569 Repositories
Python speech-style Libraries

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022
TensorFlow 101: Introduction to Deep Learning for Python Within TensorFlow
TensorFlow 101: Introduction to Deep Learning I have worked all my life in Machine Learning, and I've never seen one algorithm knock over its benchmar
 896 Jan 4, 2023
896 Jan 4, 2023

U-2-Net: U Square Net - Modified for paired image training of style transfer
U2-Net: U Square Net Modified for paired image training of style transfer This is an unofficial repo making use of the code which was made available b
 43 Oct 3, 2022
43 Oct 3, 2022

VQMIVC - Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice Conversion (Interspeech
 262 Dec 31, 2022
262 Dec 31, 2022

Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning
Unet-TTS: Improving Unseen Speaker and Style Transfer in One-shot Voice Cloning English | 中文 ❗ Now we provide inferencing code and pre-training models
 164 Jan 2, 2023
164 Jan 2, 2023

SpecAugmentPyTorch - A Pytorch (support batch and channel) implementation of GoogleBrain's SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
SpecAugment An implementation of SpecAugment for Pytorch How to use Install pytorch, version=1.9.0 (new feature (torch.Tensor.take_along_dim) is used
 3 Oct 11, 2022
3 Oct 11, 2022

The codebase for Data-driven general-purpose voice activity detection.
Data driven GPVAD Repository for the work in TASLP 2021 Voice activity detection in the wild: A data-driven approach using teacher-student training. S
 75 Nov 27, 2022
75 Nov 27, 2022
基于百度的语音识别,用python实现,pyaudio+pyqt
Speech-recognition 基于百度的语音识别,python3.8(conda)+pyaudio+pyqt+baidu-aip 百度有面向python
 1 Jan 3, 2022
1 Jan 3, 2022
A retro text-to-speech bot for Discord
hawking A retro text-to-speech bot for Discord, designed to work with all of the stuff you might've seen in Moonbase Alpha, using the existing command
 23 Dec 25, 2022
23 Dec 25, 2022
Autoregressive Predictive Coding: An unsupervised autoregressive model for speech representation learning
Autoregressive Predictive Coding This repository contains the official implementation (in PyTorch) of Autoregressive Predictive Coding (APC) proposed
 173 Dec 18, 2022
173 Dec 18, 2022

HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis Jungil Kong, Jaehyeon Kim, Jaekyoung Bae In our paper, we p
 1.1k Jan 2, 2023
1.1k Jan 2, 2023

🚀Clone a voice in 5 seconds to generate arbitrary speech in real-time
English | 中文 Features 🌍 Chinese supported mandarin and tested with multiple datasets: aidatatang_200zh, magicdata, aishell3, data_aishell, and etc. ?
 25.6k Dec 31, 2022
25.6k Dec 31, 2022
A deep learning model for style-specific music generation.
DeepJ: A model for style-specific music generation https://arxiv.org/abs/1801.00887 Abstract Recent advances in deep neural networks have enabled algo
 704 Nov 23, 2022
704 Nov 23, 2022
Generates images with semantic content from distribution A in the style of distribution B
A2B Generates images with semantic content from distribution A in the style of d
 2 Dec 27, 2021
2 Dec 27, 2021
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger
Part of Speech Tagging using Hidden Markov Model (HMM) POS Tagger and Brill Tagger In this project, our aim is to tune, compare, and contrast the perf
 0 Dec 25, 2021
0 Dec 25, 2021
The ability of computer software to identify words and phrases in spoken language and convert them to human-readable text
speech-recognition-py Speech recognition is the ability of computer software to identify words and phrases in spoken language and convert them to huma
 1 Apr 3, 2022
1 Apr 3, 2022

