662 Repositories
Python turkish-nlp Libraries
An API that uses NLP and AI to let you predict possible diseases and symptoms based on a prompt of what you're feeling.
Disease detection API for MediSearch An API that uses NLP and AI to let you predict possible diseases and symptoms based on a prompt of what you're fe
 1 Jan 15, 2022
1 Jan 15, 2022
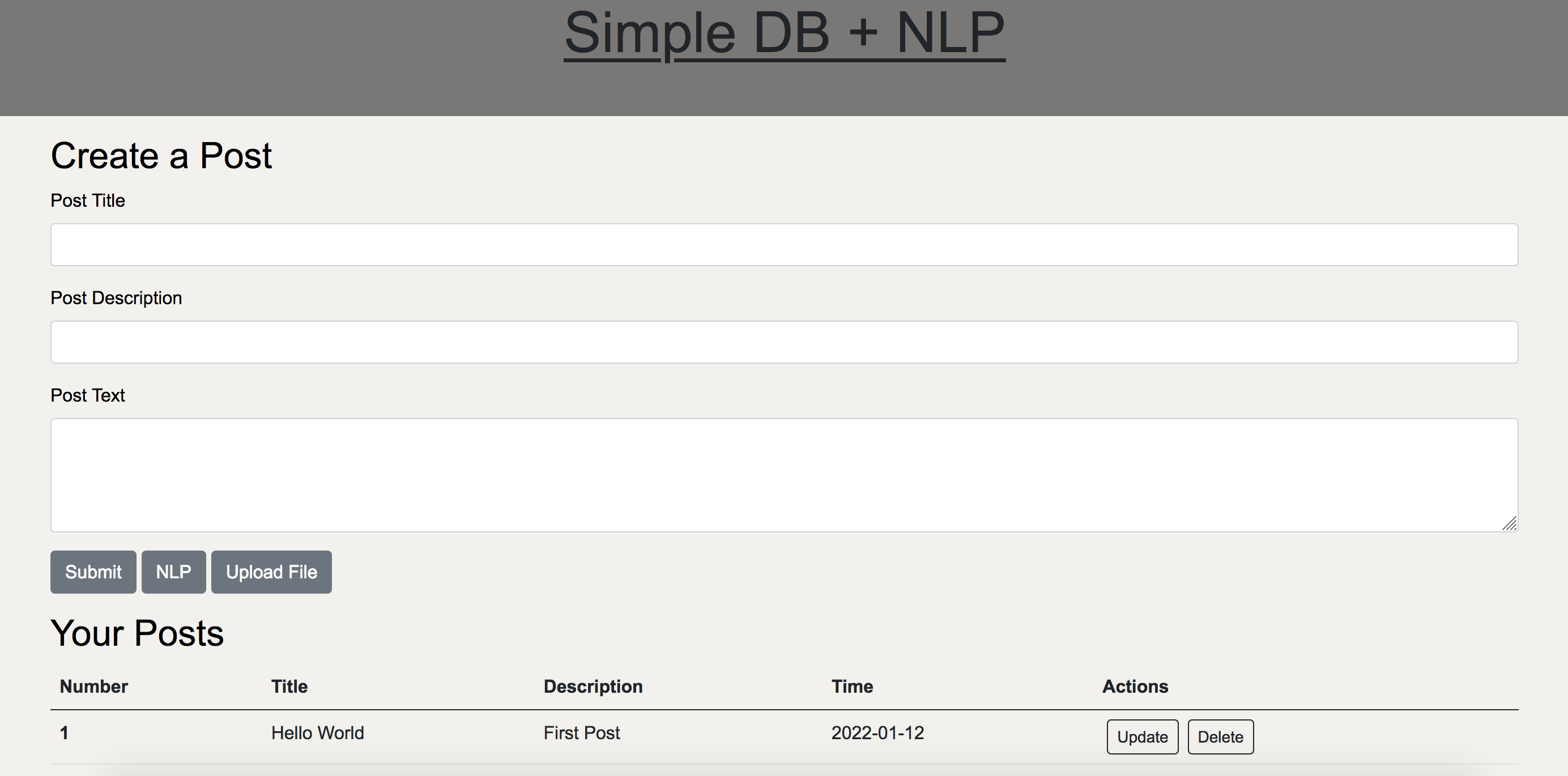
A simple Flask site that allows users to create, update, and delete posts in a database, as well as perform basic NLP tasks on the posts.
A simple Flask site that allows users to create, update, and delete posts in a database, as well as perform basic NLP tasks on the posts.
 1 Jan 15, 2022
1 Jan 15, 2022
NLP: SLU tagging
NLP: SLU tagging
 3 Jan 14, 2022
3 Jan 14, 2022

auto_code_complete is a auto word-completetion program which allows you to customize it on your need
auto_code_complete v1.3 purpose and usage auto_code_complete is a auto word-completetion program which allows you to customize it on your needs. the m
 2 Feb 22, 2022
2 Feb 22, 2022

Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021)
TDEER 🦌 🦒 Official Code For TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations (EMNLP2021) Overview TDEE
 33 Dec 23, 2022
33 Dec 23, 2022

Lbl2Vec learns jointly embedded label, document and word vectors to retrieve documents with predefined topics from an unlabeled document corpus.
Lbl2Vec Lbl2Vec is an algorithm for unsupervised document classification and unsupervised document retrieval. It automatically generates jointly embed
 61 Dec 20, 2022
61 Dec 20, 2022
👄 The most accurate natural language detection library for Python, suitable for long and short text alike
1. What does this library do? Its task is simple: It tells you which language some provided textual data is written in. This is very useful as a prepr
 334 Dec 30, 2022
334 Dec 30, 2022

Sentiment-Analysis and EDA on the IMDB Movie Review Dataset
Sentiment-Analysis and EDA on the IMDB Movie Review Dataset The main part of the work focuses on the exploration and study of different approaches whi
 1 Jan 12, 2022
1 Jan 12, 2022
Mapping a variable-length sentence to a fixed-length vector using BERT model
Are you looking for X-as-service? Try the Cloud-Native Neural Search Framework for Any Kind of Data bert-as-service Using BERT model as a sentence enc
 11.1k Jan 1, 2023
11.1k Jan 1, 2023
HuSpaCy: industrial-strength Hungarian natural language processing
HuSpaCy: Industrial-strength Hungarian NLP HuSpaCy is a spaCy model and a library providing industrial-strength Hungarian language processing faciliti
 120 Dec 14, 2022
120 Dec 14, 2022
Exploration of BERT-based models on twitter sentiment classifications
twitter-sentiment-analysis Explore the relationship between twitter sentiment of Tesla and its stock price/return. Explore the effect of different BER
 2 Oct 2, 2022
2 Oct 2, 2022
Natural Language Processing Best Practices & Examples
NLP Best Practices In recent years, natural language processing (NLP) has seen quick growth in quality and usability, and this has helped to drive bus
 6.1k Dec 31, 2022
6.1k Dec 31, 2022
Code and data accompanying Natural Language Processing with PyTorch
Natural Language Processing with PyTorch Build Intelligent Language Applications Using Deep Learning By Delip Rao and Brian McMahan Welcome. This is a
 1.8k Jan 1, 2023
1.8k Jan 1, 2023

Gathers machine learning and Tensorflow deep learning models for NLP problems, 1.13 Tensorflow 2.0
NLP-Models-Tensorflow, Gathers machine learning and tensorflow deep learning models for NLP problems, code simplify inside Jupyter Notebooks 100%. Tab
 1.7k Dec 30, 2022
1.7k Dec 30, 2022
Trained T5 and T5-large model for creating keywords from text
text to keywords Trained T5-base and T5-large model for creating keywords from text. Supported languages: ru Pretraining Large version | Pretraining B
 61 Nov 24, 2022
61 Nov 24, 2022
Auto_code_complete is a auto word-completetion program which allows you to customize it on your needs
auto_code_complete is a auto word-completetion program which allows you to customize it on your needs. the model for this program is one of the deep-learning NLP(Natural Language Process) model structure called 'GRU(gated recurrent unit)'.
2 Feb 22, 2022

Beyond Accuracy: Behavioral Testing of NLP models with CheckList
CheckList This repository contains code for testing NLP Models as described in the following paper: Beyond Accuracy: Behavioral Testing of NLP models
 1.8k Dec 28, 2022
1.8k Dec 28, 2022

Datasets, tools, and benchmarks for representation learning of code.
The CodeSearchNet challenge has been concluded We would like to thank all participants for their submissions and we hope that this challenge provided
 1.8k Dec 25, 2022
1.8k Dec 25, 2022

Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch
Jupyter Notebook tutorials on solving real-world problems with Machine Learning & Deep Learning using PyTorch. Topics: Face detection with Detectron 2, Time Series anomaly detection with LSTM Autoencoders, Object Detection with YOLO v5, Build your first Neural Network, Time Series forecasting for Coronavirus daily cases, Sentiment Analysis with BERT.
 1.8k Dec 31, 2022
1.8k Dec 31, 2022
A Practitioner's Guide to Natural Language Processing
Learn how to process, classify, cluster, summarize, understand syntax, semantics and sentiment of text data with the power of Python! This repository contains code and datasets used in my book, Text Analytics with Python published by Apress/Springer.
 1.5k Jan 3, 2023
1.5k Jan 3, 2023
Mycroft Core, the Mycroft Artificial Intelligence platform.
Mycroft Mycroft is a hackable open source voice assistant. Table of Contents Getting Started Running Mycroft Using Mycroft Home Device and Account Man
 6.1k Jan 9, 2023
6.1k Jan 9, 2023
A list of NLP(Natural Language Processing) tutorials
NLP Tutorial A list of NLP(Natural Language Processing) tutorials built on PyTorch. Table of Contents A step-by-step tutorial on how to implement and
 1.3k Dec 25, 2022
1.3k Dec 25, 2022

Keras implementation of "One pixel attack for fooling deep neural networks" using differential evolution on Cifar10 and ImageNet
One Pixel Attack How simple is it to cause a deep neural network to misclassify an image if an attacker is only allowed to modify the color of one pix
 1.2k Dec 26, 2022
1.2k Dec 26, 2022

Chinese version of GPT2 training code, using BERT tokenizer.
GPT2-Chinese Description Chinese version of GPT2 training code, using BERT tokenizer or BPE tokenizer. It is based on the extremely awesome repository
 5.6k Jan 4, 2023
5.6k Jan 4, 2023
NLP techniques such as named entity recognition, sentiment analysis, topic modeling, text classification with Python to predict sentiment and rating of drug from user reviews.
This file contains the following documents sumbited for Baruch CIS9665 group 9 fall 2021. 1. Dataset: drug_reviews.csv 2. python codes for text classi
 2 Jan 4, 2023
2 Jan 4, 2023

Repository for Project Insight: NLP as a Service
Project Insight NLP as a Service Contents Introduction Features Installation Setup and Documentation Project Details Demonstration Directory Details H
 286 Dec 6, 2022
286 Dec 6, 2022
Simple translation demo showcasing our headliner package.
Headliner Demo This is a demo showcasing our Headliner package. In particular, we trained a simple seq2seq model on an English-German dataset. We didn
 16 Nov 24, 2022
16 Nov 24, 2022

