3218 Repositories
Python open-data Libraries
OpenL3: Open-source deep audio and image embeddings
OpenL3 OpenL3 is an open-source Python library for computing deep audio and image embeddings. Please refer to the documentation for detailed instructi
 326 Jan 2, 2023
326 Jan 2, 2023
Primitives for machine learning and data science.
An Open Source Project from the Data to AI Lab, at MIT MLPrimitives Pipelines and primitives for machine learning and data science. Documentation: htt
 65 Dec 29, 2022
65 Dec 29, 2022

The open source extract transaction infomation by using OCR.
Transaction OCR Mã nguồn trích xuất thông tin transaction từ file scaned pdf, ở đây tôi lựa chọn tài liệu sao kê công khai của Thuy Tien. Mã nguồn có
 18 Jun 2, 2022
18 Jun 2, 2022
A free and open-source SMS/Call bombing application
TBOMB V0.1 A free and open-source SMS/Call bombing application NOTE: For Termux To use the bomber type the following commands in Termux: pkg install g
 2 Dec 7, 2021
2 Dec 7, 2021
An helper library to scrape data from Instagram effortlessly, using the Influencer Hunters APIs.
Instagram Scraper An utility library to scrape data from Instagram hassle-free Go to the website » View Demo · Report Bug · Request Feature About The
 2 Jul 6, 2022
2 Jul 6, 2022
tradingview socket api for fetching real time prices.
tradingView-API tradingview socket api for fetching real time prices. How to run git clone https://github.com/mohamadkhalaj/tradingView-API.git cd tra
 35 Dec 31, 2022
35 Dec 31, 2022
This repository is used to provide data to zzhack,
This repository is used to provide data to zzhack, but you don't have to care about anything, just write your thinking down, and you can see your thinking is rendered in zzhack perfectly