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022
CSP-style concurrency for Python
aiochan Aiochan is a library written to bring the wonderful idiom of CSP-style concurrency to python. The implementation is based on the battle-tested
 127 Dec 23, 2022
127 Dec 23, 2022
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
talkbox is a scikit for signal/speech processing, to extend scipy capabilities in that domain.
 76 Nov 30, 2022
76 Nov 30, 2022
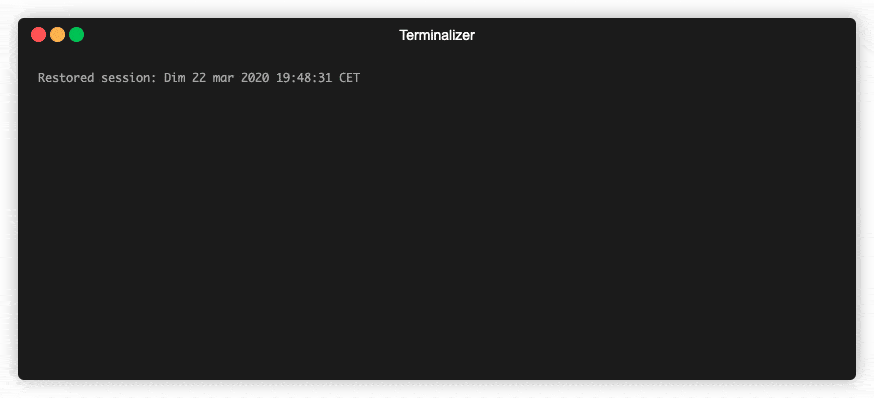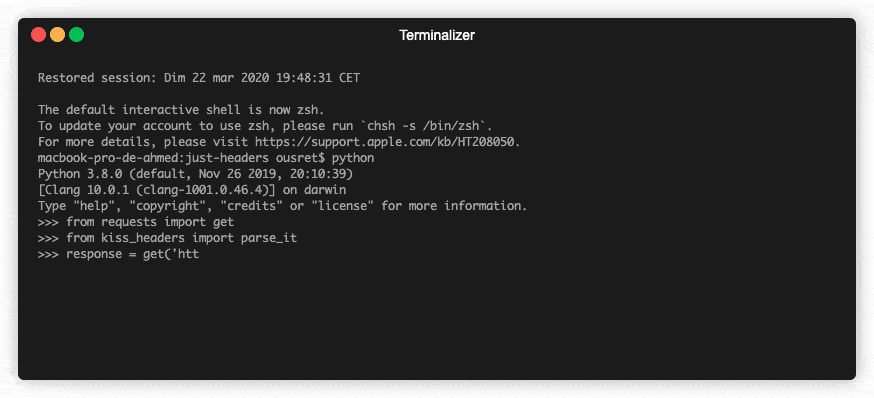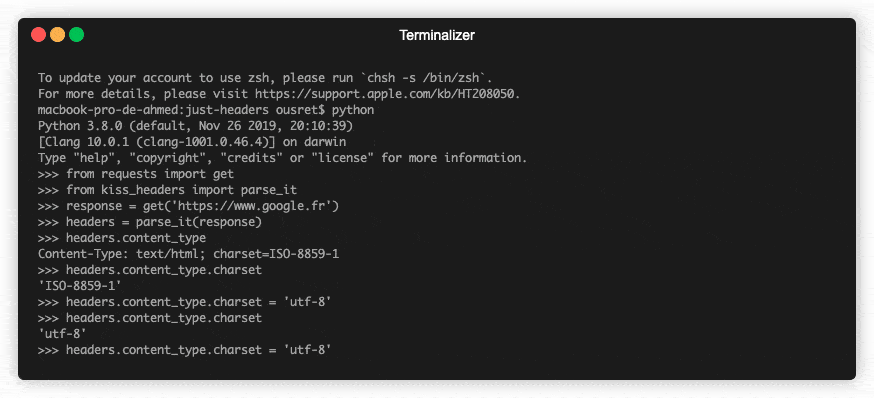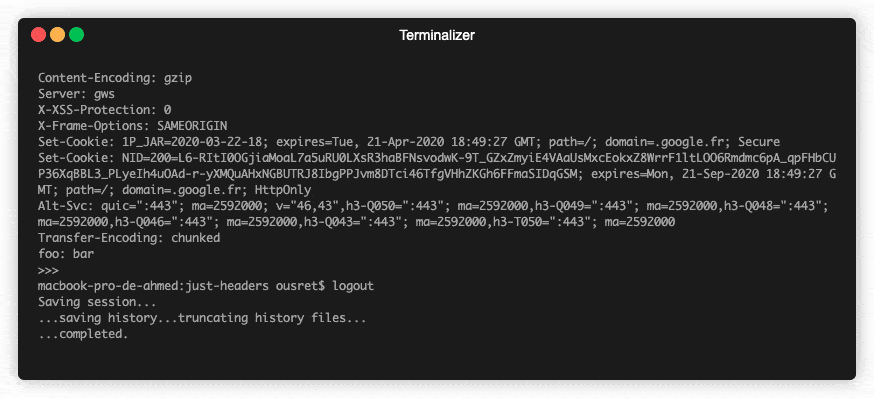
💡Python package for HTTP/1.1 style headers. Parse headers to objects. Most advanced available structure for http headers.
HTTP Headers, the Complete Toolkit 🧰 Object-oriented headers. Kind of structured headers. ❓ Why No matter if you are currently dealing with code usin
 103 Dec 2, 2022
103 Dec 2, 2022

