190 Repositories
Python speaker-adaptation Libraries
A new mini-batch framework for optimal transport in deep generative models, deep domain adaptation, approximate Bayesian computation, color transfer, and gradient flow.
BoMb-OT Python3 implementation of the papers On Transportation of Mini-batches: A Hierarchical Approach and Improving Mini-batch Optimal Transport via
 18 Nov 14, 2022
18 Nov 14, 2022
Code release for "Cycle Self-Training for Domain Adaptation" (NeurIPS 2021)
CST Code release for "Cycle Self-Training for Domain Adaptation" (NeurIPS 2021) Prerequisites torch=1.7.0 torchvision qpsolvers numpy prettytable tqd
 31 Jan 8, 2023
31 Jan 8, 2023
Deep Reinforcement Learning by using an on-policy adaptation of Maximum a Posteriori Policy Optimization (MPO)
V-MPO Simple code to demonstrate Deep Reinforcement Learning by using an on-policy adaptation of Maximum a Posteriori Policy Optimization (MPO) in Pyt
 9 Jun 6, 2022
9 Jun 6, 2022

Incremental Cross-Domain Adaptation for Robust Retinopathy Screening via Bayesian Deep Learning
Incremental Cross-Domain Adaptation for Robust Retinopathy Screening via Bayesian Deep Learning Update (September 18th, 2021) A supporting document de
 1 Mar 16, 2022
1 Mar 16, 2022

FedMM: Saddle Point Optimization for Federated Adversarial Domain Adaptation
This repository contains the code accompanying the paper " FedMM: Saddle Point Optimization for Federated Adversarial Domain Adaptation" Paper link: R
 20 Jun 29, 2022
20 Jun 29, 2022
Source code for CAST - Crisis Domain Adaptation Using Sequence-to-sequence Transformers (Accepted to ISCRAM 2021, CorePaper).
Source code for CAST: Crisis Domain Adaptation UsingSequence-to-sequenceTransformers (Paper, BibTeX, Accepted to ISCRAM 2021, CorePaper) Quick start D
 0 Jul 14, 2021
0 Jul 14, 2021

Submodular Subset Selection for Active Domain Adaptation (ICCV 2021)
S3VAADA: Submodular Subset Selection for Virtual Adversarial Active Domain Adaptation ICCV 2021 Harsh Rangwani, Arihant Jain*, Sumukh K Aithal*, R. Ve
 13 Dec 28, 2022
13 Dec 28, 2022
L-SpEx: Localized Target Speaker Extraction
L-SpEx: Localized Target Speaker Extraction The data configuration and simulation of L-SpEx. The code scripts will be released in the future. Data Gen
 20 Jan 2, 2023
20 Jan 2, 2023

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: UniSpeech (ICML 2021): Unified Pre-training for Self-Supervised Learning and Supervised Learning for ASR UniSpeech-
 33 Oct 14, 2021
33 Oct 14, 2021

Multi-Target Adversarial Frameworks for Domain Adaptation in Semantic Segmentation
Multi-Target Adversarial Frameworks for Domain Adaptation in Semantic Segmentation Paper Multi-Target Adversarial Frameworks for Domain Adaptation in
 20 Jun 21, 2022
20 Jun 21, 2022
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation (NeurIPS2021 Benchmark and Dataset Track)
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation by Junjue Wang, Zhuo Zheng, Ailong Ma, Xiaoyan Lu, and Yanfei Zh
 174 Dec 22, 2022
174 Dec 22, 2022

Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation
Audio-Visual Generalized Few-Shot Learning with Prototype-Based Co-Adaptation The code repository for "Audio-Visual Generalized Few-Shot Learning with
 3 Jun 27, 2022
3 Jun 27, 2022

Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
 47 Dec 25, 2022
47 Dec 25, 2022

