metric learning library
GeDML is an easy-to-use generalized deep metric learning library
 32 Dec 5, 2022
32 Dec 5, 2022

Implementation for our ICCV 2021 paper: Dual-Camera Super-Resolution with Aligned Attention Modules
DCSR: Dual Camera Super-Resolution Implementation for our ICCV 2021 oral paper: Dual-Camera Super-Resolution with Aligned Attention Modules paper | pr
110 Dec 20, 2022

The code repository for EMNLP 2021 paper "Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization".
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization [Paper] accepted at the EMNLP 2021: Vision Guided Genera
 42 Jan 7, 2023
42 Jan 7, 2023

Fuse radar and camera for detection
SAF-FCOS: Spatial Attention Fusion for Obstacle Detection using MmWave Radar and Vision Sensor This project hosts the code for implementing the SAF-FC
 18 Jan 1, 2023
18 Jan 1, 2023
![[ICCV 2021 Oral] NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo](https://github.com/weiyithu/NerfingMVS/raw/main/imgs/demo.gif)
[ICCV 2021 Oral] NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo
NerfingMVS Project Page | Paper | Video | Data NerfingMVS: Guided Optimization of Neural Radiance Fields for Indoor Multi-view Stereo Yi Wei, Shaohui
 369 Dec 24, 2022
369 Dec 24, 2022
![[ICCV21] Self-Calibrating Neural Radiance Fields](https://github.com/POSTECH-CVLab/SCNeRF/raw/master/assets/scnerf_teaser.png)
[ICCV21] Self-Calibrating Neural Radiance Fields
Self-Calibrating Neural Radiance Fields, ICCV, 2021 Project Page | Paper | Video Author Information Yoonwoo Jeong [Google Scholar] Seokjun Ahn [Google
 381 Dec 30, 2022
381 Dec 30, 2022

Code for Blind Image Decomposition (BID) and Blind Image Decomposition network (BIDeN).
arXiv, porject page, paper Blind Image Decomposition (BID) Blind Image Decomposition is a novel task. The task requires separating a superimposed imag
 64 Dec 20, 2022
64 Dec 20, 2022
Camera track the tip of a pen to use as a drawing tablet
cablet Camera track the tip of a pen to use as a drawing tablet Setup You will need: Writing utensil with a colored tip (preferably blue or green) Bac
 14 Feb 20, 2022
14 Feb 20, 2022

PaddleViT: State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 2.0+
PaddlePaddle Vision Transformers State-of-the-art Visual Transformer and MLP Models for PaddlePaddle 🤖 PaddlePaddle Visual Transformers (PaddleViT or
 1k Dec 28, 2022
1k Dec 28, 2022

The Official Implementation of the ICCV-2021 Paper: Semantically Coherent Out-of-Distribution Detection.
SCOOD-UDG (ICCV 2021) This repository is the official implementation of the paper: Semantically Coherent Out-of-Distribution Detection Jingkang Yang,
 62 Nov 21, 2022
62 Nov 21, 2022

Deep Unsupervised 3D SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment.
(ACMMM 2021 Oral) SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment This repository shows two tasks: Face landmark detection and Fac
 51 Dec 13, 2022
51 Dec 13, 2022

(ICCV'21) Official PyTorch implementation of Relational Embedding for Few-Shot Classification
Relational Embedding for Few-Shot Classification (ICCV 2021) Dahyun Kang, Heeseung Kwon, Juhong Min, Minsu Cho [paper], [project hompage] We propose t
 82 Dec 24, 2022
82 Dec 24, 2022

The source code of CVPR 2019 paper "Deep Exemplar-based Video Colorization".
Deep Exemplar-based Video Colorization (Pytorch Implementation) Paper | Pretrained Model | Youtube video 🔥 | Colab demo Deep Exemplar-based Video Col
 253 Dec 27, 2022
253 Dec 27, 2022

LLVIP: A Visible-infrared Paired Dataset for Low-light Vision
LLVIP: A Visible-infrared Paired Dataset for Low-light Vision Project | Arxiv | Abstract It is very challenging for various visual tasks such as image
 377 Jan 7, 2023
377 Jan 7, 2023

CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
 100 Dec 28, 2022
100 Dec 28, 2022

