275 Repositories
Python pipeline-tests Libraries

Accelerated NLP pipelines for fast inference on CPU and GPU. Built with Transformers, Optimum and ONNX Runtime.
Optimum Transformers Accelerated NLP pipelines for fast inference 🚀 on CPU and GPU. Built with 🤗 Transformers, Optimum and ONNX runtime. Installatio
 115 Dec 16, 2022
115 Dec 16, 2022

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022

Easy Parallel Library (EPL) is a general and efficient deep learning framework for distributed model training.
English | 简体中文 Easy Parallel Library Overview Easy Parallel Library (EPL) is a general and efficient library for distributed model training. Usability
 185 Dec 21, 2022
185 Dec 21, 2022
![[Arxiv preprint] Causality-inspired Single-source Domain Generalization for Medical Image Segmentation (code&data-processing pipeline)](https://github.com/cheng-01037/Causality-Medical-Image-Domain-Generalization/raw/main/intro.png)
[Arxiv preprint] Causality-inspired Single-source Domain Generalization for Medical Image Segmentation (code&data-processing pipeline)
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation Arxiv preprint Repository under construction. Might still be bug
 31 Dec 27, 2022
31 Dec 27, 2022
torchlm is aims to build a high level pipeline for face landmarks detection, it supports training, evaluating, exporting, inference(Python/C++) and 100+ data augmentations
💎A high level pipeline for face landmarks detection, supports training, evaluating, exporting, inference and 100+ data augmentations, compatible with torchvision and albumentations, can easily install with pip.
 142 Dec 25, 2022
142 Dec 25, 2022
Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogramas anuais com spark, em pyspark e SQL!
Olá! Esse é o meu primeiro repo tratando de fim a fim, uma pipeline de dados abertos do governo brasileiro relacionado a compras de contrato e cronogr
 10 Apr 4, 2022
10 Apr 4, 2022

Open-source data observability for modern data teams
Use cases Monitor your data warehouse in minutes: Data anomalies monitoring as dbt tests Data lineage made simple, reliable, and automated dbt operati
 889 Jan 1, 2023
889 Jan 1, 2023
HASOKI DDOS TOOL- powerful DDoS toolkit for penetration tests
DDoS Attack Panel includes CloudFlare Bypass (UAM, CAPTCHA, GS ,VS ,BFM, etc..) This is open source code. I am not responsible if you use it for malic
 1 Dec 2, 2022
1 Dec 2, 2022

A pytest plugin to run an ansible collection's unit tests with pytest.
pytest-ansible-units An experimental pytest plugin to run an ansible collection's unit tests with pytest. Description pytest-ansible-units is a pytest
 9 Dec 9, 2022
9 Dec 9, 2022

This is the first released system towards complex meters` detection and recognition, which is implemented by computer vision techniques.
A three-stage detection and recognition pipeline of complex meters in wild This is the first released system towards detection and recognition of comp
 19 Nov 28, 2022
19 Nov 28, 2022

