2736 Repositories
Python spatial-temporal-data Libraries
Easy-to-use data handling for SQL data stores with support for implicit table creation, bulk loading, and transactions.
dataset: databases for lazy people In short, dataset makes reading and writing data in databases as simple as reading and writing JSON files. Read the
 4.2k Jan 2, 2023
4.2k Jan 2, 2023
Pandas Google BigQuery
pandas-gbq pandas-gbq is a package providing an interface to the Google BigQuery API from pandas Installation Install latest release version via conda
 345 Dec 28, 2022
345 Dec 28, 2022
A small Python module for determining appropriate platform-specific dirs, e.g. a "user data dir".
the problem What directory should your app use for storing user data? If running on macOS, you should use: ~/Library/Application Support/AppName If
 948 Dec 31, 2022
948 Dec 31, 2022
Lightweight data validation and adaptation Python library.
Valideer Lightweight data validation and adaptation library for Python. At a Glance: Supports both validation (check if a value is valid) and adaptati
 258 Nov 22, 2022
258 Nov 22, 2022
Python Data Structures for Humans™.
Schematics Python Data Structures for Humans™. About Project documentation: https://schematics.readthedocs.io/en/latest/ Schematics is a Python librar
 2.5k Dec 28, 2022
2.5k Dec 28, 2022

Typical: Fast, simple, & correct data-validation using Python 3 typing.
typical: Python's Typing Toolkit Introduction Typical is a library devoted to runtime analysis, inference, validation, and enforcement of Python types
 171 Jan 2, 2023
171 Jan 2, 2023
A simple, fast, extensible python library for data validation.
Validr A simple, fast, extensible python library for data validation. Simple and readable schema 10X faster than jsonschema, 40X faster than schematic
 209 Sep 19, 2022
209 Sep 19, 2022
Python Data Validation for Humans™.
validators Python data validation for Humans. Python has all kinds of data validation tools, but every one of them seems to require defining a schema
 670 Jan 9, 2023
670 Jan 9, 2023
CONTRIBUTIONS ONLY: Voluptuous, despite the name, is a Python data validation library.
CONTRIBUTIONS ONLY What does this mean? I do not have time to fix issues myself. The only way fixes or new features will be added is by people submitt
 1.8k Dec 31, 2022
1.8k Dec 31, 2022
Lightweight, extensible data validation library for Python
Cerberus Cerberus is a lightweight and extensible data validation library for Python. v = Validator({'name': {'type': 'string'}}) v.validate({
 2.9k Dec 27, 2022
2.9k Dec 27, 2022
Data parsing and validation using Python type hints
pydantic Data validation and settings management using Python type hinting. Fast and extensible, pydantic plays nicely with your linters/IDE/brain. De
 12.1k Jan 6, 2023
12.1k Jan 6, 2023
Protocol Buffers - Google's data interchange format
Protocol Buffers - Google's data interchange format Copyright 2008 Google Inc. https://developers.google.com/protocol-buffers/ Overview Protocol Buffe
 57.6k Jan 3, 2023
57.6k Jan 3, 2023
Easily share data across your company via SQL queries. From Grove Collab.
SQL Explorer SQL Explorer aims to make the flow of data between people fast, simple, and confusion-free. It is a Django-based application that you can
 2.1k Dec 30, 2022
2.1k Dec 30, 2022
A reusable Django model field for storing ad-hoc JSON data
jsonfield jsonfield is a reusable model field that allows you to store validated JSON, automatically handling serialization to and from the database.
 1.1k Jan 3, 2023
1.1k Jan 3, 2023

Django application and library for importing and exporting data with admin integration.
django-import-export django-import-export is a Django application and library for importing and exporting data with included admin integration. Featur
 2.6k Dec 26, 2022
2.6k Dec 26, 2022
A flask extension using pyexcel to read, manipulate and write data in different excel formats: csv, ods, xls, xlsx and xlsm.
Flask-Excel - Let you focus on data, instead of file formats Support the project If your company has embedded pyexcel and its components into a revenu
 247 Dec 27, 2022
247 Dec 27, 2022