SwinIR: Image Restoration Using Swin Transformer
SwinIR: Image Restoration Using Swin Transformer This repository is the official PyTorch implementation of SwinIR: Image Restoration Using Shifted Win
 2.4k Jan 8, 2023
2.4k Jan 8, 2023
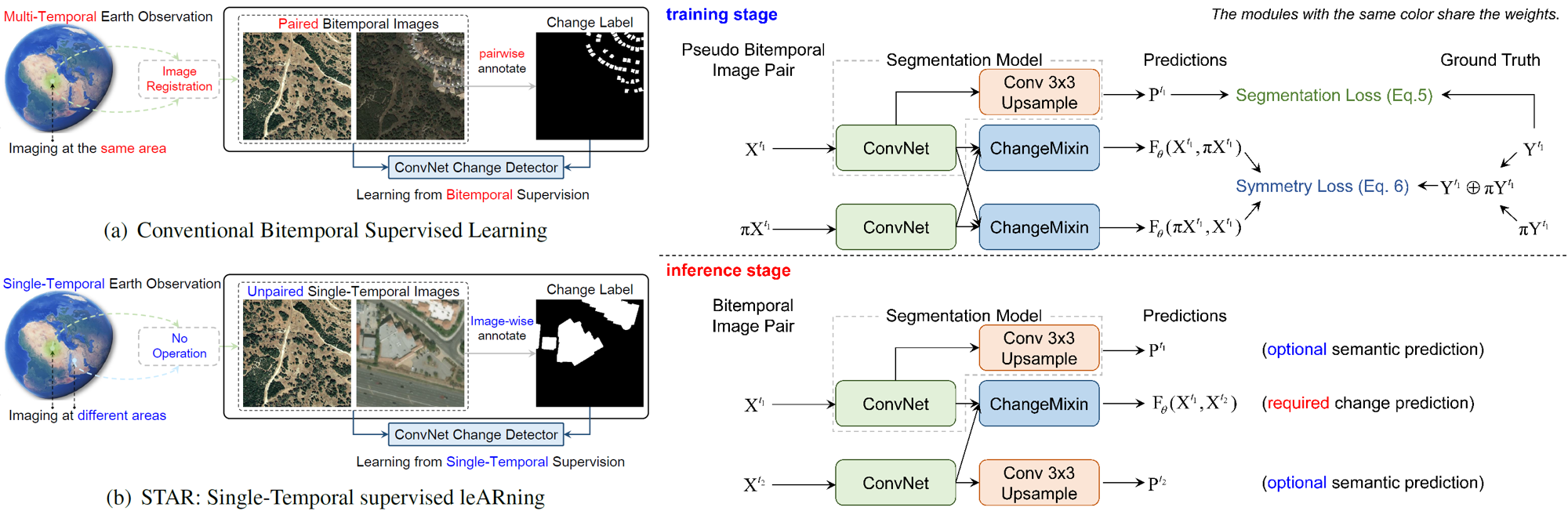
Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery (ICCV 2021)
Change is Everywhere Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery by Zhuo Zheng, Ailong Ma, Liangpei Zhang and Yanfei
125 Dec 13, 2022
CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
100 Dec 28, 2022

Robust Video Matting in PyTorch, TensorFlow, TensorFlow.js, ONNX, CoreML!
Robust Video Matting in PyTorch, TensorFlow, TensorFlow.js, ONNX, CoreML!
 6.5k Jan 4, 2023
6.5k Jan 4, 2023
Neural Message Passing for Computer Vision
Neural Message Passing for Quantum Chemistry Implementation of different models of Neural Networks on graphs as explained in the article proposed by G
 310 Nov 7, 2022
310 Nov 7, 2022

Many Class Activation Map methods implemented in Pytorch for CNNs and Vision Transformers. Including Grad-CAM, Grad-CAM++, Score-CAM, Ablation-CAM and XGrad-CAM
Class Activation Map methods implemented in Pytorch pip install grad-cam ⭐ Tested on many Common CNN Networks and Vision Transformers. ⭐ Includes smoo
 6.6k Jan 6, 2023
6.6k Jan 6, 2023
Deep Unsupervised 3D SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment.
(ACMMM 2021 Oral) SfM Face Reconstruction Based on Massive Landmark Bundle Adjustment This repository shows two tasks: Face landmark detection and Fac
51 Dec 13, 2022
rclip - AI-Powered Command-Line Photo Search Tool
rclip is a command-line photo search tool based on the awesome OpenAI's CLIP neural network.
 394 Dec 12, 2022
394 Dec 12, 2022
![[ICCV 2021 Oral] PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers](https://github.com/yuxumin/PoinTr/raw/master/fig/pointr.gif)
[ICCV 2021 Oral] PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers
PoinTr: Diverse Point Cloud Completion with Geometry-Aware Transformers Created by Xumin Yu*, Yongming Rao*, Ziyi Wang, Zuyan Liu, Jiwen Lu, Jie Zhou
 317 Dec 26, 2022
317 Dec 26, 2022
Image transformations designed for Scene Text Recognition (STR) data augmentation. Published at ICCV 2021 Workshop on Interactive Labeling and Data Augmentation for Vision.
Data Augmentation for Scene Text Recognition (ICCV 2021 Workshop) (Pronounced as "strog") Paper Arxiv Why it matters? Scene Text Recognition (STR) req
 152 Dec 28, 2022
152 Dec 28, 2022