Rhyme with AI
Local development Create a conda virtual environment and activate it: conda env create --file environment.yml conda activate rhyme-with-ai Install the
 28 Nov 21, 2022
28 Nov 21, 2022
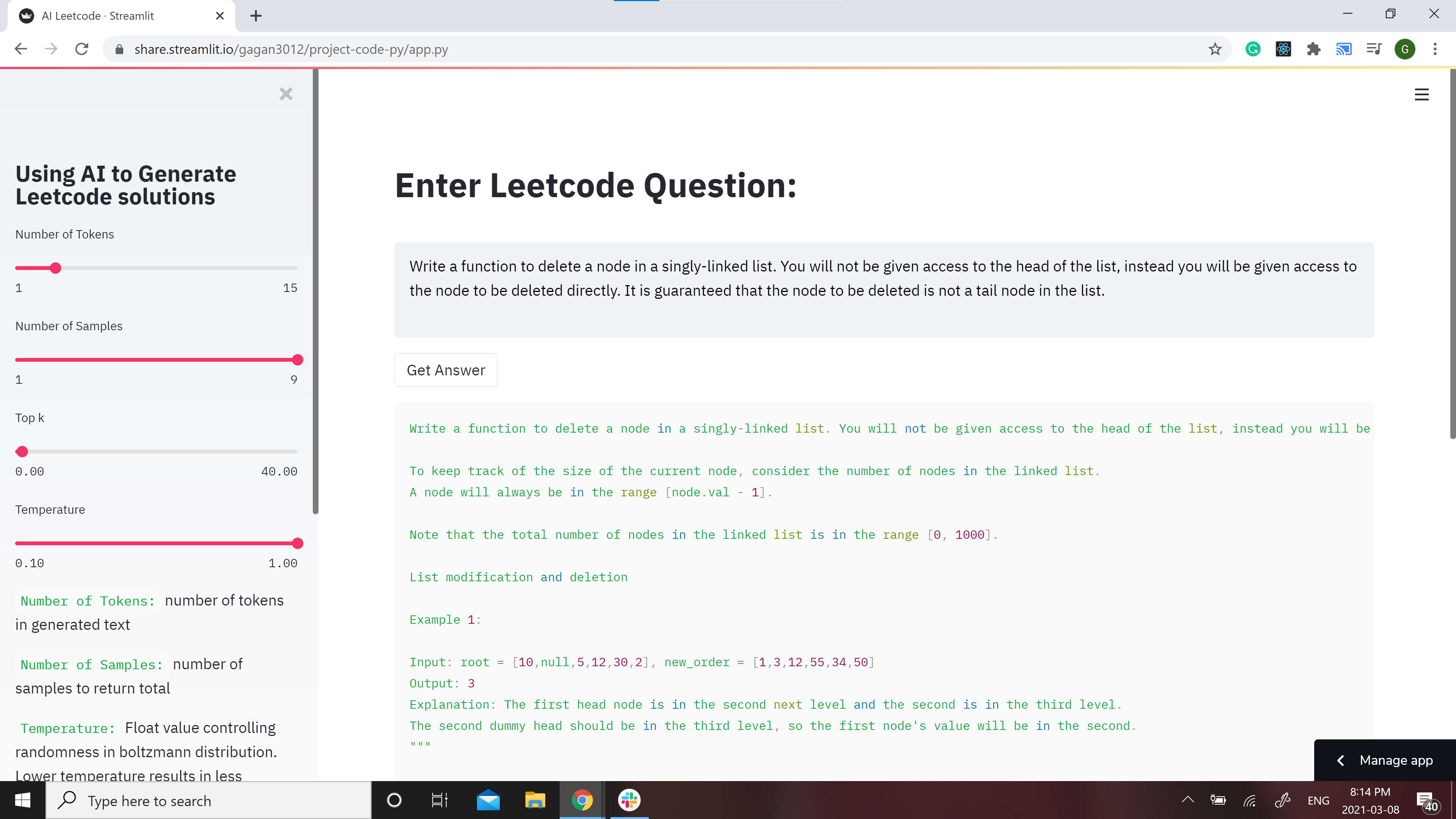
GPT-2 Model for Leetcode Questions in python
Leetcode using AI 🤖 GPT-2 Model for Leetcode Questions in python New demo here: https://huggingface.co/spaces/gagan3012/project-code-py Note: the Ans
 100 Dec 12, 2022
100 Dec 12, 2022

👑 spaCy building blocks and visualizers for Streamlit apps
spacy-streamlit: spaCy building blocks for Streamlit apps This package contains utilities for visualizing spaCy models and building interactive spaCy-
 620 Dec 29, 2022
620 Dec 29, 2022

Two-stage text summarization with BERT and BART
Two-Stage Text Summarization Description We experiment with a 2-stage summarization model on CNN/DailyMail dataset that combines the ability to filter
 6 Oct 22, 2022
6 Oct 22, 2022
Using BERT-based models for toxic span detection
SemEval 2021 Task 5: Toxic Spans Detection: Task: Link to SemEval-2021: Task 5 Toxic Span Detection is https://competitions.codalab.org/competitions/2
 1 Jan 4, 2022
1 Jan 4, 2022
This repository focus on Image Captioning & Video Captioning & Seq-to-Seq Learning & NLP
Awesome-Visual-Captioning Table of Contents ACL-2021 CVPR-2021 AAAI-2021 ACMMM-2020 NeurIPS-2020 ECCV-2020 CVPR-2020 ACL-2020 AAAI-2020 ACL-2019 NeurI
 362 Jan 3, 2023
362 Jan 3, 2023

NLP-Project - Used an API to scrape 2000 reddit posts, then used NLP analysis and created a classification model to mixed succcess
Project 3: Web APIs & NLP Problem Statement How do r/Libertarian and r/Neoliberal differ on Biden post-inaguration? The goal of the project is to see
 2 Mar 29, 2022
2 Mar 29, 2022
NLP-SentimentAnalysis - Coursera Course ( Duration : 5 weeks ) offered by DeepLearning.AI
Coursera Natural Language Processing Specialization This repository contains material related to Coursera Natural Language Processing Specialization.
 1 Jun 5, 2022
1 Jun 5, 2022
Awesome Artificial Intelligence, Machine Learning and Deep Learning as we learn it
Awesome Artificial Intelligence, Machine Learning and Deep Learning as we learn it. Study notes and a curated list of awesome resources of such topics.
 1.2k Jan 7, 2023
1.2k Jan 7, 2023