 5 Apr 29, 2022
5 Apr 29, 2022
![[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data](https://github.com/EndlessSora/DeceiveD/raw/main/resources/teaser.jpg)
[NeurIPS 2021] Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data (NeurIPS 2021) This repository provides the official PyTorch implementation
 155 Nov 30, 2021
155 Nov 30, 2021
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
Scrapping the data from each page of biocides listed on the BAUA website into a csv file
 1 Nov 30, 2021
1 Nov 30, 2021
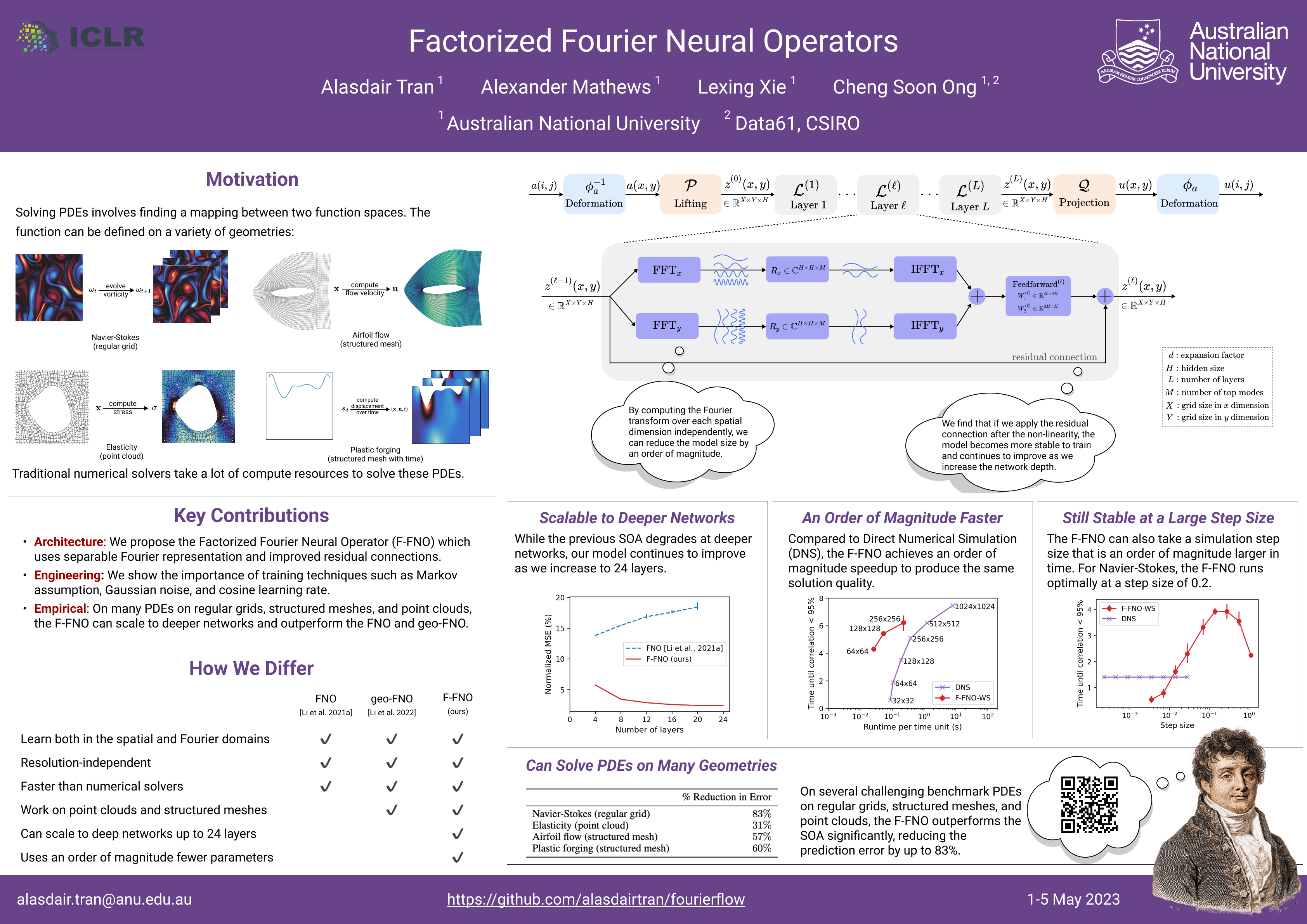
Experiments with Fourier layers on simulation data.
Factorized Fourier Neural Operators This repository contains the code to reproduce the results in our NeurIPS 2021 ML4PS workshop paper, Factorized Fo
 57 Dec 25, 2022
57 Dec 25, 2022
The first GANs-based omics-to-omics translation framework
OmiTrans Please also have a look at our multi-omics multi-task DL freamwork 👀 : OmiEmbed The FIRST GANs-based omics-to-omics translation framework Xi
 1 Nov 30, 2021
1 Nov 30, 2021
Auxiliary data to the CHIIR paper Searching to Learn with Instructional Scaffolding
Searching to Learn with Instructional Scaffolding This is the data and analysis code for the paper "Searching to Learn with Instructional Scaffolding"
 2 Mar 2, 2022
2 Mar 2, 2022
Source Code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chinese Question Matching
Description The source code and data for my paper titled Linguistic Knowledge in Data Augmentation for Natural Language Processing: An Example on Chin
 3 Jun 28, 2022
3 Jun 28, 2022

