907 Repositories
Python nlp-datasets Libraries
Lyrics generation with GPT2-based Transformer
HuggingArtists - Train a model to generate lyrics Create AI-Artist in just 5 minutes! 🚀 Run the demo notebook to train 🚀 Run the GUI demo to test Di
 65 Dec 19, 2022
65 Dec 19, 2022

Accelerated NLP pipelines for fast inference on CPU and GPU. Built with Transformers, Optimum and ONNX Runtime.
Optimum Transformers Accelerated NLP pipelines for fast inference 🚀 on CPU and GPU. Built with 🤗 Transformers, Optimum and ONNX runtime. Installatio
115 Dec 16, 2022

Entity Disambiguation as text extraction (ACL 2022)
ExtEnD: Extractive Entity Disambiguation This repository contains the code of ExtEnD: Extractive Entity Disambiguation, a novel approach to Entity Dis
 121 Jan 3, 2023
121 Jan 3, 2023

A multi-lingual approach to AllenNLP CoReference Resolution along with a wrapper for spaCy.
Crosslingual Coreference Coreference is amazing but the data required for training a model is very scarce. In our case, the available training for non
 71 Jan 4, 2023
71 Jan 4, 2023

ACL'22: Structured Pruning Learns Compact and Accurate Models
☕ CoFiPruning: Structured Pruning Learns Compact and Accurate Models This repository contains the code and pruned models for our ACL'22 paper Structur
 130 Jan 4, 2023
130 Jan 4, 2023
Curso práctico: NLP de cero a cien 🤗
Curso Práctico: NLP de cero a cien Comprende todos los conceptos y arquitecturas clave del estado del arte del NLP y aplícalos a casos prácticos utili
 147 Jan 6, 2023
147 Jan 6, 2023

This repository consists of a complete guide on natural language processing (NLP) in Python where we'll learn various techniques for implementing NLP including parsing & text processing and understand how to use NLP for text feature engineering.
Python_Natural_Language_Processing This repository contains tutorials on important topics related to Natural Language Processing (NPL). No. Name 01 01
 170 Dec 13, 2022
170 Dec 13, 2022

Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition:
Multi-Type-TD-TSR Check it out on Source Code of our Paper: Multi-Type-TD-TSR Extracting Tables from Document Images using a Multi-stage Pipeline for
 178 Dec 27, 2022
178 Dec 27, 2022

MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts (ICLR 2022)
MetaShift: A Dataset of Datasets for Evaluating Distribution Shifts and Training Conflicts This repo provides the PyTorch source code of our paper: Me
 88 Jan 4, 2023
88 Jan 4, 2023
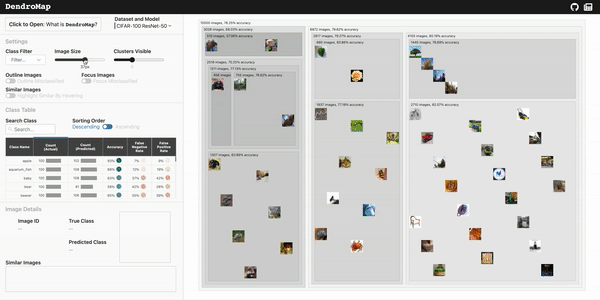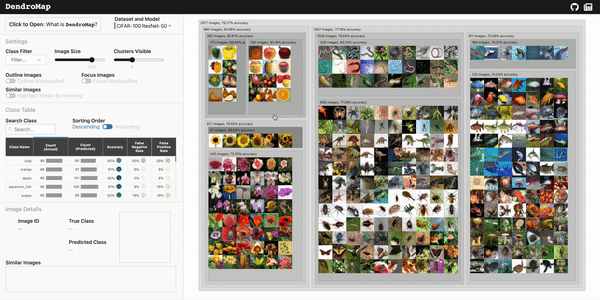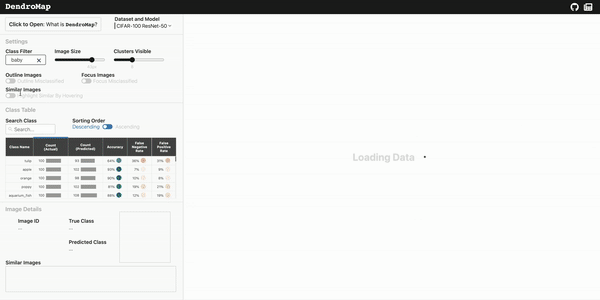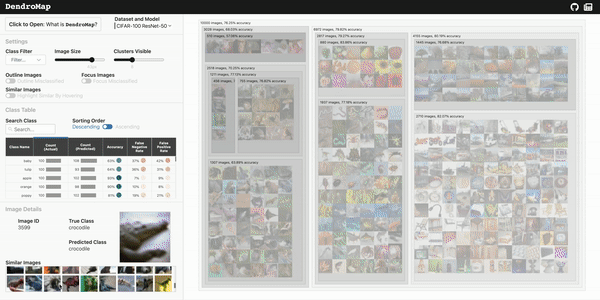
This repository contains the DendroMap implementation for scalable and interactive exploration of image datasets in machine learning.
DendroMap DendroMap is an interactive tool to explore large-scale image datasets used for machine learning. A deep understanding of your data can be v
 33 Dec 30, 2022
33 Dec 30, 2022