Official code for paper "Demystifying Local Vision Transformer: Sparse Connectivity, Weight Sharing, and Dynamic Weight"
Demysitifing Local Vision Transformer, arxiv This is the official PyTorch implementation of our paper. We simply replace local self attention by (dyna
 138 Dec 28, 2022
138 Dec 28, 2022

Official code for "Focal Self-attention for Local-Global Interactions in Vision Transformers"
Focal Transformer This is the official implementation of our Focal Transformer -- "Focal Self-attention for Local-Global Interactions in Vision Transf
 486 Dec 20, 2022
486 Dec 20, 2022

Exploring Classification Equilibrium in Long-Tailed Object Detection, ICCV2021
Exploring Classification Equilibrium in Long-Tailed Object Detection (LOCE, ICCV 2021) Paper Introduction The conventional detectors tend to make imba
 52 Nov 21, 2022
52 Nov 21, 2022

X-modaler is a versatile and high-performance codebase for cross-modal analytics.
X-modaler X-modaler is a versatile and high-performance codebase for cross-modal analytics. This codebase unifies comprehensive high-quality modules i
 910 Dec 28, 2022
910 Dec 28, 2022

TOOD: Task-aligned One-stage Object Detection, ICCV2021 Oral
One-stage object detection is commonly implemented by optimizing two sub-tasks: object classification and localization, using heads with two parallel branches, which might lead to a certain level of spatial misalignment in predictions between the two tasks.
264 Jan 9, 2023
3D ResNets for Action Recognition (CVPR 2018)
3D ResNets for Action Recognition Update (2020/4/13) We published a paper on arXiv. Hirokatsu Kataoka, Tenga Wakamiya, Kensho Hara, and Yutaka Satoh,
 3.5k Jan 6, 2023
3.5k Jan 6, 2023
A curated list of resources for Image and Video Deblurring
A curated list of resources for Image and Video Deblurring
 1.7k Jan 1, 2023
1.7k Jan 1, 2023

Fog Simulation on Real LiDAR Point Clouds for 3D Object Detection in Adverse Weather
LiDAR fog simulation Created by Martin Hahner at the Computer Vision Lab of ETH Zurich. This is the official code release of the paper Fog Simulation
 110 Dec 30, 2022
110 Dec 30, 2022
QTool: A Low-bit Quantization Toolbox for Deep Neural Networks in Computer Vision
This project provides abundant choices of quantization strategies (such as the quantization algorithms, training schedules and empirical tricks) for quantizing the deep neural networks into low-bit counterparts.
 51 Dec 10, 2022
51 Dec 10, 2022

pix2tex: Using a ViT to convert images of equations into LaTeX code.
The goal of this project is to create a learning based system that takes an image of a math formula and returns corresponding LaTeX code.
 2.6k Dec 30, 2022
2.6k Dec 30, 2022

Towards Interpretable Deep Metric Learning with Structural Matching
DIML Created by Wenliang Zhao*, Yongming Rao*, Ziyi Wang, Jiwen Lu, Jie Zhou This repository contains PyTorch implementation for paper Towards Interpr
 75 Nov 11, 2022
75 Nov 11, 2022

Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision. ICCV 2021.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision Download links and PyTorch implementation of "Towers of Ba
 40 Dec 14, 2022
40 Dec 14, 2022

This is an official implementation of the High-Resolution Transformer for Dense Prediction.
High-Resolution Transformer for Dense Prediction Introduction This is the official implementation of High-Resolution Transformer (HRT). We present a H
 403 Dec 13, 2022
403 Dec 13, 2022
An organized collection of tutorials and projects created for aspriring computer vision students.
A repository created with the purpose of teaching students in BME lab 308A- Hanoi University of Science and Technology
 5 Nov 24, 2021
5 Nov 24, 2021

