243 Repositories
Python scrapy-pipeline Libraries
![[CVPR-2021] UnrealPerson: An adaptive pipeline for costless person re-identification](https://github.com/FlyHighest/UnrealPerson/raw/main/imgs/unrealperson.jpg)
[CVPR-2021] UnrealPerson: An adaptive pipeline for costless person re-identification
UnrealPerson: An Adaptive Pipeline for Costless Person Re-identification In our paper (arxiv), we propose a novel pipeline, UnrealPerson, that decreas
 70 Oct 10, 2022
70 Oct 10, 2022

This is a repository for the Duke University Cloud Computing course project on Serveless Data Engineering Pipeline. For this project, I recreated the below pipeline.
AWS Data Engineering Pipeline This is a repository for the Duke University Cloud Computing course project on Serverless Data Engineering Pipeline. For
 15 Jul 28, 2021
15 Jul 28, 2021
Focus on Algorithm Design, Not on Data Wrangling
The dataTap Python library is the primary interface for using dataTap's rich data management tools. Create datasets, stream annotations, and analyze model performance all with one library.
 37 Nov 25, 2022
37 Nov 25, 2022

Educational project on how to build an ETL (Extract, Transform, Load) data pipeline, orchestrated with Airflow.
ETL Pipeline with Airflow, Spark, s3, MongoDB and Amazon Redshift
 214 Jan 2, 2023
214 Jan 2, 2023
Socorro is the Mozilla crash ingestion pipeline. It accepts and processes Breakpad-style crash reports. It provides analysis tools.
Socorro Socorro is a Mozilla-centric ingestion pipeline and analysis tools for crash reports using the Breakpad libraries. Support This is a Mozilla-s
 552 Dec 19, 2022
552 Dec 19, 2022
![git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]](https://github.com/happycaoyue/Pseudo-ISP/raw/main/img/3.png)
git《Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser》(2021) GitHub: [fig5]
Pseudo-ISP: Learning Pseudo In-camera Signal Processing Pipeline from A Color Image Denoiser Abstract The success of deep denoisers on real-world colo
 51 Nov 22, 2022
51 Nov 22, 2022

