2009 Repositories
Python unified-medical-language-system Libraries
Solving reinforcement learning tasks which require language and vision
Multimodal Reinforcement Learning JAX implementations of the following multimodal reinforcement learning approaches. Dual-coding Episodic Memory from
 31 Feb 26, 2022
31 Feb 26, 2022

DensePhrases provides answers to your natural language questions from the entire Wikipedia in real-time
DensePhrases provides answers to your natural language questions from the entire Wikipedia in real-time. While it efficiently searches the answers out of 60 billion phrases in Wikipedia, it is also very accurate having competitive accuracy with state-of-the-art open-domain QA models
 543 Jan 8, 2023
543 Jan 8, 2023
Cookiecutter API for creating Custom Skills for Azure Search using Python and Docker
cookiecutter-spacy-fastapi Python cookiecutter API for quick deployments of spaCy models with FastAPI Azure Search The API interface is compatible wit
 379 Jan 3, 2023
379 Jan 3, 2023
Facilitating the design, comparison and sharing of deep text matching models.
MatchZoo Facilitating the design, comparison and sharing of deep text matching models. MatchZoo 是一个通用的文本匹配工具包,它旨在方便大家快速的实现、比较、以及分享最新的深度文本匹配模型。 🔥 News
 3.4k Feb 18, 2021
3.4k Feb 18, 2021

Bidirectional LSTM-CRF and ELMo for Named-Entity Recognition, Part-of-Speech Tagging and so on.
anaGo anaGo is a Python library for sequence labeling(NER, PoS Tagging,...), implemented in Keras. anaGo can solve sequence labeling tasks such as nam
 1.4k Feb 17, 2021
1.4k Feb 17, 2021
Stand-alone language identification system
langid.py readme Introduction langid.py is a standalone Language Identification (LangID) tool. The design principles are as follows: Fast Pre-trained
 1.7k Feb 17, 2021
1.7k Feb 17, 2021
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
 11.7k Feb 18, 2021
11.7k Feb 18, 2021
Text vectorization tool to outperform TFIDF for classification tasks
WHAT: Supervised text vectorization tool Textvec is a text vectorization tool, with the aim to implement all the "classic" text vectorization NLP meth
 160 Feb 9, 2021
160 Feb 9, 2021
NLP library designed for reproducible experimentation management
Welcome to the Transfer NLP library, a framework built on top of PyTorch to promote reproducible experimentation and Transfer Learning in NLP You can
 287 Feb 14, 2021
287 Feb 14, 2021

NeuralQA: A Usable Library for Question Answering on Large Datasets with BERT
NeuralQA: A Usable Library for (Extractive) Question Answering on Large Datasets with BERT Still in alpha, lots of changes anticipated. View demo on n
 184 Feb 10, 2021
184 Feb 10, 2021
Translate - a PyTorch Language Library
NOTE PyTorch Translate is now deprecated, please use fairseq instead. Translate - a PyTorch Language Library Translate is a library for machine transl
 678 Feb 15, 2021
678 Feb 15, 2021
An Analysis Toolkit for Natural Language Generation (Translation, Captioning, Summarization, etc.)
VizSeq is a Python toolkit for visual analysis on text generation tasks like machine translation, summarization, image captioning, speech translation
 310 Feb 1, 2021
310 Feb 1, 2021