A program that analyzes data from inertia measurement units installed in aircraft and generates g-exceedance curves.
A program that analyzes data from inertia measurement units installed in aircraft and generates g-exceedance curves.
 1 Dec 2, 2021
1 Dec 2, 2021
Data wrangling & common calculations for results from qMem measurement software
qMem Datawrangler This script processes output of qMem measurement software into an Origin ® compatible *.csv files and matplotlib graphs to quickly v
 1 Nov 30, 2021
1 Nov 30, 2021
Django based webapp pulling in crypto news and price data via api
Deploy Django in Production FTA project implementing containerization of Django Web Framework into Docker to be placed into Azure Container Services a
 0 Sep 21, 2022
0 Sep 21, 2022

Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Vedaldi, Andrew Zisserman, CVPR 2016.
SynthText Code for generating synthetic text images as described in "Synthetic Data for Text Localisation in Natural Images", Ankush Gupta, Andrea Ved
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

🛰️ Scripts démontrant l'utilisation de l'imagerie RADARSAT-1 à partir d'un seau AWS | 🛰️ Scripts demonstrating the use of RADARSAT-1 imagery from an AWS bucket
🛰️ Scripts démontrant l'utilisation de l'imagerie RADARSAT-1 à partir d'un seau AWS | 🛰️ Scripts demonstrating the use of RADARSAT-1 imagery from an AWS bucket
 4 May 18, 2022
4 May 18, 2022

Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER (EMNLP 2021).
Data and evaluation code for the paper WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. @inproceedings{tedes
 40 Dec 11, 2022
40 Dec 11, 2022

This is a python script to grab data from Zyxel NSA310 NAS and display in Home Asisstant as sensors.
Home-Assistant Python Scripts Python Scripts for Home-Assistant (http://www.home-assistant.io) Zyxel-NSA310-Home-Assistant Monitoring This is a python
 6 Oct 31, 2022
6 Oct 31, 2022
Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics.
Bonnet: An Open-Source Training and Deployment Framework for Semantic Segmentation in Robotics. By Andres Milioto @ University of Bonn. (for the new P
 314 Dec 30, 2022
314 Dec 30, 2022

A real world application of a Recurrent Neural Network on a binary classification of time series data
What is this This is a real world application of a Recurrent Neural Network on a binary classification of time series data. This project includes data
 2 Jan 30, 2022
2 Jan 30, 2022

APIlocal_dbAWS_RDS - Disclaimer! All data used is for educational purposes only.
APIlocal_dbAWS_RDS Disclaimer! All data used is for educational purposes only. ETL pipeline diagram. Aim of project By creating a fully working pipe
 0 Apr 25, 2022
0 Apr 25, 2022
AI assistant built in python.the features are it can display time,say weather,open-google,youtube,instagram.
AI assistant built in python.the features are it can display time,say weather,open-google,youtube,instagram.
 1 Nov 29, 2021
1 Nov 29, 2021
Flexible time series feature extraction & processing
tsflex is a toolkit for flexible time series processing & feature extraction, that is efficient and makes few assumptions about sequence data. Useful
 206 Dec 28, 2022
206 Dec 28, 2022

DuBE: Duple-balanced Ensemble Learning from Skewed Data
DuBE: Duple-balanced Ensemble Learning from Skewed Data "Towards Inter-class and Intra-class Imbalance in Class-imbalanced Learning" (IEEE ICDE 2022 S
 6 Nov 12, 2022
6 Nov 12, 2022

Fast mesh denoising with data driven normal filtering using deep variational autoencoders
Fast mesh denoising with data driven normal filtering using deep variational autoencoders This is an implementation for the paper entitled "Fast mesh
 9 Dec 2, 2022
9 Dec 2, 2022

IMBENS: class-imbalanced ensemble learning in Python.
IMBENS: class-imbalanced ensemble learning in Python. Links: [Documentation] [Gallery] [PyPI] [Changelog] [Source] [Download] [知乎/Zhihu] [中文README] [a
 176 Jan 4, 2023
176 Jan 4, 2023
Research code for the paper "Variational Gibbs inference for statistical estimation from incomplete data".
Variational Gibbs inference (VGI) This repository contains the research code for Simkus, V., Rhodes, B., Gutmann, M. U., 2021. Variational Gibbs infer
 1 Apr 8, 2022
1 Apr 8, 2022

Deep Learning Emotion decoding using EEG data from Autism individuals
Deep Learning Emotion decoding using EEG data from Autism individuals This repository includes the python and matlab codes using for processing EEG 2D
 12 Dec 8, 2022
12 Dec 8, 2022

This repository contains all code and data for the Inside Out Visual Place Recognition task
Inside Out Visual Place Recognition This repository contains code and instructions to reproduce the results for the Inside Out Visual Place Recognitio
 15 May 21, 2022
15 May 21, 2022

Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data
Traditional Chinese Text Recognition Dataset: Synthetic Dataset and Labeled Data Authors: Yi-Chang Chen, Yu-Chuan Chang, Yen-Cheng Chang and Yi-Ren Ye
 5 Dec 15, 2022
5 Dec 15, 2022
An open-source Kazakh named entity recognition dataset (KazNERD), annotation guidelines, and baseline NER models.
Kazakh Named Entity Recognition This repository contains an open-source Kazakh named entity recognition dataset (KazNERD), named entity annotation gui
 9 Dec 23, 2022
9 Dec 23, 2022
OpenLT: An open-source project for long-tail classification
OpenLT: An open-source project for long-tail classification Supported Methods for Long-tailed Recognition: Cross-Entropy Loss Focal Loss (ICCV'17) Cla
 37 Sep 15, 2022
37 Sep 15, 2022
Tool for running a high throughput data ingestion/transformation workload with MongoDB
Mongo Mangler The mongo-mangler tool is a lightweight Python utility, which you can run from a low-powered machine to execute a high throughput data i
 9 Jan 2, 2023
9 Jan 2, 2023
Gathering data of likes on Tinder within the past 7 days
tinder_likes_data Gathering data of Likes Sent on Tinder within the past 7 days. Versions November 25th, 2021 - Functionality to get the name and age
 12 Jan 5, 2023
12 Jan 5, 2023
Empresas do Brasil (CNPJs)
Biblioteca em Python que coleta informações cadastrais de empresas do Brasil (CNPJ) obtidas de fontes oficiais (Receita Federal) e exporta para um formato legível por humanos (CSV ou JSON).
 8 Aug 17, 2022
8 Aug 17, 2022
E-Commerce recommender demo with real-time data and a graph database
🔍 E-Commerce recommender demo 🔍 This is a simple stream setup that uses Memgraph to ingest real-time data from a simulated online store. Data is str
 3 Feb 23, 2022
3 Feb 23, 2022
Redis OM Python makes it easy to model Redis data in your Python applications.
Object mapping, and more, for Redis and Python Redis OM Python makes it easy to model Redis data in your Python applications. Redis OM Python | Redis
 568 Jan 2, 2023
568 Jan 2, 2023
A telegram bot for which is help to play songs in vc 🥰 give 🌟 and fork this repo before use 😏
TamilVcMusic 🌟 TamilVCMusicBot 🌟 Give your 💙 Before clicking on deploy to heroku just click on fork and star just below How to deploy Click the bel
 150 Dec 13, 2022
150 Dec 13, 2022

A procedural Blender pipeline for photorealistic training image generation
BlenderProc2 A procedural Blender pipeline for photorealistic rendering. Documentation | Tutorials | Examples | ArXiv paper | Workshop paper Features
 1.8k Jan 2, 2023
1.8k Jan 2, 2023
Nexum is an open-source, remote administration tool written in Python 3
A full-featured remote administration tool written in Python 3. The goal of this project is to make the use of a remote administration tool as simple
 2 Nov 26, 2021
2 Nov 26, 2021
Open source software for image correlation, distance and analysis
Douglas-Quaid Project Open source software for image correlation, distance and analysis. Strongly related to : Carl-Hauser Problem statement (@CIRCL)
 2 May 1, 2022
2 May 1, 2022
ObjectDetNet is an easy, flexible, open-source object detection framework
Getting started with the ObjectDetNet ObjectDetNet is an easy, flexible, open-source object detection framework which allows you to easily train, resu
 5 Aug 25, 2020
5 Aug 25, 2020
Open source platform for Data Science Management automation
Hydrosphere examples This repo contains demo scenarios and pre-trained models to show Hydrosphere capabilities. Data and artifacts management Some mod
 6 Aug 10, 2021
6 Aug 10, 2021
Training open neural machine translation models
Train Opus-MT models This package includes scripts for training NMT models using MarianNMT and OPUS data for OPUS-MT. More details are given in the Ma
 167 Jan 3, 2023
167 Jan 3, 2023
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate.
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate. Website • Key Features • How To Use • Docs •
 21.1k Jan 8, 2023
21.1k Jan 8, 2023
Learning from graph data using Keras
Steps to run = Download the cora dataset from this link : https://linqs.soe.ucsc.edu/data unzip the files in the folder input/cora cd code python eda
 64 Nov 16, 2022
64 Nov 16, 2022
Data pipelines built with polars
valves Warning: the project is very much work in progress. Valves is a collection of functions for your data .pipe()-lines. This project aimes to host
 14 Jan 3, 2023
14 Jan 3, 2023