Prososdy Morph: A python library for manipulating pitch and duration in an algorithmic way, for resynthesizing speech.
ProMo (Prosody Morph) Questions? Comments? Feedback? Chat with us on gitter! A library for manipulating pitch and duration in an algorithmic way, for
 71 Jan 2, 2023
71 Jan 2, 2023
This is an app for creating your own color scheme for Termux!
Termux Terminal Theme Creator [WIP] If you need help on how to use the program, you can either create a GitHub issue or join this temporary Discord se
 3 Dec 31, 2022
3 Dec 31, 2022
Reproducing code of hair style replacement method from Barbershorp.
Barbershorp Reproducing code of hair style replacement method from Barbershorp. Also reproduces II2S, an improved version of Image2StyleGAN. Requireme
 1 Dec 24, 2021
1 Dec 24, 2021
Wonderful Phoenix-Bot
Phoenix Bot Discord Phoenix Bot is inspired by Natewong1313's Bird Bot project yet due to lack of activity by their team. We have decided to revive th
 0 Aug 12, 2021
0 Aug 12, 2021

A inspector to be able to view and edit Qt style sheet while an application is running
Qt Style Sheet Inspector An inspector widget to view and modify the style sheet of a Qt app at runtime. Usage In order to use the inspector widget on
 46 Dec 10, 2022
46 Dec 10, 2022
Utility for Google Text-To-Speech batch audio files generator. Ideal for prompt files creation with Google voices for application in offline IVRs
Google Text-To-Speech Batch Prompt File Maker Are you in the need of IVR prompts, but you have no voice actors? Let Google talk your prompts like a pr
 1 Aug 19, 2021
1 Aug 19, 2021

ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python)
ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python) 日本語は以下に続きます (Japanese follows) English: This book is written in Japanese and primaril
 189 Dec 29, 2022
189 Dec 29, 2022