Transfer-Learn is an open-source and well-documented library for Transfer Learning.
Transfer-Learn is an open-source and well-documented library for Transfer Learning. It is based on pure PyTorch with high performance and friendly API. Our code is pythonic, and the design is consistent with torchvision. You can easily develop new algorithms, or readily apply existing algorithms.
 2.2k Jan 3, 2023
2.2k Jan 3, 2023

Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E. Evaluated on benchmark dataset Office31.
Deep-Unsupervised-Domain-Adaptation Pytorch implementation of four neural network based domain adaptation techniques: DeepCORAL, DDC, CDAN and CDAN+E.
 49 Dec 20, 2022
49 Dec 20, 2022

SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
SpeechNAS Better Trade off between Latency and Accuracy for Large Scale Speaker Verification
 24 May 20, 2022
24 May 20, 2022

Semi-supervised Domain Adaptation via Minimax Entropy
Semi-supervised Domain Adaptation via Minimax Entropy (ICCV 2019) Install pip install -r requirements.txt The code is written for Pytorch 0.4.0, but s
 243 Jan 9, 2023
243 Jan 9, 2023

A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
A Non-Autoregressive Transformer based TTS, supporting a family of SOTA transformers with supervised and unsupervised duration modelings. This project grows with the research community, aiming to achieve the ultimate TTS.
 237 Jan 2, 2023
237 Jan 2, 2023

PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
 1.8k Jan 8, 2023
1.8k Jan 8, 2023
Original implementation of the pooling method introduced in "Speaker embeddings by modeling channel-wise correlations"
Speaker-Embeddings-Correlation-Pooling This is the original implementation of the pooling method introduced in "Speaker embeddings by modeling channel
 10 Apr 30, 2022
10 Apr 30, 2022

Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
 187 Jan 6, 2023
187 Jan 6, 2023
Demo for the paper "Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation"
Streaming speaker diarization Overlap-aware low-latency online speaker diarization based on end-to-end local segmentation by Juan Manuel Coria, Hervé
185 Jan 1, 2023

RDA: Robust Domain Adaptation via Fourier Adversarial Attacking
RDA: Robust Domain Adaptation via Fourier Adversarial Attacking Updates 08/2021: check out our domain adaptation for video segmentation paper Domain A
 17 Nov 30, 2022
17 Nov 30, 2022

Classifying audio using Wavelet transform and deep learning
Audio Classification using Wavelet Transform and Deep Learning A step-by-step tutorial to classify audio signals using continuous wavelet transform (C
 17 Nov 29, 2022
17 Nov 29, 2022

Original code for "Zero-Shot Domain Adaptation with a Physics Prior"
Zero-Shot Domain Adaptation with a Physics Prior [arXiv] [sup. material] - ICCV 2021 Oral paper, by Attila Lengyel, Sourav Garg, Michael Milford and J
 40 Dec 21, 2022
40 Dec 21, 2022

A data annotation pipeline to generate high-quality, large-scale speech datasets with machine pre-labeling and fully manual auditing.
About This repository provides data and code for the paper: Scalable Data Annotation Pipeline for High-Quality Large Speech Datasets Development (subm
 86 Dec 7, 2022
86 Dec 7, 2022
Official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch.
Multi-speaker DGP This repository provides official implementation of deep Gaussian process (DGP)-based multi-speaker speech synthesis with PyTorch. O
 24 Sep 7, 2022
24 Sep 7, 2022

CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
 100 Dec 28, 2022
100 Dec 28, 2022
CrossNorm and SelfNorm for Generalization under Distribution Shifts (ICCV 2021)
CrossNorm (CN) and SelfNorm (SN) (Accepted at ICCV 2021) This is the official PyTorch implementation of our CNSN paper, in which we propose CrossNorm
100 Dec 28, 2022
Look Who’s Talking: Active Speaker Detection in the Wild
Look Who's Talking: Active Speaker Detection in the Wild Dependencies pip install -r requirements.txt In addition to the Python dependencies, ffmpeg
 60 Dec 8, 2022
60 Dec 8, 2022

