569 Repositories
Python speech-style Libraries

Efficient Speech Processing Tookit for Automatic Speaker Recognition
Sugar Efficient Speech Processing Tookit for Automatic Speaker Recognition | HuggingFace | What's New EfficientTDNN: Efficient Architecture Search for
 14 Sep 14, 2022
14 Sep 14, 2022
A simple python oriented telegram bot to give out creative font style's
Font-Bot A simple python oriented telegram bot to give out creative font style's REQUIREMENTS tgcrypto pyrogram==1.2.9 Installation Fork this reposito
 4 Jan 30, 2022
4 Jan 30, 2022
German Text-To-Speech Engine using Tacotron and Griffin-Lim
jotts JoTTS is a German text-to-speech engine using tacotron and griffin-lim. The synthesizer model has been trained on my voice using Tacotron1. Due
 6 Aug 28, 2022
6 Aug 28, 2022
Learning Neural Painters Fast! using PyTorch and Fast.ai
The Joy of Neural Painting Learning Neural Painters Fast! using PyTorch and Fast.ai Blogpost with more details: The Joy of Neural Painting The impleme
 72 Nov 10, 2022
72 Nov 10, 2022
A module to develop and apply old-style links
Old-Linkage-Dev (OLD) Old Linkage Development is a module to develop and apply old-style links. Old-style links stand for some traditional or conventi
 2 Dec 4, 2021
2 Dec 4, 2021

This script runs neural style transfer against the provided content image.
Neural Style Transfer Content Style Output Description: This script runs neural style transfer against the provided content image. The content image m
 0 Nov 25, 2021
0 Nov 25, 2021

Keras Implementation of Neural Style Transfer from the paper "A Neural Algorithm of Artistic Style"
Neural Style Transfer & Neural Doodles Implementation of Neural Style Transfer from the paper A Neural Algorithm of Artistic Style in Keras 2.0+ INetw
 2.2k Dec 31, 2022
2.2k Dec 31, 2022
A desktop GUI providing an audio interface for GPT3.
Jabberwocky neil_degrasse_tyson_with_audio.mp4 Project Description This GUI provides an audio interface to GPT-3. My main goal was to provide a conven
 16 Nov 27, 2022
16 Nov 27, 2022
JavaScript-style async programming for Python.
promisio JavaScript-style async programming for Python. Examples Create a promise-based async function using the promisify decorator. It works on both
 191 Dec 30, 2022
191 Dec 30, 2022

PyTorch implementation of our ICCV 2021 paper Intrinsic-Extrinsic Preserved GANs for Unsupervised 3D Pose Transfer.
Unsupervised_IEPGAN This is the PyTorch implementation of our ICCV 2021 paper Intrinsic-Extrinsic Preserved GANs for Unsupervised 3D Pose Transfer. Ha
 25 Oct 26, 2022
25 Oct 26, 2022

Matplotlib JOTA style for making figures
Matplotlib JOTA style for making figures This repo has Matplotlib JOTA style to format plots and figures for publications and presentation.
 2 May 5, 2022
2 May 5, 2022
A CSRankings-like index for speech researchers
Speech Rankings This project mimics CSRankings to generate an ordered list of researchers in speech/spoken language processing along with their possib
 19 Nov 26, 2022
19 Nov 26, 2022

Official PyTorch implementation of "BlendGAN: Implicitly GAN Blending for Arbitrary Stylized Face Generation" (NeurIPS 2021)
BlendGAN: Implicitly GAN Blending for Arbitrary Stylized Face Generation Official PyTorch implementation of the NeurIPS 2021 paper Mingcong Liu, Qiang
 462 Dec 29, 2022
462 Dec 29, 2022
Multi-Content GAN for Few-Shot Font Style Transfer at CVPR 2018
MC-GAN in PyTorch This is the implementation of the Multi-Content GAN for Few-Shot Font Style Transfer. The code was written by Samaneh Azadi. If you
 422 Dec 4, 2022
422 Dec 4, 2022

TensorFlow implementation of Style Transfer Generative Adversarial Networks: Learning to Play Chess Differently.
Adversarial Chess TensorFlow implementation of Style Transfer Generative Adversarial Networks: Learning to Play Chess Differently. Requirements To run
 30 Sep 7, 2021
30 Sep 7, 2021

Code and data for paper "Deep Photo Style Transfer"
deep-photo-styletransfer Code and data for paper "Deep Photo Style Transfer" Disclaimer This software is published for academic and non-commercial use
 9.9k Dec 29, 2022
9.9k Dec 29, 2022

Software that can generate photos from paintings, turn horses into zebras, perform style transfer, and more.
CycleGAN PyTorch | project page | paper Torch implementation for learning an image-to-image translation (i.e. pix2pix) without input-output pairs, for
 11.5k Dec 30, 2022
11.5k Dec 30, 2022
![[SIGGRAPH Asia 2019] Artistic Glyph Image Synthesis via One-Stage Few-Shot Learning](https://github.com/hologerry/AGIS-Net/raw/master/imgs/architecture.png)
[SIGGRAPH Asia 2019] Artistic Glyph Image Synthesis via One-Stage Few-Shot Learning
AGIS-Net Introduction This is the official PyTorch implementation of the Artistic Glyph Image Synthesis via One-Stage Few-Shot Learning. paper | suppl
 102 Jan 2, 2023
102 Jan 2, 2023