Building a real-time environment using webcam frame division in OpenCV and classify cropped images using a fine-tuned vision transformers on hybryd datasets samples for facial emotion recognition.
Visual Transformer for Facial Emotion Recognition (FER) This project has the aim to build an efficient Visual Transformer for the Facial Emotion Recog
 8 Dec 12, 2022
8 Dec 12, 2022
An easy-to-use framework for BERT models, with trainers, various NLP tasks and detailed annonations
FantasyBert English | 中文 Introduction An easy-to-use framework for BERT models, with trainers, various NLP tasks and detailed annonations. You can imp
 137 Oct 26, 2022
137 Oct 26, 2022
An attempt to map the areas with active conflict in Ukraine using open source twitter data.
Live Action Map (LAM) An attempt to use open source data on Twitter to map areas with active conflict. Right now it is used for the Ukraine-Russia con
 171 Nov 21, 2022
171 Nov 21, 2022
A Python library that enables ML teams to share, load, and transform data in a collaborative, flexible, and efficient way :chestnut:
Squirrel Core Share, load, and transform data in a collaborative, flexible, and efficient way What is Squirrel? Squirrel is a Python library that enab
 249 Dec 7, 2022
249 Dec 7, 2022
My Implementation for the paper EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks using Tensorflow
Easy Data Augmentation Implementation This repository contains my Implementation for the paper EDA: Easy Data Augmentation Techniques for Boosting Per
 9 Oct 31, 2022
9 Oct 31, 2022

A large-scale (194k), Multiple-Choice Question Answering (MCQA) dataset designed to address realworld medical entrance exam questions.
MedMCQA MedMCQA : A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering A large-scale, Multiple-Choice Question Answe
 24 Nov 30, 2022
24 Nov 30, 2022

SentimentArcs: a large ensemble of dozens of sentiment analysis models to analyze emotion in text over time
SentimentArcs - Emotion in Text An end-to-end pipeline based on Jupyter notebooks to detect, extract, process and anlayze emotion over time in text. E
 14 Dec 19, 2022
14 Dec 19, 2022