CinnaMon is a Python library which offers a number of tools to detect, explain, and correct data drift in a machine learning system
CinnaMon is a Python library which offers a number of tools to detect, explain, and correct data drift in a machine learning system
 67 Dec 28, 2022
67 Dec 28, 2022
🗂️ 🔍 Geospatial Data Management and Search API - Django Apps
Geospatial Data API in Django Resonant GeoData (RGD) is a series of Django applications well suited for cataloging and searching annotated geospatial
 53 Nov 1, 2022
53 Nov 1, 2022
A package designed to scrape data from Yahoo Finance.
yahoostock A package designed to scrape data from Yahoo Finance. Installation The most simple installation method is through PIP. pip install yahoosto
 2 May 28, 2022
2 May 28, 2022
An index of algorithms for learning causality with data
awesome-causality-algorithms An index of algorithms for learning causality with data. Please cite our survey paper if this index is helpful. @article{
 2.3k Jan 8, 2023
2.3k Jan 8, 2023
Haystack is an open source NLP framework that leverages Transformer models.
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
 2.7k Nov 28, 2021
2.7k Nov 28, 2021
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022
Qlib is an AI-oriented quantitative investment platform
Qlib is an AI-oriented quantitative investment platform, which aims to realize the potential, empower the research, and create the value of AI technologies in quantitative investment.
10.1k Dec 30, 2022

We are building an open database of COVID-19 cases with chest X-ray or CT images.
🛑 Note: please do not claim diagnostic performance of a model without a clinical study! This is not a kaggle competition dataset. Please read this pa
 2.9k Dec 30, 2022
2.9k Dec 30, 2022
Automatically download the cwru data set, and then divide it into training data set and test data set
Automatically download the cwru data set, and then divide it into training data set and test data set.自动下载cwru数据集,然后分训练数据集和测试数据集
 6 Jun 27, 2022
6 Jun 27, 2022

Improve current data preprocessing for FTM's WOB data to analyze Shell and Dutch Governmental contacts.
We're the hackathon leftovers, but we are Too Good To Go ;-). A repo by Lukas Schubotz and Raymon van Dinter. We aim to improve current data preprocessing for FTM's WOB data to analyze Shell and Dutch Governmental contacts.
 5 Dec 9, 2021
5 Dec 9, 2021
Project under the certification "Data Analysis with Python" on FreeCodeCamp
Sea Level Predictor Assignment You will anaylize a dataset of the global average sea level change since 1880. You will use the data to predict the sea
 3 Jan 31, 2022
3 Jan 31, 2022
Tools for the analysis, simulation, and presentation of Lorentz TEM data.
ltempy ltempy is a set of tools for Lorentz TEM data analysis, simulation, and presentation. Features Single Image Transport of Intensity Equation (SI
 1 Dec 26, 2022
1 Dec 26, 2022
The FIRST GANs-based omics-to-omics translation framework
OmiTrans Please also have a look at our multi-omics multi-task DL freamwork 👀 : OmiEmbed The FIRST GANs-based omics-to-omics translation framework Xi
6 Dec 14, 2022
Finds, downloads, parses, and standardizes public bikeshare data into a standard pandas dataframe format
Finds, downloads, parses, and standardizes public bikeshare data into a standard pandas dataframe format.
 2 Dec 1, 2021
2 Dec 1, 2021
NYCT-GTFS - Real-time NYC subway data parsing for humans
NYCT-GTFS - Real-time NYC subway data parsing for humans This python library provides a human-friendly, native python interface for dealing with the N
 37 Dec 27, 2022
37 Dec 27, 2022
Data and codes for ACL 2021 paper: Towards Emotional Support Dialog Systems
Emotional-Support-Conversation Copyright © 2021 CoAI Group, Tsinghua University. All rights reserved. Data and codes are for academic research use onl
 126 Dec 21, 2022
126 Dec 21, 2022
Gathers data and displays metrics related to climate change and resource depletion on a PowerBI report.
Apocalypse Status Dashboard Purpose Climate change and resource depletion are grave long-term dangers. The code in this repository will pull data from
 1 Nov 12, 2021
1 Nov 12, 2021
An Open-Source Package for Information Retrieval.
OpenMatch An Open-Source Package for Information Retrieval. 😃 What's New Top Spot on TREC-COVID Challenge (May 2020, Round2) The twin goals of the ch
 439 Dec 27, 2022
439 Dec 27, 2022
Compilation of resources and insights that helped me on my journey to data scientist
Compilation of resources and insights that helped me on my journey to data scientist
 1.5k Jan 2, 2023
1.5k Jan 2, 2023
Towards Open-World Feature Extrapolation: An Inductive Graph Learning Approach
This repository holds the implementation for paper Towards Open-World Feature Extrapolation: An Inductive Graph Learning Approach Download our preproc
 42 Dec 27, 2022
42 Dec 27, 2022