Automated Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning
The mljar-supervised is an Automated Machine Learning Python package that works with tabular data. I
 2.4k Jan 2, 2023
2.4k Jan 2, 2023
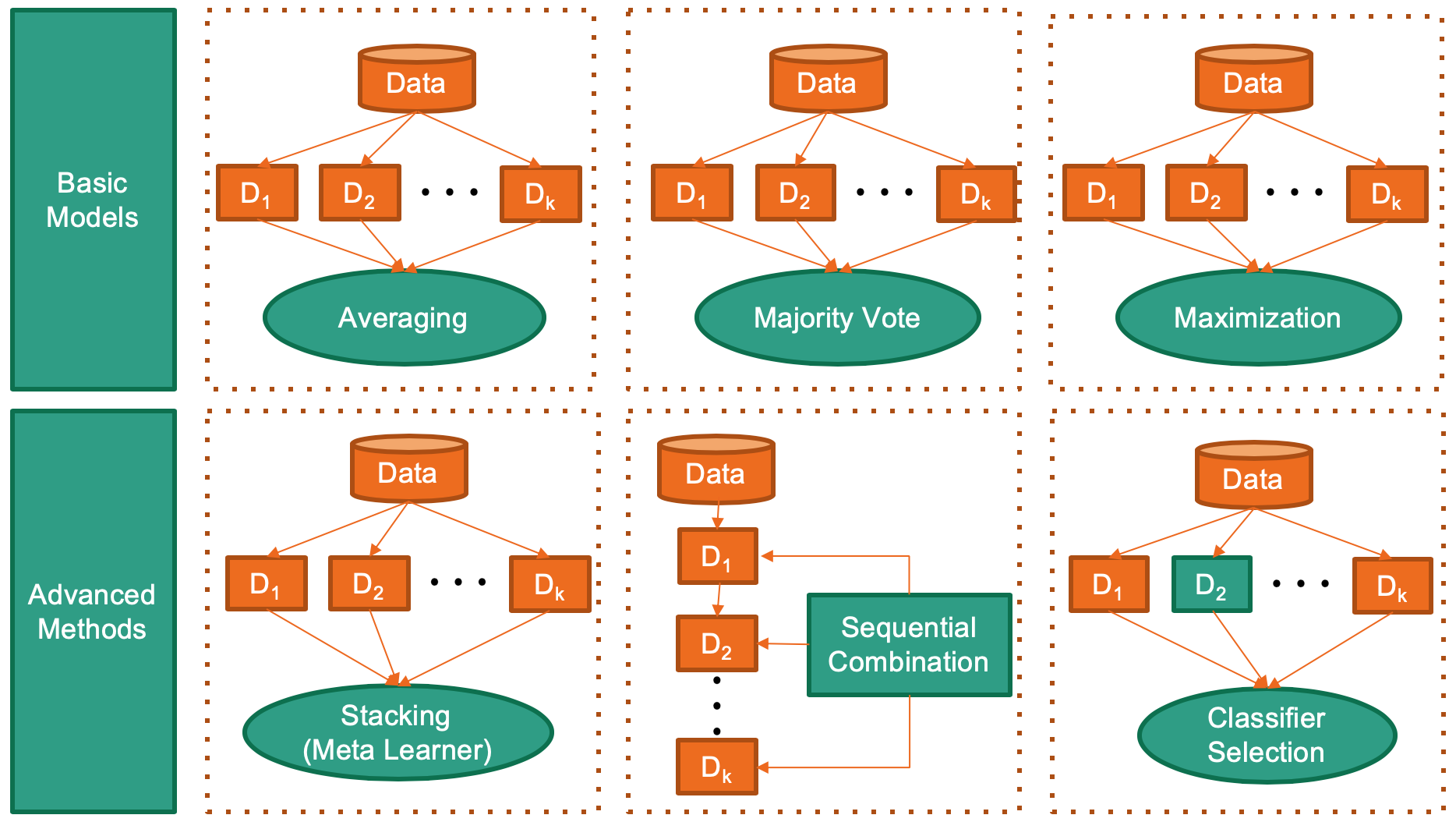
(AAAI' 20) A Python Toolbox for Machine Learning Model Combination
combo: A Python Toolbox for Machine Learning Model Combination Deployment & Documentation & Stats Build Status & Coverage & Maintainability & License
 606 Dec 21, 2022
606 Dec 21, 2022
PyTorch extensions for fast R&D prototyping and Kaggle farming
Pytorch-toolbelt A pytorch-toolbelt is a Python library with a set of bells and whistles for PyTorch for fast R&D prototyping and Kaggle farming: What
 1.3k Jan 5, 2023
1.3k Jan 5, 2023

A GPU-accelerated library containing highly optimized building blocks and an execution engine for data processing to accelerate deep learning training and inference applications.
NVIDIA DALI The NVIDIA Data Loading Library (DALI) is a library for data loading and pre-processing to accelerate deep learning applications. It provi
 4.2k Jan 8, 2023
4.2k Jan 8, 2023
We have implemented shaDow-GNN as a general and powerful pipeline for graph representation learning. For more details, please find our paper titled Deep Graph Neural Networks with Shallow Subgraph Samplers, available on arXiv (https//arxiv.org/abs/2012.01380).
Deep GNN, Shallow Sampling Hanqing Zeng, Muhan Zhang, Yinglong Xia, Ajitesh Srivastava, Andrey Malevich, Rajgopal Kannan, Viktor Prasanna, Long Jin, R
 117 Dec 20, 2022
117 Dec 20, 2022
An expandable and scalable OCR pipeline
Overview Nidaba is the central controller for the entire OGL OCR pipeline. It oversees and automates the process of converting raw images into citable
 81 Jan 4, 2023
81 Jan 4, 2023

This is a c++ project deploying a deep scene text reading pipeline with tensorflow. It reads text from natural scene images. It uses frozen tensorflow graphs. The detector detect scene text locations. The recognizer reads word from each detected bounding box.
DeepSceneTextReader This is a c++ project deploying a deep scene text reading pipeline. It reads text from natural scene images. Prerequsites The proj
 49 Sep 10, 2022
49 Sep 10, 2022