Django Smuggler is a pluggable application for Django Web Framework that helps you to import/export fixtures via the automatically-generated administration interface.
Django Smuggler Django Smuggler is a pluggable application for Django Web Framework to easily dump/load fixtures via the automatically-generated admin
 373 Dec 26, 2022
373 Dec 26, 2022
Middleware for Starlette that allows you to store and access the context data of a request. Can be used with logging so logs automatically use request headers such as x-request-id or x-correlation-id.
starlette context Middleware for Starlette that allows you to store and access the context data of a request. Can be used with logging so logs automat
 300 Dec 26, 2022
300 Dec 26, 2022
GoAccess is a real-time web log analyzer and interactive viewer that runs in a terminal in *nix systems or through your browser.
GoAccess What is it? GoAccess is an open source real-time web log analyzer and interactive viewer that runs in a terminal on *nix systems or through y
 15.6k Jan 2, 2023
15.6k Jan 2, 2023
Library to scrape and clean web pages to create massive datasets.
lazynlp A straightforward library that allows you to crawl, clean up, and deduplicate webpages to create massive monolingual datasets. Using this libr
 2.1k Jan 6, 2023
2.1k Jan 6, 2023
Parsel lets you extract data from XML/HTML documents using XPath or CSS selectors
Parsel Parsel is a BSD-licensed Python library to extract and remove data from HTML and XML using XPath and CSS selectors, optionally combined with re
 859 Dec 29, 2022
859 Dec 29, 2022
IMDbPY is a Python package useful to retrieve and manage the data of the IMDb movie database about movies, people, characters and companies
IMDbPY is a Python package for retrieving and managing the data of the IMDb movie database about movies, people and companies. Revamp notice Starting
 1.1k Jan 2, 2023
1.1k Jan 2, 2023
TuShare is a utility for crawling historical data of China stocks
TuShare Tushare Pro版已发布,请访问新的官网了解和查询数据接口! https://tushare.pro TuShare是实现对股票/期货等金融数据从数据采集、清洗加工 到 数据存储过程的工具,满足金融量化分析师和学习数据分析的人在数据获取方面的需求,它的特点是数据覆盖范围广,接口
 11.9k Dec 30, 2022
11.9k Dec 30, 2022
🏆 A ranked list of awesome machine learning Python libraries. Updated weekly.
Best-of Machine Learning with Python 🏆 A ranked list of awesome machine learning Python libraries. Updated weekly. This curated list contains 840 awe
 12.2k Jan 4, 2023
12.2k Jan 4, 2023
Mockoon is the easiest and quickest way to run mock APIs locally. No remote deployment, no account required, open source.
Mockoon Mockoon is the easiest and quickest way to run mock APIs locally. No remote deployment, no account required, open source. It has been built wi
 4.4k Dec 30, 2022
4.4k Dec 30, 2022
Script used to download data for stocks.
This script is useful for downloading stock market data for a wide range of companies specified by their respective tickers. The script reads in the d
 71 Oct 4, 2022
71 Oct 4, 2022
🏆 A ranked list of awesome Python open-source libraries and tools. Updated weekly.
Best-of Python 🏆 A ranked list of awesome Python open-source libraries & tools. Updated weekly. This curated list contains 230 awesome open-source pr
2.7k Jan 3, 2023

DeiT: Data-efficient Image Transformers
DeiT: Data-efficient Image Transformers This repository contains PyTorch evaluation code, training code and pretrained models for DeiT (Data-Efficient
 3.2k Jan 6, 2023
3.2k Jan 6, 2023

Deploy a ML inference service on a budget in less than 10 lines of code.
BudgetML is perfect for practitioners who would like to quickly deploy their models to an endpoint, but not waste a lot of time, money, and effort trying to figure out how to do this end-to-end.
 1.3k Dec 25, 2022
1.3k Dec 25, 2022

This is a database of 180.000+ symbols containing Equities, ETFs, Funds, Indices, Futures, Options, Currencies, Cryptocurrencies and Money Markets.
Finance Database As a private investor, the sheer amount of information that can be found on the internet is rather daunting.
 1.4k Dec 31, 2022
1.4k Dec 31, 2022
Python AsyncIO data API to manage billions of resources
Introduction Please read the detailed docs This is the working project of the next generation Guillotina server based on asyncio. Dependencies Python
 183 Nov 15, 2022
183 Nov 15, 2022