A few stylization coreML models that I've trained with CreateML
CoreML-StyleTransfer A few stylization coreML models that I've trained with CreateML You can open and use the .mlmodel files in the "models" folder in
8 Aug 18, 2022
WordPress-style shortcodes for Python
Python Shortcodes WordPress-style shortcodes for Python Create and use WordPress-style shortcodes in your Python based app. Example # static output de
 1 Dec 22, 2021
1 Dec 22, 2021
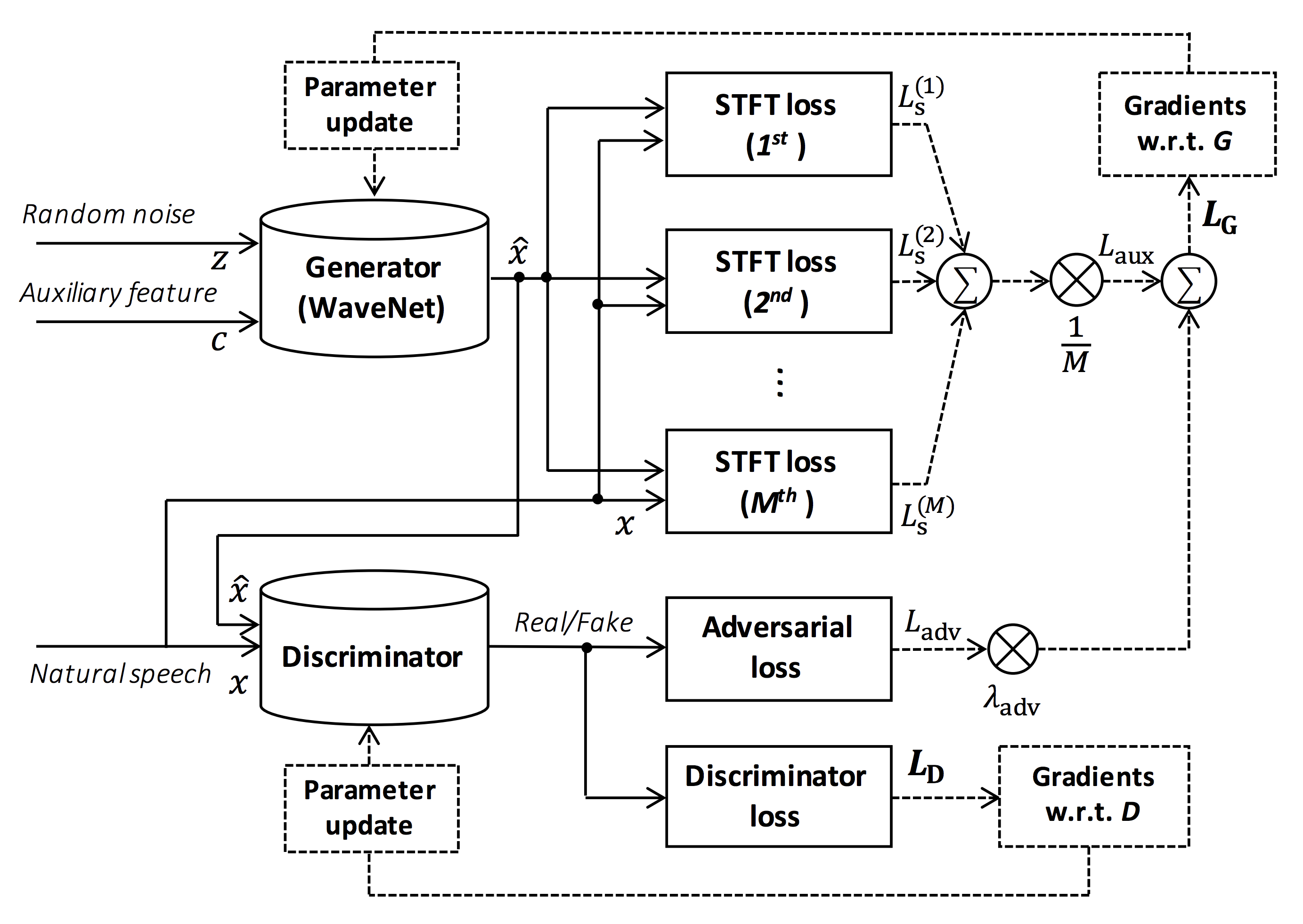
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022

Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition"
Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition" Pre-trained Deep Convo
 5 Nov 11, 2022
5 Nov 11, 2022

This is a really simple text-to-speech app made with python and tkinter.
Tkinter Text-to-Speech App by Souvik Roy This is a really simple tkinter app which converts the text you have entered into a speech. It is created wit
 1 Dec 21, 2021
1 Dec 21, 2021
A Python module made to simplify the usage of Text To Speech and Speech Recognition.
Nav Module The solution for voice related stuff in Python Nav is a Python module which simplifies voice related stuff in Python. Just import the Modul
 1 Dec 20, 2021
1 Dec 20, 2021

DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022; Official code
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
 803 Dec 28, 2022
803 Dec 28, 2022

J.A.R.V.I.S is an AI virtual assistant made in python.
J.A.R.V.I.S is an AI virtual assistant made in python. Running JARVIS Without Python To run JARVIS without python: 1. Head over to our installation pa
 16 Dec 29, 2022
16 Dec 29, 2022

TensorFlow (Python API) implementation of Neural Style
neural-style-tf This is a TensorFlow implementation of several techniques described in the papers: Image Style Transfer Using Convolutional Neural Net
 3.1k Jan 2, 2023
3.1k Jan 2, 2023
Wav2Vec for speech recognition, classification, and audio classification
Soxan در زبان پارسی به نام سخن This repository consists of models, scripts, and notebooks that help you to use all the benefits of Wav2Vec 2.0 in your
 140 Dec 15, 2022
140 Dec 15, 2022
Arabic speech recognition, classification and text-to-speech.
klaam Arabic speech recognition, classification and text-to-speech using many advanced models like wave2vec and fastspeech2. This repository allows tr
 177 Dec 27, 2022
177 Dec 27, 2022
Contains links to publicly available datasets for modeling health outcomes using speech and language.
speech-nlp-datasets Contains links to publicly available datasets for modeling various health outcomes using speech and language. Speech-based Corpora
 77 Dec 7, 2022
77 Dec 7, 2022

Create light scenes , voice control, ifttt, fuzzywuzzy speech correction and much more with Tuya light bulbs.
LightBox Features: Auto discover tuya lights Set and create moods (aka: light profiles) Change moods via IFTTT List moods via IFTTT FuzzyWuzzy, speech
 1 Dec 20, 2021
1 Dec 20, 2021
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
829 Jan 7, 2023
🤗 Paper Style Guide
🤗 Paper Style Guide (Work in progress, send a PR!) Libraries to Know booktabs natbib cleveref Either seaborn, plotly or altair for graphs algorithmic
 66 Dec 12, 2022
66 Dec 12, 2022
![An end-to-end library for editing and rendering motion of 3D characters with deep learning [SIGGRAPH 2020]](https://github.com/DeepMotionEditing/deep-motion-editing/raw/master/images/retargeting_teaser.gif)
An end-to-end library for editing and rendering motion of 3D characters with deep learning [SIGGRAPH 2020]
Deep-motion-editing This library provides fundamental and advanced functions to work with 3D character animation in deep learning with Pytorch. The co
 1.2k Dec 29, 2022
1.2k Dec 29, 2022

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: WavLM (arXiv): WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing UniSpeech (ICML 202
 281 Dec 15, 2022
281 Dec 15, 2022
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
Malaya-Speech is a Speech-Toolkit library for bahasa Malaysia, powered by Deep Learning Tensorflow.
Malaya-Speech is a Speech-Toolkit library for bahasa Malaysia, powered by Deep Learning Tensorflow. Documentation Proper documentation is available at
 151 Jan 5, 2023
151 Jan 5, 2023
Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks
wav2vec_finetune Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks Initial test: gender recognition on this dat
 8 Aug 11, 2022
8 Aug 11, 2022
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
77.1k Dec 31, 2022
An implementation of model parallel GPT-2 and GPT-3-style models using the mesh-tensorflow library.
GPT Neo 🎉 1T or bust my dudes 🎉 An implementation of model & data parallel GPT3-like models using the mesh-tensorflow library. If you're just here t
 6.7k Dec 28, 2022
6.7k Dec 28, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023
A web application using [FastAPI + streamlit + Docker] Neural Style Transfer (NST) refers to a class of software algorithms that manipulate digital images
Neural Style Transfer Web App - [FastAPI + streamlit + Docker] NST - application based on the Perceptual Losses for Real-Time Style Transfer and Super
 3 Dec 5, 2022
3 Dec 5, 2022
Pytorch implementation NORESQA A Framework for Speech Quality Assessment using Non-Matching References.
NORESQA: Speech Quality Assessment using Non-Matching References This is a Pytorch implementation for using NORESQA. It contains minimal code to predi
 11 Dec 14, 2021
11 Dec 14, 2021
CYGNUS, the Cynical AI, combines snarky responses with uncanny aggression.
New & (hopefully) Improved CYGNUS with several API updates, user updates, and online/offline operations added!!!
 0 Mar 28, 2022
0 Mar 28, 2022