Learning Chinese Character style with conditional GAN
zi2zi: Master Chinese Calligraphy with Conditional Adversarial Networks Introduction Learning eastern asian language typefaces with GAN. zi2zi(字到字, me
 2.2k Jan 2, 2023
2.2k Jan 2, 2023
Python script to generate Vale linting rules from word usage guidance in the Red Hat Supplementary Style Guide
ssg-vale-rules-gen Python script to generate Vale linting rules from word usage guidance in the Red Hat Supplementary Style Guide. These rules are use
 1 Jan 13, 2022
1 Jan 13, 2022
Run async workflows using pytest-fixtures-style dependency injection
Run async workflows using pytest-fixtures-style dependency injection
 26 Jun 26, 2022
26 Jun 26, 2022

Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition | paper | dataset | pretrained detection model | Authors: Yi-Chang Che
 1 Aug 23, 2022
1 Aug 23, 2022
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL, and utterance id
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL
 3 Dec 26, 2022
3 Dec 26, 2022
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 168 Dec 28, 2022
168 Dec 28, 2022
Voice Conversion Using Speech-to-Speech Neuro-Style Transfer
This repo contains the official implementation of the VAE-GAN from the INTERSPEECH 2020 paper Voice Conversion Using Speech-to-Speech Neuro-Style Transfer.
 93 Jan 5, 2023
93 Jan 5, 2023
This Project is based on NLTK It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
This Project is based on NLTK(Natural Language Toolkit) It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
 2 Nov 17, 2021
2 Nov 17, 2021

SASE : Self-Adaptive noise distribution network for Speech Enhancement with heterogeneous data of Cross-Silo Federated learning
SASE : Self-Adaptive noise distribution network for Speech Enhancement with heterogeneous data of Cross-Silo Federated learning We propose a SASE mode
 1 Nov 20, 2021
1 Nov 20, 2021
A relatively simple python program to generate one of those reddit text to speech videos dominating youtube.
Reddit text to speech generator A basic reddit tts video generator Current functionality Generate videos for subs based on comments,(askreddit) so rea
 17 Dec 19, 2022
17 Dec 19, 2022
We have built a Voice based Personal Assistant for people to access files hands free in their device using natural language processing.
Voice Based Personal Assistant We have built a Voice based Personal Assistant for people to access files hands free in their device using natural lang
 2 Nov 13, 2021
2 Nov 13, 2021
PyKaldi is a Python scripting layer for the Kaldi speech recognition toolkit.
PyKaldi is a Python scripting layer for the Kaldi speech recognition toolkit. It provides easy-to-use, low-overhead, first-class Python wrappers for t
 922 Dec 31, 2022
922 Dec 31, 2022

Self-Supervised Learning with Data Augmentations Provably Isolates Content from Style
Self-Supervised Learning with Data Augmentations Provably Isolates Content from Style [NeurIPS 2021] Official code to reproduce the results and data p
 27 Sep 19, 2022
27 Sep 19, 2022
Uses Google's gTTS module to easily create robo text readin' on command.
Tool to convert text to speech, creating files for later use. TTRS uses Google's gTTS module to easily create robo text readin' on command.
 0 Jun 20, 2021
0 Jun 20, 2021

Investigating automatic navigation towards standard US views integrating MARL with the virtual US environment developed in CT2US simulation
AutomaticUSnavigation Investigating automatic navigation towards standard US views integrating MARL with the virtual US environment developed in CT2US
 6 Dec 5, 2022
6 Dec 5, 2022