⚾🤖⚾ Automatic baseball pitching overlay in realtime
⚾ Automatically overlaying pitch motion and trajectory with machine learning! This project takes your baseball pitching clips and automatically genera
 240 Dec 5, 2022
240 Dec 5, 2022
A machine learning benchmark of in-the-wild distribution shifts, with data loaders, evaluators, and default models.
WILDS is a benchmark of in-the-wild distribution shifts spanning diverse data modalities and applications, from tumor identification to wildlife monitoring to poverty mapping.
 437 Dec 30, 2022
437 Dec 30, 2022
Graphing communities on Twitch.tv in a visually intuitive way
VisualizingTwitchCommunities This project maps communities of streamers on Twitch.tv based on shared viewership. The data is collected from the Twitch
 312 Jan 7, 2023
312 Jan 7, 2023
Converts Betaflight blackbox gyro to MP4 GoPro Meta data so it can be used with ReelSteady GO
Here are a bunch of scripts that I created some time ago as a proof of concept that Betaflight blackbox gyro data can be converted to GoPro Metadata F
 108 Oct 5, 2022
108 Oct 5, 2022

Export your data from Xiami
Xiami Exporter 导出虾米音乐的个人数据,功能: 导出歌曲为 json 收藏歌曲 收藏专辑 播放列表 导出收藏艺人为 json 导出收藏专辑为 json 导出播放列表为 json (个人和收藏) 将导出的数据整理至 sqlite 数据库 收藏歌曲 收藏艺人 收藏专辑 播放列表 下载已导出
 59 Nov 13, 2021
59 Nov 13, 2021
An API serving data on all creatures, monsters, materials, equipment, and treasure in The Legend of Zelda: Breath of the Wild
Hyrule Compendium API An API serving data on all creatures, monsters, materials, equipment, and treasure in The Legend of Zelda: Breath of the Wild. B
 116 Dec 1, 2022
116 Dec 1, 2022

TDN: Temporal Difference Networks for Efficient Action Recognition
TDN: Temporal Difference Networks for Efficient Action Recognition Overview We release the PyTorch code of the TDN(Temporal Difference Networks).
 326 Dec 13, 2022
326 Dec 13, 2022
Soda SQL Data testing, monitoring and profiling for SQL accessible data.
Soda SQL Data testing, monitoring and profiling for SQL accessible data. What does Soda SQL do? Soda SQL allows you to Stop your pipeline when bad dat
 51 Jan 1, 2023
51 Jan 1, 2023

A framework for joint super-resolution and image synthesis, without requiring real training data
SynthSR This repository contains code to train a Convolutional Neural Network (CNN) for Super-resolution (SR), or joint SR and data synthesis. The met
 83 Jan 1, 2023
83 Jan 1, 2023
data/code repository of "C2F-FWN: Coarse-to-Fine Flow Warping Network for Spatial-Temporal Consistent Motion Transfer"
C2F-FWN data/code repository of "C2F-FWN: Coarse-to-Fine Flow Warping Network for Spatial-Temporal Consistent Motion Transfer" (https://arxiv.org/abs/
 46 Dec 14, 2022
46 Dec 14, 2022
This repository is related to an Arabic tutorial, within the tutorial we discuss the common data structure and algorithms and their worst and best case for each, then implement the code using Python.
Data Structure and Algorithms with Python This repository is related to the Arabic tutorial here, within the tutorial we discuss the common data struc
 33 Dec 2, 2022
33 Dec 2, 2022
A Pythonic client for the official https://data.gov.gr API.
pydatagovgr An unofficial Pythonic client for the official data.gov.gr API. Aims to be an easy, intuitive and out-of-the-box way to: find data publish
 40 Nov 10, 2022
40 Nov 10, 2022

