182 Repositories
Python policy-gradient Libraries

Simple Python tool that generates a pseudo-random password with numbers, letters, and special characters in accordance with password policy best practices.
Simple Python tool that generates a pseudo-random password with numbers, letters, and special characters in accordance with password policy best practices.
 7 Mar 25, 2022
7 Mar 25, 2022

Gradient Step Denoiser for convergent Plug-and-Play
Source code for the paper "Gradient Step Denoiser for convergent Plug-and-Play"
 11 Sep 17, 2022
11 Sep 17, 2022
Training vision models with full-batch gradient descent and regularization
Stochastic Training is Not Necessary for Generalization -- Training competitive vision models without stochasticity This repository implements trainin
 32 Jan 6, 2023
32 Jan 6, 2023

Official Implementation of 'UPDeT: Universal Multi-agent Reinforcement Learning via Policy Decoupling with Transformers' ICLR 2021(spotlight)
UPDeT Official Implementation of UPDeT: Universal Multi-agent Reinforcement Learning via Policy Decoupling with Transformers (ICLR 2021 spotlight) The
 96 Dec 22, 2022
96 Dec 22, 2022
Wonk is a tool for combining a set of AWS policy files into smaller compiled policy sets.
Wonk is a tool for combining a set of AWS policy files into smaller compiled policy sets.
 140 Dec 16, 2022
140 Dec 16, 2022

Pytorch implementation of convolutional neural network visualization techniques
Convolutional Neural Network Visualizations This repository contains a number of convolutional neural network visualization techniques implemented in
 7k Jan 3, 2023
7k Jan 3, 2023
Tutorial for surrogate gradient learning in spiking neural networks
SpyTorch A tutorial on surrogate gradient learning in spiking neural networks Version: 0.4 This repository contains tutorial files to get you started
 203 Nov 28, 2022
203 Nov 28, 2022
A PyTorch implementation of Learning to learn by gradient descent by gradient descent
Intro PyTorch implementation of Learning to learn by gradient descent by gradient descent. Run python main.py TODO Initial implementation Toy data LST
 300 Dec 11, 2022
300 Dec 11, 2022

ppo_pytorch_cpp - an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch
PPO Pytorch C++ This is an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch. It uses a simple TestEnvironment t
 59 Dec 9, 2022
59 Dec 9, 2022

Pytorch implementation of Distributed Proximal Policy Optimization: https://arxiv.org/abs/1707.02286
Pytorch-DPPO Pytorch implementation of Distributed Proximal Policy Optimization: https://arxiv.org/abs/1707.02286 Using PPO with clip loss (from https
 163 Dec 26, 2022
163 Dec 26, 2022
A PyTorch implementation of Learning to learn by gradient descent by gradient descent
Intro PyTorch implementation of Learning to learn by gradient descent by gradient descent. Run python main.py TODO Initial implementation Toy data LST
300 Dec 11, 2022
Implementation of algorithms for continuous control (DDPG and NAF).
DEPRECATION This repository is deprecated and is no longer maintaned. Please see a more recent implementation of RL for continuous control at jax-sac.
288 Dec 31, 2022

Demonstration that AWS IAM policy evaluation docs are incorrect
The flowchart from the AWS IAM policy evaluation documentation page, as of 2021-09-12, and dating back to at least 2018-12-27, is the following: The f
 15 Oct 21, 2022
15 Oct 21, 2022

PPO is a very popular Reinforcement Learning algorithm at present.
PPO is a very popular Reinforcement Learning algorithm at present. OpenAI takes PPO as the current baseline algorithm. We use the PPO algorithm to train a policy to give the best action in any situation.
 11 Aug 23, 2021
11 Aug 23, 2021

Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
 105 Jan 3, 2023
105 Jan 3, 2023
Code for EMNLP 2021 main conference paper "Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification"
Text-AutoAugment (TAA) This repository contains the code for our paper Text AutoAugment: Learning Compositional Augmentation Policy for Text Classific
105 Jan 3, 2023
An efficient framework for reinforcement learning.
rl: An efficient framework for reinforcement learning Requirements Introduction PPO Test Requirements name version Python =3.7 numpy =1.19 torch =1
 16 Nov 30, 2022
16 Nov 30, 2022
Pytorch implementation of Distributed Proximal Policy Optimization
Pytorch-DPPO Pytorch implementation of Distributed Proximal Policy Optimization: https://arxiv.org/abs/1707.02286 Using PPO with clip loss (from https
164 Jan 5, 2023