Let Xiao Ai speakers control third-party devices
A stupid way to extend miot/xiaoai. Demo for Panasonic Bath Bully FV-RB20VL1 逆向 Panasonic Smart China,获得控制浴霸的请求信息(HTTP 请求),详见 apps/panasonic.py; 2. 通过
 14 Jul 7, 2022
14 Jul 7, 2022

IAST: Instance Adaptive Self-training for Unsupervised Domain Adaptation (ECCV 2020)
This repo is the official implementation of our paper "Instance Adaptive Self-training for Unsupervised Domain Adaptation". The purpose of this repo is to better communicate with you and respond to your questions. This repo is almost the same with Another-Version, and you can also refer to that version.
 84 Dec 12, 2022
84 Dec 12, 2022
[CVPR2021] Domain Consensus Clustering for Universal Domain Adaptation
[CVPR2021] Domain Consensus Clustering for Universal Domain Adaptation [Paper] Prerequisites To install requirements: pip install -r requirements.txt
 84 Dec 26, 2022
84 Dec 26, 2022

PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
Daft-Exprt - PyTorch Implementation PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis The
47 Dec 18, 2022

VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning
VisualGPT Our Paper VisualGPT: Data-efficient Adaptation of Pretrained Language Models for Image Captioning Main Architecture of Our VisualGPT Downloa
 140 Dec 28, 2022
140 Dec 28, 2022
neural network based speaker embedder
Content What is deepaudio-speaker? Installation Get Started Model Architecture How to contribute to deepaudio-speaker? Acknowledge What is deepaudio-s
 20 Dec 29, 2022
20 Dec 29, 2022
Unified unsupervised and semi-supervised domain adaptation network for cross-scenario face anti-spoofing, Pattern Recognition
USDAN The implementation of Unified unsupervised and semi-supervised domain adaptation network for cross-scenario face anti-spoofing, which is accepte
 11 Nov 3, 2022
11 Nov 3, 2022
code for ICCV 2021 paper 'Generalized Source-free Domain Adaptation'
G-SFDA Code (based on pytorch 1.3) for our ICCV 2021 paper 'Generalized Source-free Domain Adaptation'. [project] [paper]. Dataset preparing Download
 84 Dec 26, 2022
84 Dec 26, 2022
Byte-based multilingual transformer TTS for low-resource/few-shot language adaptation.
One model to speak them all 🌎 Audio Language Text ▷ Chinese 人人生而自由,在尊严和权利上一律平等。 ▷ English All human beings are born free and equal in dignity and rig
 60 Nov 14, 2022
60 Nov 14, 2022

🧠 A PyTorch implementation of 'Deep CORAL: Correlation Alignment for Deep Domain Adaptation.', ECCV 2016
Deep CORAL A PyTorch implementation of 'Deep CORAL: Correlation Alignment for Deep Domain Adaptation. B Sun, K Saenko, ECCV 2016' Deep CORAL can learn
 200 Dec 25, 2022
200 Dec 25, 2022

Implementation detail for paper "Multi-level colonoscopy malignant tissue detection with adversarial CAC-UNet"
Multi-level-colonoscopy-malignant-tissue-detection-with-adversarial-CAC-UNet Implementation detail for our paper "Multi-level colonoscopy malignant ti
84 Nov 22, 2022
PyTorch implementation of convolutional neural networks-based text-to-speech synthesis models
Deepvoice3_pytorch PyTorch implementation of convolutional networks-based text-to-speech synthesis models: arXiv:1710.07654: Deep Voice 3: Scaling Tex
1.8k Dec 30, 2022

Code for the ICML 2021 paper "Bridging Multi-Task Learning and Meta-Learning: Towards Efficient Training and Effective Adaptation", Haoxiang Wang, Han Zhao, Bo Li.
Bridging Multi-Task Learning and Meta-Learning Code for the ICML 2021 paper "Bridging Multi-Task Learning and Meta-Learning: Towards Efficient Trainin
 57 Dec 15, 2022
57 Dec 15, 2022