Vad-sli-asr - A Python scripts for a speech processing pipeline with Voice Activity Detection (VAD)
VAD-SLI-ASR Python scripts for a speech processing pipeline with Voice Activity
 14 Dec 9, 2022
14 Dec 9, 2022
Udacity-api-reporting-pipeline - Udacity api reporting pipeline
udacity-api-reporting-pipeline In this exercise, you'll use portions of each of
 1 Feb 15, 2022
1 Feb 15, 2022
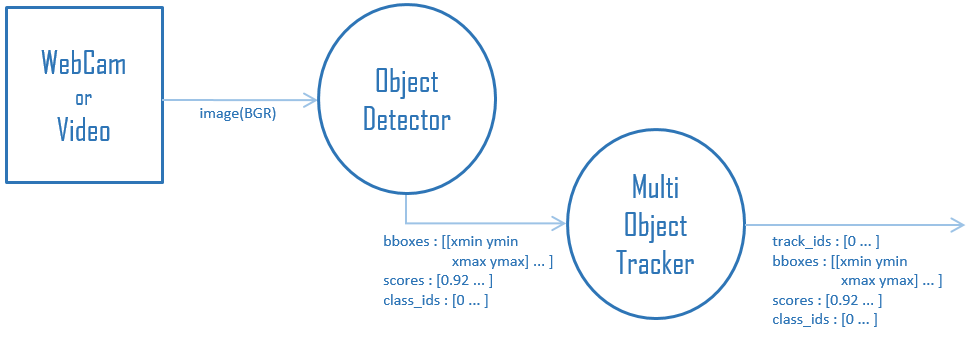
MOT-Tracking-by-Detection-Pipeline - For Tracking-by-Detection format MOT (Multi Object Tracking), is it a framework that separates Detection and Tracking processes?
MOT-Tracking-by-Detection-Pipeline Tracking-by-Detection形式のMOT(Multi Object Trac
 41 Nov 23, 2022
41 Nov 23, 2022
Bugbane - Application security tools for CI/CD pipeline
BugBane Набор утилит для аудита безопасности приложений. Основные принципы и осо
 20 Dec 9, 2022
20 Dec 9, 2022
fair-test is a library to build and deploy FAIR metrics tests APIs supporting the specifications used by the FAIRMetrics working group.
☑️ FAIR test fair-test is a library to build and deploy FAIR metrics tests APIs supporting the specifications used by the FAIRMetrics working group. I
 6 Oct 30, 2022
6 Oct 30, 2022

Benchmarking Pipeline for Prediction of Protein-Protein Interactions
B4PPI Benchmarking Pipeline for the Prediction of Protein-Protein Interactions How this benchmarking pipeline has been built, and how to use it, is de
 4 Jun 27, 2022
4 Jun 27, 2022

MLOps pipeline project using Amazon SageMaker Pipelines
This project shows steps to build an end to end MLOps architecture that covers data prep, model training, realtime and batch inference, build model registry, track lineage of artifacts and model drift detection. It utilizes SageMaker Pipelines that offers machine learning (ML) to orchestrate SageMaker jobs and author reproducible ML pipelines.
 3 Sep 16, 2022
3 Sep 16, 2022
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify.
An ETL Pipeline of a large data set from a fictitious music streaming service named Sparkify. The ETL process flows from AWS's S3 into staging tables in AWS Redshift.
 1 Feb 11, 2022
1 Feb 11, 2022

Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
Using Data Science with Machine Learning techniques (ETL pipeline and ML pipeline) to classify received messages after disasters.
 1 Feb 11, 2022
1 Feb 11, 2022

Detecting Human-Object Interactions with Object-Guided Cross-Modal Calibrated Semantics
[AAAI2022] Detecting Human-Object Interactions with Object-Guided Cross-Modal Calibrated Semantics Overall pipeline of OCN. Paper Link: [arXiv] [AAAI
 13 Nov 21, 2022
13 Nov 21, 2022
A scrapy pipeline that provides an easy way to store files and images using various folder structures.
scrapy-folder-tree This is a scrapy pipeline that provides an easy way to store files and images using various folder structures. Supported folder str
 7 Oct 23, 2022
7 Oct 23, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
 32 Dec 29, 2022
32 Dec 29, 2022
Pytest modified env
Pytest plugin to fail a test if it leaves modified os.environ afterwards.
 7 Sep 11, 2022
7 Sep 11, 2022
FAIR Enough Metrics is an API for various FAIR Metrics Tests, written in python
☑️ FAIR Enough metrics for research FAIR Enough Metrics is an API for various FAIR Metrics Tests, written in python, conforming to the specifications
3 Jul 6, 2022

Hyperparameters tuning and features selection are two common steps in every machine learning pipeline.
shap-hypetune A python package for simultaneous Hyperparameters Tuning and Features Selection for Gradient Boosting Models. Overview Hyperparameters t
 422 Jan 8, 2023
422 Jan 8, 2023
Compute execution plan: A DAG representation of work that you want to get done. Individual nodes of the DAG could be simple python or shell tasks or complex deeply nested parallel branches or embedded DAGs themselves.
Hello from magnus Magnus provides four capabilities for data teams: Compute execution plan: A DAG representation of work that you want to get done. In
 12 Feb 8, 2022
12 Feb 8, 2022
E2EDNA2 - An automated pipeline for simulation of DNA aptamers complexed with small molecules and short peptides
E2EDNA2 - An automated pipeline for simulation of DNA aptamers complexed with small molecules and short peptides
 11 Nov 8, 2022
11 Nov 8, 2022