Textpipe: clean and extract metadata from text
textpipe: clean and extract metadata from text textpipe is a Python package for converting raw text in to clean, readable text and extracting metadata
 272 Feb 16, 2021
272 Feb 16, 2021
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
 718 Feb 18, 2021
718 Feb 18, 2021
Kashgari is a production-level NLP Transfer learning framework built on top of tf.keras for text-labeling and text-classification, includes Word2Vec, BERT, and GPT2 Language Embedding.
Kashgari Overview | Performance | Installation | Documentation | Contributing 🎉 🎉 🎉 We released the 2.0.0 version with TF2 Support. 🎉 🎉 🎉 If you
 2k Feb 9, 2021
2k Feb 9, 2021
:house_with_garden: Fast & easy transfer learning for NLP. Harvesting language models for the industry. Focus on Question Answering.
(Framework for Adapting Representation Models) What is it? FARM makes Transfer Learning with BERT & Co simple, fast and enterprise-ready. It's built u
 1.1k Feb 14, 2021
1.1k Feb 14, 2021
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
 1.4k Feb 17, 2021
1.4k Feb 17, 2021
Toolkit for Machine Learning, Natural Language Processing, and Text Generation, in TensorFlow. This is part of the CASL project: http://casl-project.ai/
Texar is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar provides
 2.1k Feb 17, 2021
2.1k Feb 17, 2021
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
 2.6k Feb 18, 2021
2.6k Feb 18, 2021

Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
 1.5k Feb 17, 2021
1.5k Feb 17, 2021
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
 1.9k Feb 18, 2021
1.9k Feb 18, 2021
🛸 Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy
spacy-transformers: Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy This package provides spaCy components and architectures to use tr
 903 Feb 17, 2021
903 Feb 17, 2021

🦆 Contextually-keyed word vectors
sense2vec: Contextually-keyed word vectors sense2vec (Trask et. al, 2015) is a nice twist on word2vec that lets you learn more interesting and detaile
1.2k Feb 17, 2021

⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
Translations 🇩🇪 DE 🇫🇷 FR 🇭🇺 HU 🇮🇩 ID 🇮🇹 IT 🇳🇱 NL 🇧🇷 PT-BR 🇷🇺 RU 🇨🇳 ZH ➡️ Documentation | Discord | Installation Guide ⬅️ Fully autom
 6.3k Feb 18, 2021
6.3k Feb 18, 2021
The Classical Language Toolkit
Notice: This Git branch (dev) contains the CLTK's upcoming major release (v. 1.0.0). See https://github.com/cltk/cltk/tree/master and https://docs.clt
 629 Feb 17, 2021
629 Feb 17, 2021

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
 1.4k Feb 17, 2021
1.4k Feb 17, 2021