TalkNet: Audio-visual active speaker detection Model
Is someone talking? TalkNet: Audio-visual active speaker detection Model This repository contains the code for our ACM MM 2021 paper, TalkNet, an acti
 142 Dec 14, 2022
142 Dec 14, 2022

IJCAI2020 & IJCV 2020 :city_sunrise: Unsupervised Scene Adaptation with Memory Regularization in vivo
Seg_Uncertainty In this repo, we provide the code for the two papers, i.e., MRNet:Unsupervised Scene Adaptation with Memory Regularization in vivo, IJ
 348 Jan 5, 2023
348 Jan 5, 2023

PyTorch implementation of Densely Connected Time Delay Neural Network
Densely Connected Time Delay Neural Network PyTorch implementation of Densely Connected Time Delay Neural Network (D-TDNN) in our paper "Densely Conne
 64 Oct 11, 2022
64 Oct 11, 2022

Repository for the paper "Online Domain Adaptation for Occupancy Mapping", RSS 2020
RSS 2020 - Online Domain Adaptation for Occupancy Mapping Repository for the paper "Online Domain Adaptation for Occupancy Mapping", Robotics: Science
 26 Sep 22, 2022
26 Sep 22, 2022

Simplified diarization pipeline using some pretrained models - audio file to diarized segments in a few lines of code
simple_diarizer Simplified diarization pipeline using some pretrained models. Made to be a simple as possible to go from an input audio file to diariz
 65 Dec 30, 2022
65 Dec 30, 2022

(CVPR2021) DANNet: A One-Stage Domain Adaptation Network for Unsupervised Nighttime Semantic Segmentation
DANNet: A One-Stage Domain Adaptation Network for Unsupervised Nighttime Semantic Segmentation CVPR2021(oral) [arxiv] Requirements python3.7 pytorch==
 85 Dec 7, 2022
85 Dec 7, 2022
Use android as mic/speaker for ubuntu
Pulse Audio Control Panel Platforms Requirements sudo apt install ffmpeg pactl (already installed) Download Download the AppImage from release page ch
 19 Dec 1, 2022
19 Dec 1, 2022
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS)
This repository is an implementation of Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis (SV2TTS) with a vocoder that works in real-time. Feel free to check my thesis if you're curious or if you're looking for info I haven't documented. Mostly I would recommend giving a quick look to the figures beyond the introduction.
 38.5k Jan 3, 2023
38.5k Jan 3, 2023
![[ICML 2021] Break-It-Fix-It: Learning to Repair Programs from Unlabeled Data](https://github.com/michiyasunaga/BIFI/raw/main/figs/task.png)
[ICML 2021] Break-It-Fix-It: Learning to Repair Programs from Unlabeled Data
Break-It-Fix-It: Learning to Repair Programs from Unlabeled Data This repo provides the source code & data of our paper: Break-It-Fix-It: Unsupervised
 86 Nov 30, 2022
86 Nov 30, 2022
A PyTorch implementation for Unsupervised Domain Adaptation by Backpropagation(DANN), support Office-31 and Office-Home dataset
DANN A PyTorch implementation for Unsupervised Domain Adaptation by Backpropagation Prerequisites Linux or OSX NVIDIA GPU + CUDA (may CuDNN) and corre
 8 Apr 16, 2022
8 Apr 16, 2022

Official pytorch implement for “Transformer-Based Source-Free Domain Adaptation”
Official implementation for TransDA Official pytorch implement for “Transformer-Based Source-Free Domain Adaptation”. Overview: Result: Prerequisites:
 54 Dec 22, 2022
54 Dec 22, 2022