Learning from History: Modeling Temporal Knowledge Graphs with Sequential Copy-Generation Networks
CyGNet This repository reproduces the AAAI'21 paper “Learning from History: Modeling Temporal Knowledge Graphs with Sequential Copy-Generation Network
 89 Jan 3, 2023
89 Jan 3, 2023
Temporal-Relational CrossTransformers
Temporal-Relational Cross-Transformers (TRX) This repo contains code for the method introduced in the paper: Temporal-Relational CrossTransformers for
 83 Dec 12, 2022
83 Dec 12, 2022
A minimalistic library designed to provide native access to YNAB data from Python
pYNAB A minimalistic library designed to provide native access to YNAB data from Python. Install The simplest way is to install the latest version fro
 92 Apr 6, 2022
92 Apr 6, 2022
Python wrapper for the Sportradar APIs ⚽️🏈
Sportradar APIs This is a Python wrapper for the sports APIs provided by Sportradar. You'll need to sign up for an API key to use the service. Sportra
 39 Jan 1, 2023
39 Jan 1, 2023
Python client for the Socrata Open Data API
sodapy sodapy is a python client for the Socrata Open Data API. Installation You can install with pip install sodapy. If you want to install from sour
 368 Dec 9, 2022
368 Dec 9, 2022
A Python API to retrieve and read MLB GameDay data
mlbgame mlbgame is a Python API to retrieve and read MLB GameDay data. mlbgame works with real time data, getting information as games are being playe
 493 Dec 13, 2022
493 Dec 13, 2022
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning tasks.
Light Gradient Boosting Machine LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed a
 14.5k Jan 8, 2023
14.5k Jan 8, 2023
:snake: A simple library to fetch data from the iTunes Store API made for Python = 3.5
itunespy itunespy is a simple library to fetch data from the iTunes Store API made for Python 3.5 and beyond. Important: Since version 1.6 itunespy no
 56 Dec 22, 2022
56 Dec 22, 2022