Meta-TTS: Meta-Learning for Few-shot SpeakerAdaptive Text-to-Speech
Meta-TTS: Meta-Learning for Few-shot SpeakerAdaptive Text-to-Speech This repository is the official implementation of "Meta-TTS: Meta-Learning for Few
 128 Dec 25, 2022
128 Dec 25, 2022
Official implementation of "Membership Inference Attacks Against Self-supervised Speech Models"
Introduction Official implementation of "Membership Inference Attacks Against Self-supervised Speech Models". In this work, we demonstrate that existi
 7 Nov 1, 2022
7 Nov 1, 2022
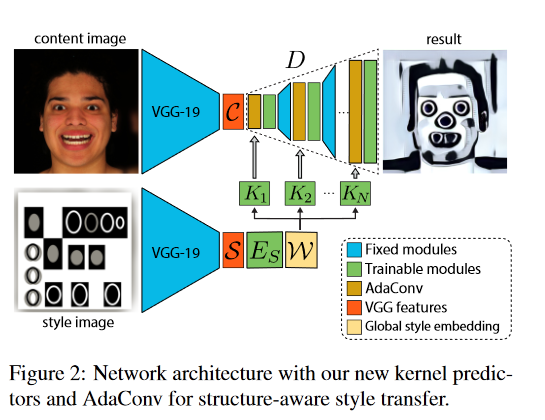
Unofficial PyTorch implementation of the Adaptive Convolution architecture for image style transfer
AdaConv Unofficial PyTorch implementation of the Adaptive Convolution architecture for image style transfer from "Adaptive Convolutions for Structure-
 65 Dec 22, 2022
65 Dec 22, 2022
Azure Neural Speech Service TTS
Written in Python using the Azure Speech SDK. App.py provides an easy way to create an Text-To-Speech request to Azure Speech and download the wav file. Azure Neural Voices Text-To-Speech enables fluid, natural-sounding text to speech that matches the patterns and intonation of human voices.
 4 Dec 14, 2022
4 Dec 14, 2022
A simple Speech Emotion Recognition (SER) API created using Flask and running in a Docker container.
emovoz Introduction A simple Speech Emotion Recognition (SER) API created using Flask and running in a Docker container. The SER system was built with
 2 Nov 11, 2022
2 Nov 11, 2022
This repository details the steps in creating a Part of Speech tagger using Trigram Hidden Markov Models and the Viterbi Algorithm without using external libraries.
POS-Tagger This repository details the creation of a Part-of-Speech tagger using Trigram Hidden Markov Models to predict word tags in a word sequence.
 1 Dec 9, 2021
1 Dec 9, 2021
JTEX is a command line tool (CLI) for rendering LaTeX documents from jinja-style templates.
JTEX JTEX is a command line tool (CLI) for rendering LaTeX documents from jinja-style templates. This package uses Jinja2 as the template engine with
 15 Dec 21, 2022
15 Dec 21, 2022
A collection of differentiable SVD methods and also the official implementation of the ICCV21 paper "Why Approximate Matrix Square Root Outperforms Accurate SVD in Global Covariance Pooling?"
Differentiable SVD Introduction This repository contains: The official Pytorch implementation of ICCV21 paper Why Approximate Matrix Square Root Outpe
 32 Dec 25, 2022
32 Dec 25, 2022

PaddlePaddle GAN library, including lots of interesting applications like First-Order motion transfer, wav2lip, picture repair, image editing, photo2cartoon, image style transfer, and so on.
English | 简体中文 PaddleGAN PaddleGAN provides developers with high-performance implementation of classic and SOTA Generative Adversarial Networks, and s
 6.4k Jan 9, 2023
6.4k Jan 9, 2023

 4k Jan 7, 2023
4k Jan 7, 2023

Styled text-to-drawing synthesis method. Featured at the 2021 NeurIPS Workshop on Machine Learning for Creativity and Design
Styled text-to-drawing synthesis method. Featured at the 2021 NeurIPS Workshop on Machine Learning for Creativity and Design
 247 Dec 23, 2022
247 Dec 23, 2022
Cryptocurrency application that displays instant cryptocurrency prices and reads prices with the Google Text-to-Speech library.
📈 Cryptocurrency Price App 💰 ◽ Cryptocurrency application that displays instant cryptocurrency prices and reads prices with the Google Text-to-Speec
 2 Nov 8, 2021
2 Nov 8, 2021
Ukrainian TTS (text-to-speech) using Coqui TTS
title emoji colorFrom colorTo sdk app_file pinned Ukrainian TTS 🐸 green green gradio app.py false Ukrainian TTS 📢 🤖 Ukrainian TTS (text-to-speech)
 85 Dec 26, 2022
85 Dec 26, 2022
On-device speech-to-index engine powered by deep learning.
On-device speech-to-index engine powered by deep learning.
 30 Nov 24, 2022
30 Nov 24, 2022

Manifold Alignment for Semantically Aligned Style Transfer
Manifold Alignment for Semantically Aligned Style Transfer [Paper] Getting Started MAST has been tested on CentOS 7.6 with python = 3.6. It supports
 35 Nov 14, 2022
35 Nov 14, 2022
Code for paper: An Effective, Robust and Fairness-awareHate Speech Detection Framework
BiQQLSTM_HS Code and data for paper: Title: An Effective, Robust and Fairness-awareHate Speech Detection Framework. Authors: Guanyi Mou and Kyumin Lee
 2 Dec 27, 2022
2 Dec 27, 2022

Sign-to-Speech for Sign Language Understanding: A case study of Nigerian Sign Language
Sign-to-Speech for Sign Language Understanding: A case study of Nigerian Sign Language This repository contains the code, model, and deployment config
 16 Oct 23, 2022
16 Oct 23, 2022
Cross-lingual Transfer for Speech Processing using Acoustic Language Similarity
Cross-lingual Transfer for Speech Processing using Acoustic Language Similarity Indic TTS Samples can be found at https://peter-yh-wu.github.io/cross-
 1 Nov 12, 2022
1 Nov 12, 2022
Explore different way to mix speech model(wav2vec2, hubert) and nlp model(BART,T5,GPT) together
SpeechMix Explore different way to mix speech model(wav2vec2, hubert) and nlp model(BART,T5,GPT) together. Introduction For the same input: from datas
 31 Nov 7, 2022
31 Nov 7, 2022
PyTorch implementation of "A Two-Stage End-to-End System for Speech-in-Noise Hearing Aid Processing"
Implementation of the Sheffield entry for the first Clarity enhancement challenge (CEC1) This repository contains the PyTorch implementation of "A Two
 10 Aug 19, 2022
10 Aug 19, 2022