PyTorch implementation of Advantage Actor Critic (A2C), Proximal Policy Optimization (PPO), Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation (ACKTR) and Generative Adversarial Imitation Learning (GAIL).
pytorch-a2c-ppo-acktr Update (April 12th, 2021) PPO is great, but Soft Actor Critic can be better for many continuous control tasks. Please check out
3k Jan 9, 2023
Set the draft security HTTP header Permissions-Policy (previously Feature-Policy) on your Django app.
django-permissions-policy Set the draft security HTTP header Permissions-Policy (previously Feature-Policy) on your Django app. Requirements Python 3.
 76 Nov 30, 2022
76 Nov 30, 2022
Code for the paper "TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks"
TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks This is a Python3 / Pytorch implementation of TadGAN paper. The associated
 92 Dec 3, 2022
92 Dec 3, 2022
Pytorch implementations of popular off-policy multi-agent reinforcement learning algorithms, including QMix, VDN, MADDPG, and MATD3.
Off-Policy Multi-Agent Reinforcement Learning (MARL) Algorithms This repository contains implementations of various off-policy multi-agent reinforceme
 183 Dec 28, 2022
183 Dec 28, 2022
Continuum Learning with GEM: Gradient Episodic Memory
Gradient Episodic Memory for Continual Learning Source code for the paper: @inproceedings{GradientEpisodicMemory, title={Gradient Episodic Memory
 360 Dec 27, 2022
360 Dec 27, 2022

Pytorch Implementation of paper "Noisy Natural Gradient as Variational Inference"
Noisy Natural Gradient as Variational Inference PyTorch implementation of Noisy Natural Gradient as Variational Inference. Requirements Python 3 Pytor
 119 Dec 2, 2022
119 Dec 2, 2022
PyTorch implementation of Trust Region Policy Optimization
PyTorch implementation of TRPO Try my implementation of PPO (aka newer better variant of TRPO), unless you need to you TRPO for some specific reasons.
366 Nov 15, 2022
Proximal Backpropagation - a neural network training algorithm that takes implicit instead of explicit gradient steps
Proximal Backpropagation Proximal Backpropagation (ProxProp) is a neural network training algorithm that takes implicit instead of explicit gradient s
 40 Dec 17, 2022
40 Dec 17, 2022

This is the pytorch implementation of the paper - Axiomatic Attribution for Deep Networks.
Integrated Gradients This is the pytorch implementation of "Axiomatic Attribution for Deep Networks". The original tensorflow version could be found h
 150 Dec 23, 2022
150 Dec 23, 2022
This is an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch
This is an implementation of the proximal policy optimization algorithm for the C++ API of Pytorch. It uses a simple TestEnvironment to test the algorithm
59 Dec 9, 2022

Bonsai: Gradient Boosted Trees + Bayesian Optimization
Bonsai is a wrapper for the XGBoost and Catboost model training pipelines that leverages Bayesian optimization for computationally efficient hyperparameter tuning.
 24 Oct 27, 2022
24 Oct 27, 2022

Official implementation of paper Gradient Matching for Domain Generalization
Gradient Matching for Domain Generalisation This is the official PyTorch implementation of Gradient Matching for Domain Generalisation. In our paper,
 94 Dec 23, 2022
94 Dec 23, 2022
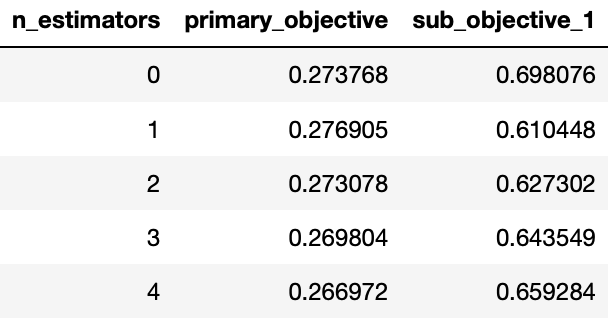
MooGBT is a library for Multi-objective optimization in Gradient Boosted Trees.
MooGBT is a library for Multi-objective optimization in Gradient Boosted Trees. MooGBT optimizes for multiple objectives by defining constraints on sub-objective(s) along with a primary objective. The constraints are defined as upper bounds on sub-objective loss function. MooGBT uses a Augmented Lagrangian(AL) based constrained optimization framework with Gradient Boosted Trees, to optimize for multiple objectives.
 66 Dec 6, 2022
66 Dec 6, 2022
Implementation of Learning Gradient Fields for Molecular Conformation Generation (ICML 2021).
[PDF] | [Slides] The official implementation of Learning Gradient Fields for Molecular Conformation Generation (ICML 2021 Long talk) Installation Inst
 117 Dec 9, 2022
117 Dec 9, 2022
Custom TensorFlow2 implementations of forward and backward computation of soft-DTW algorithm in batch mode.
Batch Soft-DTW(Dynamic Time Warping) in TensorFlow2 including forward and backward computation Custom TensorFlow2 implementations of forward and backw
 19 Aug 30, 2022
19 Aug 30, 2022
ML Optimizers from scratch using JAX
Toy implementations of some popular ML optimizers using Python/JAX
 38 Jul 29, 2022
38 Jul 29, 2022
On the model-based stochastic value gradient for continuous reinforcement learning
On the model-based stochastic value gradient for continuous reinforcement learning This repository is by Brandon Amos, Samuel Stanton, Denis Yarats, a
46 Dec 15, 2022
Probabilistic Gradient Boosting Machines
PGBM Probabilistic Gradient Boosting Machines (PGBM) is a probabilistic gradient boosting framework in Python based on PyTorch/Numba, developed by Air
 112 Dec 28, 2022
112 Dec 28, 2022

