418 Repositories
Python speech-to-index Libraries
Python PostgreSQL database performance insights. Locks, index usage, buffer cache hit ratios, vacuum stats and more.
Python PG Extras Python port of Heroku PG Extras with several additions and improvements. The goal of this project is to provide powerful insights int
 35 Nov 1, 2022
35 Nov 1, 2022
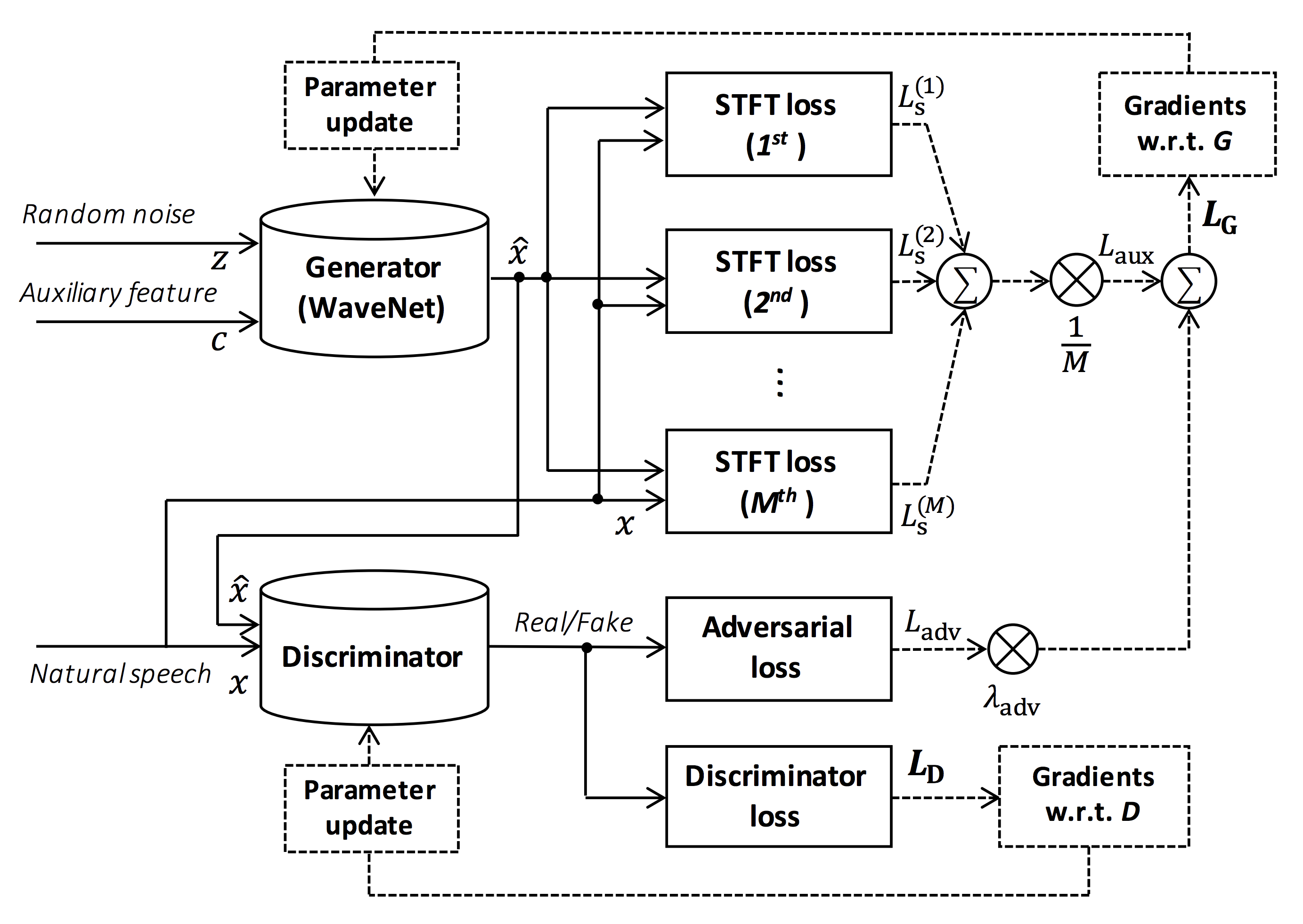
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN & HiFi-GAN & StyleMelGAN) with Pytorch
Parallel WaveGAN implementation with Pytorch This repository provides UNOFFICIAL pytorch implementations of the following models: Parallel WaveGAN Mel
 1.2k Dec 23, 2022
1.2k Dec 23, 2022

Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition"
Tensorflow Implementation for "Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition" Pre-trained Deep Convo
 5 Nov 11, 2022
5 Nov 11, 2022
A Telegram bot to index Chinese and Japanese group contents, works with @lilydjwg/luoxu.
luoxu-bot luoxu-bot 是类似于 luoxu-web 的 CJK 友好的 Telegram Bot,依赖于 luoxu 所创建的后端。 测试环境 Python 3.7.9 pip 21.1.2 开发中使用到的 Telethon 需要 Python 3+ 配置 前往 luoxu 根据相
 10 Nov 18, 2022
10 Nov 18, 2022

This is a really simple text-to-speech app made with python and tkinter.
Tkinter Text-to-Speech App by Souvik Roy This is a really simple tkinter app which converts the text you have entered into a speech. It is created wit
 1 Dec 21, 2021
1 Dec 21, 2021
A Python module made to simplify the usage of Text To Speech and Speech Recognition.
Nav Module The solution for voice related stuff in Python Nav is a Python module which simplifies voice related stuff in Python. Just import the Modul
 1 Dec 20, 2021
1 Dec 20, 2021

DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022; Official code
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
 803 Dec 28, 2022
803 Dec 28, 2022

J.A.R.V.I.S is an AI virtual assistant made in python.
J.A.R.V.I.S is an AI virtual assistant made in python. Running JARVIS Without Python To run JARVIS without python: 1. Head over to our installation pa
 16 Dec 29, 2022
16 Dec 29, 2022
Wav2Vec for speech recognition, classification, and audio classification
Soxan در زبان پارسی به نام سخن This repository consists of models, scripts, and notebooks that help you to use all the benefits of Wav2Vec 2.0 in your
 140 Dec 15, 2022
140 Dec 15, 2022
Arabic speech recognition, classification and text-to-speech.
klaam Arabic speech recognition, classification and text-to-speech using many advanced models like wave2vec and fastspeech2. This repository allows tr
 177 Dec 27, 2022
177 Dec 27, 2022
Contains links to publicly available datasets for modeling health outcomes using speech and language.
speech-nlp-datasets Contains links to publicly available datasets for modeling various health outcomes using speech and language. Speech-based Corpora
 77 Dec 7, 2022
77 Dec 7, 2022

Create light scenes , voice control, ifttt, fuzzywuzzy speech correction and much more with Tuya light bulbs.
LightBox Features: Auto discover tuya lights Set and create moods (aka: light profiles) Change moods via IFTTT List moods via IFTTT FuzzyWuzzy, speech
 1 Dec 20, 2021
1 Dec 20, 2021
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism (SVS & TTS); AAAI 2022
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism This repository is the official PyTorch implementation of our AAAI-2022 paper, in
829 Jan 7, 2023

UniSpeech - Large Scale Self-Supervised Learning for Speech
UniSpeech The family of UniSpeech: WavLM (arXiv): WavLM: Large-Scale Self-Supervised Pre-training for Full Stack Speech Processing UniSpeech (ICML 202
 281 Dec 15, 2022
281 Dec 15, 2022
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
SEW (Squeezed and Efficient Wav2vec) The repo contains the code of the paper "Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speec
 67 Dec 1, 2022
67 Dec 1, 2022
Malaya-Speech is a Speech-Toolkit library for bahasa Malaysia, powered by Deep Learning Tensorflow.
Malaya-Speech is a Speech-Toolkit library for bahasa Malaysia, powered by Deep Learning Tensorflow. Documentation Proper documentation is available at
 151 Jan 5, 2023
151 Jan 5, 2023
Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks
wav2vec_finetune Test finetuning of XLSR (multilingual wav2vec 2.0) for other speech classification tasks Initial test: gender recognition on this dat
 8 Aug 11, 2022
8 Aug 11, 2022
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023
Pytorch implementation NORESQA A Framework for Speech Quality Assessment using Non-Matching References.
NORESQA: Speech Quality Assessment using Non-Matching References This is a Pytorch implementation for using NORESQA. It contains minimal code to predi
 11 Dec 14, 2021
11 Dec 14, 2021
CYGNUS, the Cynical AI, combines snarky responses with uncanny aggression.
New & (hopefully) Improved CYGNUS with several API updates, user updates, and online/offline operations added!!!
 0 Mar 28, 2022
0 Mar 28, 2022