End-to-end pipeline for real-time scene text detection and recognition.
Real-time-Scene-Text-Detection-and-Recognition-System End-to-end pipeline for real-time scene text detection and recognition. The detection model use
 89 Aug 4, 2022
89 Aug 4, 2022
Toy example of an applied ML pipeline for me to experiment with MLOps tools.
Toy Machine Learning Pipeline Table of Contents About Getting Started ML task description and evaluation procedure Dataset description Repository stru
 190 Dec 21, 2022
190 Dec 21, 2022
BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflows even for datasets that do not fit into memory.
BatchFlow BatchFlow helps you conveniently work with random or sequential batches of your data and define data processing and machine learning workflo
 185 Dec 20, 2022
185 Dec 20, 2022
Easy pipelines for pandas DataFrames.
pdpipe ˨ Easy pipelines for pandas DataFrames (learn how!). Website: https://pdpipe.github.io/pdpipe/ Documentation: https://pdpipe.github.io/pdpipe/d
 694 Jan 5, 2023
694 Jan 5, 2023
MLBox is a powerful Automated Machine Learning python library.
MLBox is a powerful Automated Machine Learning python library. It provides the following features: Fast reading and distributed data preprocessing/cle
 1.4k Jan 6, 2023
1.4k Jan 6, 2023
DaCy: The State of the Art Danish NLP pipeline using SpaCy
DaCy: A SpaCy NLP Pipeline for Danish DaCy is a Danish preprocessing pipeline trained in SpaCy. At the time of writing it has achieved State-of-the-Ar
 71 Jan 6, 2023
71 Jan 6, 2023
feapder 是一款简单、快速、轻量级的爬虫框架。以开发快速、抓取快速、使用简单、功能强大为宗旨。支持分布式爬虫、批次爬虫、多模板爬虫,以及完善的爬虫报警机制。
feapder 是一款简单、快速、轻量级的爬虫框架。起名源于 fast、easy、air、pro、spider的缩写,以开发快速、抓取快速、使用简单、功能强大为宗旨,历时4年倾心打造。支持轻量爬虫、分布式爬虫、批次爬虫、爬虫集成,以及完善的爬虫报警机制。 之
 1.4k Dec 29, 2022
1.4k Dec 29, 2022
Data intensive science for everyone.
The latest information about Galaxy can be found on the Galaxy Community Hub. Community support is available at Galaxy Help. Galaxy Quickstart Galaxy
 1k Jan 8, 2023
1k Jan 8, 2023
Backend, modern REST API for obtaining match and odds data crawled from multiple sites. Using FastAPI, MongoDB as database, Motor as async MongoDB client, Scrapy as crawler and Docker.
Introduction Apiestas is a project composed of a backend powered by the awesome framework FastAPI and a crawler powered by Scrapy. This project has fo
 54 Dec 13, 2022
54 Dec 13, 2022
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
 2.1k Feb 13, 2021
2.1k Feb 13, 2021
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
 831 Feb 17, 2021
831 Feb 17, 2021
🛸 Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy
spacy-transformers: Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy This package provides spaCy components and architectures to use tr
 903 Feb 17, 2021
903 Feb 17, 2021
✨Fast Coreference Resolution in spaCy with Neural Networks
✨ NeuralCoref 4.0: Coreference Resolution in spaCy with Neural Networks. NeuralCoref is a pipeline extension for spaCy 2.1+ which annotates and resolv
 2.2k Feb 18, 2021
2.2k Feb 18, 2021
An audio digital processing toolbox based on a workflow/pipeline principle
AudioTK Audio ToolKit is a set of audio filters. It helps assembling workflows for specific audio processing workloads. The audio workflow is split in
 238 Oct 18, 2022
238 Oct 18, 2022
PipeLayer is a lightweight Python pipeline framework
PipeLayer is a lightweight Python pipeline framework. Define a series of steps, and chain them together to create modular applications
 64 Jul 21, 2022
64 Jul 21, 2022
Text preprocessing, representation and visualization from zero to hero.
Text preprocessing, representation and visualization from zero to hero. From zero to hero • Installation • Getting Started • Examples • API • FAQ • Co
2.7k Jan 8, 2023