Segmentation Training Pipeline
Segmentation Training Pipeline This package is a part of Musket ML framework. Reasons to use Segmentation Pipeline Segmentation Pipeline was developed
 52 Dec 12, 2022
52 Dec 12, 2022
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline
Built a deep neural network (DNN) that functions as an end-to-end machine translation pipeline. The pipeline accepts english text as input and returns the French translation.
 1 Jan 24, 2022
1 Jan 24, 2022
Ingestinator is my personal VFX pipeline tool for ingesting folders containing frame sequences that have been pulled and downloaded to a local folder
Ingestinator Ingestinator is my personal VFX pipeline tool for ingesting folders containing frame sequences that have been pulled and downloaded to a
 2 Nov 18, 2022
2 Nov 18, 2022

This is an open solution to the Home Credit Default Risk challenge 🏡
Home Credit Default Risk: Open Solution This is an open solution to the Home Credit Default Risk challenge 🏡 . More competitions 🎇 Check collection
 427 Dec 27, 2022
427 Dec 27, 2022

Google AI Open Images - Object Detection Track: Open Solution
Google AI Open Images - Object Detection Track: Open Solution This is an open solution to the Google AI Open Images - Object Detection Track 😃 More c
46 Jun 22, 2022

TGS Salt Identification Challenge
TGS Salt Identification Challenge This is an open solution to the TGS Salt Identification Challenge. Note Unfortunately, we can no longer provide supp
 123 Nov 4, 2022
123 Nov 4, 2022

Open solution to the Toxic Comment Classification Challenge
Starter code: Kaggle Toxic Comment Classification Challenge More competitions 🎇 Check collection of public projects 🎁 , where you can find multiple
153 Jun 22, 2022
TweebankNLP - Pre-trained Tweet NLP Pipeline (NER, tokenization, lemmatization, POS tagging, dependency parsing) + Models + Tweebank-NER
TweebankNLP This repo contains the new Tweebank-NER dataset and Twitter-Stanza p
 84 Dec 20, 2022
84 Dec 20, 2022

PrimaryBid - Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift
Transform application Lifecycle Data and Design and ETL pipeline architecture for ingesting data from multiple sources to redshift This project is composed of two parts: Part1 and Part2
 1 Jan 19, 2022
1 Jan 19, 2022

Pipeline for employing a Lightweight deep learning models for LOW-power systems
PL-LOW A high-performance deep learning model lightweight pipeline that gradually lightens deep neural networks in order to utilize high-performance d
 9 Aug 13, 2022
9 Aug 13, 2022

Visual Python and C++ nanosecond profiler, logger, tests enabler
Look into Palanteer and get an omniscient view of your program Palanteer is a set of lean and efficient tools to improve the quality of software, for
 1.9k Dec 26, 2022
1.9k Dec 26, 2022

Words-per-minute - A terminal app written in python utilizing the curses module that tests the user's ability to type
words-per-minute A terminal app written in python utilizing the curses module th
 1 Jan 14, 2022
1 Jan 14, 2022

Implement backup and recovery with AWS Backup across your AWS Organizations using a CI/CD pipeline (AWS CodePipeline).
Backup and Recovery with AWS Backup This repository provides you with a management and deployment solution for implementing Backup and Recovery with A
8 Nov 22, 2022
Pipeline code for Sequential-GAM(Genome Architecture Mapping).
Sequential-GAM Pipeline code for Sequential-GAM(Genome Architecture Mapping). mapping whole_preprocess.sh include the whole processing of mapping. usa
 3 Nov 3, 2022
3 Nov 3, 2022
Python dilinin Selenium kütüphanesini kullanarak; Amazon, LinkedIn ve ÇiçekSepeti üzerinde test işlemleri yaptığımız bir case study reposudur.
Python dilinin Selenium kütüphanesini kullanarak; Amazon, LinkedIn ve ÇiçekSepeti üzerinde test işlemleri yaptığımız bir case study reposudur. LinkedI
 8 Nov 1, 2022
8 Nov 1, 2022