Code for "LoRA: Low-Rank Adaptation of Large Language Models"
LoRA: Low-Rank Adaptation of Large Language Models This repo contains the implementation of LoRA in GPT-2 and steps to replicate the results in our re
394 Jan 8, 2023

PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.13
140 Dec 21, 2022
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation
StyleSpeech - PyTorch Implementation PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation. Status (2021.06.09
142 Jan 6, 2023

The official codes of "Semi-supervised Models are Strong Unsupervised Domain Adaptation Learners".
SSL models are Strong UDA learners Introduction This is the official code of paper "Semi-supervised Models are Strong Unsupervised Domain Adaptation L
 26 Dec 26, 2022
26 Dec 26, 2022
code for our paper "Source Data-absent Unsupervised Domain Adaptation through Hypothesis Transfer and Labeling Transfer"
SHOT++ Code for our TPAMI submission "Source Data-absent Unsupervised Domain Adaptation through Hypothesis Transfer and Labeling Transfer" that is ext
 75 Dec 16, 2022
75 Dec 16, 2022
Code for CVPR2021 "Visualizing Adapted Knowledge in Domain Transfer". Visualization for domain adaptation. #explainable-ai
Visualizing Adapted Knowledge in Domain Transfer @inproceedings{hou2021visualizing, title={Visualizing Adapted Knowledge in Domain Transfer}, auth
 80 Dec 25, 2022
80 Dec 25, 2022

DIRL: Domain-Invariant Representation Learning
DIRL: Domain-Invariant Representation Learning Domain-Invariant Representation Learning (DIRL) is a novel algorithm that semantically aligns both the
 30 Nov 7, 2022
30 Nov 7, 2022

ERISHA is a mulitilingual multispeaker expressive speech synthesis framework. It can transfer the expressivity to the speaker's voice for which no expressive speech corpus is available.
ERISHA: Multilingual Multispeaker Expressive Text-to-Speech Library ERISHA is a multilingual multispeaker expressive speech synthesis framework. It ca
 43 Nov 27, 2022
43 Nov 27, 2022
MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Resolution (CVPR2021)
MASA-SR Official PyTorch implementation of our CVPR2021 paper MASA-SR: Matching Acceleration and Spatial Adaptation for Reference-Based Image Super-Re
 126 Dec 20, 2022
126 Dec 20, 2022
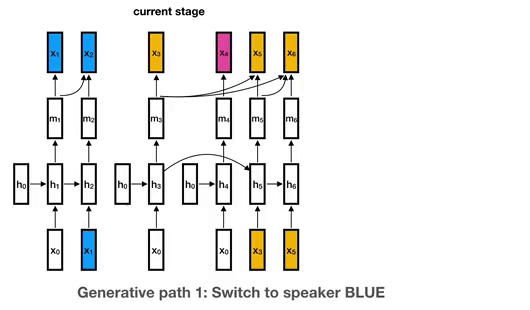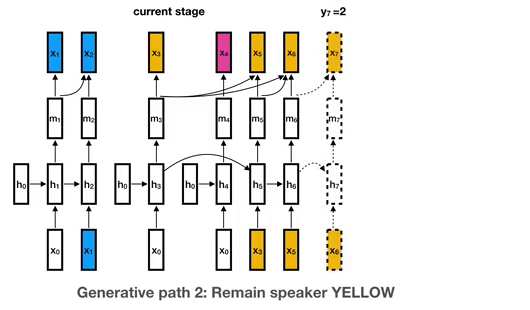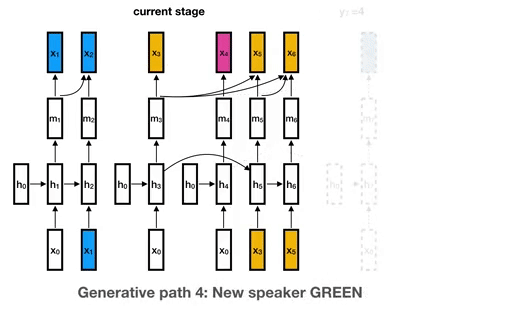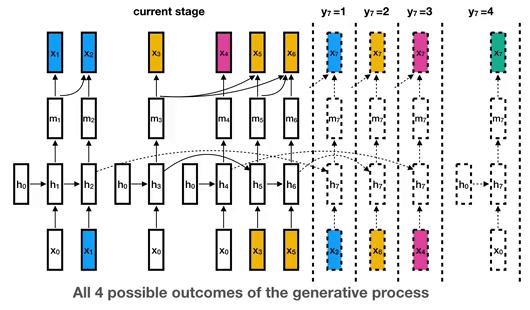
This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm, corresponding to the paper Fully Supervised Speaker Diarization.
UIS-RNN Overview This is the library for the Unbounded Interleaved-State Recurrent Neural Network (UIS-RNN) algorithm. UIS-RNN solves the problem of s
 1.4k Dec 28, 2022
1.4k Dec 28, 2022
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
 2.2k Jan 9, 2023
2.2k Jan 9, 2023