Backtest 1000s of minute-by-minute trading algorithms for training AI with automated pricing data from: IEX, Tradier and FinViz. Datasets and trading performance automatically published to S3 for building AI training datasets for teaching DNNs how to trade. Runs on Kubernetes and docker-compose. 150 million trading history rows generated from +5000 algorithms. Heads up: Yahoo's Finance API was disabled on 2019-01-03 https://developer.yahoo.com/yql/
Stock Analysis Engine Build and tune investment algorithms for use with artificial intelligence (deep neural networks) with a distributed stack for ru
 828 Dec 28, 2022
828 Dec 28, 2022
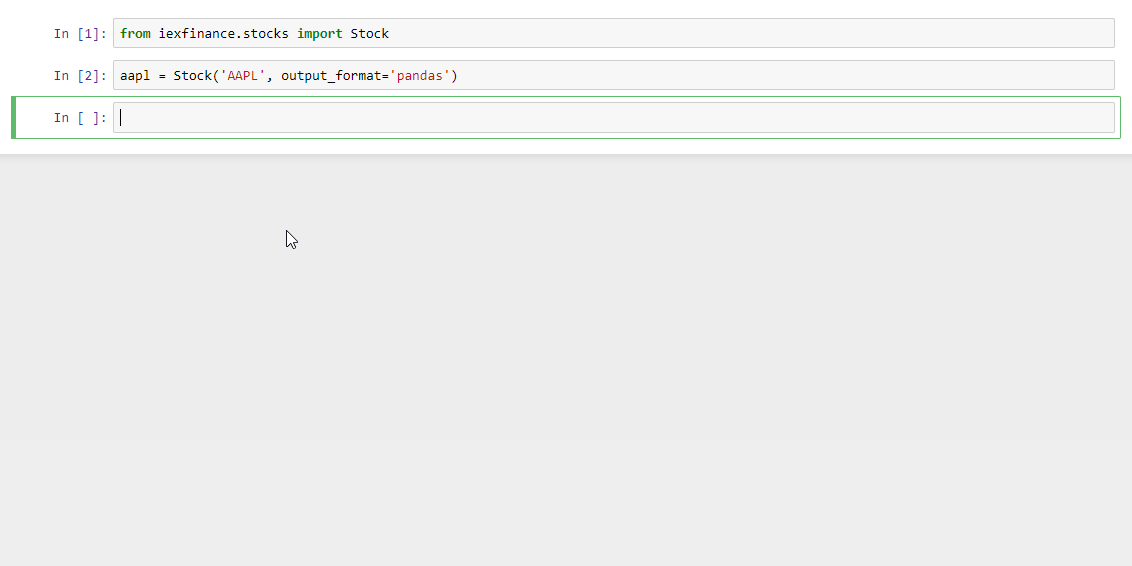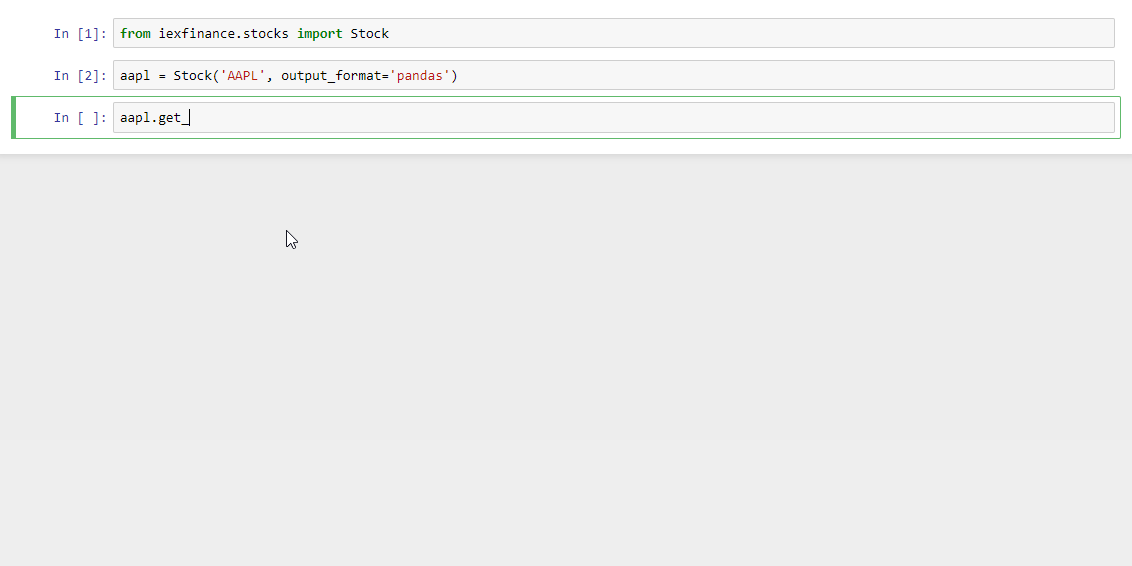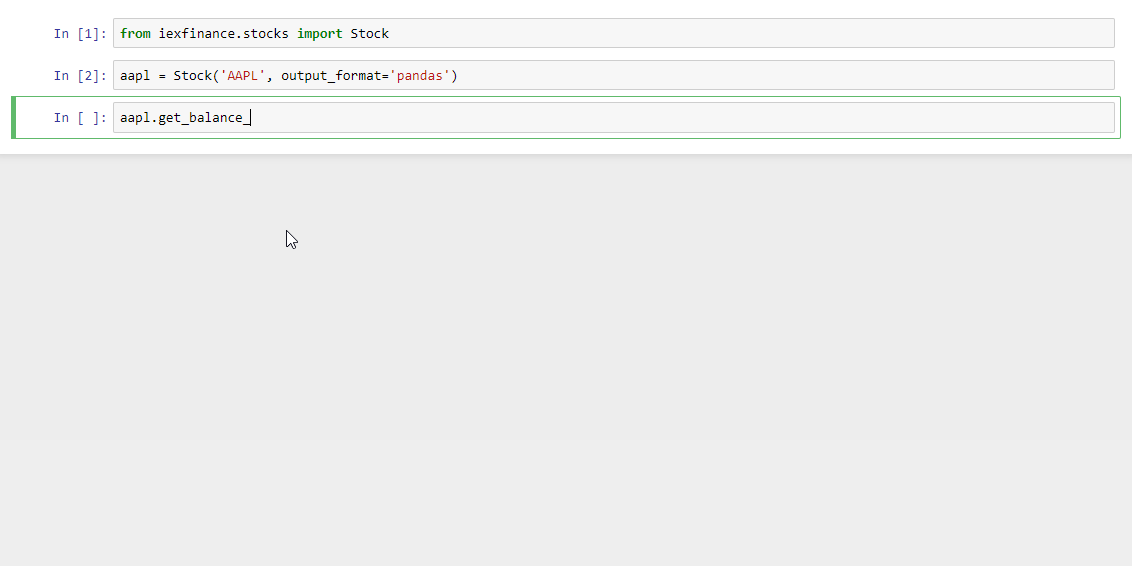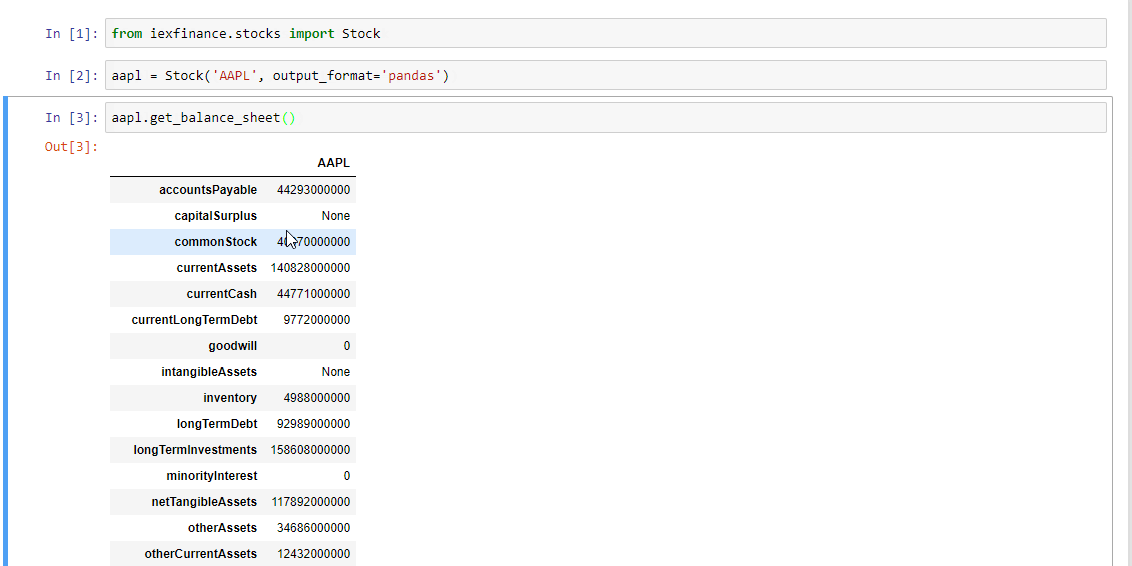
Python SDK for IEX Cloud
iexfinance Python SDK for IEX Cloud. Architecture mirrors that of the IEX Cloud API (and its documentation). An easy-to-use toolkit to obtain data for
 640 Jan 7, 2023
640 Jan 7, 2023
Mimesis is a high-performance fake data generator for Python, which provides data for a variety of purposes in a variety of languages.
Mimesis - Fake Data Generator Description Mimesis is a high-performance fake data generator for Python, which provides data for a variety of purposes
 3.8k Jan 1, 2023
3.8k Jan 1, 2023
Faker is a Python package that generates fake data for you.
Faker is a Python package that generates fake data for you. Whether you need to bootstrap your database, create good-looking XML documents, fill-in yo
 15.2k Jan 1, 2023
15.2k Jan 1, 2023
create custom test databases that are populated with fake data
About Generate fake but valid data filled databases for test purposes using most popular patterns(AFAIK). Current support is sqlite, mysql, postgresql
 2.2k Jan 6, 2023
2.2k Jan 6, 2023
Mimesis is a high-performance fake data generator for Python, which provides data for a variety of purposes in a variety of languages.
Mimesis - Fake Data Generator Description Mimesis is a high-performance fake data generator for Python, which provides data for a variety of purposes
3.8k Dec 29, 2022
Faker is a Python package that generates fake data for you.