Speech-Emotion-Analyzer - The neural network model is capable of detecting five different male/female emotions from audio speeches. (Deep Learning, NLP, Python)
Speech Emotion Analyzer The idea behind creating this project was to build a machine learning model that could detect emotions from the speech we have
 965 Dec 24, 2022
965 Dec 24, 2022

KoBERT - Korean BERT pre-trained cased (KoBERT)
KoBERT KoBERT Korean BERT pre-trained cased (KoBERT) Why'?' Training Environment Requirements How to install How to use Using with PyTorch Using with
 1k Jan 2, 2023
1k Jan 2, 2023
News-Articles-and-Essays - NLP (Topic Modeling and Clustering)
NLP T5 Project proposal Topic Modeling and Clustering of News-Articles-and-Essays Students: Nasser Alshehri Abdullah Bushnag Abdulrhman Alqurashi OVER
 2 Jan 18, 2022
2 Jan 18, 2022
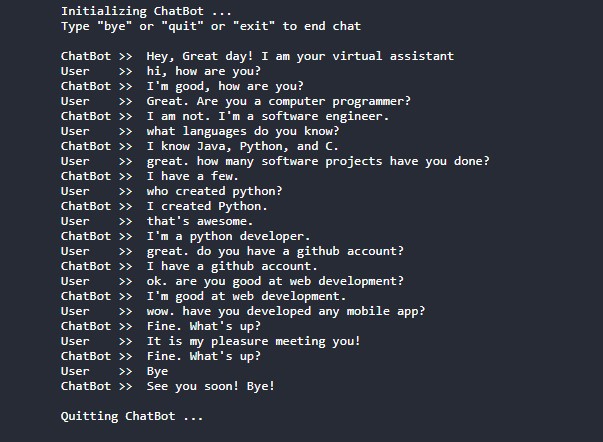
Conversational-AI-ChatBot - Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users!
Conversational AI ChatBot Intelligent ChatBot built with Microsoft's DialoGPT transformer to make conversations with human users! In this project? Thi
 6 Nov 30, 2022
6 Nov 30, 2022
A recommendation system for suggesting new books given similar books.
Book Recommendation System A recommendation system for suggesting new books given similar books. Datasets Dataset Kaggle Dataset Notebooks goodreads-E
 2 Jan 6, 2022
2 Jan 6, 2022

Search-Engine - 📖 AI based search engine
Search Engine AI based search engine that was trained on 25000 samples, feel free to train on up to 1.2M sample from kaggle dataset, link below StackS
 2 Nov 29, 2022
2 Nov 29, 2022

A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
A list of NLP(Natural Language Processing) tutorials built on Tensorflow 2.0.
 335 Jan 4, 2023
335 Jan 4, 2023

Natural Language Processing for Adverse Drug Reaction (ADR) Detection
Natural Language Processing for Adverse Drug Reaction (ADR) Detection This repo contains code from a project to identify ADRs in discharge summaries a
 21 Aug 5, 2022
21 Aug 5, 2022
Ecco is a python library for exploring and explaining Natural Language Processing models using interactive visualizations.
Visualize, analyze, and explore NLP language models. Ecco creates interactive visualizations directly in Jupyter notebooks explaining the behavior of Transformer-based language models (like GPT2, BERT, RoBERTA, T5, and T0).
 1.6k Dec 25, 2022
1.6k Dec 25, 2022
Python library for parsing resumes using natural language processing and machine learning
CVParser Python library for parsing resumes using natural language processing and machine learning. Setup Installation on Linux and Mac OS Follow the
 0 Jul 29, 2021
0 Jul 29, 2021

NLP project that works with news (NER, context generation, news trend analytics)
СоАвтор СоАвтор – платформа и открытый набор инструментов для редакций и журналистов-фрилансеров, который призван сделать процесс создания контента ма
 38 Jan 4, 2023
38 Jan 4, 2023

For storing the complete exploration of Visual Question Answering for our B.Tech Project
Multi-Image vqa @authors: Akhilesh, Janhavi, Harsh Paper summary, Ideas tried and their corresponding results: on wiki Other discussions: on discussio
 3 Jun 16, 2022
3 Jun 16, 2022
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
Develop open-source Python Arabic NLP libraries that the Arab world will easily use in all Natural Language Processing applications
 2 Oct 22, 2022
2 Oct 22, 2022
txtai: Build AI-powered semantic search applications in Go
txtai: Build AI-powered semantic search applications in Go txtai executes machine-learning workflows to transform data and build AI-powered semantic s
 49 Dec 6, 2022
49 Dec 6, 2022
Fast, DB Backed pretrained word embeddings for natural language processing.
Embeddings Embeddings is a python package that provides pretrained word embeddings for natural language processing and machine learning. Instead of lo
 212 Nov 21, 2022
212 Nov 21, 2022