(CVPR 2021) ST3D: Self-training for Unsupervised Domain Adaptation on 3D Object Detection
ST3D Code release for the paper ST3D: Self-training for Unsupervised Domain Adaptation on 3D Object Detection, CVPR 2021 Authors: Jihan Yang*, Shaoshu
 224 Dec 28, 2022
224 Dec 28, 2022

Self-Supervised Learning for Domain Adaptation on Point-Clouds
Self-Supervised Learning for Domain Adaptation on Point-Clouds Introduction Self-supervised learning (SSL) allows to learn useful representations from
 66 Dec 20, 2022
66 Dec 20, 2022
ICLR21 Tent: Fully Test-Time Adaptation by Entropy Minimization
⛺️ Tent: Fully Test-Time Adaptation by Entropy Minimization This is the official project repository for Tent: Fully-Test Time Adaptation by Entropy Mi
 204 Dec 25, 2022
204 Dec 25, 2022

Official repository for Few-shot Image Generation via Cross-domain Correspondence (CVPR '21)
Few-shot Image Generation via Cross-domain Correspondence Utkarsh Ojha, Yijun Li, Jingwan Lu, Alexei A. Efros, Yong Jae Lee, Eli Shechtman, Richard Zh
 251 Dec 11, 2022
251 Dec 11, 2022
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model Edresson Casanova, Christopher Shulby, Eren Gölge, Nicolas Michael Müller, Frede
 92 Dec 9, 2022
92 Dec 9, 2022

TTS is a library for advanced Text-to-Speech generation.
TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality. TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.
 6.5k Jan 8, 2023
6.5k Jan 8, 2023

Code for HLA-Face: Joint High-Low Adaptation for Low Light Face Detection (CVPR21)
HLA-Face: Joint High-Low Adaptation for Low Light Face Detection The official PyTorch implementation for HLA-Face: Joint High-Low Adaptation for Low L
 77 Dec 8, 2022
77 Dec 8, 2022
POT : Python Optimal Transport
This open source Python library provide several solvers for optimization problems related to Optimal Transport for signal, image processing and machine learning.
 1.7k Jan 4, 2023
1.7k Jan 4, 2023

PyTorch code for the paper "Curriculum Graph Co-Teaching for Multi-target Domain Adaptation" (CVPR2021)
PyTorch code for the paper "Curriculum Graph Co-Teaching for Multi-target Domain Adaptation" (CVPR2021) This repo presents PyTorch implementation of M
 79 Dec 19, 2022
79 Dec 19, 2022
Adversarial Adaptation with Distillation for BERT Unsupervised Domain Adaptation
Knowledge Distillation for BERT Unsupervised Domain Adaptation Official PyTorch implementation | Paper Abstract A pre-trained language model, BERT, ha
 29 Nov 30, 2022
29 Nov 30, 2022