fastNLP: A Modularized and Extensible NLP Framework. Currently still in incubation.
fastNLP fastNLP是一款轻量级的自然语言处理(NLP)工具包,目标是快速实现NLP任务以及构建复杂模型。 fastNLP具有如下的特性: 统一的Tabular式数据容器,简化数据预处理过程; 内置多种数据集的Loader和Pipe,省去预处理代码; 各种方便的NLP工具,例如Embedd
 2k Feb 14, 2021
2k Feb 14, 2021
Code for the paper "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer"
T5: Text-To-Text Transfer Transformer The t5 library serves primarily as code for reproducing the experiments in Exploring the Limits of Transfer Lear
 3.2k Feb 17, 2021
3.2k Feb 17, 2021
Official Stanford NLP Python Library for Many Human Languages
Stanza: A Python NLP Library for Many Human Languages The Stanford NLP Group's official Python NLP library. It contains support for running various ac
 5.2k Feb 17, 2021
5.2k Feb 17, 2021
A natural language modeling framework based on PyTorch
Overview PyText is a deep-learning based NLP modeling framework built on PyTorch. PyText addresses the often-conflicting requirements of enabling rapi
6.1k Feb 18, 2021
:mag: End-to-End Framework for building natural language search interfaces to data by utilizing Transformers and the State-of-the-Art of NLP. Supporting DPR, Elasticsearch, HuggingFace’s Modelhub and much more!
Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want
1.4k Feb 18, 2021
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
 1.9k Feb 18, 2021
1.9k Feb 18, 2021
NLP, before and after spaCy
textacy: NLP, before and after spaCy textacy is a Python library for performing a variety of natural language processing (NLP) tasks, built on the hig
 1.6k Feb 17, 2021
1.6k Feb 17, 2021
NLP made easy
GluonNLP: Your Choice of Deep Learning for NLP GluonNLP is a toolkit that helps you solve NLP problems. It provides easy-to-use tools that helps you l
 2.2k Feb 17, 2021
2.2k Feb 17, 2021
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production
Provides an implementation of today's most used tokenizers, with a focus on performance and versatility. Main features: Train new vocabularies and tok
 4.3k Feb 18, 2021
4.3k Feb 18, 2021
Simple, Pythonic, text processing--Sentiment analysis, part-of-speech tagging, noun phrase extraction, translation, and more.
TextBlob: Simplified Text Processing Homepage: https://textblob.readthedocs.io/ TextBlob is a Python (2 and 3) library for processing textual data. It
 7.5k Feb 17, 2021
7.5k Feb 17, 2021
An open-source NLP research library, built on PyTorch.
An Apache 2.0 NLP research library, built on PyTorch, for developing state-of-the-art deep learning models on a wide variety of linguistic tasks. Quic
 9.7k Feb 18, 2021
9.7k Feb 18, 2021
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. IMPORTANT: (30.08.2020) We moved our models
 10k Feb 18, 2021
10k Feb 18, 2021
Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabu
 4.8k Feb 18, 2021
4.8k Feb 18, 2021
ChatterBot is a machine learning, conversational dialog engine for creating chat bots
ChatterBot ChatterBot is a machine-learning based conversational dialog engine build in Python which makes it possible to generate responses based on
 10.8k Feb 18, 2021
10.8k Feb 18, 2021
💬 Open source machine learning framework to automate text- and voice-based conversations: NLU, dialogue management, connect to Slack, Facebook, and more - Create chatbots and voice assistants
Rasa Open Source Rasa is an open source machine learning framework to automate text-and voice-based conversations. With Rasa, you can build contextual
 10.8k Feb 18, 2021
10.8k Feb 18, 2021
NLTK Source
Natural Language Toolkit (NLTK) NLTK -- the Natural Language Toolkit -- is a suite of open source Python modules, data sets, and tutorials supporting
 9.6k Feb 17, 2021
9.6k Feb 17, 2021
🤗Transformers: State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0.
State-of-the-art Natural Language Processing for PyTorch and TensorFlow 2.0 🤗 Transformers provides thousands of pretrained models to perform tasks o
40.9k Feb 18, 2021
💫 Industrial-strength Natural Language Processing (NLP) in Python
spaCy: Industrial-strength NLP spaCy is a library for advanced Natural Language Processing in Python and Cython. It's built on the very latest researc
19.6k Feb 18, 2021
Flask user session management.
Flask-Login Flask-Login provides user session management for Flask. It handles the common tasks of logging in, logging out, and remembering your users
 2.7k Feb 17, 2021
2.7k Feb 17, 2021
Code for How To Create A Fully Automated AI Based Trading System With Python
AI Based Trading System This code works as a boilerplate for an AI based trading system with yfinance as data source and RobinHood or Alpaca as broker
 196 Jan 5, 2023
196 Jan 5, 2023

a spacial-temporal pattern detection system for home automation
Argos a spacial-temporal pattern detection system for home automation. Based on OpenCV and Tensorflow, can run on raspberry pi and notify HomeAssistan
 133 Jan 5, 2023
133 Jan 5, 2023
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language
UA-GEC: Grammatical Error Correction and Fluency Corpus for the Ukrainian Language This repository contains UA-GEC data and an accompanying Python lib
 227 Jan 2, 2023
227 Jan 2, 2023