A collection of online resources to help you on your Tech journey.
Everything Tech Resources & Projects About The Project Coming from an engineering background and looking to up skill yourself on a new field can be di
 396 Dec 31, 2022
396 Dec 31, 2022

This is Assignment1 code for the Web Data Processing System.
This is a Python program to Entity Linking by processing WARC files. We recognize entities from web pages and link them to a Knowledge Base(Wikidata).
 3 Dec 4, 2022
3 Dec 4, 2022
COVID-19 Chatbot with Rasa 2.0: open source conversational AI
COVID-19 chatbot implementation with Rasa open source 2.0, conversational AI framework.
 1 Dec 23, 2022
1 Dec 23, 2022
In the case of your data having only 1 channel while want to use timm models
timm_custom Description In the case of your data having only 1 channel while want to use timm models (with or without pretrained weights), run the fol
 2 Nov 26, 2021
2 Nov 26, 2021
Minimum Bounding Box of Geospatial data
BBOX Problem definition: The spatial data users often are required to obtain the coordinates of the minimum bounding box of vector and raster data in
 1 Sep 8, 2022
1 Sep 8, 2022
A logical, reasonably standardized, but flexible project structure for doing and sharing data science work.
Cookiecutter Data Science A logical, reasonably standardized, but flexible project structure for doing and sharing data science work. Project homepage
 6.4k Jan 2, 2023
6.4k Jan 2, 2023
Advanced Pandas Vault — Utilities, Functions and Snippets (by @firmai).
PandasVault — Advanced Pandas Functions and Code Snippets The only Pandas utility package you would ever need. It has no exotic external dependencies
 374 Jan 7, 2023
374 Jan 7, 2023