Faker is a Python package that generates fake data for you. Whether you need to bootstrap your database, create good-looking XML documents, fill-in yo
15.2k Jan 1, 2023
create custom test databases that are populated with fake data
About Generate fake but valid data filled databases for test purposes using most popular patterns(AFAIK). Current support is sqlite, mysql, postgresql
2.2k Jan 4, 2023
Single API for reading, manipulating and writing data in csv, ods, xls, xlsx and xlsm files
pyexcel - Let you focus on data, instead of file formats Support the project If your company has embedded pyexcel and its components into a revenue ge
 1.1k Dec 29, 2022
1.1k Dec 29, 2022
Statsmodels: statistical modeling and econometrics in Python
About statsmodels statsmodels is a Python package that provides a complement to scipy for statistical computations including descriptive statistics an
 8k Dec 29, 2022
8k Dec 29, 2022
Rich Python data types for Redis
Created by Stephen McDonald Introduction HOT Redis is a wrapper library for the redis-py client. Rather than calling the Redis commands directly from
 281 Nov 10, 2022
281 Nov 10, 2022
Easy-to-use data handling for SQL data stores with support for implicit table creation, bulk loading, and transactions.
dataset: databases for lazy people In short, dataset makes reading and writing data in databases as simple as reading and writing JSON files. Read the
4.2k Dec 26, 2022
Safely pass trusted data to untrusted environments and back.
ItsDangerous ... so better sign this Various helpers to pass data to untrusted environments and to get it back safe and sound. Data is cryptographical
 2.6k Jan 1, 2023
2.6k Jan 1, 2023
🔩 Like builtins, but boltons. 250+ constructs, recipes, and snippets which extend (and rely on nothing but) the Python standard library. Nothing like Michael Bolton.
Boltons boltons should be builtins. Boltons is a set of over 230 BSD-licensed, pure-Python utilities in the same spirit as — and yet conspicuously mis
 6k Jan 6, 2023
6k Jan 6, 2023