A full spaCy pipeline and models for scientific/biomedical documents.
This repository contains custom pipes and models related to using spaCy for scientific documents. In particular, there is a custom tokenizer that adds
1.3k Jan 3, 2023
🛸 Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy
spacy-transformers: Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy This package provides spaCy components and architectures to use tr
1.2k Jan 8, 2023
✨Fast Coreference Resolution in spaCy with Neural Networks
✨ NeuralCoref 4.0: Coreference Resolution in spaCy with Neural Networks. NeuralCoref is a pipeline extension for spaCy 2.1+ which annotates and resolv
2.6k Jan 4, 2023
:mag: Transformers at scale for question answering & neural search. Using NLP via a modular Retriever-Reader-Pipeline. Supporting DPR, Elasticsearch, HuggingFace's Modelhub...
Haystack is an end-to-end framework for Question Answering & Neural search that enables you to ... ... ask questions in natural language and find gran
 6.4k Jan 9, 2023
6.4k Jan 9, 2023
MongoDB data stream pipeline tools by YouGov (adopted from MongoDB)
mongo-connector The mongo-connector project originated as a MongoDB mongo-labs project and is now community-maintained under the custody of YouGov, Pl
 1.9k Jan 4, 2023
1.9k Jan 4, 2023
Pipeline is an asset packaging library for Django.
Pipeline Pipeline is an asset packaging library for Django, providing both CSS and JavaScript concatenation and compression, built-in JavaScript templ
 1.4k Jan 3, 2023
1.4k Jan 3, 2023
Distributed Crawler Management Framework Based on Scrapy, Scrapyd, Django and Vue.js
Gerapy Distributed Crawler Management Framework Based on Scrapy, Scrapyd, Scrapyd-Client, Scrapyd-API, Django and Vue.js. Documentation Documentation
 2.9k Jan 3, 2023
2.9k Jan 3, 2023
Scrapy, a fast high-level web crawling & scraping framework for Python.
Scrapy Overview Scrapy is a fast high-level web crawling and web scraping framework, used to crawl websites and extract structured data from their pag
 45.5k Jan 7, 2023
45.5k Jan 7, 2023
Soda SQL Data testing, monitoring and profiling for SQL accessible data.
Soda SQL Data testing, monitoring and profiling for SQL accessible data. What does Soda SQL do? Soda SQL allows you to Stop your pipeline when bad dat
 51 Jan 1, 2023
51 Jan 1, 2023
Pipeline is an asset packaging library for Django.
Pipeline Pipeline is an asset packaging library for Django, providing both CSS and JavaScript concatenation and compression, built-in JavaScript templ
1.4k Dec 26, 2022

Automates Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning :rocket:
MLJAR Automated Machine Learning Documentation: https://supervised.mljar.com/ Source Code: https://github.com/mljar/mljar-supervised Table of Contents
2.4k Dec 31, 2022
A Sklearn-like Framework for Hyperparameter Tuning and AutoML in Deep Learning projects. Finally have the right abstractions and design patterns to properly do AutoML. Let your pipeline steps have hyperparameter spaces. Enable checkpoints to cut duplicate calculations. Go from research to production environment easily.
Neuraxle Pipelines Code Machine Learning Pipelines - The Right Way. Neuraxle is a Machine Learning (ML) library for building machine learning pipeline
 555 Dec 24, 2022
555 Dec 24, 2022
Lightweight, Python library for fast and reproducible experimentation :microscope:
Steppy What is Steppy? Steppy is a lightweight, open-source, Python 3 library for fast and reproducible experimentation. Steppy lets data scientist fo
 134 Jul 10, 2022
134 Jul 10, 2022
Visual scraping for Scrapy
Portia Portia is a tool that allows you to visually scrape websites without any programming knowledge required. With Portia you can annotate a web pag
 8.7k Jan 5, 2023
8.7k Jan 5, 2023