Multilingual word vectors in 78 languages
Aligning the fastText vectors of 78 languages Facebook recently open-sourced word vectors in 89 languages. However these vectors are monolingual; mean
 1.2k Dec 17, 2022
1.2k Dec 17, 2022
An automated program that helps customers of Pizza Palour place their pizza orders
PIzza_Order_Assistant Introduction An automated program that helps customers of Pizza Palour place their pizza orders. The program uses voice commands
 1 Dec 26, 2021
1 Dec 26, 2021
jiant is an NLP toolkit
🚨 Update 🚨 : As of 2021/10/17, the jiant project is no longer being actively maintained. This means there will be no plans to add new models, tasks,
 1.5k Dec 28, 2022
1.5k Dec 28, 2022
A modified Sequential and NLP based Bot
A modified Sequential and NLP based Bot I improvised this bot a bit with some implementations as a part of my own hobby project :) Note: I do not own
 2 Jan 7, 2022
2 Jan 7, 2022
A Lightweight NLP Data Loader for All Deep Learning Frameworks in Python
LineFlow: Framework-Agnostic NLP Data Loader in Python LineFlow is a simple text dataset loader for NLP deep learning tasks. LineFlow was designed to
 177 Jan 4, 2023
177 Jan 4, 2023

Spokestack is a library that allows a user to easily incorporate a voice interface into any Python application with a focus on embedded systems.
Welcome to Spokestack Python! This library is intended for developing voice interfaces in Python. This can include anything from Raspberry Pi applicat
 133 Sep 20, 2022
133 Sep 20, 2022

Fast and robust date extraction from web pages, with Python or on the command-line
Find original and updated publication dates of any web page. From the command-line or within Python, all the steps needed from web page download to HTML parsing, scraping, and text analysis are included.
 60 Dec 14, 2022
60 Dec 14, 2022
Practical Natural Language Processing Tools for Humans is build on the top of Senna Natural Language Processing (NLP)
Practical Natural Language Processing Tools for Humans is build on the top of Senna Natural Language Processing (NLP) predictions: part-of-speech (POS) tags, chunking (CHK), name entity recognition (NER), semantic role labeling (SRL) and syntactic parsing (PSG) with skip-gram all in Python and still more features will be added. The website give is for downlarding Senna tool
 20 Apr 30, 2022
20 Apr 30, 2022
Simple multilingual lemmatizer for Python, especially useful for speed and efficiency
Simplemma: a simple multilingual lemmatizer for Python Purpose Lemmatization is the process of grouping together the inflected forms of a word so they
70 Dec 29, 2022
Faster, modernized fork of the language identification tool langid.py
py3langid py3langid is a fork of the standalone language identification tool langid.py by Marco Lui. Original license: BSD-2-Clause. Fork license: BSD
12 Nov 5, 2022

Quick insights from Zoom meeting transcripts using Graph + NLP
Transcript Analysis - Graph + NLP This program extracts insights from Zoom Meeting Transcripts (.vtt) using TigerGraph and NLTK. In order to run this
 7 Sep 17, 2022
7 Sep 17, 2022
Unofficial Python library for using the Polish Wordnet (plWordNet / Słowosieć)
Polish Wordnet Python library Simple, easy-to-use and reasonably fast library for using the Słowosieć (also known as PlWordNet) - a lexico-semantic da
 12 Dec 23, 2022
12 Dec 23, 2022
Turkish Stop Words Türkçe Dolgu Sözcükleri
trstop Turkish Stop Words Türkçe Dolgu Sözcükleri In this repository I put Turkish stop words that is contained in the first 10 thousand words with th
 103 Nov 12, 2022
103 Nov 12, 2022
A Japanese tokenizer based on recurrent neural networks
Nagisa is a python module for Japanese word segmentation/POS-tagging. It is designed to be a simple and easy-to-use tool. This tool has the following
 325 Jan 5, 2023
325 Jan 5, 2023
Crawl BookCorpus
These are scripts to reproduce BookCorpus by yourself.
 590 Jan 3, 2023
590 Jan 3, 2023