Debugging, monitoring and visualization for Python Machine Learning and Data Science
Welcome to TensorWatch TensorWatch is a debugging and visualization tool designed for data science, deep learning and reinforcement learning from Micr
3.3k Dec 27, 2022

Analytical Web Apps for Python, R, Julia, and Jupyter. No JavaScript Required.
Dash Dash is the most downloaded, trusted Python framework for building ML & data science web apps. Built on top of Plotly.js, React and Flask, Dash t
 17.9k Dec 31, 2022
17.9k Dec 31, 2022
Multi-class confusion matrix library in Python
Table of contents Overview Installation Usage Document Try PyCM in Your Browser Issues & Bug Reports Todo Outputs Dependencies Contribution References
 1.3k Dec 31, 2022
1.3k Dec 31, 2022

:bowtie: Create a dashboard with python!
Installation | Documentation | Gitter Chat | Google Group Bowtie Introduction Bowtie is a library for writing dashboards in Python. No need to know we
 753 Dec 22, 2022
753 Dec 22, 2022

An intuitive library to add plotting functionality to scikit-learn objects.
Welcome to Scikit-plot Single line functions for detailed visualizations The quickest and easiest way to go from analysis... ...to this. Scikit-plot i
 2.3k Dec 31, 2022
2.3k Dec 31, 2022
Tools for exploratory data analysis in Python
Dora Exploratory data analysis toolkit for Python. Contents Summary Setup Usage Reading Data & Configuration Cleaning Feature Selection & Extraction V
 599 Dec 25, 2022
599 Dec 25, 2022
Apache Superset is a Data Visualization and Data Exploration Platform
Superset A modern, enterprise-ready business intelligence web application. Why Superset? | Supported Databases | Installation and Configuration | Rele
 50k Jan 6, 2023
50k Jan 6, 2023
The windML framework provides an easy-to-use access to wind data sources within the Python world, building upon numpy, scipy, sklearn, and matplotlib. Renewable Wind Energy, Forecasting, Prediction
windml Build status : The importance of wind in smart grids with a large number of renewable energy resources is increasing. With the growing infrastr
 125 Dec 24, 2022
125 Dec 24, 2022
The Python ensemble sampling toolkit for affine-invariant MCMC
emcee The Python ensemble sampling toolkit for affine-invariant MCMC emcee is a stable, well tested Python implementation of the affine-invariant ense
 1.3k Jan 4, 2023
1.3k Jan 4, 2023
NumPy and Pandas interface to Big Data
Blaze translates a subset of modified NumPy and Pandas-like syntax to databases and other computing systems. Blaze allows Python users a familiar inte
 3.1k Jan 1, 2023
3.1k Jan 1, 2023
Fast data visualization and GUI tools for scientific / engineering applications
PyQtGraph A pure-Python graphics library for PyQt5/PyQt6/PySide2/PySide6 Copyright 2020 Luke Campagnola, University of North Carolina at Chapel Hill h
 3.1k Jan 8, 2023
3.1k Jan 8, 2023
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
 2.1k Jan 1, 2023
2.1k Jan 1, 2023
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 13.8k Jan 2, 2023
13.8k Jan 2, 2023
Yet Another Sequence Encoder - Encode sequences to vector of vector in python !
Yase Yet Another Sequence Encoder - encode sequences to vector of vectors in python ! Why Yase ? Yase enable you to encode any sequence which can be r
 12 Aug 19, 2021
12 Aug 19, 2021
💫 Industrial-strength Natural Language Processing (NLP) in Python
spaCy: Industrial-strength NLP spaCy is a library for advanced Natural Language Processing in Python and Cython. It's built on the very latest researc
 24.9k Jan 2, 2023
24.9k Jan 2, 2023
A Python package implementing a new model for text classification with visualization tools for Explainable AI :octocat:
A Python package implementing a new model for text classification with visualization tools for Explainable AI 🍣 Online live demos: http://tworld.io/s
 285 Jan 2, 2023
285 Jan 2, 2023
Tools, wrappers, etc... for data science with a concentration on text processing
Rosetta Tools for data science with a focus on text processing. Focuses on "medium data", i.e. data too big to fit into memory but too small to necess
 207 Nov 22, 2022
207 Nov 22, 2022