A voice assistant which can be used to interact with your computer and controls your pc operations
Introduction 👨💻 It is a voice assistant which can be used to interact with your computer and also you have been seeing it in Iron man movies, but t
 84 Dec 22, 2022
84 Dec 22, 2022
A Munch is a Python dictionary that provides attribute-style access (a la JavaScript objects).
munch munch is a fork of David Schoonover's Bunch package, providing similar functionality. 99% of the work was done by him, and the fork was made mai
 643 Jan 7, 2023
643 Jan 7, 2023

TensorFlow CNN for fast style transfer
Fast Style Transfer in TensorFlow Add styles from famous paintings to any photo in a fraction of a second! It takes 100ms on a 2015 Titan X to style t
 1 Dec 14, 2021
1 Dec 14, 2021
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022
 519 Dec 30, 2022
519 Dec 30, 2022
A tool for creating Toontown-style nametags in Panda3D
Toontown-Nametag Toontown-Nametag is a tool for creating Toontown Online/Toontown Rewritten-style nametags in Panda3D. It contains a function, createN
 2 Dec 23, 2021
2 Dec 23, 2021
A complete speech segmentation system using Kaldi and x-vectors for voice activity detection (VAD) and speaker diarisation.
bbc-speech-segmenter: Voice Activity Detection & Speaker Diarization A complete speech segmentation system using Kaldi and x-vectors for voice activit
 16 Oct 27, 2022
16 Oct 27, 2022
Code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language"
The repository provides the source code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language" submitted to HA
 3 Aug 4, 2022
3 Aug 4, 2022
(AAAI2022) Style Mixing and Patchwise Prototypical Matching for One-Shot Unsupervised Domain Adaptive Semantic Segmentation
SM-PPM This is a Pytorch implementation of our paper "Style Mixing and Patchwise Prototypical Matching for One-Shot Unsupervised Domain Adaptive Seman
 10 Dec 7, 2022
10 Dec 7, 2022

Simple Tensorflow implementation of "Adaptive Convolutions for Structure-Aware Style Transfer" (CVPR 2021)
AdaConv — Simple TensorFlow Implementation [Paper] : Adaptive Convolutions for Structure-Aware Style Transfer (CVPR 2021) Note This repository does no
 26 Nov 18, 2022
26 Nov 18, 2022

PyTorch implementation of our paper: "Artistic Style Transfer with Internal-external Learning and Contrastive Learning"
Artistic Style Transfer with Internal-external Learning and Contrastive Learning This is the official PyTorch implementation of our paper: "Artistic S
 19 Dec 10, 2021
19 Dec 10, 2021
The world's largest toxicity dataset.
The Toxicity Dataset by Surge AI Saving the internet is fun. Combing through thousands of online comments to build a toxicity dataset isn't. That's wh
 134 Dec 19, 2022
134 Dec 19, 2022
An end to end ASR Transformer model training repo
END TO END ASR TRANSFORMER 本项目基于transformer 6*encoder+6*decoder的基本结构构造的端到端的语音识别系统 Model Instructions 1.数据准备: 自行下载数据,遵循文件结构如下: ├── data │ ├── train │
 10 Jul 19, 2022
10 Jul 19, 2022
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone In our recent paper we propose the YourTTS model. YourTTS bri
 390 Dec 29, 2022
390 Dec 29, 2022