Data App Performance Tests
Data App Performance Tests My hypothesis is that The different architectures of
 6 Dec 14, 2022
6 Dec 14, 2022

Pizza Orders Data Pipeline Usecase Solved by SQL, Sqoop, HDFS, Hive, Airflow.
PizzaOrders_DataPipeline There is a Tony who is owning a New Pizza shop. He knew that pizza alone was not going to help him get seed funding to expand
 4 Jun 5, 2022
4 Jun 5, 2022

A computer vision pipeline to identify the "icons" in Christian paintings
Christian-Iconography A computer vision pipeline to identify the "icons" in Christian paintings. A bit about iconography. Iconography is related to id
 3 Jul 30, 2022
3 Jul 30, 2022
HuSpaCy: industrial-strength Hungarian natural language processing
HuSpaCy: Industrial-strength Hungarian NLP HuSpaCy is a spaCy model and a library providing industrial-strength Hungarian language processing faciliti
 120 Dec 14, 2022
120 Dec 14, 2022
End-to-end MLOps pipeline of a BERT model for emotion classification.
image source EmoBERT-MLOps The goal of this repository is to build an end-to-end MLOps pipeline based on the MLOps course from Made with ML, but this
 4 Nov 6, 2022
4 Nov 6, 2022
A practical ML pipeline for data labeling with experiment tracking using DVC.
Auto Label Pipeline A practical ML pipeline for data labeling with experiment tracking using DVC Goals: Demonstrate reproducible ML Use DVC to build a
 4 Mar 8, 2022
4 Mar 8, 2022

Always know what to expect from your data.
Great Expectations Always know what to expect from your data. Introduction Great Expectations helps data teams eliminate pipeline debt, through data t
 7.8k Jan 5, 2023
7.8k Jan 5, 2023
Deep Learning pipeline for motor-imagery classification.
BCI-ToolBox 1. Introduction BCI-ToolBox is deep learning pipeline for motor-imagery classification. This repo contains five models: ShallowConvNet, De
 18 Oct 31, 2022
18 Oct 31, 2022

DevSecOps pipeline for Python based web app using Jenkins, Ansible, AWS, and open-source security tools and checks.
DevSecOps pipeline for Python Web App A Jenkins end-to-end DevSecOps pipeline for Python web application, hosted on AWS Ubuntu 20.04 Note: This projec
 4 Aug 15, 2022
4 Aug 15, 2022

Cherche (search in French) allows you to create a neural search pipeline using retrievers and pre-trained language models as rankers.
Cherche (search in French) allows you to create a neural search pipeline using retrievers and pre-trained language models as rankers. Cherche is meant to be used with small to medium sized corpora. Cherche's main strength is its ability to build diverse and end-to-end pipelines.
 224 Nov 29, 2022
224 Nov 29, 2022
examify-io is an online examination system that offers automatic grading , exam statistics , proctoring and programming tests , multiple user roles
examify-io is an online examination system that offers automatic grading , exam statistics , proctoring and programming tests , multiple user roles ( Examiner , Supervisor , Student )
 4 Oct 28, 2021
4 Oct 28, 2021
This is the offline-training-pipeline for our project.
offline-training-pipeline This is the offline-training-pipeline for our project. We adopt the offline training and online prediction Machine Learning
 0 Apr 22, 2022
0 Apr 22, 2022

Complete pipeline for crawling online newspaper article.
Complete pipeline for crawling online newspaper article. The articles are stored to MongoDB. The whole pipeline is dockerized, thus the user does not need to worry about dependencies. Additionally, docker-compose is available to increase the useability for the user.
 4 May 27, 2022
4 May 27, 2022
A library to make concurrent selenium tests that automatically download and setup webdrivers
AutoParaSelenium A library to make parallel selenium tests that automatically download and setup webdrivers Usage Installation pip install autoparasel
 8 Mar 13, 2022
8 Mar 13, 2022