A voice assistant which can be used to interact with your computer and controls your pc operations
Introduction 👨💻 It is a voice assistant which can be used to interact with your computer and also you have been seeing it in Iron man movies, but t
 84 Dec 22, 2022
84 Dec 22, 2022
Continuous Augmented Positional Embeddings (CAPE) implementation for PyTorch
PyTorch implementation of Continuous Augmented Positional Embeddings (CAPE), by Likhomanenko et al. Enhance your Transformer positional embeddings with easy-to-use augmentations!
 26 Dec 13, 2022
26 Dec 13, 2022
A complete speech segmentation system using Kaldi and x-vectors for voice activity detection (VAD) and speaker diarisation.
bbc-speech-segmenter: Voice Activity Detection & Speaker Diarization A complete speech segmentation system using Kaldi and x-vectors for voice activit
 16 Oct 27, 2022
16 Oct 27, 2022
Code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language"
The repository provides the source code for the paper "Combining Textual Features for the Detection of Hateful and Offensive Language" submitted to HA
 3 Aug 4, 2022
3 Aug 4, 2022
The world's largest toxicity dataset.
The Toxicity Dataset by Surge AI Saving the internet is fun. Combing through thousands of online comments to build a toxicity dataset isn't. That's wh
 134 Dec 19, 2022
134 Dec 19, 2022
An end to end ASR Transformer model training repo
END TO END ASR TRANSFORMER 本项目基于transformer 6*encoder+6*decoder的基本结构构造的端到端的语音识别系统 Model Instructions 1.数据准备: 自行下载数据,遵循文件结构如下: ├── data │ ├── train │
 10 Jul 19, 2022
10 Jul 19, 2022
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone In our recent paper we propose the YourTTS model. YourTTS bri
 390 Dec 29, 2022
390 Dec 29, 2022
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks
Lip Reading - Cross Audio-Visual Recognition using 3D Convolutional Neural Networks - Official Project Page This repository contains the code develope
 1.7k Dec 18, 2022
1.7k Dec 18, 2022
This github repo is for Neurips 2021 paper, NORESQA A Framework for Speech Quality Assessment using Non-Matching References.
NORESQA: Speech Quality Assessment using Non-Matching References This is a Pytorch implementation for using NORESQA. It contains minimal code to predi
36 Dec 8, 2022
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
PyTorch Implementation of Daft-Exprt: Robust Prosody Transfer Across Speakers for Expressive Speech Synthesis
 76 Dec 30, 2022
76 Dec 30, 2022

Any-to-any voice conversion using synthetic specific-speaker speeches as intermedium features
MediumVC MediumVC is an utterance-level method towards any-to-any VC. Before that, we propose SingleVC to perform A2O tasks(Xi → Ŷi) , Xi means utter
 47 Dec 25, 2022
47 Dec 25, 2022

SingleVC performs any-to-one VC, which is an important component of MediumVC project.
SingleVC performs any-to-one VC, which is an important component of MediumVC project. Here is the official implementation of the paper, MediumVC.
26 Dec 28, 2022

Implementation of Google Brain's WaveGrad high-fidelity vocoder
WaveGrad Implementation (PyTorch) of Google Brain's high-fidelity WaveGrad vocoder (paper). First implementation on GitHub with high-quality generatio
 363 Dec 27, 2022
363 Dec 27, 2022
DiffWave is a fast, high-quality neural vocoder and waveform synthesizer.
DiffWave DiffWave is a fast, high-quality neural vocoder and waveform synthesizer. It starts with Gaussian noise and converts it into speech via itera
 498 Jan 3, 2023
498 Jan 3, 2023
Neural HMMs are all you need (for high-quality attention-free TTS)
Neural HMMs are all you need (for high-quality attention-free TTS) Shivam Mehta, Éva Székely, Jonas Beskow, and Gustav Eje Henter This is the official
 0 Oct 28, 2022
0 Oct 28, 2022