Short, introductory guide for the Python programming language
100 Page Python Intro This book is a short, introductory guide for the Python programming language.
 185 Dec 26, 2022
185 Dec 26, 2022
InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective
InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective This is the official code base for our ICLR 2021 paper
 71 Nov 25, 2022
71 Nov 25, 2022
CJK computer science terms comparison / 中日韓電腦科學術語對照 / 日中韓のコンピュータ科学の用語対照 / 한·중·일 전산학 용어 대조
CJK computer science terms comparison This repository contains the source code of the website. You can see the website from the following link: Englis
 88 Dec 23, 2022
88 Dec 23, 2022
GAP-text2SQL: Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training
GAP-text2SQL: Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training Code and model from our AAAI 2021 paper
 83 Jan 9, 2023
83 Jan 9, 2023
Facilitating the design, comparison and sharing of deep text matching models.
MatchZoo Facilitating the design, comparison and sharing of deep text matching models. MatchZoo 是一个通用的文本匹配工具包,它旨在方便大家快速的实现、比较、以及分享最新的深度文本匹配模型。 🔥 News
3.7k Jan 2, 2023
Bidirectional LSTM-CRF and ELMo for Named-Entity Recognition, Part-of-Speech Tagging and so on.
anaGo anaGo is a Python library for sequence labeling(NER, PoS Tagging,...), implemented in Keras. anaGo can solve sequence labeling tasks such as nam
1.5k Dec 5, 2022
Stand-alone language identification system
langid.py readme Introduction langid.py is a standalone Language Identification (LangID) tool. The design principles are as follows: Fast Pre-trained
1.7k Feb 7, 2021
Topic Modelling for Humans
gensim – Topic Modelling in Python Gensim is a Python library for topic modelling, document indexing and similarity retrieval with large corpora. Targ
11.7k Feb 12, 2021
Text vectorization tool to outperform TFIDF for classification tasks
WHAT: Supervised text vectorization tool Textvec is a text vectorization tool, with the aim to implement all the "classic" text vectorization NLP meth
186 Dec 29, 2022
NLP library designed for reproducible experimentation management
Welcome to the Transfer NLP library, a framework built on top of PyTorch to promote reproducible experimentation and Transfer Learning in NLP You can
290 Dec 20, 2022
NeuralQA: A Usable Library for Question Answering on Large Datasets with BERT
NeuralQA: A Usable Library for (Extractive) Question Answering on Large Datasets with BERT Still in alpha, lots of changes anticipated. View demo on n
220 Dec 11, 2022
Translate - a PyTorch Language Library
NOTE PyTorch Translate is now deprecated, please use fairseq instead. Translate - a PyTorch Language Library Translate is a library for machine transl
775 Dec 24, 2022
An Analysis Toolkit for Natural Language Generation (Translation, Captioning, Summarization, etc.)
VizSeq is a Python toolkit for visual analysis on text generation tasks like machine translation, summarization, image captioning, speech translation
409 Oct 28, 2022
Textpipe: clean and extract metadata from text
textpipe: clean and extract metadata from text textpipe is a Python package for converting raw text in to clean, readable text and extracting metadata
298 Nov 21, 2022
Unsupervised text tokenizer focused on computational efficiency
YouTokenToMe YouTokenToMe is an unsupervised text tokenizer focused on computational efficiency. It currently implements fast Byte Pair Encoding (BPE)
847 Dec 19, 2022
Kashgari is a production-level NLP Transfer learning framework built on top of tf.keras for text-labeling and text-classification, includes Word2Vec, BERT, and GPT2 Language Embedding.
Kashgari Overview | Performance | Installation | Documentation | Contributing 🎉 🎉 🎉 We released the 2.0.0 version with TF2 Support. 🎉 🎉 🎉 If you
2.3k Dec 29, 2022
:house_with_garden: Fast & easy transfer learning for NLP. Harvesting language models for the industry. Focus on Question Answering.
(Framework for Adapting Representation Models) What is it? FARM makes Transfer Learning with BERT & Co simple, fast and enterprise-ready. It's built u
1.6k Dec 27, 2022
DELTA is a deep learning based natural language and speech processing platform.
DELTA - A DEep learning Language Technology plAtform What is DELTA? DELTA is a deep learning based end-to-end natural language and speech processing p
1.5k Dec 26, 2022
Toolkit for Machine Learning, Natural Language Processing, and Text Generation, in TensorFlow. This is part of the CASL project: http://casl-project.ai/
Texar is a toolkit aiming to support a broad set of machine learning, especially natural language processing and text generation tasks. Texar provides
2.3k Jan 7, 2023
A model library for exploring state-of-the-art deep learning topologies and techniques for optimizing Natural Language Processing neural networks
A Deep Learning NLP/NLU library by Intel® AI Lab Overview | Models | Installation | Examples | Documentation | Tutorials | Contributing NLP Architect
2.9k Jan 2, 2023
Beautiful visualizations of how language differs among document types.
Scattertext 0.1.0.0 A tool for finding distinguishing terms in corpora and displaying them in an interactive HTML scatter plot. Points corresponding t
2k Dec 27, 2022
Basic Utilities for PyTorch Natural Language Processing (NLP)
Basic Utilities for PyTorch Natural Language Processing (NLP) PyTorch-NLP, or torchnlp for short, is a library of basic utilities for PyTorch NLP. tor
1.9k Feb 3, 2021
🛸 Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy
spacy-transformers: Use pretrained transformers like BERT, XLNet and GPT-2 in spaCy This package provides spaCy components and architectures to use tr
1.2k Jan 8, 2023
🦆 Contextually-keyed word vectors
sense2vec: Contextually-keyed word vectors sense2vec (Trask et. al, 2015) is a nice twist on word2vec that lets you learn more interesting and detaile
1.5k Dec 25, 2022
⚡ Automatically decrypt encryptions without knowing the key or cipher, decode encodings, and crack hashes ⚡
Translations 🇩🇪 DE 🇫🇷 FR 🇭🇺 HU 🇮🇩 ID 🇮🇹 IT 🇳🇱 NL 🇧🇷 PT-BR 🇷🇺 RU 🇨🇳 ZH ➡️ Documentation | Discord | Installation Guide ⬅️ Fully autom
11.2k Jan 5, 2023
The Classical Language Toolkit
Notice: This Git branch (dev) contains the CLTK's upcoming major release (v. 1.0.0). See https://github.com/cltk/cltk/tree/master and https://docs.clt
629 Feb 11, 2021