A lightweight face-recognition toolbox and pipeline based on tensorflow-lite
FaceIDLight 📘 Description A lightweight face-recognition toolbox and pipeline based on tensorflow-lite with MTCNN-Face-Detection and ArcFace-Face-Rec
 16 Dec 7, 2022
16 Dec 7, 2022
Data on COVID-19 (coronavirus) cases, deaths, hospitalizations, tests • All countries • Updated daily by Our World in Data
COVID-19 Dataset by Our World in Data Find our data on COVID-19 and its documentation in public/data. Documentation Data: complete COVID-19 dataset Da
 5.5k Jan 3, 2023
5.5k Jan 3, 2023
Fine tuning keras-ocr python package with custom synthetic dataset from scratch
OCR-Pipeline-with-Keras The keras-ocr package generally consists of two parts: a Detector and a Recognizer: Detector is responsible for creating bound
 1 Jan 5, 2022
1 Jan 5, 2022

Streaming Finance Data with AWS Lambda
A data pipeline consisting of an AWS lambda function reading data from yfinance API, an AWS Kinesis stream to receive & store data in S3 buckets and AWS Glue crawler & Athena to run SQL queries.
 4 Aug 30, 2022
4 Aug 30, 2022
DeepSpeech - Easy-to-use Speech Toolkit including SOTA ASR pipeline, influential TTS with text frontend and End-to-End Speech Simultaneous Translation.
(简体中文|English) Quick Start | Documents | Models List PaddleSpeech is an open-source toolkit on PaddlePaddle platform for a variety of critical tasks i
 5.6k Jan 3, 2023
5.6k Jan 3, 2023
Data-science-on-gcp - Source code accompanying book: Data Science on the Google Cloud Platform, Valliappa Lakshmanan, O'Reilly 2017
data-science-on-gcp Source code accompanying book: Data Science on the Google Cloud Platform, 2nd Edition Valliappa Lakshmanan O'Reilly, Jan 2022 Bran
 1.2k Dec 28, 2022
1.2k Dec 28, 2022
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
X-news - Pipeline data use scrapy, kafka, spark streaming, spark ML and elasticsearch, Kibana
 5 Sep 28, 2022
5 Sep 28, 2022

PyTorch Lightning + Hydra. A feature-rich template for rapid, scalable and reproducible ML experimentation with best practices. ⚡🔥⚡
Lightning-Hydra-Template A clean and scalable template to kickstart your deep learning project 🚀 ⚡ 🔥 Click on Use this template to initialize new re
 2.1k Jan 9, 2023
2.1k Jan 9, 2023
Data reduction pipeline for KOALA on the AAT.
KOALA KOALA, the Kilofibre Optical AAT Lenslet Array, is a wide-field, high efficiency, integral field unit used by the AAOmega spectrograph on the 3.
 4 Sep 26, 2022
4 Sep 26, 2022
whylogs: A Data and Machine Learning Logging Standard
whylogs: A Data and Machine Learning Logging Standard whylogs is an open source standard for data and ML logging whylogs logging agent is the easiest
 2k Jan 6, 2023
2k Jan 6, 2023

ETL pipeline on movie data using Python and postgreSQL
Movies-ETL ETL pipeline on movie data using Python and postgreSQL Overview This project consisted on a automated Extraction, Transformation and Load p
 0 Jul 7, 2021
0 Jul 7, 2021

The object detection pipeline is based on Ultralytics YOLOv5
AYOLOv2 The main goal of this repository is to rewrite the object detection pipeline with a better code structure for better portability and adaptabil
 153 Dec 22, 2022
153 Dec 22, 2022
Design by contract for Python. Write bug-free code. Add a few decorators, get static analysis and tests for free.
A Python library for design by contract (DbC) and checking values, exceptions, and side-effects. In a nutshell, deal empowers you to write bug-free co
 473 Dec 28, 2022
473 Dec 28, 2022
pypyr task-runner cli & api for automation pipelines.
pypyr task-runner cli & api for automation pipelines. Automate anything by combining commands, different scripts in different languages & applications into one pipeline process.
 471 Dec 15, 2022
471 Dec 15, 2022
FauxFactory generates random data for your automated tests easily!
FauxFactory FauxFactory generates random data for your automated tests easily! There are times when you're writing tests for your application when you
 37 Sep 23, 2022
37 Sep 23, 2022
The DL Streamer Pipeline Zoo is a catalog of optimized media and media analytics pipelines.
The DL Streamer Pipeline Zoo is a catalog of optimized media and media analytics pipelines. It includes tools for downloading pipelines and their dependencies and tools for measuring their performace.
 8 Dec 4, 2022
8 Dec 4, 2022