This is the official Pytorch implementation of the paper "Diverse Motion Stylization for Multiple Style Domains via Spatial-Temporal Graph-Based Generative Model"
Diverse Motion Stylization (Official) This is the official Pytorch implementation of this paper. Diverse Motion Stylization for Multiple Style Domains
 28 Dec 16, 2022
28 Dec 16, 2022
Installation, test and evaluation of Scribosermo speech-to-text engine
Scribosermo STT Setup Scribosermo is a LGPL licensed, open-source speech recognition engine to "Train fast Speech-to-Text networks in different langua
 3 Jun 20, 2022
3 Jun 20, 2022
A Django-style ORM idea for manipulating Google Datastore entities
No SeiQueLa ORM EM DESENVOLVIMENTO Uma ideia de ORM no estilo do Django para manipular entidades do Google Datastore. Montando seu modelo: from noseiq
 16 Nov 1, 2022
16 Nov 1, 2022

Text to speech converter with GUI made in Python.
Text-to-speech-with-GUI Text to speech converter with GUI made in Python. To run this download the zip file and run the main file or clone this repo.
 1 Nov 15, 2021
1 Nov 15, 2021
Azure Text-to-speech service for Home Assistant
Azure Text-to-speech service for Home Assistant The Azure text-to-speech platform uses online Azure Text-to-Speech cognitive service to read a text wi
 2 Aug 6, 2022
2 Aug 6, 2022
Terminal-based audio-to-text converter
att Terminal-based audio-to-text converter Project description A terminal-based audio-to-text converter written in python, enabling you to convert .wa
 4 Dec 15, 2022
4 Dec 15, 2022

Pytorch Implementation of "Diagonal Attention and Style-based GAN for Content-Style disentanglement in image generation and translation" (ICCV 2021)
DiagonalGAN Official Pytorch Implementation of "Diagonal Attention and Style-based GAN for Content-Style Disentanglement in Image Generation and Trans
 32 Dec 6, 2022
32 Dec 6, 2022
Simple, hackable offline speech to text - using the VOSK-API.
Simple, hackable offline speech to text - using the VOSK-API.
 844 Jan 7, 2023
844 Jan 7, 2023

🔥 Real-time Super Resolution enhancement (4x) with content loss and relativistic adversarial optimization 🔥
🔥 Real-time Super Resolution enhancement (4x) with content loss and relativistic adversarial optimization 🔥
 48 Dec 20, 2022
48 Dec 20, 2022
Simple Speech to Text, Text to Speech
Simple Speech to Text, Text to Speech 1. Download Repository Opsi 1 Download repository ini, extract di lokasi yang diinginkan Opsi 2 Jika sudah famil
 5 Dec 28, 2021
5 Dec 28, 2021
The PyTorch based implementation of continuous integrate-and-fire (CIF) module.
CIF-PyTorch This is a PyTorch based implementation of continuous integrate-and-fire (CIF) module for end-to-end (E2E) automatic speech recognition (AS
 24 Dec 29, 2022
24 Dec 29, 2022
Cobra is a highly-accurate and lightweight voice activity detection (VAD) engine.
On-device voice activity detection (VAD) powered by deep learning.
88 Dec 16, 2022

PSGAN running with ncnn⚡妆容迁移/仿妆⚡Imitation Makeup/Makeup Transfer⚡
PSGAN running with ncnn⚡妆容迁移/仿妆⚡Imitation Makeup/Makeup Transfer⚡
 144 Dec 26, 2022
144 Dec 26, 2022
SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch.
The SpeechBrain Toolkit SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch. The goal is to create a single, flexible, and us
 5.1k Jan 2, 2023
5.1k Jan 2, 2023
Repository for Driving Style Recognition algorithms for Autonomous Vehicles
Driving Style Recognition Using Interval Type-2 Fuzzy Inference System and Multiple Experts Decision Making Created by Iago Pachêco Gomes at USP - ICM
 9 Nov 28, 2022
9 Nov 28, 2022
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrai
 77.4k Jan 5, 2023
77.4k Jan 5, 2023

PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Cross-Speaker-Emotion-Transfer - PyTorch Implementation PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Conditio
 114 Jan 8, 2023
114 Jan 8, 2023
A flask application to predict the speech emotion of any .wav file.
This is a speech emotion recognition app. It will allow you to train a modular MLP model with the RAVDESS dataset, and then use that model with a flask application to predict the speech emotion of any .wav file.
 2 Dec 15, 2021
2 Dec 15, 2021
A JSON utility library for Python featuring Django-style queries and mutations.
JSON Enhanced JSON Enhanced implements fast and pythonic queries and mutations for JSON objects. Installation You can install json-enhanced with pip:
 4 Aug 22, 2022
4 Aug 22, 2022
strbind - lapidary text converter for translate an text file to the C-style string
strbind strbind - lapidary text converter for translate an text file to the C-style string. My motivation is fast adding large text chunks to the C co
 1 Oct 22, 2021
1 Oct 22, 2021