In this project we investigate the performance of the SetCon model on realistic video footage. Therefore, we implemented the model in PyTorch and tested the model on two example videos.
Contrastive Learning of Object Representations Supervisor: Prof. Dr. Gemma Roig Institutions: Goethe University CVAI - Computational Vision & Artifici
 6 Dec 8, 2022
6 Dec 8, 2022
FastReID is a research platform that implements state-of-the-art re-identification algorithms.
FastReID is a research platform that implements state-of-the-art re-identification algorithms.
 2.8k Jan 7, 2023
2.8k Jan 7, 2023

3D position tracking for soccer players with multi-camera videos
This repo contains a full pipeline to support 3D position tracking of soccer players, with multi-view calibrated moving/fixed video sequences as inputs.
 72 Dec 27, 2022
72 Dec 27, 2022
Vision-Language Transformer and Query Generation for Referring Segmentation (ICCV 2021)
Vision-Language Transformer and Query Generation for Referring Segmentation Please consider citing our paper in your publications if the project helps
 143 Dec 23, 2022
143 Dec 23, 2022

10th place solution for Google Smartphone Decimeter Challenge at kaggle.
Under refactoring 10th place solution for Google Smartphone Decimeter Challenge at kaggle. Google Smartphone Decimeter Challenge Global Navigation Sat
 12 Oct 25, 2022
12 Oct 25, 2022

Learning and Building Convolutional Neural Networks using PyTorch
Image Classification Using Deep Learning Learning and Building Convolutional Neural Networks using PyTorch. Models, selected are based on number of ci
 126 Dec 22, 2022
126 Dec 22, 2022
Extreme Rotation Estimation using Dense Correlation Volumes
Extreme Rotation Estimation using Dense Correlation Volumes This repository contains a PyTorch implementation of the paper: Extreme Rotation Estimatio
 29 Nov 18, 2022
29 Nov 18, 2022

We evaluate our method on different datasets (including ShapeNet, CUB-200-2011, and Pascal3D+) and achieve state-of-the-art results, outperforming all the other supervised and unsupervised methods and 3D representations, all in terms of performance, accuracy, and training time.
An Effective Loss Function for Generating 3D Models from Single 2D Image without Rendering Papers with code | Paper Nikola Zubić Pietro Lio University
 213 Dec 27, 2022
213 Dec 27, 2022

Automatic Calibration for Non-repetitive Scanning Solid-State LiDAR and Camera Systems
ACSC Automatic extrinsic calibration for non-repetitive scanning solid-state LiDAR and camera systems. System Architecture 1. Dependency Tested with U
 192 Dec 13, 2022
192 Dec 13, 2022

Vision Transformer and MLP-Mixer Architectures
Vision Transformer and MLP-Mixer Architectures Update (2.7.2021): Added the "When Vision Transformers Outperform ResNets..." paper, and SAM (Sharpness
 6.4k Jan 4, 2023
6.4k Jan 4, 2023
Code for the paper "VisualBERT: A Simple and Performant Baseline for Vision and Language"
This repository contains code for the following two papers: VisualBERT: A Simple and Performant Baseline for Vision and Language (arxiv) with a short
 463 Dec 9, 2022
463 Dec 9, 2022
Multi Task Vision and Language
12-in-1: Multi-Task Vision and Language Representation Learning Please cite the following if you use this code. Code and pre-trained models for 12-in-
 712 Dec 19, 2022
712 Dec 19, 2022

(CVPR2021) Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain Mingchen Zhuge*, Dehong Gao*, Deng-Ping Fan#, Linbo Jin, Ben Chen, Haoming Zhou, Minghui
 250 Jan 8, 2023
250 Jan 8, 2023

Exploring Image Deblurring via Blur Kernel Space (CVPR'21)
Exploring Image Deblurring via Encoded Blur Kernel Space About the project We introduce a method to encode the blur operators of an arbitrary dataset
 118 Dec 19, 2022
118 Dec 19, 2022

Official implementation of the paper Vision Transformer with Progressive Sampling, ICCV 2021.
Vision Transformer with Progressive Sampling This is the official implementation of the paper Vision Transformer with Progressive Sampling, ICCV 2021.
 123 Jan 1, 2023
123 Jan 1, 2023

Code for generating a single image pretraining dataset
Single Image Pretraining of Visual Representations As shown in the paper A critical analysis of self-supervision, or what we can learn from a single i
 12 Dec 19, 2022
12 Dec 19, 2022