End-2-end speech synthesis with recurrent neural networks
Introduction New: Interactive demo using Google Colaboratory can be found here TTS-Cube is an end-2-end speech synthesis system that provides a full p
 214 Dec 7, 2022
214 Dec 7, 2022

Text to speech for Vietnamese, ez to use, ez to update
Chào mọi người, đây là dự án mở nhằm giúp việc đọc được trở nên dễ dàng hơn. Rất cảm ơn đội ngũ Zalo đã cung cấp hạ tầng để mình có thể tạo ra app này
 32 Jul 29, 2022
32 Jul 29, 2022
An 16kHz implementation of HiFi-GAN for soft-vc.
HiFi-GAN An 16kHz implementation of HiFi-GAN for soft-vc. Relevant links: Official HiFi-GAN repo HiFi-GAN paper Soft-VC repo Soft-VC paper Example Usa
 42 Dec 27, 2022
42 Dec 27, 2022
Simple Python library, distributed via binary wheels with few direct dependencies, for easily using wav2vec 2.0 models for speech recognition
Wav2Vec2 STT Python Beta Software Simple Python library, distributed via binary wheels with few direct dependencies, for easily using wav2vec 2.0 mode
 22 Dec 29, 2022
22 Dec 29, 2022
A set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI.
Overview This is a set of simple scripts to process the Imagenet-1K dataset as TFRecords and make index files for NVIDIA DALI. Make TFRecords To run t
 8 Nov 1, 2022
8 Nov 1, 2022
IBD Style Relative Strength Percentile Ranking of Stocks (i.e. 0-100 Score).
relative-strength IBD Style Relative Strength Percentile Ranking of Stocks (i.e. 0-100 Score). I also made a TradingView indicator, but it cannot give
 57 Jan 6, 2023
57 Jan 6, 2023
Combine Tacotron2 and Hifi GAN to generate speech from text
EndToEndTextToSpeech Combine Tacotron2 and Hifi GAN to generate speech from text Download weights Hifi GAN - hifi_gan/checkpoint/ : pretrain 2.5M ste
 1 Dec 18, 2021
1 Dec 18, 2021
An index of algorithms for learning causality with data
awesome-causality-algorithms An index of algorithms for learning causality with data. Please cite our survey paper if this index is helpful. @article{
 2.3k Jan 8, 2023
2.3k Jan 8, 2023

Conversational text Analysis using various NLP techniques
PyConverse Let me try first Installation pip install pyconverse Usage Please try this notebook that demos the core functionalities: basic usage noteb
 158 Dec 25, 2022
158 Dec 25, 2022
Simple virtual assistant using pyttsx3 and speech recognition optionally with pywhatkit and pther libraries.
VirtualAssistant Simple virtual assistant using pyttsx3 and speech recognition optionally with pywhatkit and pther libraries. Third Party Libraries us
 1 Nov 27, 2021
1 Nov 27, 2021
Text-to-Speech for Belarusian language
title emoji colorFrom colorTo sdk app_file pinned Belarusian TTS 🐸 green green gradio app.py false Belarusian TTS 📢 🤖 Belarusian TTS (text-to-speec
 1 Nov 27, 2021
1 Nov 27, 2021
Inverted index creation and query search mechanism on Wikipedia pages.
WikiPedia Search Engine Step 1 : Installing Requirements Install "stemming" module for python using pip. Step 2 : Parsing the Data To parse the data,
 1 Nov 27, 2021
1 Nov 27, 2021

Indices Matter: Learning to Index for Deep Image Matting
IndexNet Matting This repository includes the official implementation of IndexNet Matting for deep image matting, presented in our paper: Indices Matt
 357 Nov 26, 2022
357 Nov 26, 2022

A python gui program to generate reddit text to speech videos from the id of any post.
Reddit text to speech generator A python gui program to generate reddit text to speech videos from the id of any post. Current functionality Generate
 17 Dec 19, 2022
17 Dec 19, 2022
Romanian Automatic Speech Recognition from the ROBIN project
RobinASR This repository contains Robin's Automatic Speech Recognition (RobinASR) for the Romanian language based on the DeepSpeech2 architecture, tog
 10 Jan 1, 2023
10 Jan 1, 2023

Repository for paper "Non-intrusive speech intelligibility prediction from discrete latent representations"
Non-Intrusive Speech Intelligibility Prediction from Discrete Latent Representations Official repository for paper "Non-Intrusive Speech Intelligibili
 5 Oct 25, 2022
5 Oct 25, 2022