⛵️The official PyTorch implementation for "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing" (EMNLP 2020).
BERT-of-Theseus Code for paper "BERT-of-Theseus: Compressing BERT by Progressive Module Replacing". BERT-of-Theseus is a new compressed BERT by progre
 284 Nov 25, 2022
284 Nov 25, 2022
Basic yet complete Machine Learning pipeline for NLP tasks
Basic yet complete Machine Learning pipeline for NLP tasks This repository accompanies the article on building basic yet complete ML pipelines for sol
 20 Aug 22, 2022
20 Aug 22, 2022
Code for the project carried out fulfilling the course requirements for Fall 2021 NLP at NYU
Introduction Fairseq(-py) is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization,
 1 Apr 25, 2022
1 Apr 25, 2022

Sentiment Analysis web app using Streamlit - American Airlines Tweets
Analyse des sentiments à partir des Tweets L'application est développée par Streamlit L'analyse sentimentale est effectuée sur l'ensemble de données d
 2 Feb 4, 2022
2 Feb 4, 2022
The source code of "Language Models are Few-shot Multilingual Learners" (MRL @ EMNLP 2021)
Language Models are Few-shot Multilingual Learners Paper This is the source code of the paper [Arxiv] [ACL Anthology]: This code has been written usin
 45 Nov 21, 2022
45 Nov 21, 2022
Lightweight utility tools for the detection of multiple spellings, meanings, and language-specific terminology in British and American English
Breame ( British English and American English) Breame is a lightweight Python package with a number of utility tools to aid in the detection of words
 8 Oct 10, 2022
8 Oct 10, 2022
Materials (slides, code, assignments) for the NYU class I teach on NLP and ML Systems (Master of Engineering).
FREE_7773 Repo containing material for the NYU class (Master of Engineering) I teach on NLP, ML Sys etc. For context on what the class is trying to ac
 90 Dec 19, 2022
90 Dec 19, 2022
BARTpho: Pre-trained Sequence-to-Sequence Models for Vietnamese
Table of contents Introduction Using BARTpho with fairseq Using BARTpho with transformers Notes BARTpho: Pre-trained Sequence-to-Sequence Models for V
 58 Dec 23, 2022
58 Dec 23, 2022
Contains links to publicly available datasets for modeling health outcomes using speech and language.
speech-nlp-datasets Contains links to publicly available datasets for modeling various health outcomes using speech and language. Speech-based Corpora
 77 Dec 7, 2022
77 Dec 7, 2022

A PyTorch-based model pruning toolkit for pre-trained language models
English | 中文说明 TextPruner是一个为预训练语言模型设计的模型裁剪工具包,通过轻量、快速的裁剪方法对模型进行结构化剪枝,从而实现压缩模型体积、提升模型速度。 其他相关资源: 知识蒸馏工具TextBrewer:https://github.com/airaria/TextBrewe
 231 Jan 8, 2023
231 Jan 8, 2023
BERT, LDA, and TFIDF based keyword extraction in Python
BERT, LDA, and TFIDF based keyword extraction in Python kwx is a toolkit for multilingual keyword extraction based on Google's BERT and Latent Dirichl
 41 Dec 27, 2022
41 Dec 27, 2022

BERT-based Financial Question Answering System
BERT-based Financial Question Answering System In this example, we use Jina, PyTorch, and Hugging Face transformers to build a production-ready BERT-b
 61 Sep 18, 2022
61 Sep 18, 2022
Chinese NER with albert/electra or other bert descendable model (keras)
Chinese NLP (albert/electra with Keras) Named Entity Recognization Project Structure ./ ├── NER │ ├── __init__.py │ ├── log
 2 Nov 20, 2022
2 Nov 20, 2022

Label data using HuggingFace's transformers and automatically get a prediction service
Label Studio for Hugging Face's Transformers Website • Docs • Twitter • Join Slack Community Transfer learning for NLP models by annotating your textu
 135 Dec 29, 2022
135 Dec 29, 2022