Official implementation of the paper: "LDNet: Unified Listener Dependent Modeling in MOS Prediction for Synthetic Speech"
LDNet Author: Wen-Chin Huang (Nagoya University) Email: [email protected] This is the official implementation of the paper "LDNet
 40 Nov 20, 2022
40 Nov 20, 2022
A simple Blog Using Django Framework and Used IBM Cloud Services for Text Analysis and Text to Speech
ElhamBlog Cloud Computing Course first assignment. A simple Blog Using Django Framework and Used IBM Cloud Services for Text Analysis and Text to Spee
 5 Dec 6, 2022
5 Dec 6, 2022
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge This is an implementation of the paper,
19 Oct 14, 2022
Minimal GUI for accessing the Watson Text to Speech service.
Description Minimal graphical application for accessing the Watson Text to Speech service. Requirements Python 3 plus all dependencies listed in requi
 1 Oct 22, 2021
1 Oct 22, 2021
Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR
Speech_38_ru_commands Recognition of 38 speech commands in russian. Based on Yandex Cup 2021 ML Challenge: ASR Программа умеет распознавать 38 ключевы
 9 May 5, 2022
9 May 5, 2022
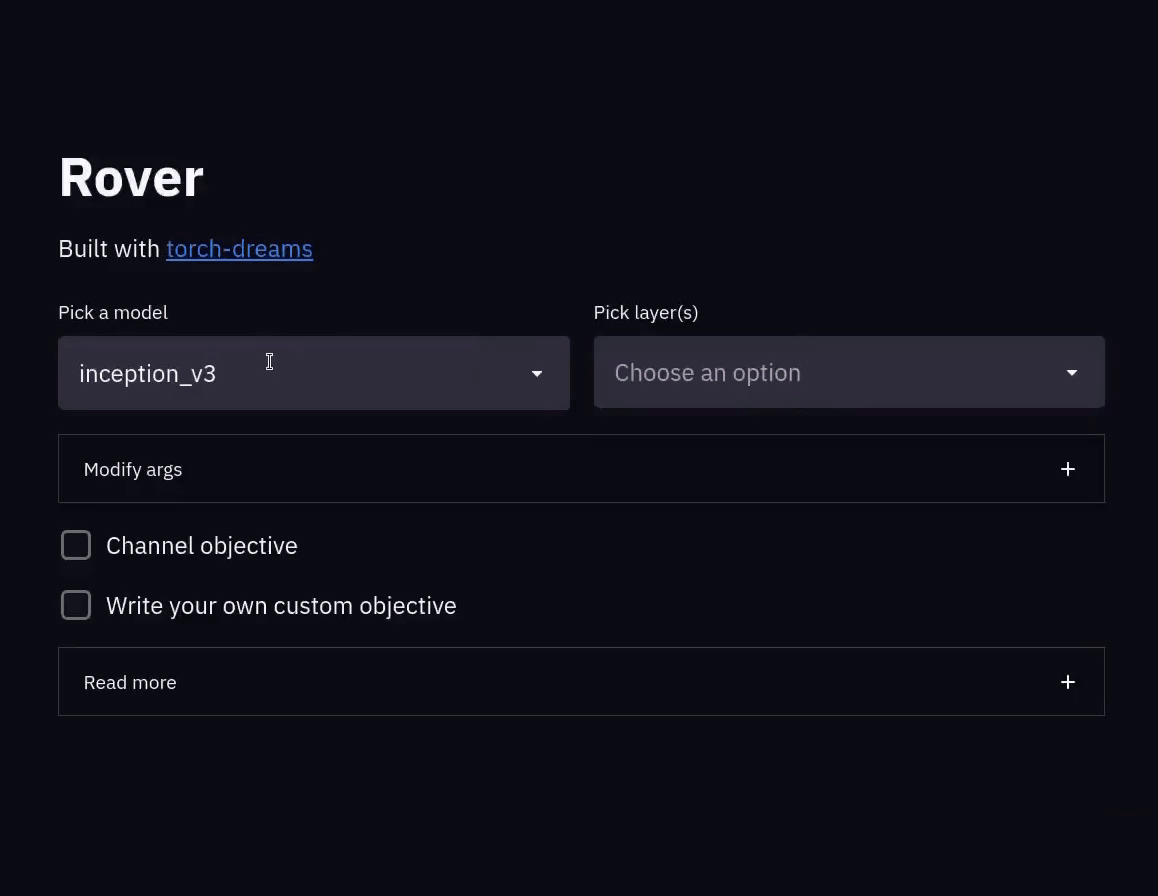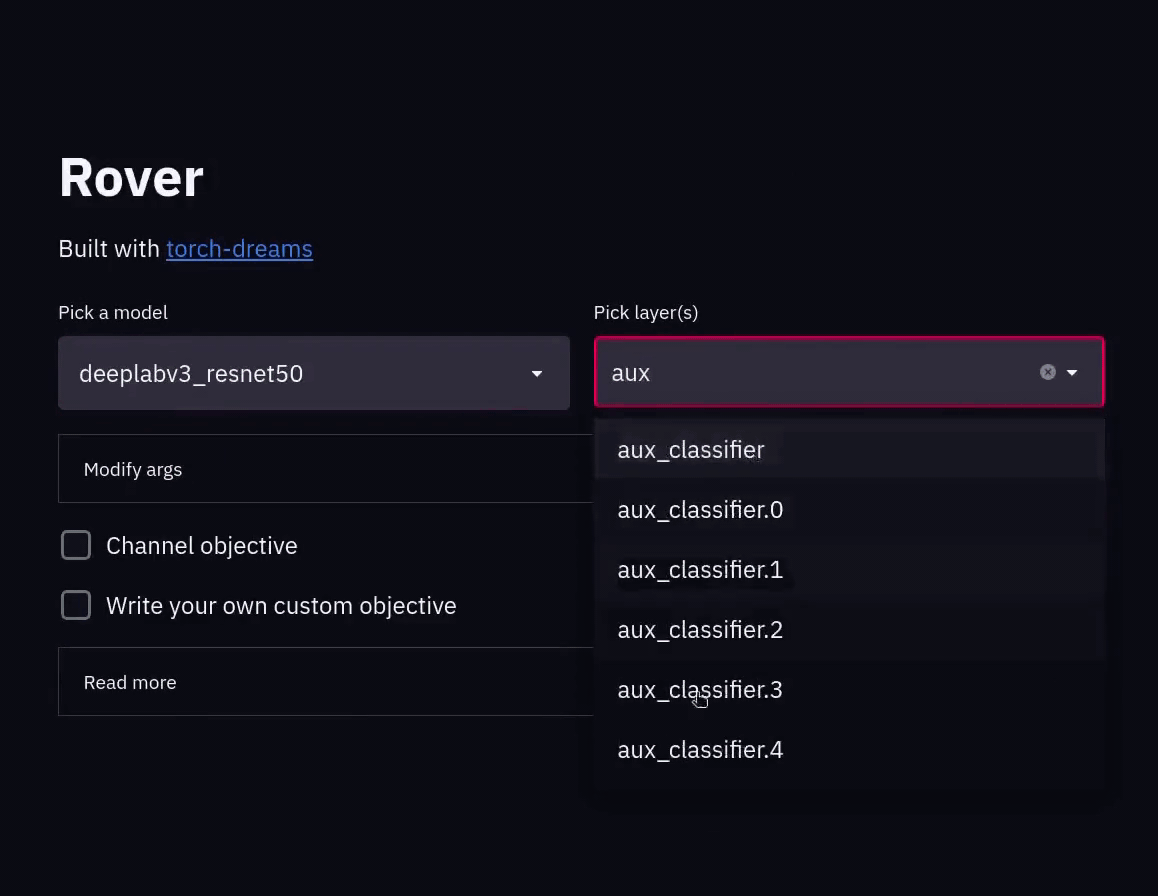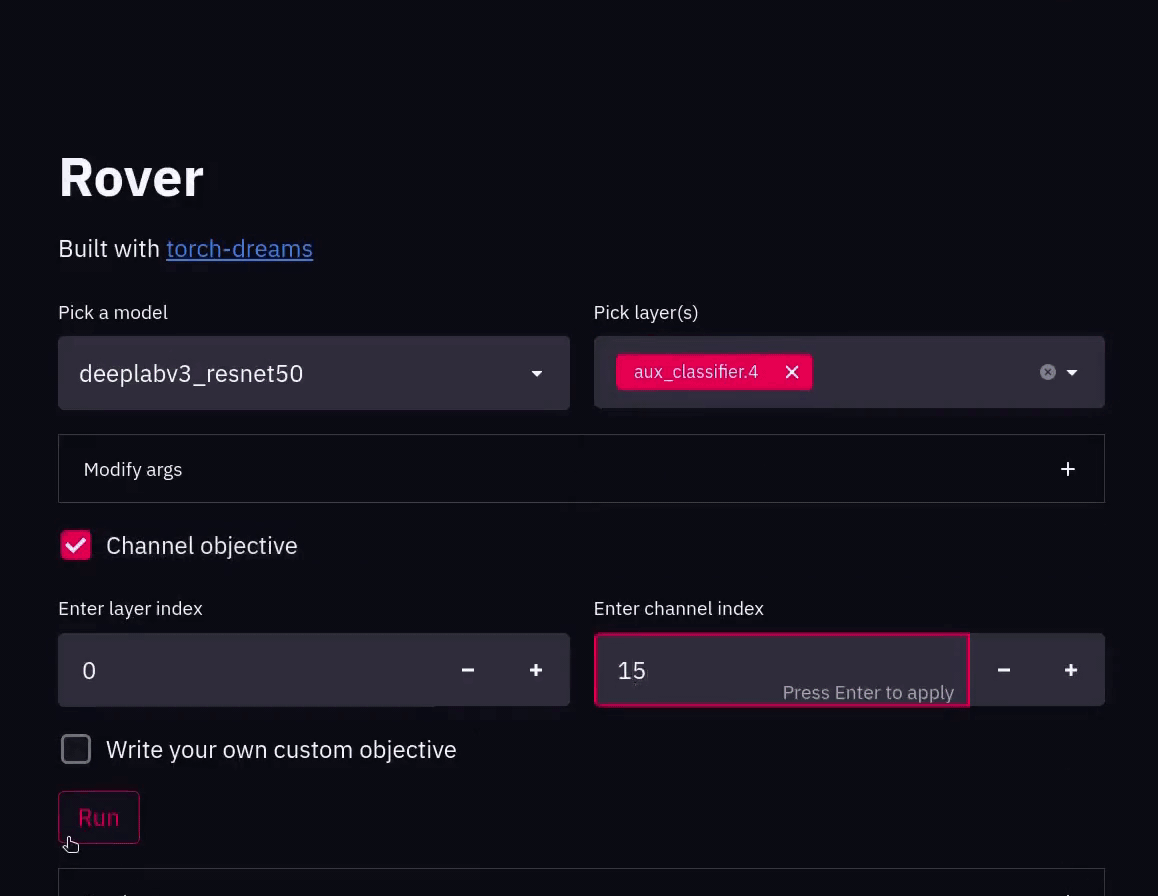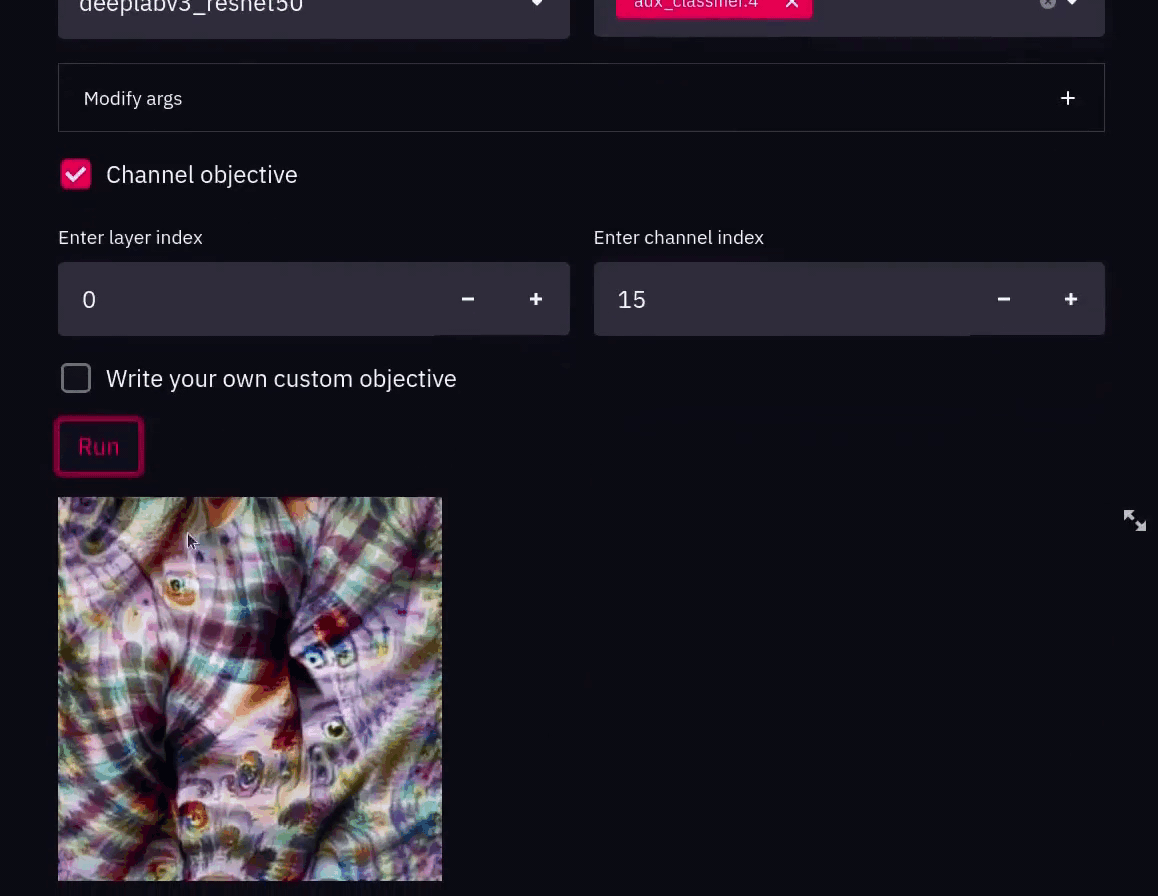
Reverse engineer your pytorch vision models, in style
🔍 Rover Reverse engineer your CNNs, in style Rover will help you break down your CNN and visualize the features from within the model. No need to wri
 32 Sep 24, 2022
32 Sep 24, 2022