Neural style in TensorFlow! 🎨
neural-style An implementation of neural style in TensorFlow. This implementation is a lot simpler than a lot of the other ones out there, thanks to T
 5.5k Dec 29, 2022
5.5k Dec 29, 2022
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks - Official Project Page This repository contains the code develope
 1.7k Dec 18, 2022
1.7k Dec 18, 2022
This github repo is for Neurips 2021 paper, NORESQA A Framework for Speech Quality Assessment using Non-Matching References.
NORESQA: Speech Quality Assessment using Non-Matching References This is a Pytorch implementation for using NORESQA. It contains minimal code to predi
36 Dec 8, 2022
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
 76 Dec 30, 2022
76 Dec 30, 2022

Self-Supervised Generative Style Transfer for One-Shot Medical Image Segmentation
Self-Supervised Generative Style Transfer for One-Shot Medical Image Segmentation This repository contains the Pytorch implementation of the proposed
 19 Nov 10, 2022
19 Nov 10, 2022

Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
 47 Dec 25, 2022
47 Dec 25, 2022

SingleVC performs any-to-one VC, which is an important component of MediumVC project.
SingleVC performs any-to-one VC, which is an important component of MediumVC project. Here is the official implementation of the paper, MediumVC.
26 Dec 28, 2022

Implementation of Google Brain's WaveGrad high-fidelity vocoder
WaveGrad Implementation (PyTorch) of Google Brain's high-fidelity WaveGrad vocoder (paper). First implementation on GitHub with high-quality generatio
 363 Dec 27, 2022
363 Dec 27, 2022
DiffWave is a fast, high-quality neural vocoder and waveform synthesizer.
DiffWave DiffWave is a fast, high-quality neural vocoder and waveform synthesizer. It starts with Gaussian noise and converts it into speech via itera
 498 Jan 3, 2023
498 Jan 3, 2023
Neural HMMs are all you need (for high-quality attention-free TTS)
Neural HMMs are all you need (for high-quality attention-free TTS) Shivam Mehta, Éva Székely, Jonas Beskow, and Gustav Eje Henter This is the official
 0 Oct 28, 2022
0 Oct 28, 2022

Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition"
CLIPstyler Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition" Environment Pytorch 1.7.1, Python 3.6 $ c
 201 Dec 29, 2022
201 Dec 29, 2022

End-2-end speech synthesis with recurrent neural networks
Introduction New: Interactive demo using Google Colaboratory can be found here TTS-Cube is an end-2-end speech synthesis system that provides a full p
 214 Dec 7, 2022
214 Dec 7, 2022

Text to speech for Vietnamese, ez to use, ez to update
Chào mọi người, đây là dự án mở nhằm giúp việc đọc được trở nên dễ dàng hơn. Rất cảm ơn đội ngũ Zalo đã cung cấp hạ tầng để mình có thể tạo ra app này
 32 Jul 29, 2022
32 Jul 29, 2022
An 16kHz implementation of HiFi-GAN for soft-vc.
HiFi-GAN An 16kHz implementation of HiFi-GAN for soft-vc. Relevant links: Official HiFi-GAN repo HiFi-GAN paper Soft-VC repo Soft-VC paper Example Usa
 42 Dec 27, 2022
42 Dec 27, 2022
Simple Python library, distributed via binary wheels with few direct dependencies, for easily using wav2vec 2.0 models for speech recognition
Wav2Vec2 STT Python Beta Software Simple Python library, distributed via binary wheels with few direct dependencies, for easily using wav2vec 2.0 mode
 22 Dec 29, 2022
22 Dec 29, 2022
Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition"
CLIPstyler Official Pytorch implementation of "CLIPstyler:Image Style Transfer with a Single Text Condition" Environment Pytorch 1.7.1, Python 3.6 $ c
203 Dec 30, 2022
BERTAC (BERT-style transformer-based language model with Adversarially pretrained Convolutional neural network)
BERTAC (BERT-style transformer-based language model with Adversarially pretrained Convolutional neural network) BERTAC is a framework that combines a
 6 Jan 24, 2022
6 Jan 24, 2022
This is the official PyTorch implementation of our paper: "Artistic Style Transfer with Internal-external Learning and Contrastive Learning".
Artistic Style Transfer with Internal-external Learning and Contrastive Learning This is the official PyTorch implementation of our paper: "Artistic S
51 Dec 20, 2022