Precision Medicine Knowledge Graph (PrimeKG)
PrimeKG Website | bioRxiv Paper | Harvard Dataverse Precision Medicine Knowledge Graph (PrimeKG) presents a holistic view of diseases. PrimeKG integra
 103 Dec 10, 2022
103 Dec 10, 2022
DLO8012: Natural Language Processing & CSL804: Computational Lab - II Semester VIII
NATURAL-LANGUAGE-PROCESSING-AND-COMPUTATIONAL-LAB-II DLO8012: NLP & CSL804: CL-II [SEMESTER VIII] Syllabus NLP - Reference Books THE WALL MEGA SATISH
 7 Apr 28, 2022
7 Apr 28, 2022
This repository contains helper functions which can help you generate additional data points depending on your NLP task.
NLP Albumentations For Data Augmentation This repository contains helper functions which can help you generate additional data points depending on you
6 May 22, 2022

A Persian Image Captioning model based on Vision Encoder Decoder Models of the transformers🤗.
Persian-Image-Captioning We fine-tuning the Vision Encoder Decoder Model for the task of image captioning on the coco-flickr-farsi dataset. The implem
 15 Aug 25, 2022
15 Aug 25, 2022
An official repository for tutorials of Probabilistic Modelling and Reasoning (2021/2022) - a University of Edinburgh master's course.
PMR computer tutorials on HMMs (2021-2022) This is a repository for computer tutorials of Probabilistic Modelling and Reasoning (2021/2022) - a Univer
 10 Dec 6, 2022
10 Dec 6, 2022
Contains the code and data for our #ICSE2022 paper titled as "CodeFill: Multi-token Code Completion by Jointly Learning from Structure and Naming Sequences"
CodeFill This repository contains the code for our paper titled as "CodeFill: Multi-token Code Completion by Jointly Learning from Structure and Namin
 11 Oct 31, 2022
11 Oct 31, 2022
✔👉A Centralized WebApp to Ensure Road Safety by checking on with the activities of the driver and activating label generator using NLP.
AI-For-Road-Safety Challenge hosted by Omdena Hyderabad Chapter Original Repo Link : https://github.com/OmdenaAI/omdena-india-roadsafety Final Present
 7 Nov 29, 2022
7 Nov 29, 2022

Winner system (DAMO-NLP) of SemEval 2022 MultiCoNER shared task over 10 out of 13 tracks.
KB-NER: a Knowledge-based System for Multilingual Complex Named Entity Recognition The code is for the winner system (DAMO-NLP) of SemEval 2022 MultiC
 116 Dec 27, 2022
116 Dec 27, 2022

Enterprise Scale NLP with Hugging Face & SageMaker Workshop series
Workshop: Enterprise-Scale NLP with Hugging Face & Amazon SageMaker Earlier this year we announced a strategic collaboration with Amazon to make it ea
 161 Dec 16, 2022
161 Dec 16, 2022
Statistics and Mathematics for Machine Learning, Deep Learning , Deep NLP
Stat4ML Statistics and Mathematics for Machine Learning, Deep Learning , Deep NLP This is the first course from our trio courses: Statistics Foundatio
 83 Dec 29, 2022
83 Dec 29, 2022
Framework for evaluating ANNS algorithms on billion scale datasets.
Billion-Scale ANN http://big-ann-benchmarks.com/ Install The only prerequisite is Python (tested with 3.6) and Docker. Works with newer versions of Py
 132 Dec 24, 2022
132 Dec 24, 2022
Applied Natural Language Processing in the Enterprise - An O'Reilly Media Publication
Applied Natural Language Processing in the Enterprise This is the companion repo for Applied Natural Language Processing in the Enterprise, an O'Reill
 95 Jan 5, 2023
95 Jan 5, 2023
A benchmark for evaluation and comparison of various NLP tasks in Persian language.
Persian NLP Benchmark The repository aims to track existing natural language processing models and evaluate their performance on well-known datasets.
 68 Dec 19, 2022
68 Dec 19, 2022