The project is associated with the recently-launched ICASSP 2022 Multi-channel Multi-party Meeting Transcription Challenge (M2MeT) to provide participants with baseline systems for speech recognition and speaker diarization in conference scenario.
M2MeT challenge baseline -- AliMeeting This project provides the baseline system recipes for the ICASSP 2020 Multi-channel Multi-party Meeting Transcr
 81 Dec 8, 2022
81 Dec 8, 2022

Efficient Speech Processing Tookit for Automatic Speaker Recognition
Sugar Efficient Speech Processing Tookit for Automatic Speaker Recognition | HuggingFace | What's New EfficientTDNN: Efficient Architecture Search for
 14 Sep 14, 2022
14 Sep 14, 2022
German Text-To-Speech Engine using Tacotron and Griffin-Lim
jotts JoTTS is a German text-to-speech engine using tacotron and griffin-lim. The synthesizer model has been trained on my voice using Tacotron1. Due
 6 Aug 28, 2022
6 Aug 28, 2022
A desktop GUI providing an audio interface for GPT3.
Jabberwocky neil_degrasse_tyson_with_audio.mp4 Project Description This GUI provides an audio interface to GPT-3. My main goal was to provide a conven
 16 Nov 27, 2022
16 Nov 27, 2022
Simple web index to use bloom filter for Pwned Passwords
pwbloom Simple web index to use bloom filter for Pwned Passwords The index.py runs a simple CGI web service checking passwords with a bloom filter for
 4 Nov 23, 2021
4 Nov 23, 2021
A CSRankings-like index for speech researchers
Speech Rankings This project mimics CSRankings to generate an ordered list of researchers in speech/spoken language processing along with their possib
 19 Nov 26, 2022
19 Nov 26, 2022

Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition
Integrated Semantic and Phonetic Post-correction for Chinese Speech Recognition | paper | dataset | pretrained detection model | Authors: Yi-Chang Che
 1 Aug 23, 2022
1 Aug 23, 2022
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL, and utterance id
TEDSummary is a speech summary corpus. It includes TED talks subtitle (Document), Title-Detail (Summary), speaker name (Meta info), MP4 URL
 3 Dec 26, 2022
3 Dec 26, 2022
Official implementation of Meta-StyleSpeech and StyleSpeech
Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation Dongchan Min, Dong Bok Lee, Eunho Yang, and Sung Ju Hwang This is an official code
 168 Dec 28, 2022
168 Dec 28, 2022
Voice Conversion Using Speech-to-Speech Neuro-Style Transfer
This repo contains the official implementation of the VAE-GAN from the INTERSPEECH 2020 paper Voice Conversion Using Speech-to-Speech Neuro-Style Transfer.
 93 Jan 5, 2023
93 Jan 5, 2023
This Project is based on NLTK It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
This Project is based on NLTK(Natural Language Toolkit) It generates a RANDOM WORD from a predefined list of words, From that random word it read out the word, its meaning with parts of speech , its antonyms, its synonyms
 2 Nov 17, 2021
2 Nov 17, 2021

SASE : Self-Adaptive noise distribution network for Speech Enhancement with heterogeneous data of Cross-Silo Federated learning
SASE : Self-Adaptive noise distribution network for Speech Enhancement with heterogeneous data of Cross-Silo Federated learning We propose a SASE mode
 1 Nov 20, 2021
1 Nov 20, 2021
A relatively simple python program to generate one of those reddit text to speech videos dominating youtube.
Reddit text to speech generator A basic reddit tts video generator Current functionality Generate videos for subs based on comments,(askreddit) so rea
17 Dec 19, 2022
Add a "flame" effect on each hand's index onto a video stream.
Add a "flame" effect on each hand's index onto a video stream. recording.webm.mov This script is just a quick hack, it's a bit of glue between mediapi
 7 Sep 15, 2022
7 Sep 15, 2022
We have built a Voice based Personal Assistant for people to access files hands free in their device using natural language processing.
Voice Based Personal Assistant We have built a Voice based Personal Assistant for people to access files hands free in their device using natural lang
 2 Nov 13, 2021
2 Nov 13, 2021
PyKaldi is a Python scripting layer for the Kaldi speech recognition toolkit.
PyKaldi is a Python scripting layer for the Kaldi speech recognition toolkit. It provides easy-to-use, low-overhead, first-class Python wrappers for t
 922 Dec 31, 2022
922 Dec 31, 2022
Uses Google's gTTS module to easily create robo text readin' on command.
Tool to convert text to speech, creating files for later use. TTRS uses Google's gTTS module to easily create robo text readin' on command.
 0 Jun 20, 2021
0 Jun 20, 2021