PandaPy has the speed of NumPy and the usability of Pandas 10x to 50x faster (by @firmai)
PandaPy "I came across PandaPy last week and have already used it in my current project. It is a fascinating Python library with a lot of potential to
527 Jan 2, 2023
Automatically visualize your pandas dataframe via a single print! 📊 💡
A Python API for Intelligent Visual Discovery Lux is a Python library that facilitate fast and easy data exploration by automating the visualization a
 4.3k Dec 28, 2022
4.3k Dec 28, 2022
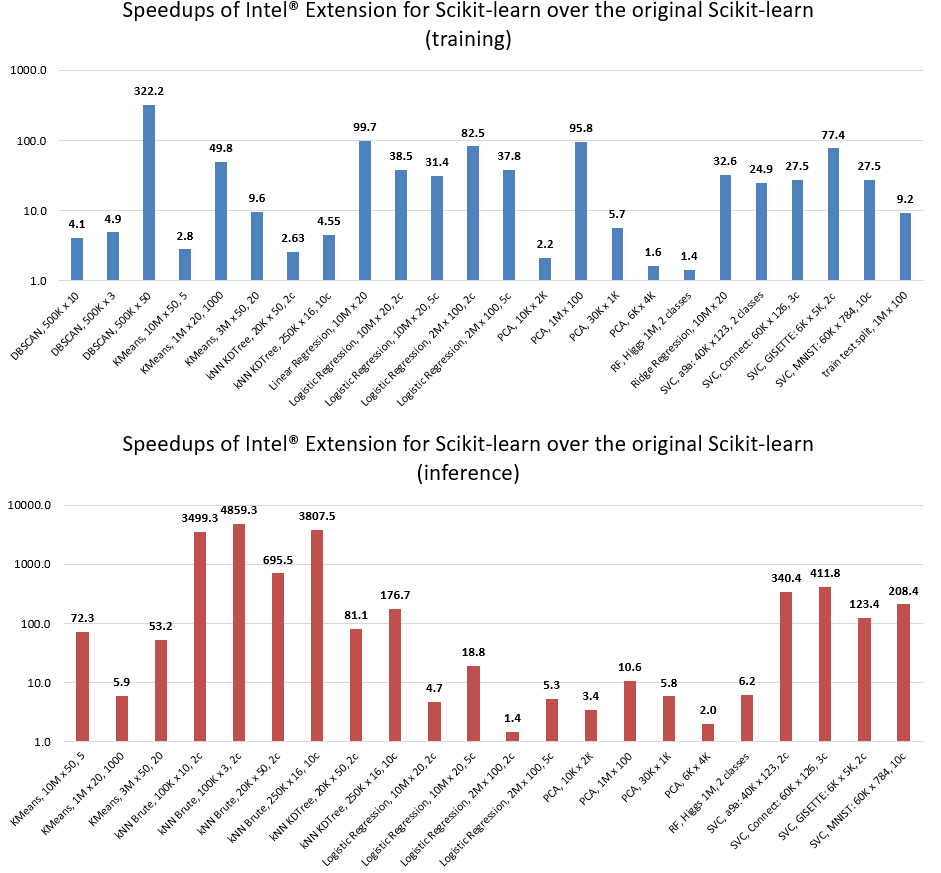
Intel(R) Extension for Scikit-learn is a seamless way to speed up your Scikit-learn application
Intel(R) Extension for Scikit-learn* Installation | Documentation | Examples | Support | FAQ With Intel(R) Extension for Scikit-learn you can accelera
 858 Dec 25, 2022
858 Dec 25, 2022
Finding project directories in Python (data science) projects, just like there R rprojroot and here packages
Find relative paths from a project root directory Finding project directories in Python (data science) projects, just like there R here and rprojroot
 102 Nov 16, 2022
102 Nov 16, 2022
Intake is a lightweight package for finding, investigating, loading and disseminating data.
Intake: A general interface for loading data Intake is a lightweight set of tools for loading and sharing data in data science projects. Intake helps
 851 Jan 1, 2023
851 Jan 1, 2023
Mars is a tensor-based unified framework for large-scale data computation which scales numpy, pandas, scikit-learn and Python functions.
Mars is a tensor-based unified framework for large-scale data computation which scales numpy, pandas, scikit-learn and many other libraries. Documenta
 2.5k Jan 7, 2023
2.5k Jan 7, 2023

A columnar data container that can be compressed.
Unmaintained Package Notice Unfortunately, and due to lack of resources, the Blosc Development Team is unable to maintain this package anymore. During
 944 Dec 9, 2022
944 Dec 9, 2022
Metrics to evaluate quality and efficacy of synthetic datasets.
An Open Source Project from the Data to AI Lab, at MIT Metrics for Synthetic Data Generation Projects Website: https://sdv.dev Documentation: https://
 129 Jan 3, 2023
129 Jan 3, 2023
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
NVTabular is a feature engineering and preprocessing library for tabular data designed to quickly and easily manipulate terabyte scale datasets used to train deep learning based recommender systems.
 880 Jan 7, 2023
880 Jan 7, 2023