Persian Bert For Long-Range Sequences
ParsBigBird: Persian Bert For Long-Range Sequences The Bert and ParsBert algorithms can handle texts with token lengths of up to 512, however, many ta
 63 Dec 14, 2022
63 Dec 14, 2022
![[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets](https://github.com/autonomousvision/stylegan_xl/raw/main/media/banner.png)
[SIGGRAPH'22] StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets
[Project] [PDF] This repository contains code for our SIGGRAPH'22 paper "StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets" by Axel Sauer, Katja
 742 Jan 4, 2023
742 Jan 4, 2023

APEACH: Attacking Pejorative Expressions with Analysis on Crowd-generated Hate Speech Evaluation Datasets
APEACH - Korean Hate Speech Evaluation Datasets APEACH is the first crowd-generated Korean evaluation dataset for hate speech detection. Sentences of
 70 Dec 6, 2022
70 Dec 6, 2022

CLIPfa: Connecting Farsi Text and Images
CLIPfa: Connecting Farsi Text and Images OpenAI released the paper Learning Transferable Visual Models From Natural Language Supervision in which they
66 Dec 14, 2022

Code Implementation of "Learning Span-Level Interactions for Aspect Sentiment Triplet Extraction".
Span-ASTE: Learning Span-Level Interactions for Aspect Sentiment Triplet Extraction ***** New March 31th, 2022: Scikit-Style API for Easy Usage *****
 111 Dec 23, 2022
111 Dec 23, 2022

This is a repo of basic Machine Learning!
Basic Machine Learning This repository contains a topic-wise curated list of Machine Learning and Deep Learning tutorials, articles and other resource
 53 Dec 31, 2022
53 Dec 31, 2022
Implementation of Basic Machine Learning Algorithms on small datasets using Scikit Learn.
Basic Machine Learning Algorithms All the basic Machine Learning Algorithms are implemented in Python using libraries Acknowledgements Machine Learnin
 47 Oct 16, 2022
47 Oct 16, 2022

🚀 RocketQA, dense retrieval for information retrieval and question answering, including both Chinese and English state-of-the-art models.
In recent years, the dense retrievers based on pre-trained language models have achieved remarkable progress. To facilitate more developers using cutt
 475 Jan 4, 2023
475 Jan 4, 2023
SciFive: a text-text transformer model for biomedical literature
SciFive SciFive provided a Text-Text framework for biomedical language and natural language in NLP. Under the T5's framework and desrbibed in the pape
 54 Dec 24, 2022
54 Dec 24, 2022
Multilingual Emotion classification using BERT (fine-tuning). Published at the WASSA workshop (ACL2022).
XLM-EMO: Multilingual Emotion Prediction in Social Media Text Abstract Detecting emotion in text allows social and computational scientists to study h
 35 Sep 17, 2022
35 Sep 17, 2022

ACL22 paper: Imputing Out-of-Vocabulary Embeddings with LOVE Makes Language Models Robust with Little Cost
Imputing Out-of-Vocabulary Embeddings with LOVE Makes Language Models Robust with Little Cost LOVE is accpeted by ACL22 main conference as a long pape
 32 Jan 3, 2023
32 Jan 3, 2023
Implementation of some unbalanced loss like focal_loss, dice_loss, DSC Loss, GHM Loss et.al
Implementation of some unbalanced loss for NLP task like focal_loss, dice_loss, DSC Loss, GHM Loss et.al Summary Here is a loss implementation reposit
 121 Jan 1, 2023
121 Jan 1, 2023

Code for the Findings of NAACL 2022(Long Paper): AdapterBias: Parameter-efficient Token-dependent Representation Shift for Adapters in NLP Tasks
AdapterBias: Parameter-efficient Token-dependent Representation Shift for Adapters in NLP Tasks arXiv link: upcoming To be published in Findings of NA
 16 Nov 12, 2022
16 Nov 12, 2022