Python implementation of TextRank for phrase extraction and summarization of text documents
PyTextRank PyTextRank is a Python implementation of TextRank as a spaCy pipeline extension, used to: extract the top-ranked phrases from text document
1.9k Jan 6, 2023
fastNLP: A Modularized and Extensible NLP Framework. Currently still in incubation.
fastNLP fastNLP是一款轻量级的自然语言处理(NLP)工具包,目标是快速实现NLP任务以及构建复杂模型。 fastNLP具有如下的特性: 统一的Tabular式数据容器,简化数据预处理过程; 内置多种数据集的Loader和Pipe,省去预处理代码; 各种方便的NLP工具,例如Embedd
2.8k Jan 1, 2023
Code for the paper "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer"
T5: Text-To-Text Transfer Transformer The t5 library serves primarily as code for reproducing the experiments in Exploring the Limits of Transfer Lear
4.6k Jan 1, 2023
Official Stanford NLP Python Library for Many Human Languages
Stanza: A Python NLP Library for Many Human Languages The Stanford NLP Group's official Python NLP library. It contains support for running various ac
5.2k Feb 12, 2021
A natural language modeling framework based on PyTorch
Overview PyText is a deep-learning based NLP modeling framework built on PyTorch. PyText addresses the often-conflicting requirements of enabling rapi
6.1k Feb 12, 2021
:mag: Transformers at scale for question answering & neural search. Using NLP via a modular Retriever-Reader-Pipeline. Supporting DPR, Elasticsearch, HuggingFace's Modelhub...
Haystack is an end-to-end framework for Question Answering & Neural search that enables you to ... ... ask questions in natural language and find gran
6.4k Jan 9, 2023
State of the Art Natural Language Processing
Spark NLP: State of the Art Natural Language Processing Spark NLP is a Natural Language Processing library built on top of Apache Spark ML. It provide
3k Jan 5, 2023
NLP, before and after spaCy
textacy: NLP, before and after spaCy textacy is a Python library for performing a variety of natural language processing (NLP) tasks, built on the hig
1.6k Feb 10, 2021
NLP made easy
GluonNLP: Your Choice of Deep Learning for NLP GluonNLP is a toolkit that helps you solve NLP problems. It provides easy-to-use tools that helps you l
2.5k Jan 4, 2023
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production
Provides an implementation of today's most used tokenizers, with a focus on performance and versatility. Main features: Train new vocabularies and tok
6.2k Dec 31, 2022
Simple, Pythonic, text processing--Sentiment analysis, part-of-speech tagging, noun phrase extraction, translation, and more.
TextBlob: Simplified Text Processing Homepage: https://textblob.readthedocs.io/ TextBlob is a Python (2 and 3) library for processing textual data. It
8.4k Dec 26, 2022
An open-source NLP research library, built on PyTorch.
An Apache 2.0 NLP research library, built on PyTorch, for developing state-of-the-art deep learning models on a wide variety of linguistic tasks. Quic
11.4k Jan 1, 2023
A very simple framework for state-of-the-art Natural Language Processing (NLP)
A very simple framework for state-of-the-art NLP. Developed by Humboldt University of Berlin and friends. IMPORTANT: (30.08.2020) We moved our models
12.3k Dec 31, 2022
Unsupervised text tokenizer for Neural Network-based text generation.
SentencePiece SentencePiece is an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabu
6.4k Jan 1, 2023
ChatterBot is a machine learning, conversational dialog engine for creating chat bots
ChatterBot ChatterBot is a machine-learning based conversational dialog engine build in Python which makes it possible to generate responses based on
12.8k Jan 3, 2023
💬 Open source machine learning framework to automate text- and voice-based conversations: NLU, dialogue management, connect to Slack, Facebook, and more - Create chatbots and voice assistants
Rasa Open Source Rasa is an open source machine learning framework to automate text-and voice-based conversations. With Rasa, you can build contextual
15.3k Jan 3, 2023
NLTK Source
Natural Language Toolkit (NLTK) NLTK -- the Natural Language Toolkit -- is a suite of open source Python modules, data sets, and tutorials supporting
11.4k Jan 4, 2023
🤗Transformers: State-of-the-art Natural Language Processing for Pytorch and TensorFlow 2.0.
State-of-the-art Natural Language Processing for PyTorch and TensorFlow 2.0 🤗 Transformers provides thousands of pretrained models to perform tasks o
77.3k Jan 3, 2023
💫 Industrial-strength Natural Language Processing (NLP) in Python
spaCy: Industrial-strength NLP spaCy is a library for advanced Natural Language Processing in Python and Cython. It's built on the very latest researc
19.5k Feb 13, 2021