A set of tests for evaluating large-scale algorithms for Wasserstein-2 transport maps computation.
Continuous Wasserstein-2 Benchmark This is the official Python implementation of the NeurIPS 2021 paper Do Neural Optimal Transport Solvers Work? A Co
 22 Dec 12, 2022
22 Dec 12, 2022
Spline is a tool that is capable of running locally as well as part of well known pipelines like Jenkins (Jenkinsfile), Travis CI (.travis.yml) or similar ones.
Welcome to spline - the pipeline tool Important note: Since change in my job I didn't had the chance to continue on this project. My main new project
 29 Aug 22, 2022
29 Aug 22, 2022

Build an Amazon SageMaker Pipeline to Transform Raw Texts to A Knowledge Graph
Build an Amazon SageMaker Pipeline to Transform Raw Texts to A Knowledge Graph This repository provides a pipeline to create a knowledge graph from ra
3 Jan 1, 2022
A library that allows you to easily mock out tests based on AWS infrastructure.
Moto - Mock AWS Services Install $ pip install moto[ec2,s3,all] In a nutshell Moto is a library that allows your tests to easily mock out AWS Services
 6.5k Jan 2, 2023
6.5k Jan 2, 2023
Monitor the stability of a pandas or spark dataframe ⚙︎
Population Shift Monitoring popmon is a package that allows one to check the stability of a dataset. popmon works with both pandas and spark datasets.
 403 Dec 7, 2022
403 Dec 7, 2022
A pipeline for making highlighted text stand-alone.
title emoji colorFrom colorTo sdk app_file pinned decontextualizer 📤 green gray streamlit main.py false Decontextualizer As a second step in improvin
 26 Dec 17, 2022
26 Dec 17, 2022
Basic yet complete Machine Learning pipeline for NLP tasks
Basic yet complete Machine Learning pipeline for NLP tasks This repository accompanies the article on building basic yet complete ML pipelines for sol
 20 Aug 22, 2022
20 Aug 22, 2022
A pytest plugin to skip `@pytest.mark.slow` tests by default.
pytest-skip-slow A pytest plugin to skip @pytest.mark.slow tests by default. Include the slow tests with --slow. Installation $ pip install pytest-ski
 19 Jan 4, 2023
19 Jan 4, 2023
Travel through time in your tests.
time-machine Travel through time in your tests. A quick example: import datetime as dt
 373 Dec 27, 2022
373 Dec 27, 2022
simple way to build the declarative and destributed data pipelines with python
unipipeline simple way to build the declarative and distributed data pipelines. Why you should use it Declarative strict config Scaffolding Fully type
 0 Jan 26, 2022
0 Jan 26, 2022
Python library for creating data pipelines with chain functional programming
PyFunctional Features PyFunctional makes creating data pipelines easy by using chained functional operators. Here are a few examples of what it can do
 2.1k Jan 5, 2023
2.1k Jan 5, 2023

A full pipeline AutoML tool for tabular data
HyperGBM Doc | 中文 We Are Hiring! Dear folks,we are offering challenging opportunities located in Beijing for both professionals and students who are k
 240 Jan 3, 2023
240 Jan 3, 2023