Princeton NLP's pre-training library based on fairseq with DeepSpeed kernel integration 🚃
This repository provides a library for efficient training of masked language models (MLM), built with fairseq. We fork fairseq to give researchers mor
92 Dec 27, 2022
Helping data scientists better understand their datasets and models in text classification. With love from ServiceNow.
Azimuth, an open-source dataset and error analysis tool for text classification, with love from ServiceNow. Overview Azimuth is an open source applica
 145 Dec 23, 2022
145 Dec 23, 2022

A Flask Sentiment Analysis API, with visual implementation
The Sentiment Analysis Api was created using python flask module,it allows users to parse a text or sentence throught the (?text) arguement, then view the sentiment analysis of that sentence. It can be implementable into a web application.
 10 Jul 17, 2022
10 Jul 17, 2022
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets.
Adansons Base is a data management tool that organizes metadata of unstructured data and creates and organizes datasets. It makes dataset creation more effective and helps find essential insights from training results and improves AI performance.
 27 Oct 22, 2022
27 Oct 22, 2022
Text classification is one of the popular tasks in NLP that allows a program to classify free-text documents based on pre-defined classes.
Deep-Learning-for-Text-Document-Classification Text classification is one of the popular tasks in NLP that allows a program to classify free-text docu
 2 Mar 17, 2022
2 Mar 17, 2022

In this project we predict the forest cover type using the cartographic variables in the training/test datasets.
Kaggle Competition: Forest Cover Type Prediction In this project we predict the forest cover type (the predominant kind of tree cover) using the carto
 1 Mar 15, 2022
1 Mar 15, 2022
My implementation of Safaricom Machine Learning Codility test. The code has bugs, logical I guess I made errors and any correction will be appreciated.
Safaricom_Codility Machine Learning 2022 The test entails two questions. Question 1 was on Machine Learning. Question 2 was on SQL I ran out of time.
 1 Mar 3, 2022
1 Mar 3, 2022

Under the hood working of transformers, fine-tuning GPT-3 models, DeBERTa, vision models, and the start of Metaverse, using a variety of NLP platforms: Hugging Face, OpenAI API, Trax, and AllenNLP
Transformers-for-NLP-2nd-Edition @copyright 2022, Packt Publishing, Denis Rothman Contact me for any question you have on LinkedIn Get the book on Ama
 150 Dec 23, 2022
150 Dec 23, 2022
Implementaion of our ACL 2022 paper Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation
Bridging the Data Gap between Training and Inference for Unsupervised Neural Machine Translation This is the implementaion of our paper: Bridging the
 20 Dec 12, 2022
20 Dec 12, 2022
An extension package of 🤗 Datasets that provides support for executing arbitrary SQL queries on HF datasets
datasets_sql A 🤗 Datasets extension package that provides support for executing arbitrary SQL queries on HF datasets. It uses DuckDB as a SQL engine
 19 Dec 15, 2022
19 Dec 15, 2022
This is a general repo that helps you develop fast/effective NLP classifiers using Huggingface
NLP Classifier Introduction This project trains a bert model on any NLP classifcation model. And uses the model in make predictions on new data using
 3 Mar 11, 2022
3 Mar 11, 2022
A simple Streamlit App to classify swahili news into different categories.
Swahili News Classifier Streamlit App A simple app to classify swahili news into different categories. Installation Install all streamlit requirements
 4 May 1, 2022
4 May 1, 2022
Transformers-regression - Regression Bugs Are In Your Model! Measuring, Reducing and Analyzing Regressions In NLP Model Updates
Regression Free Model Update Code for the paper: Regression Bugs Are In Your Mod
 2 Feb 17, 2022
2 Feb 17, 2022
SimCTG - A Contrastive Framework for Neural Text Generation
A Contrastive Framework for Neural Text Generation Authors: Yixuan Su, Tian Lan,
 345 Jan 3, 2023
345 Jan 3, 2023

Job-Recommend-Competition - Vectorwise Interpretable Attentions for Multimodal Tabular Data
SiD - Simple Deep Model Vectorwise Interpretable Attentions for Multimodal Tabul
 40 Dec 22, 2022
40 Dec 22, 2022