Code to reproduce the experiments in the paper "Transformer Based Multi-Source Domain Adaptation" (EMNLP 2020)
Transformer Based Multi-Source Domain Adaptation Dustin Wright and Isabelle Augenstein To appear in EMNLP 2020. Read the preprint: https://arxiv.org/a
 36 Dec 5, 2022
36 Dec 5, 2022

Code release for "Transferable Semantic Augmentation for Domain Adaptation" (CVPR 2021)
Transferable Semantic Augmentation for Domain Adaptation Code release for "Transferable Semantic Augmentation for Domain Adaptation" (CVPR 2021) Paper
 66 Dec 16, 2022
66 Dec 16, 2022

Progressive Domain Adaptation for Object Detection
Progressive Domain Adaptation for Object Detection Implementation of our paper Progressive Domain Adaptation for Object Detection, based on pytorch-fa
 96 Nov 25, 2022
96 Nov 25, 2022

Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation (CVPR 2021)
Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation (CVPR 2021, official Pytorch implementatio
247 Dec 25, 2022
kaldi-asr/kaldi is the official location of the Kaldi project.
Kaldi Speech Recognition Toolkit To build the toolkit: see ./INSTALL. These instructions are valid for UNIX systems including various flavors of Linux
 12.3k Jan 5, 2023
12.3k Jan 5, 2023
TensorFlowTTS: Real-Time State-of-the-art Speech Synthesis for Tensorflow 2 (supported including English, Korean, Chinese, German and Easy to adapt for other languages)
🤪 TensorFlowTTS provides real-time state-of-the-art speech synthesis architectures such as Tacotron-2, Melgan, Multiband-Melgan, FastSpeech, FastSpeech2 based-on TensorFlow 2. With Tensorflow 2, we can speed-up training/inference progress, optimizer further by using fake-quantize aware and pruning, make TTS models can be run faster than real-time and be able to deploy on mobile devices or embedded systems.
 3k Jan 4, 2023
3k Jan 4, 2023
POT : Python Optimal Transport
POT: Python Optimal Transport This open source Python library provide several solvers for optimization problems related to Optimal Transport for signa
1.7k Dec 31, 2022
Conference planning tool: CfP, scheduling, speaker management
pretalx is a conference planning tool focused on providing the best experience for organisers, speakers, reviewers, and attendees alike. It handles th
 496 Dec 31, 2022
496 Dec 31, 2022
Conference planning tool: CfP, scheduling, speaker management
pretalx is a conference planning tool focused on providing the best experience for organisers, speakers, reviewers, and attendees alike. It handles th
492 Dec 28, 2022

Transfer SemanticKITTI labeles into other dataset/sensor formats.
LiDAR-Transfer Transfer SemanticKITTI labeles into other dataset/sensor formats. Content Convert datasets (NUSCENES, FORD, NCLT) to KITTI format Minim
 64 Nov 21, 2022
64 Nov 21, 2022
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
 1.4k Feb 17, 2021
1.4k Feb 17, 2021
Neural building blocks for speaker diarization: speech activity detection, speaker change detection, overlapped speech detection, speaker embedding
⚠️ Checkout develop branch to see what is coming in pyannote.audio 2.0: a much smaller and cleaner codebase Python-first API (the good old pyannote-au
2.1k Dec 31, 2022
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
1.5k Dec 26, 2022
Lightweight data validation and adaptation Python library.
Valideer Lightweight data validation and adaptation library for Python. At a Glance: Supports both validation (check if a value is valid) and adaptati
 258 Nov 22, 2022
258 Nov 22, 2022
CrossNER: Evaluating Cross-Domain Named Entity Recognition (AAAI-2021)
CrossNER is a fully-labeled collected of named entity recognition (NER) data spanning over five diverse domains (Politics, Natural Science, Music, Literature, and Artificial Intelligence) with specialized entity categories for different domains.
 89 Nov 10, 2022
89 Nov 10, 2022