Meta-TTS: Meta-Learning for Few-shot SpeakerAdaptive Text-to-Speech
Meta-TTS: Meta-Learning for Few-shot SpeakerAdaptive Text-to-Speech This repository is the official implementation of "Meta-TTS: Meta-Learning for Few
 128 Dec 25, 2022
128 Dec 25, 2022
Official implementation of "Membership Inference Attacks Against Self-supervised Speech Models"
Introduction Official implementation of "Membership Inference Attacks Against Self-supervised Speech Models". In this work, we demonstrate that existi
 7 Nov 1, 2022
7 Nov 1, 2022
Azure Neural Speech Service TTS
Written in Python using the Azure Speech SDK. App.py provides an easy way to create an Text-To-Speech request to Azure Speech and download the wav file. Azure Neural Voices Text-To-Speech enables fluid, natural-sounding text to speech that matches the patterns and intonation of human voices.
 4 Dec 14, 2022
4 Dec 14, 2022
A simple Speech Emotion Recognition (SER) API created using Flask and running in a Docker container.
emovoz Introduction A simple Speech Emotion Recognition (SER) API created using Flask and running in a Docker container. The SER system was built with
 2 Nov 11, 2022
2 Nov 11, 2022
This repository details the steps in creating a Part of Speech tagger using Trigram Hidden Markov Models and the Viterbi Algorithm without using external libraries.
POS-Tagger This repository details the creation of a Part-of-Speech tagger using Trigram Hidden Markov Models to predict word tags in a word sequence.
 1 Dec 9, 2021
1 Dec 9, 2021
Cryptocurrency application that displays instant cryptocurrency prices and reads prices with the Google Text-to-Speech library.
📈 Cryptocurrency Price App 💰 ◽ Cryptocurrency application that displays instant cryptocurrency prices and reads prices with the Google Text-to-Speec
 2 Nov 8, 2021
2 Nov 8, 2021
Ukrainian TTS (text-to-speech) using Coqui TTS
title emoji colorFrom colorTo sdk app_file pinned Ukrainian TTS 🐸 green green gradio app.py false Ukrainian TTS 📢 🤖 Ukrainian TTS (text-to-speech)
85 Dec 26, 2022
On-device speech-to-index engine powered by deep learning.
On-device speech-to-index engine powered by deep learning.
 30 Nov 24, 2022
30 Nov 24, 2022

A Fear and Greed index visualiser for Bitcoin on a SSD1351 OLED Screen
We're Doomed - A Bitcoin Fear and Greed index OLED visualiser Doom is a first-person-shooter from the 1990s. The health status monitor was one of the
 19 Dec 29, 2022
19 Dec 29, 2022
Code for paper: An Effective, Robust and Fairness-awareHate Speech Detection Framework
BiQQLSTM_HS Code and data for paper: Title: An Effective, Robust and Fairness-awareHate Speech Detection Framework. Authors: Guanyi Mou and Kyumin Lee
 2 Dec 27, 2022
2 Dec 27, 2022

Sign-to-Speech for Sign Language Understanding: A case study of Nigerian Sign Language
Sign-to-Speech for Sign Language Understanding: A case study of Nigerian Sign Language This repository contains the code, model, and deployment config
 16 Oct 23, 2022
16 Oct 23, 2022
Cross-lingual Transfer for Speech Processing using Acoustic Language Similarity
Cross-lingual Transfer for Speech Processing using Acoustic Language Similarity Indic TTS Samples can be found at https://peter-yh-wu.github.io/cross-
 1 Nov 12, 2022
1 Nov 12, 2022
Explore different way to mix speech model(wav2vec2, hubert) and nlp model(BART,T5,GPT) together
SpeechMix Explore different way to mix speech model(wav2vec2, hubert) and nlp model(BART,T5,GPT) together. Introduction For the same input: from datas
 31 Nov 7, 2022
31 Nov 7, 2022
PyTorch implementation of "A Two-Stage End-to-End System for Speech-in-Noise Hearing Aid Processing"
Implementation of the Sheffield entry for the first Clarity enhancement challenge (CEC1) This repository contains the PyTorch implementation of "A Two
 10 Aug 19, 2022
10 Aug 19, 2022
Installation, test and evaluation of Scribosermo speech-to-text engine
Scribosermo STT Setup Scribosermo is a LGPL licensed, open-source speech recognition engine to "Train fast Speech-to-Text networks in different langua
 3 Jun 20, 2022
3 Jun 20, 2022