Text-Summarization-using-NLP - Text Summarization using NLP to fetch BBC News Article and summarize its text and also it includes custom article Summarization
Text-Summarization-using-NLP Text Summarization using NLP to fetch BBC News Arti
 21 Aug 6, 2022
21 Aug 6, 2022
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
VHub - An API that permits uploading of vulnerability datasets and return of the serialized data
 2 Feb 14, 2022
2 Feb 14, 2022
Using PyTorch Perform intent classification using three different models to see which one is better for this task
Using PyTorch Perform intent classification using three different models to see which one is better for this task
 1 Feb 14, 2022
1 Feb 14, 2022
OpenDelta - An Open-Source Framework for Paramter Efficient Tuning.
OpenDelta is a toolkit for parameter efficient methods (we dub it as delta tuning), by which users could flexibly assign (or add) a small amount parameters to update while keeping the most paramters frozen. By using OpenDelta, users could easily implement prefix-tuning, adapters, Lora, or any other types of delta tuning with preferred PTMs.
 386 Dec 26, 2022
386 Dec 26, 2022
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data"
Code and Datasets from the paper "Self-supervised contrastive learning for volcanic unrest detection from InSAR data" You can download the pretrained
 3 May 7, 2022
3 May 7, 2022

Automatic game data translator for RPGMaker-MV
RPGMaker-MV Translator 🕹️ 🎮 Use AI to translate all the dialogs and texts of your RPGMaker automatically. 👊 You worked hard to make your game, now
 11 Dec 26, 2022
11 Dec 26, 2022
This repository has a implementations of data augmentation for NLP for Japanese.
daaja This repository has a implementations of data augmentation for NLP for Japanese: EDA: Easy Data Augmentation Techniques for Boosting Performance
 60 Nov 11, 2022
60 Nov 11, 2022
Crowd-Kit is a powerful Python library that implements commonly-used aggregation methods for crowdsourced annotation and offers the relevant metrics and datasets
Crowd-Kit: Computational Quality Control for Crowdsourcing Documentation Crowd-Kit is a powerful Python library that implements commonly-used aggregat
 125 Dec 30, 2022
125 Dec 30, 2022
A repo for materials relating to the tutorial of CS-332 NLP
CS-332-NLP A repo for materials relating to the tutorial of CS-332 NLP Contents Tutorial 1: Introduction Corpus Regular expression Tokenization Tutori
 9 Feb 15, 2022
9 Feb 15, 2022

Datasets and pretrained Models for StyleGAN3 ...
Datasets and pretrained Models for StyleGAN3 ... Dear arfiticial friend, this is a collection of artistic datasets and models that we have put togethe
 34 Oct 6, 2022
34 Oct 6, 2022

What are the best Systems? New Perspectives on NLP Benchmarking
What are the best Systems? New Perspectives on NLP Benchmarking In Machine Learning, a benchmark refers to an ensemble of datasets associated with one
 12 Nov 3, 2022
12 Nov 3, 2022
Notebook and code to synthesize complex and highly dimensional datasets using Gretel APIs.
Gretel Trainer This code is designed to help users successfully train synthetic models on complex datasets with high row and column counts. The code w
 24 Nov 3, 2022
24 Nov 3, 2022
Create a semantic search engine with a neural network (i.e. BERT) whose knowledge base can be updated
Create a semantic search engine with a neural network (i.e. BERT) whose knowledge base can be updated. This engine can later be used for downstream tasks in NLP such as Q&A, summarization, generation, and natural language understanding (NLU).
 1 Mar 20, 2022
1 Mar 20, 2022
Course materials for a 3-day seminar "Machine Learning and NLP: Advances and Applications" at New College of Florida
Machine Learning and NLP: Advances and Applications This repository hosts the course materials used for a 3-day seminar "Machine Learning and NLP: Adv
 11 Jun 22, 2022
11 Jun 22, 2022
PyTorch implementation of the ExORL: Exploratory Data for Offline Reinforcement Learning
ExORL: Exploratory Data for Offline Reinforcement Learning This is an original PyTorch implementation of the ExORL framework from Don't Change the Alg
 52 Jan 1, 2023
52 Jan 1, 2023