Implementation for our ICCV2021 paper: Internal Video Inpainting by Implicit Long-range Propagation
Implicit Internal Video Inpainting Implementation for our ICCV2021 paper: Internal Video Inpainting by Implicit Long-range Propagation paper | project
202 Dec 30, 2022
Video Contrastive Learning with Global Context
Video Contrastive Learning with Global Context (VCLR) This is the official PyTorch implementation of our VCLR paper. Install dependencies environments
143 Dec 26, 2022
Scenic: A Jax Library for Computer Vision and Beyond
Scenic Scenic is a codebase with a focus on research around attention-based models for computer vision. Scenic has been successfully used to develop c
1.6k Dec 27, 2022

FPGA: Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification
FPGA & FreeNet Fast Patch-Free Global Learning Framework for Fully End-to-End Hyperspectral Image Classification by Zhuo Zheng, Yanfei Zhong, Ailong M
92 Jan 3, 2023

Code for our CVPR 2021 Paper "Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes".
Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes (CVPR 2021) Project page | Paper | Colab | Colab for Drawing App Rethinking Style
 153 Jan 4, 2023
153 Jan 4, 2023

Open-World Entity Segmentation
Open-World Entity Segmentation Project Website Lu Qi*, Jason Kuen*, Yi Wang, Jiuxiang Gu, Hengshuang Zhao, Zhe Lin, Philip Torr, Jiaya Jia This projec
 410 Jan 3, 2023
410 Jan 3, 2023
TF2 implementation of knowledge distillation using the "function matching" hypothesis from the paper Knowledge distillation: A good teacher is patient and consistent by Beyer et al.
FunMatch-Distillation TF2 implementation of knowledge distillation using the "function matching" hypothesis from the paper Knowledge distillation: A g
 67 Dec 20, 2022
67 Dec 20, 2022
A Telegram Bot to prevent Night Spams
NightModeBot A Telegram Bot to lock group in night to prevent night spam Setps To Use - Put Variables Correctly. - Add Bot to your group and make admi
 10 Oct 21, 2022
10 Oct 21, 2022

The code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention.
CrossFormer This repository is the code for our paper CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention. Introduction Existin
 238 Jan 6, 2023
238 Jan 6, 2023

meProp: Sparsified Back Propagation for Accelerated Deep Learning
meProp The codes were used for the paper meProp: Sparsified Back Propagation for Accelerated Deep Learning with Reduced Overfitting (ICML 2017) [pdf]
 107 Nov 18, 2022
107 Nov 18, 2022

Image Deblurring using Generative Adversarial Networks
DeblurGAN arXiv Paper Version Pytorch implementation of the paper DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. Our netwo
 2.2k Jan 1, 2023
2.2k Jan 1, 2023

Synthesizing and manipulating 2048x1024 images with conditional GANs
pix2pixHD Project | Youtube | Paper Pytorch implementation of our method for high-resolution (e.g. 2048x1024) photorealistic image-to-image translatio
 6k Dec 27, 2022
6k Dec 27, 2022

PyTorch implementation of the YOLO (You Only Look Once) v2
PyTorch implementation of the YOLO (You Only Look Once) v2 The YOLOv2 is one of the most popular one-stage object detector. This project adopts PyTorc
 433 Nov 24, 2022
433 Nov 24, 2022
PyTorch Implementation of Realtime Multi-Person Pose Estimation project.
PyTorch Realtime Multi-Person Pose Estimation This is a pytorch version of Realtime_Multi-Person_Pose_Estimation, origin code is here Realtime_Multi-P
 157 Nov 12, 2022
157 Nov 12, 2022