The official implementation of You Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient.
You Only Compress Once: Towards Effective and Elastic BERT Compression via Exploit-Explore Stochastic Nature Gradient (paper) @misc{zhang2021compress,
 46 Dec 7, 2022
46 Dec 7, 2022
Code release to accompany paper "Geometry-Aware Gradient Algorithms for Neural Architecture Search."
Geometry-Aware Gradient Algorithms for Neural Architecture Search This repository contains the code required to run the experiments for the DARTS sear
 18 May 27, 2022
18 May 27, 2022
TensorFlow Decision Forests (TF-DF) is a collection of state-of-the-art algorithms for the training, serving and interpretation of Decision Forest models.
TensorFlow Decision Forests (TF-DF) is a collection of state-of-the-art algorithms for the training, serving and interpretation of Decision Forest models. The library is a collection of Keras models and supports classification, regression and ranking. TF-DF is a TensorFlow wrapper around the Yggdrasil Decision Forests C++ libraries. Models trained with TF-DF are compatible with Yggdrasil Decision Forests' models, and vice versa.
 538 Jan 1, 2023
538 Jan 1, 2023
[ECCV 2020] Gradient-Induced Co-Saliency Detection
Gradient-Induced Co-Saliency Detection Zhao Zhang*, Wenda Jin*, Jun Xu, Ming-Ming Cheng ⭐ Project Home » The official repo of the ECCV 2020 paper Grad
 35 Nov 25, 2022
35 Nov 25, 2022

Paddle-RLBooks is a reinforcement learning code study guide based on pure PaddlePaddle.
Paddle-RLBooks Welcome to Paddle-RLBooks which is a reinforcement learning code study guide based on pure PaddlePaddle. 欢迎来到Paddle-RLBooks,该仓库主要是针对强化学
 117 Dec 12, 2022
117 Dec 12, 2022

A collection of various RL algorithms like policy gradients, DQN and PPO. The goal of this repo will be to make it a go-to resource for learning about RL. How to visualize, debug and solve RL problems. I've additionally included playground.py for learning more about OpenAI gym, etc.
Reinforcement Learning (PyTorch) 🤖 + 🍰 = ❤️ This repo will contain PyTorch implementation of various fundamental RL algorithms. It's aimed at making
 123 Dec 23, 2022
123 Dec 23, 2022
A Closer Look at Invalid Action Masking in Policy Gradient Algorithms
A Closer Look at Invalid Action Masking in Policy Gradient Algorithms This repo contains the source code to reproduce the results in the paper A Close
 73 Dec 24, 2022
73 Dec 24, 2022
Text Generation by Learning from Demonstrations
Text Generation by Learning from Demonstrations The README was last updated on March 7, 2021. The repo is based on fairseq (v0.9.?). Paper arXiv Prere
 38 Oct 21, 2022
38 Oct 21, 2022
![[CVPRW 21]](https://github.com/VITA-Group/BNN_NoBN/raw/main/Figs/res.png)
[CVPRW 21] "BNN - BN = ? Training Binary Neural Networks without Batch Normalization", Tianlong Chen, Zhenyu Zhang, Xu Ouyang, Zechun Liu, Zhiqiang Shen, Zhangyang Wang
BNN - BN = ? Training Binary Neural Networks without Batch Normalization Codes for this paper BNN - BN = ? Training Binary Neural Networks without Bat
 40 Dec 30, 2022
40 Dec 30, 2022