Text to speech converter with GUI made in Python.
Text-to-speech-with-GUI Text to speech converter with GUI made in Python. To run this download the zip file and run the main file or clone this repo.
 1 Nov 15, 2021
1 Nov 15, 2021
Azure Text-to-speech service for Home Assistant
Azure Text-to-speech service for Home Assistant The Azure text-to-speech platform uses online Azure Text-to-Speech cognitive service to read a text wi
 2 Aug 6, 2022
2 Aug 6, 2022
Terminal-based audio-to-text converter
att Terminal-based audio-to-text converter Project description A terminal-based audio-to-text converter written in python, enabling you to convert .wa
 4 Dec 15, 2022
4 Dec 15, 2022
Simple, hackable offline speech to text - using the VOSK-API.
Simple, hackable offline speech to text - using the VOSK-API.
 844 Jan 7, 2023
844 Jan 7, 2023
Simple Speech to Text, Text to Speech
Simple Speech to Text, Text to Speech 1. Download Repository Opsi 1 Download repository ini, extract di lokasi yang diinginkan Opsi 2 Jika sudah famil
 5 Dec 28, 2021
5 Dec 28, 2021
The PyTorch based implementation of continuous integrate-and-fire (CIF) module.
CIF-PyTorch This is a PyTorch based implementation of continuous integrate-and-fire (CIF) module for end-to-end (E2E) automatic speech recognition (AS
 24 Dec 29, 2022
24 Dec 29, 2022
Cobra is a highly-accurate and lightweight voice activity detection (VAD) engine.
On-device voice activity detection (VAD) powered by deep learning.
88 Dec 16, 2022
SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch.
The SpeechBrain Toolkit SpeechBrain is an open-source and all-in-one speech toolkit based on PyTorch. The goal is to create a single, flexible, and us
 5.1k Jan 2, 2023
5.1k Jan 2, 2023
🤗 Transformers: State-of-the-art Natural Language Processing for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Natural Language Processing for Jax, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrai
77.4k Jan 5, 2023

PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Cross-Speaker-Emotion-Transfer - PyTorch Implementation PyTorch Implementation of ByteDance's Cross-speaker Emotion Transfer Based on Speaker Conditio
 114 Jan 8, 2023
114 Jan 8, 2023

Awesome Spectral Indices in Python.
Awesome Spectral Indices in Python: Numpy | Pandas | GeoPandas | Xarray | Earth Engine | Planetary Computer | Dask GitHub: https://github.com/davemlz/
 98 Jan 2, 2023
98 Jan 2, 2023
A flask application to predict the speech emotion of any .wav file.
This is a speech emotion recognition app. It will allow you to train a modular MLP model with the RAVDESS dataset, and then use that model with a flask application to predict the speech emotion of any .wav file.
 2 Dec 15, 2021
2 Dec 15, 2021

Official implementation of the paper: "LDNet: Unified Listener Dependent Modeling in MOS Prediction for Synthetic Speech"
LDNet Author: Wen-Chin Huang (Nagoya University) Email: [email protected] This is the official implementation of the paper "LDNet
 40 Nov 20, 2022
40 Nov 20, 2022
A simple Blog Using Django Framework and Used IBM Cloud Services for Text Analysis and Text to Speech
ElhamBlog Cloud Computing Course first assignment. A simple Blog Using Django Framework and Used IBM Cloud Services for Text Analysis and Text to Spee
 5 Dec 6, 2022
5 Dec 6, 2022
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge
Neural Lexicon Reader: Reduce Pronunciation Errors in End-to-end TTS by Leveraging External Textual Knowledge This is an implementation of the paper,
19 Oct 14, 2022