PyTorch implementation of 1712.06087 "Zero-Shot" Super-Resolution using Deep Internal Learning
Unofficial PyTorch implementation of "Zero-Shot" Super-Resolution using Deep Internal Learning Unofficial Implementation of 1712.06087 "Zero-Shot" Sup
196 Nov 27, 2022
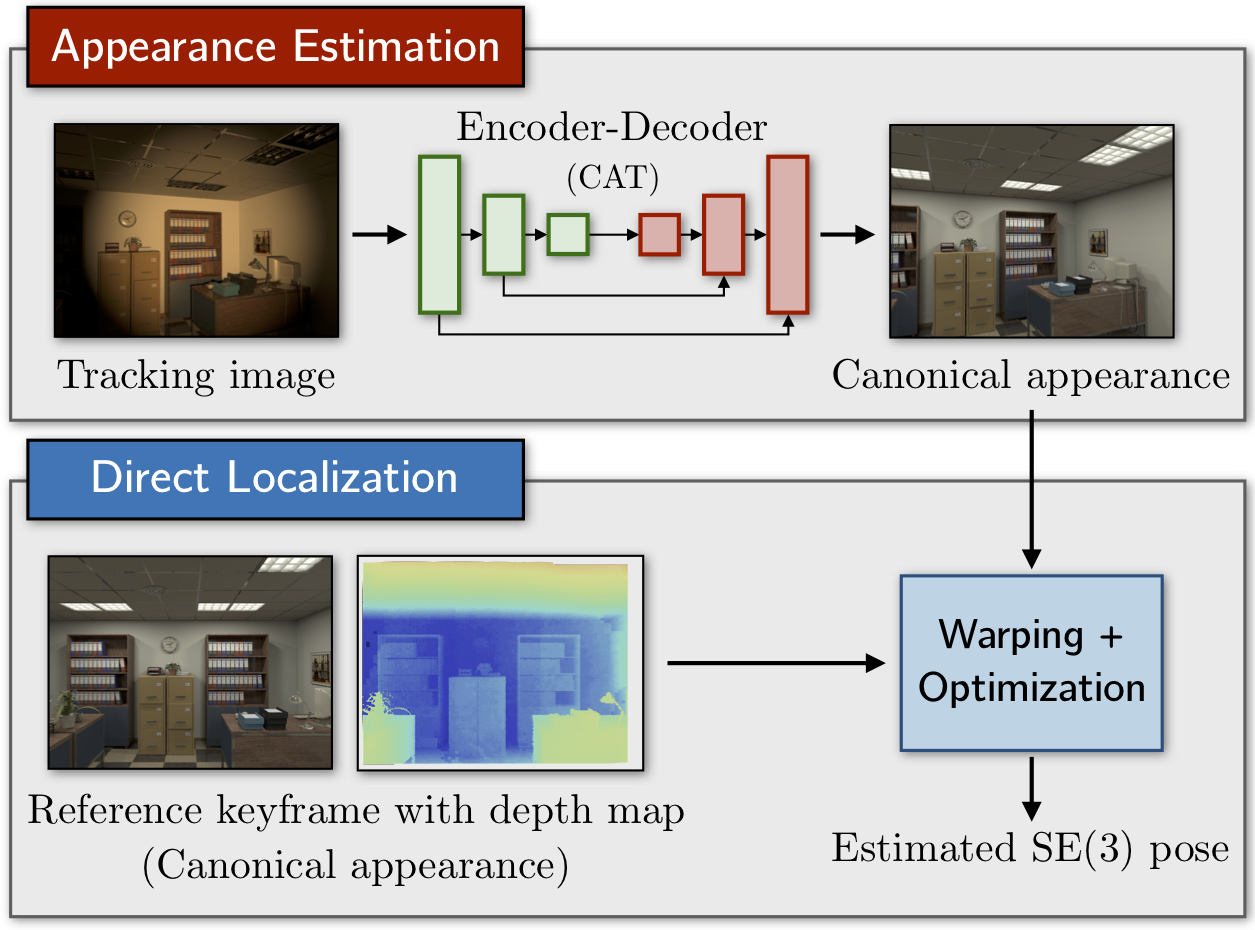
Canonical Appearance Transformations
CAT-Net: Learning Canonical Appearance Transformations Code to accompany our paper "How to Train a CAT: Learning Canonical Appearance Transformations
 54 Dec 24, 2022
54 Dec 24, 2022

This's an implementation of deepmind Visual Interaction Networks paper using pytorch
Visual-Interaction-Networks An implementation of Deepmind visual interaction networks in Pytorch. Introduction For the purpose of understanding the ch
 166 Dec 6, 2022
166 Dec 6, 2022

A PyTorch Implementation of Neural IMage Assessment
NIMA: Neural IMage Assessment This is a PyTorch implementation of the paper NIMA: Neural IMage Assessment (accepted at IEEE Transactions on Image Proc
 418 Dec 29, 2022
418 Dec 29, 2022
NIMA: Neural IMage Assessment
PyTorch NIMA: Neural IMage Assessment PyTorch implementation of Neural IMage Assessment by Hossein Talebi and Peyman Milanfar. You can learn more from
 293 Dec 30, 2022
293 Dec 30, 2022
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks
Stochastic Downsampling for Cost-Adjustable Inference and Improved Regularization in Convolutional Networks (SDPoint) This repository contains the cod
 17 Jul 4, 2022
17 Jul 4, 2022

CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped
CSWin-Transformer This repo is the official implementation of "CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows". Th
409 Jan 6, 2023