Validate all your Customer IAM Policies against AWS Access Analyzer - Policy Validation
✅ Access Analyzer - Batch Policy Validator This script will analyze using AWS Access Analyzer - Policy Validation all your account customer managed IA
 41 Dec 12, 2022
41 Dec 12, 2022
A Pytorch implementation of the multi agent deep deterministic policy gradients (MADDPG) algorithm
Multi-Agent-Deep-Deterministic-Policy-Gradients A Pytorch implementation of the multi agent deep deterministic policy gradients(MADDPG) algorithm This
 159 Dec 28, 2022
159 Dec 28, 2022
Policy and data administration, distribution, and real-time updates on top of Open Policy Agent
⚡ OPAL ⚡ Open Policy Administration Layer OPAL is an administration layer for Open Policy Agent (OPA), detecting changes to both policy and policy dat
 8 Dec 7, 2022
8 Dec 7, 2022
PGPortfolio: Policy Gradient Portfolio, the source code of "A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem"(https://arxiv.org/pdf/1706.10059.pdf).
This is the original implementation of our paper, A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem (arXiv:1706.1
 1.5k Dec 29, 2022
1.5k Dec 29, 2022
A resource for learning about deep learning techniques from regression to LSTM and Reinforcement Learning using financial data and the fitness functions of algorithmic trading
A tour through tensorflow with financial data I present several models ranging in complexity from simple regression to LSTM and policy networks. The s
 195 Dec 7, 2022
195 Dec 7, 2022

This project provides a stock market environment using OpenGym with Deep Q-learning and Policy Gradient.
Stock Trading Market OpenAI Gym Environment with Deep Reinforcement Learning using Keras Overview This project provides a general environment for stoc
 769 Dec 25, 2022
769 Dec 25, 2022
Scalable, event-driven, deep-learning-friendly backtesting library
...Minimizing the mean square error on future experience. - Richard S. Sutton BTGym Scalable event-driven RL-friendly backtesting library. Build on
 922 Dec 27, 2022
922 Dec 27, 2022

An introduction of Markov decision process (MDP) and two algorithms that solve MDPs (value iteration, policy iteration) along with their Python implementations.
Markov Decision Process A Markov decision process (MDP), by definition, is a sequential decision problem for a fully observable, stochastic environmen
 31 Dec 30, 2022
31 Dec 30, 2022
Code for: Gradient-based Hierarchical Clustering using Continuous Representations of Trees in Hyperbolic Space. Nicholas Monath, Manzil Zaheer, Daniel Silva, Andrew McCallum, Amr Ahmed. KDD 2019.
gHHC Code for: Gradient-based Hierarchical Clustering using Continuous Representations of Trees in Hyperbolic Space. Nicholas Monath, Manzil Zaheer, D
 35 Nov 16, 2022
35 Nov 16, 2022

Official implementation of "GS-WGAN: A Gradient-Sanitized Approach for Learning Differentially Private Generators" (NeurIPS 2020)
GS-WGAN This repository contains the implementation for GS-WGAN: A Gradient-Sanitized Approach for Learning Differentially Private Generators (NeurIPS
 46 Nov 9, 2022
46 Nov 9, 2022

A mini library for Policy Gradients with Parameter-based Exploration, with reference implementation of the ClipUp optimizer from NNAISENSE.
PGPElib A mini library for Policy Gradients with Parameter-based Exploration [1] and friends. This library serves as a clean re-implementation of the
 56 Jan 1, 2023
56 Jan 1, 2023

This is the source code of RPG (Reward-Randomized Policy Gradient)
RPG (Reward-Randomized Policy Gradient) Zhenggang Tang*, Chao Yu*, Boyuan Chen, Huazhe Xu, Xiaolong Wang, Fei Fang, Simon Shaolei Du, Yu Wang, Yi Wu (
 40 Nov 25, 2022
40 Nov 25, 2022