Galois is an auto code completer for code editors (or any text editor) based on OpenAI GPT-2.
Galois is an auto code completer for code editors (or any text editor) based on OpenAI GPT-2. It is trained (finetuned) on a curated list of approximately 45K Python (~470MB) files gathered from the Github. Currently, it just works properly on Python but not bad at other languages (thanks to GPT-2's power).
 91 Sep 23, 2022
91 Sep 23, 2022

The pyrelational package offers a flexible workflow to enable active learning with as little change to the models and datasets as possible
pyrelational is a python active learning library developed by Relation Therapeutics for rapidly implementing active learning pipelines from data management, model development (and Bayesian approximation), to creating novel active learning strategies.
 95 Dec 27, 2022
95 Dec 27, 2022

I³ Tracker for Essential Open Innovation Datasets
I³ Tracker for Essential Open Innovation Datasets This repository is set up to track, version, and contribute updates to the I³ Essential Open Innovat
 1 Feb 8, 2022
1 Feb 8, 2022

BCI datasets and algorithms
Brainda Welcome! First and foremost, Welcome! Thank you for visiting the Brainda repository which was initially released at this repo and reorganized
 52 Jan 4, 2023
52 Jan 4, 2023

HAIS_2GNN: 3D Visual Grounding with Graph and Attention
HAIS_2GNN: 3D Visual Grounding with Graph and Attention This repository is for the HAIS_2GNN research project. Tao Gu, Yue Chen Introduction The motiv
 1 Nov 26, 2022
1 Nov 26, 2022

Complete* list of autonomous driving related datasets
AD Datasets Complete* and curated list of autonomous driving related datasets Contributing Contributions are very welcome! To add or update a dataset:
 13 Dec 19, 2022
13 Dec 19, 2022
L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources.
L3Cube-MahaCorpus L3Cube-MahaCorpus a Marathi monolingual data set scraped from different internet sources. We expand the existing Marathi monolingual
 21 Dec 17, 2022
21 Dec 17, 2022

Pytorch implementation of TailCalibX : Feature Generation for Long-tail Classification
TailCalibX : Feature Generation for Long-tail Classification by Rahul Vigneswaran, Marc T. Law, Vineeth N. Balasubramanian, Makarand Tapaswi [arXiv] [
 34 Jan 2, 2023
34 Jan 2, 2023
Estimation of the CEFR complexity score of a given word, sentence or text.
NLP-Swedish … allows to estimate CEFR (Common European Framework of References) complexity score of a given word, sentence or text. CEFR scores come f
 3 Apr 30, 2022
3 Apr 30, 2022

Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5
NLP-Summarizer Natural language processing summarizer using 3 state of the art Transformer models: BERT, GPT2, and T5 This project aimed to provide in
 1 Feb 7, 2022
1 Feb 7, 2022
Application to help find best train itinerary, uses speech to text, has a spam filter to segregate invalid inputs, NLP and Pathfinding algos.
T-IAI-901-MSC2022 - GROUP 18 Gestion de projet Notre travail a été organisé et réparti dans un Trello. https://trello.com/b/X3s2fpPJ/ia-projet Install
 1 Feb 5, 2022
1 Feb 5, 2022
/samples.jpg)
A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution.
Awesome Pretrained StyleGAN2 A collection of pre-trained StyleGAN2 models trained on different datasets at different resolution. Note the readme is a
 1.1k Dec 24, 2022
1.1k Dec 24, 2022