A DSL for data-driven computational pipelines
"Dataflow variables are spectacularly expressive in concurrent programming" Henri E. Bal , Jennifer G. Steiner , Andrew S. Tanenbaum Quick overview Ne
 1.9k Jan 3, 2023
1.9k Jan 3, 2023

Integrate bus data from a variety of sources (batch processing and real time processing).
Purpose: This is integrate bus data from a variety of sources such as: csv, json api, sensor data ... into Relational Database (batch processing and r
 1 Nov 25, 2021
1 Nov 25, 2021
Python script for diving image data to train test and val
dataset-division-to-train-val-test-python python script for dividing image data to train test and val If you have an image dataset in the following st
 1 Nov 14, 2022
1 Nov 14, 2022

RecList is an open source library providing behavioral, "black-box" testing for recommender systems.
RecList is an open source library providing behavioral, "black-box" testing for recommender systems.
 375 Dec 30, 2022
375 Dec 30, 2022
Data repo for one-among.us
Our Data Data repo for one-among.us File Structure Directory /people/userid/: Data for a specific person info.json5: Profile information page.md: Pr
 55 Dec 30, 2022
55 Dec 30, 2022
Pydantic based mock data generation
This library offers powerful mock data generation capabilities for pydantic based models. It can also be used with other libraries that use pydantic as a foundation, for example SQLModel, Beanie and ormar.
 396 Dec 28, 2022
396 Dec 28, 2022

Maze generator and solver with python
Procedural-Maze-Generator-Algorithms Check out my youtube channel : Auctux Ressources Thanks to Jamis Buck Book : Mazes for programmers Requirements P
 19 Dec 7, 2022
19 Dec 7, 2022
An open source algorithm and dataset for finding poop in pictures.
The shitspotter module is where I will be work on the "shitspotter" poop-detection algorithm and dataset. The primary goal of this work is to allow for the creation of a phone app that finds where your dog pooped, because you ran to grab the doggy-bags you forgot, and now you can't find the damn thing.
 29 Nov 29, 2022
29 Nov 29, 2022

Helping you manage your data science projects sanely.
PyDS CLI Helping you manage your data science projects sanely. Requirements Anaconda/Miniconda/Miniforge/Mambaforge (Mambaforge recommended!) git on y
 16 Apr 25, 2022
16 Apr 25, 2022

Source files for the data lake demo video using the AWS TICKIT database
Data Lake Demo Source code for video demonstration detailed in the post, Building a Simple Data Lake on AWS . Build a simple data lake on AWS using a
 97 Dec 23, 2022
97 Dec 23, 2022

The official PyTorch code for NeurIPS 2021 ML4AD Paper, "Does Thermal data make the detection systems more reliable?"
MultiModal-Collaborative (MMC) Learning Framework for integrating RGB and Thermal spectral modalities This is the official code for NeurIPS 2021 Machi
 5 Nov 25, 2021
5 Nov 25, 2021

This repository contains part of the code used to make the images visible in the article "How does an AI Imagine the Universe?" published on Towards Data Science.
Generative Adversarial Network - Generating Universe This repository contains part of the code used to make the images visible in the article "How doe
 9 Dec 18, 2022
9 Dec 18, 2022
AWS documentation corpus for zero-shot open-book question answering.
aws-documentation We present the AWS documentation corpus, an open-book QA dataset, which contains 25,175 documents along with 100 matched questions a
 2 Jul 7, 2022
2 Jul 7, 2022
eBay's TSV Utilities: Command line tools for large, tabular data files. Filtering, statistics, sampling, joins and more.
Command line utilities for tabular data files This is a set of command line utilities for manipulating large tabular data files. Files of numeric and
 1.4k Jan 9, 2023
1.4k Jan 9, 2023

Desafio proposto pela IGTI em seu bootcamp de Cloud Data Engineer
Desafio Modulo 4 - Cloud Data Engineer Bootcamp - IGTI Objetivos Criar infraestrutura como código Utuilizando um cluster Kubernetes na Azure Ingestão
 4 Jan 23, 2022
4 Jan 23, 2022