Automatically compile an AWS Service Control Policy that ONLY allows AWS services that are compliant with your preferred compliance frameworks.
aws-allowlister Automatically compile an AWS Service Control Policy that ONLY allows AWS services that are compliant with your preferred compliance fr
 189 Dec 8, 2022
189 Dec 8, 2022
🎯 A comprehensive gradient-free optimization framework written in Python
Solid is a Python framework for gradient-free optimization. It contains basic versions of many of the most common optimization algorithms that do not
 565 Dec 26, 2022
565 Dec 26, 2022
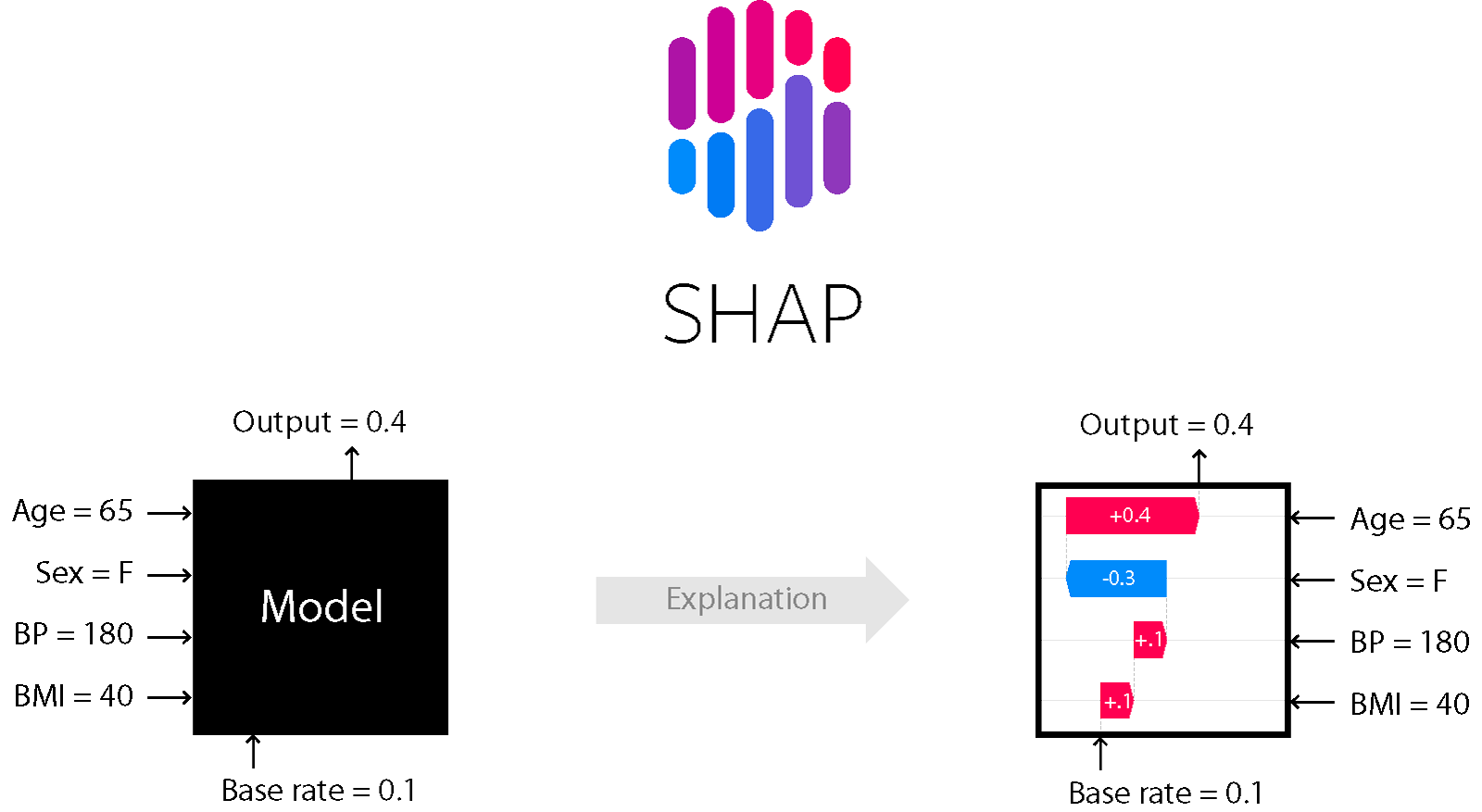
A game theoretic approach to explain the output of any machine learning model.
SHAP (SHapley Additive exPlanations) is a game theoretic approach to explain the output of any machine learning model. It connects optimal credit allo
 18.3k Jan 8, 2023
18.3k Jan 8, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 5, 2023
6.9k Jan 5, 2023
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
 14.5k Jan 7, 2023
14.5k Jan 7, 2023
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
eXtreme Gradient Boosting Community | Documentation | Resources | Contributors | Release Notes XGBoost is an optimized distributed gradient boosting l
 23.6k Jan 3, 2023
23.6k Jan 3, 2023
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
Master status: Development status: Package information: TPOT stands for Tree-based Pipeline Optimization Tool. Consider TPOT your Data Science Assista
 8.9k Jan 9, 2023
8.9k Jan 9, 2023