Official Implementation for Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation We present a generic image-to-image translation framework, pixel2style2pixel (pSp
 2.8k Dec 30, 2022
2.8k Dec 30, 2022
IBD Style Relative Strength Percentile Ranking of Stocks (i.e. 0-100 Score).
relative-strength IBD Style Relative Strength Percentile Ranking of Stocks (i.e. 0-100 Score). I also made a TradingView indicator, but it cannot give
 57 Jan 6, 2023
57 Jan 6, 2023

Official Implementation of SWAGAN: A Style-based Wavelet-driven Generative Model
Official Implementation of SWAGAN: A Style-based Wavelet-driven Generative Model SWAGAN: A Style-based Wavelet-driven Generative Model Rinon Gal, Dana
 55 Dec 6, 2022
55 Dec 6, 2022
Combine Tacotron2 and Hifi GAN to generate speech from text
EndToEndTextToSpeech Combine Tacotron2 and Hifi GAN to generate speech from text Download weights Hifi GAN - hifi_gan/checkpoint/ : pretrain 2.5M ste
 1 Dec 18, 2021
1 Dec 18, 2021

Conversational text Analysis using various NLP techniques
PyConverse Let me try first Installation pip install pyconverse Usage Please try this notebook that demos the core functionalities: basic usage noteb
 158 Dec 25, 2022
158 Dec 25, 2022
Simple virtual assistant using pyttsx3 and speech recognition optionally with pywhatkit and pther libraries.
VirtualAssistant Simple virtual assistant using pyttsx3 and speech recognition optionally with pywhatkit and pther libraries. Third Party Libraries us
 1 Nov 27, 2021
1 Nov 27, 2021
Text-to-Speech for Belarusian language
title emoji colorFrom colorTo sdk app_file pinned Belarusian TTS 🐸 green green gradio app.py false Belarusian TTS 📢 🤖 Belarusian TTS (text-to-speec
 1 Nov 27, 2021
1 Nov 27, 2021
This program will stylize your photos with fast neural style transfer.
Neural Style Transfer (NST) Using TensorFlow Demo TensorFlow TensorFlow is an end-to-end open source platform for machine learning. It has a comprehen
 1 Aug 8, 2022
1 Aug 8, 2022

A python gui program to generate reddit text to speech videos from the id of any post.
Reddit text to speech generator A python gui program to generate reddit text to speech videos from the id of any post. Current functionality Generate
 17 Dec 19, 2022
17 Dec 19, 2022
Romanian Automatic Speech Recognition from the ROBIN project
RobinASR This repository contains Robin's Automatic Speech Recognition (RobinASR) for the Romanian language based on the DeepSpeech2 architecture, tog
 10 Jan 1, 2023
10 Jan 1, 2023

Repository for paper "Non-intrusive speech intelligibility prediction from discrete latent representations"
Non-Intrusive Speech Intelligibility Prediction from Discrete Latent Representations Official repository for paper "Non-Intrusive Speech Intelligibili
 5 Oct 25, 2022
5 Oct 25, 2022

The project is associated with the recently-launched ICASSP 2022 Multi-channel Multi-party Meeting Transcription Challenge (M2MeT) to provide participants with baseline systems for speech recognition and speaker diarization in conference scenario.
M2MeT challenge baseline -- AliMeeting This project provides the baseline system recipes for the ICASSP 2020 Multi-channel Multi-party Meeting Transcr
 81 Dec 8, 2022
81 Dec 8, 2022
Fast style transfer
faststyle Faststyle aims to provide an easy and modular interface to Image to Image problems based on feature loss. Install Making sure you have a wor
 21 Mar 11, 2022
21 Mar 11, 2022
Domain Generalization for Mammography Detection via Multi-style and Multi-view Contrastive Learning
MSVCL_MICCAI2021 Installation Please follow the instruction in pytorch-CycleGAN-and-pix2pix to install. Example Usage An example of vendor-styles tran
 11 Oct 19, 2022
11 Oct 19, 2022