Healthsea is a spaCy pipeline for analyzing user reviews of supplementary products for their effects on health.
Welcome to Healthsea ✨ Create better access to health with spaCy. Healthsea is a pipeline for analyzing user reviews to supplement products by extract
 75 Dec 19, 2022
75 Dec 19, 2022
Transform a Google Drive server into a VFX pipeline ready server
Google Drive VFX Server VFX Pipeline About The Project Quick tutorial to setup a Google Drive Server for multiple machines access, and VFX Pipeline on
 17 Jun 27, 2022
17 Jun 27, 2022
Allele-specific pipeline for unbiased read mapping(WIP), QTL discovery(WIP), and allelic-imbalance analysis
WASP2 (Currently in pre-development): Allele-specific pipeline for unbiased read mapping(WIP), QTL discovery(WIP), and allelic-imbalance analysis Requ
 2 Aug 11, 2022
2 Aug 11, 2022
A computational block to solve entity alignment over textual attributes in a knowledge graph creation pipeline.
How to apply? Create your config.ini file following the example provided in config.ini Choose one of the options below to run: Run with Python3 pip in
 3 Jun 23, 2022
3 Jun 23, 2022

A real-time financial data streaming pipeline and visualization platform using Apache Kafka, Cassandra, and Bokeh.
Realtime Financial Market Data Visualization and Analysis Introduction This repo shows my project about real-time stock data pipeline. All the code is
 6 Sep 7, 2022
6 Sep 7, 2022
RCT-ART is an NLP pipeline built with spaCy for converting clinical trial result sentences into tables through jointly extracting intervention, outcome and outcome measure entities and their relations.
Randomised controlled trial abstract result tabulator RCT-ART is an NLP pipeline built with spaCy for converting clinical trial result sentences into
 2 Sep 16, 2022
2 Sep 16, 2022
Microsoft Azure provides a wide number of services for managing and storing data
Microsoft Azure provides a wide number of services for managing and storing data. One product is Microsoft Azure SQL. Which gives us the capability to create and manage instances of SQL Servers hosted in the cloud. This project, demonstrates how to use these services to manage data we collect from different sources.
 1 Dec 12, 2021
1 Dec 12, 2021
a wrapper around pytest for executing tests to look for test flakiness and runtime regression
bubblewrap a wrapper around pytest for assessing flakiness and runtime regressions a cs implementations practice project How to Run: First, install de
 1 Aug 5, 2021
1 Aug 5, 2021
One-stop-shop for docs and test coverage of dbt projects.
dbt-coverage One-stop-shop for docs and test coverage of dbt projects. Why do I need something like this? dbt-coverage is to dbt what coverage.py and
 106 Dec 27, 2022
106 Dec 27, 2022
Automated tests for OKAY websites in Python (Selenium) - user friendly version
Okay Selenium Testy Aplikace určená k testování produkčních webů společnosti OKAY s.r.o. Závislosti K běhu aplikace je potřeba mít v počítači nainstal
 0 Oct 1, 2022
0 Oct 1, 2022
Fail tests that take too long to run
GitHub | PyPI | Issues pytest-fail-slow is a pytest plugin for making tests fail that take too long to run. It adds a --fail-slow DURATION command-lin
 4 Nov 27, 2022
4 Nov 27, 2022
The sarge package provides a wrapper for subprocess which provides command pipeline functionality.
Overview The sarge package provides a wrapper for subprocess which provides command pipeline functionality. This package leverages subprocess to provi
 14 Dec 18, 2022
14 Dec 18, 2022

MapReader: A computer vision pipeline for the semantic exploration of maps at scale
MapReader A computer vision pipeline for the semantic exploration of maps at scale MapReader is an end-to-end computer vision (CV) pipeline designed b
 25 Dec 26, 2022
25 Dec 26, 2022
This repository contains full machine learning pipeline of the Zillow Houses competition on Kaggle platform.
Zillow-Houses This repository contains full machine learning pipeline of the Zillow Houses competition on Kaggle platform. Pipeline is consists of 10
 2 Jan 9, 2022
2 Jan 9, 2022
Demonstrate a Dataflow pipeline that saves data from an API into BigQuery table
Overview dataflow-mvp provides a basic example pipeline that pulls data from an API and writes it to a BigQuery table using GCP's Dataflow (i.e., Apac
 1 Dec 3, 2021
1 Dec 3, 2021
Pipeline for training LSA models using Scikit-Learn.
Latent Semantic Analysis Pipeline for training LSA models using Scikit-Learn. Usage Instead of writing custom code for latent semantic analysis, you j
 23 Sep 5, 2022
23 Sep 5, 2022