Implements Gradient Centralization and allows it to use as a Python package in TensorFlow
Gradient Centralization TensorFlow This Python package implements Gradient Centralization in TensorFlow, a simple and effective optimization technique
 101 Nov 1, 2022
101 Nov 1, 2022
DRLib:A concise deep reinforcement learning library, integrating HER and PER for almost off policy RL algos.
DRLib:A concise deep reinforcement learning library, integrating HER and PER for almost off policy RL algos A concise deep reinforcement learning libr
 329 Jan 3, 2023
329 Jan 3, 2023
Storchastic is a PyTorch library for stochastic gradient estimation in Deep Learning
Storchastic is a PyTorch library for stochastic gradient estimation in Deep Learning
 140 Dec 30, 2022
140 Dec 30, 2022
NFNets and Adaptive Gradient Clipping for SGD implemented in PyTorch
PyTorch implementation of Normalizer-Free Networks and SGD - Adaptive Gradient Clipping Paper: https://arxiv.org/abs/2102.06171.pdf Original code: htt
 320 Jan 2, 2023
320 Jan 2, 2023
Keras implementation of Normalizer-Free Networks and SGD - Adaptive Gradient Clipping
Keras implementation of Normalizer-Free Networks and SGD - Adaptive Gradient Clipping
 63 Sep 21, 2022
63 Sep 21, 2022
Fast and Easy Infinite Neural Networks in Python
Neural Tangents ICLR 2020 Video | Paper | Quickstart | Install guide | Reference docs | Release notes Overview Neural Tangents is a high-level neural
 1.9k Jan 9, 2023
1.9k Jan 9, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
5.7k Feb 12, 2021
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
14.5k Jan 8, 2023
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
eXtreme Gradient Boosting Community | Documentation | Resources | Contributors | Release Notes XGBoost is an optimized distributed gradient boosting l
20.6k Feb 13, 2021

Image morphing without reference points by applying warp maps and optimizing over them.
Differentiable Morphing Image morphing without reference points by applying warp maps and optimizing over them. Differentiable Morphing is machine lea
 380 Dec 19, 2022
380 Dec 19, 2022

Modular Deep Reinforcement Learning framework in PyTorch. Companion library of the book "Foundations of Deep Reinforcement Learning".
SLM Lab Modular Deep Reinforcement Learning framework in PyTorch. Documentation: https://slm-lab.gitbook.io/slm-lab/ BeamRider Breakout KungFuMaster M
 1.1k Dec 24, 2022
1.1k Dec 24, 2022
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
14.5k Jan 8, 2023
Machine learning, in numpy
numpy-ml Ever wish you had an inefficient but somewhat legible collection of machine learning algorithms implemented exclusively in NumPy? No? Install
 11.6k Dec 30, 2022
11.6k Dec 30, 2022
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
6.9k Jan 4, 2023
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
Master status: Development status: Package information: TPOT stands for Tree-based Pipeline Optimization Tool. Consider TPOT your Data Science Assista
8.9k Dec 30, 2022
[UNMAINTAINED] Automated machine learning for analytics & production
auto_ml Automated machine learning for production and analytics Installation pip install auto_ml Getting started from auto_ml import Predictor from au
 1.6k Jan 2, 2023
1.6k Jan 2, 2023
Scalable, Portable and Distributed Gradient Boosting (GBDT, GBRT or GBM) Library, for Python, R, Java, Scala, C++ and more. Runs on single machine, Hadoop, Spark, Dask, Flink and DataFlow
eXtreme Gradient Boosting Community | Documentation | Resources | Contributors | Release Notes XGBoost is an optimized distributed gradient boosting l
23.6k Dec 31, 2022
H2O is an Open Source, Distributed, Fast & Scalable Machine Learning Platform: Deep Learning, Gradient Boosting (GBM) & XGBoost, Random Forest, Generalized Linear Modeling (GLM with Elastic Net), K-Means, PCA, Generalized Additive Models (GAM), RuleFit, Support Vector Machine (SVM), Stacked Ensembles, Automatic Machine Learning (AutoML), etc.
H2O H2O is an in-memory platform for distributed, scalable machine learning. H2O uses familiar interfaces like R, Python, Scala, Java, JSON and the Fl
 6.1k Jan 5, 2023
6.1k Jan 5, 2023