A Python/Pytorch app for easily synthesising human voices
Voice Cloning App A Python/Pytorch app for easily synthesising human voices Documentation Discord Server Video guide Voice Sharing Hub FAQ's System Re
 840 Jan 4, 2023
840 Jan 4, 2023
The end-to-end platform for building voice products at scale
Picovoice Made in Vancouver, Canada by Picovoice Picovoice is the end-to-end platform for building voice products on your terms. Unlike Alexa and Goog
318 Jan 7, 2023
On-device speech-to-intent engine powered by deep learning
Rhino Made in Vancouver, Canada by Picovoice Rhino is Picovoice's Speech-to-Intent engine. It directly infers intent from spoken commands within a giv
510 Dec 30, 2022
Connectionist Temporal Classification (CTC) decoding algorithms: best path, beam search, lexicon search, prefix search, and token passing. Implemented in Python.
CTC Decoding Algorithms Update 2021: installable Python package Python implementation of some common Connectionist Temporal Classification (CTC) decod
 736 Jan 3, 2023
736 Jan 3, 2023

Unofficial pytorch implementation of 'Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization'
pytorch-AdaIN This is an unofficial pytorch implementation of a paper, Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization [Hua
 873 Jan 6, 2023
873 Jan 6, 2023

Production First and Production Ready End-to-End Speech Recognition Toolkit
WeNet 中文版 Discussions | Docs | Papers | Runtime (x86) | Runtime (android) | Pretrained Models We share neural Net together. The main motivation of WeN
 2.7k Jan 4, 2023
2.7k Jan 4, 2023
glow-speak is a fast, local, neural text to speech system that uses eSpeak-ng as a text/phoneme front-end.
Glow-Speak glow-speak is a fast, local, neural text to speech system that uses eSpeak-ng as a text/phoneme front-end. Installation git clone https://g
 8 Dec 25, 2022
8 Dec 25, 2022
Identify the emotion of multiple speakers in an Audio Segment
MevonAI - Speech Emotion Recognition Identify the emotion of multiple speakers in a Audio Segment Report Bug · Request Feature Try the Demo Here Table
 110 Dec 3, 2022
110 Dec 3, 2022
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge This is an implementation of the paper,
19 Oct 14, 2022
Official implementation of the paper: "LDNet: Unified Listener Dependent Modeling in MOS Prediction for Synthetic Speech"
LDNet Author: Wen-Chin Huang (Nagoya University) Email: [email protected] This is the official implementation of the paper "LDNet
40 Nov 20, 2022
Replication Package for AequeVox:Automated Fariness Testing for Speech Recognition Systems
AequeVox Replication Package for AequeVox:Automated Fariness Testing for Speech Recognition Systems README under development. Python Packages Required
 2 Aug 28, 2022
2 Aug 28, 2022

PyTorch implementation of paper "StarEnhancer: Learning Real-Time and Style-Aware Image Enhancement" (ICCV 2021 Oral)
StarEnhancer StarEnhancer: Learning Real-Time and Style-Aware Image Enhancement (ICCV 2021 Oral) Abstract: Image enhancement is a subjective process w
 133 Dec 28, 2022
133 Dec 28, 2022

Fast Style Transfer in TensorFlow
Fast Style Transfer in TensorFlow Add styles from famous paintings to any photo in a fraction of a second! You can even style videos! It takes 100ms o
 5 Oct 24, 2021
5 Oct 24, 2021
Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training".
Mixup-Data-Dependency Code associated with the paper "Towards Understanding the Data Dependency of Mixup-style Training". Running Alternating Line Exp
0 Nov 11, 2021
End-to-End Speech Processing Toolkit
ESPnet: end-to-end speech processing toolkit system/pytorch ver. 1.3.1 1.4.0 1.5.1 1.6.0 1.7.1 1.8.1 1.9.0 ubuntu20/python3.9/pip ubuntu20/python3.8/p
 5.9k Jan 4, 2023
5.9k Jan 4, 2023
CPC-big and k-means clustering for zero-resource speech processing
The CPC-big model and k-means checkpoints used in Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing.
 5 Nov 23, 2022
5 Nov 23, 2022

Light-SERNet: A lightweight fully convolutional neural network for speech emotion recognition
Light-SERNet This is the Tensorflow 2.x implementation of our paper "Light-SERNet: A lightweight fully convolutional neural network for speech emotion
 29 Nov 12, 2022
29 Nov 12, 2022
Paimon is a pixie (or script) who was made for anyone from {EPITECH} who are struggling with the Coding Style.
Paimon Paimon is a pixie (or script) who was made for anyone from {EPITECH} who are struggling with the Coding Style. Her goal is to assist you in you
 2 Oct 17, 2021
2 Oct 17, 2021
Maix Speech AI lib, including ASR, chat, TTS etc.
Maix-Speech 中文 | English Brief Now only support Chinese, See 中文 Build Clone code by: git clone https://github.com/sipeed/Maix-Speech Compile x86x64 c
 267 Dec 25, 2022
267 Dec 25, 2022

translate using your voice
speech-to-text-translator Usage translate using your voice description this project makes translating a word easy, all you have to do is speak and...
 1 Oct 18, 2021
1 Oct 18, 2021
To lazy to read your homework ? Get it done with LOL
LOL To lazy to read your homework ? Get it done with LOL Needs python 3.x L:::::::::L OO:::::::::OO L:::::::::L L:::::::
 4 Dec 8, 2022
4 Dec 8, 2022