An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to art and design.
Awesome AI for Art & Design An awesome list of AI for art and design - resources, and popular datasets and how we may apply computer vision tasks to a
 20 Dec 21, 2022
20 Dec 21, 2022
nlabel is a library for generating, storing and retrieving tagging information and embedding vectors from various nlp libraries through a unified interface.
nlabel is a library for generating, storing and retrieving tagging information and embedding vectors from various nlp libraries through a unified interface.
 2 Jun 10, 2022
2 Jun 10, 2022
GraphNLI: A Graph-based Natural Language Inference Model for Polarity Prediction in Online Debates
GraphNLI: A Graph-based Natural Language Inference Model for Polarity Prediction in Online Debates Vibhor Agarwal, Sagar Joglekar, Anthony P. Young an
 2 Jun 30, 2022
2 Jun 30, 2022
Final Project for the Intel AI Readiness Boot Camp NLP (Jan)
NLP Boot Camp (Jan) Synopsis Full Name: Prameya Mohanty Name of your School: Delhi Public School, Rourkela Class: VIII Title of the Project: iTransect
 1 Feb 1, 2022
1 Feb 1, 2022

Espial is an engine for automated organization and discovery of personal knowledge
Live Demo (currently not running, on it) Espial is an engine for automated organization and discovery in knowledge bases. It can be adapted to run wit
 159 Dec 30, 2022
159 Dec 30, 2022
Mednlp - Medical natural language parsing and utility library
Medical natural language parsing and utility library A natural language medical
 3 Aug 24, 2022
3 Aug 24, 2022
LSTM model - IMDB review sentiment analysis
NLP - Movie review sentiment analysis The colab notebook contains the code for building a LSTM Recurrent Neural Network that gives 87-88% accuracy on
 1 Jan 29, 2022
1 Jan 29, 2022
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines
spaCy-wrap: For Wrapping fine-tuned transformers in spaCy pipelines spaCy-wrap is minimal library intended for wrapping fine-tuned transformers from t
 32 Dec 29, 2022
32 Dec 29, 2022
List of Land Cover datasets in the GEE Catalog
List of Land Cover datasets in the GEE Catalog A list of all the Land Cover (or discrete) datasets in Google Earth Engine. Values, Colors and Descript
 5 Aug 24, 2022
5 Aug 24, 2022
In this workshop we will be exploring NLP state of the art transformers, with SOTA models like T5 and BERT, then build a model using HugginFace transformers framework.
Transformers are all you need In this workshop we will be exploring NLP state of the art transformers, with SOTA models like T5 and BERT, then build a
 8 Apr 13, 2022
8 Apr 13, 2022

RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and rearranging captions and pictures. Unlike other versions of the model we use BERT for text encoder and SWIN transformer for image encoder.
ruCLIP-SB RuCLIP-SB (Russian Contrastive Language–Image Pretraining SWIN-BERT) is a multimodal model for obtaining images and text similarities and re
 5 Apr 13, 2022
5 Apr 13, 2022

This repository provides the official code for GeNER (an automated dataset Generation framework for NER).
GeNER This repository provides the official code for GeNER (an automated dataset Generation framework for NER). Overview of GeNER GeNER allows you to
 50 Nov 30, 2022
50 Nov 30, 2022
NLP applications using deep learning.
NLP-Natural-Language-Processing NLP applications using deep learning like text generation etc. 1- Poetry Generation: Using a collection of Irish Poem
 1 Jan 27, 2022
1 Jan 27, 2022
WikiPron - a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary
WikiPron WikiPron is a command-line tool and Python API for mining multilingual pronunciation data from Wiktionary, as well as a database of pronuncia
 213 Jan 1, 2023
213 Jan 1, 2023
Annotate datasets with a semi-trained or fully trained YOLOv5 model
YOLOv5 Auto Annotator Annotate datasets with a semi-trained or fully trained YOLOv5 model Prerequisites Ubuntu =20.04 Python =3.7 System dependencie
 3 May 14, 2022
3 May 14, 2022