Code for CodeT5: a new code-aware pre-trained encoder-decoder model.
CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation This is the official PyTorch implementation
 564 Jan 8, 2023
564 Jan 8, 2023
The code for the Subformer, from the EMNLP 2021 Findings paper: "Subformer: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers", by Machel Reid, Edison Marrese-Taylor, and Yutaka Matsuo
Subformer This repository contains the code for the Subformer. To help overcome this we propose the Subformer, allowing us to retain performance while
 10 Dec 27, 2022
10 Dec 27, 2022
Transcribing audio files using Hugging Face's implementation of Wav2Vec2 + "chain-linking" NLP tasks to combine speech-to-text with downstream tasks like translation and summarisation.
PART 2: CHAIN LINKING AUDIO-TO-TEXT NLP TASKS 2A: TRANSCRIBE-TRANSLATE-SENTIMENT-ANALYSIS In notebook3.0, I demo a simple workflow to: transcribe a lo
 30 Jul 13, 2022
30 Jul 13, 2022
🤗 Transformers: State-of-the-art Machine Learning for Pytorch, TensorFlow, and JAX.
English | 简体中文 | 繁體中文 | 한국어 State-of-the-art Machine Learning for JAX, PyTorch and TensorFlow 🤗 Transformers provides thousands of pretrained models
 77.1k Dec 31, 2022
77.1k Dec 31, 2022
Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
Hiring We are hiring at all levels (including FTE researchers and interns)! If you are interested in working with us on NLP and large-scale pre-traine
7.8k Jan 9, 2023
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA Introduction ELECTRA is a method for self-supervised language representation learning. It can be used to pre-train transformer networks using
 2.1k Dec 28, 2022
2.1k Dec 28, 2022

Awesome Treasure of Transformers Models Collection
💁 Awesome Treasure of Transformers Models for Natural Language processing contains papers, videos, blogs, official repo along with colab Notebooks. 🛫☑️
 577 Jan 7, 2023
577 Jan 7, 2023

Text Classification in Turkish Texts with Bert
You can watch the details of the project on my youtube channel Project Interface Project Second Interface Goal= Correctly guessing the classification
 42 Dec 31, 2022
42 Dec 31, 2022

The projects lets you extract glossary words and their definitions from a given piece of text automatically using NLP techniques
Unsupervised technique to Glossary and Definition Extraction Code Files GPT2-DefinitionModel.ipynb - GPT-2 model for definition generation. Data_Gener
 28 May 25, 2021
28 May 25, 2021

Powerful unsupervised domain adaptation method for dense retrieval.
Powerful unsupervised domain adaptation method for dense retrieval
 191 Dec 28, 2022
191 Dec 28, 2022
Converts a Bangla numeric string to literal words.
Bangla Number in Words Converts a Bangla numeric string to literal words. Install $ pip install banglanum2words Usage
 3 Aug 29, 2022
3 Aug 29, 2022
Text completion with Hugging Face and TensorFlow.js running on Node.js
Katana ML Text Completion 🤗 Description Runs with with Hugging Face DistilBERT and TensorFlow.js on Node.js distilbert-model - converter from Hugging
 2 Nov 4, 2022
2 Nov 4, 2022
Using Bert as the backbone model for lime, designed for NLP task explanation (sentence pair text classification task)
Lime Comparing deep contextualized model for sentences highlighting task. In addition, take the classic explanation model "LIME" with bert-base model
 2 Jan 18, 2022
2 Jan 18, 2022
ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab
AliceMind AliceMind: ALIbaba's Collection of Encoder-decoders from MinD (Machine IntelligeNce of Damo) Lab This repository provides pre-trained encode
 1.4k Jan 1, 2023
1.4k Jan 1, 2023

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
keytotext Idea is to build a model which will take keywords as inputs and generate sentences as outputs. Potential use case can include: Marketing Sea
364 Jan 3, 2023

A toolkit for document-level event extraction, containing some SOTA model implementations
Document-level Event Extraction via Heterogeneous Graph-based Interaction Model with a Tracker Source code for ACL-IJCNLP 2021 Long paper: Document-le
 84 Dec 15, 2022
84 Dec 15, 2022
RCT-ART is an NLP pipeline built with spaCy for converting clinical trial result sentences into tables through jointly extracting intervention, outcome and outcome measure entities and their relations.
Randomised controlled trial abstract result tabulator RCT-ART is an NLP pipeline built with spaCy for converting clinical trial result sentences into
 2 Sep 16, 2022
2 Sep 16, 2022

NLP tool to extract emotional phrase from tweets 🤩
Emotional phrase extractor Extract phrase in the given text that is used to express the sentiment. Capturing sentiment in language is important in the
 38 Oct 17, 2022
38 Oct 17, 2022
Continuously update some NLP practice based on different tasks.
NLP_practice We will continuously update some NLP practice based on different tasks. prerequisites Software pytorch = 1.10 torchtext = 0.11.0 sklear
 0 Jan 5, 2022
0 Jan 5, 2022

State-of-the-art NLP through transformer models in a modular design and consistent APIs.
Trapper (Transformers wRAPPER) Trapper is an NLP library that aims to make it easier to train transformer based models on downstream tasks. It wraps h
 42 Sep 21, 2022
42 Sep 21, 2022