Create UIs for prototyping your machine learning model in 3 minutes
Note: We just launched Hosted, where anyone can upload their interface for permanent hosting. Check it out! Welcome to Gradio Quickly create customiza
 11.7k Jan 7, 2023
11.7k Jan 7, 2023
A unified framework for machine learning with time series
Welcome to sktime A unified framework for machine learning with time series We provide specialized time series algorithms and scikit-learn compatible
 6k Jan 8, 2023
6k Jan 8, 2023

A Peer-to-peer Platform for Secure, Privacy-preserving, Decentralized Data Science
PyGrid is a peer-to-peer network of data owners and data scientists who can collectively train AI models using PySyft. PyGrid is also the central serv
 615 Jan 3, 2023
615 Jan 3, 2023
A library for answering questions using data you cannot see
A library for computing on data you do not own and cannot see PySyft is a Python library for secure and private Deep Learning. PySyft decouples privat
8.5k Jan 2, 2023

Automates Machine Learning Pipeline with Feature Engineering and Hyper-Parameters Tuning :rocket:
MLJAR Automated Machine Learning Documentation: https://supervised.mljar.com/ Source Code: https://github.com/mljar/mljar-supervised Table of Contents
 2.4k Dec 31, 2022
2.4k Dec 31, 2022
A machine learning package for streaming data in Python. The other ancestor of River.
scikit-multiflow is a machine learning package for streaming data in Python. creme and scikit-multiflow are merging into a new project called River. W
 670 Dec 30, 2022
670 Dec 30, 2022
🌊 Online machine learning in Python
In a nutshell River is a Python library for online machine learning. It is the result of a merger between creme and scikit-multiflow. River's ambition
 4k Jan 2, 2023
4k Jan 2, 2023
MiraiML: asynchronous, autonomous and continuous Machine Learning in Python
MiraiML Mirai: future in japanese. MiraiML is an asynchronous engine for continuous & autonomous machine learning, built for real-time usage. Usage In
 25 Jul 27, 2022
25 Jul 27, 2022

StellarGraph - Machine Learning on Graphs
StellarGraph Machine Learning Library StellarGraph is a Python library for machine learning on graphs and networks. Table of Contents Introduction Get
 2.6k Jan 5, 2023
2.6k Jan 5, 2023
Best Practices on Recommendation Systems
Recommenders What's New (February 4, 2021) We have a new relase Recommenders 2021.2! It comes with lots of bug fixes, optimizations and 3 new algorith
14.8k Jan 3, 2023
High performance, easy-to-use, and scalable machine learning (ML) package, including linear model (LR), factorization machines (FM), and field-aware factorization machines (FFM) for Python and CLI interface.
What is xLearn? xLearn is a high performance, easy-to-use, and scalable machine learning package that contains linear model (LR), factorization machin
 3k Jan 3, 2023
3k Jan 3, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 4, 2023
6.9k Jan 4, 2023
Machine Learning From Scratch. Bare bones NumPy implementations of machine learning models and algorithms with a focus on accessibility. Aims to cover everything from linear regression to deep learning.
Machine Learning From Scratch About Python implementations of some of the fundamental Machine Learning models and algorithms from scratch. The purpose
 21.8k Jan 9, 2023
21.8k Jan 9, 2023
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate.
The lightweight PyTorch wrapper for high-performance AI research. Scale your models, not the boilerplate. Website • Key Features • How To Use • Docs •
 21.1k Jan 1, 2023
21.1k Jan 1, 2023

A web-based application for quick, scalable, and automated hyperparameter tuning and stacked ensembling in Python.
Xcessiv Xcessiv is a tool to help you create the biggest, craziest, and most excessive stacked ensembles you can think of. Stacked ensembles are simpl
1.3k Nov 17, 2022

Deep learning library featuring a higher-level API for TensorFlow.
TFLearn: Deep learning library featuring a higher-level API for TensorFlow. TFlearn is a modular and transparent deep learning library built on top of
 9.6k Jan 2, 2023
9.6k Jan 2, 2023
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming.
Master status: Development status: Package information: TPOT stands for Tree-based Pipeline Optimization Tool. Consider TPOT your Data Science Assista
 8.9k Dec 30, 2022
8.9k Dec 30, 2022
A library of extension and helper modules for Python's data analysis and machine learning libraries.
Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. Sebastian Raschka 2014-2020 Links Doc
 4.2k Jan 2, 2023
4.2k Jan 2, 2023