Ludwig is a toolbox that allows to train and evaluate deep learning models without the need to write code.
Translated in 🇰🇷 Korean/ Ludwig is a toolbox that allows users to train and test deep learning models without the need to write code. It is built on
 8.7k Jan 5, 2023
8.7k Jan 5, 2023
Vowpal Wabbit is a machine learning system which pushes the frontier of machine learning with techniques such as online, hashing, allreduce, reductions, learning2search, active, and interactive learning.
This is the Vowpal Wabbit fast online learning code. Why Vowpal Wabbit? Vowpal Wabbit is a machine learning system which pushes the frontier of machin
 8.1k Jan 6, 2023
8.1k Jan 6, 2023
🔮 A refreshing functional take on deep learning, compatible with your favorite libraries
Thinc: A refreshing functional take on deep learning, compatible with your favorite libraries From the makers of spaCy, Prodigy and FastAPI Thinc is a
2.6k Dec 30, 2022
Apache Spark - A unified analytics engine for large-scale data processing
Apache Spark Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an op
 34.7k Jan 4, 2023
34.7k Jan 4, 2023
Diamond is a python daemon that collects system metrics and publishes them to Graphite (and others). It is capable of collecting cpu, memory, network, i/o, load and disk metrics. Additionally, it features an API for implementing custom collectors for gathering metrics from almost any source.
Diamond Diamond is a python daemon that collects system metrics and publishes them to Graphite (and others). It is capable of collecting cpu, memory,
 1.7k Jan 5, 2023
1.7k Jan 5, 2023
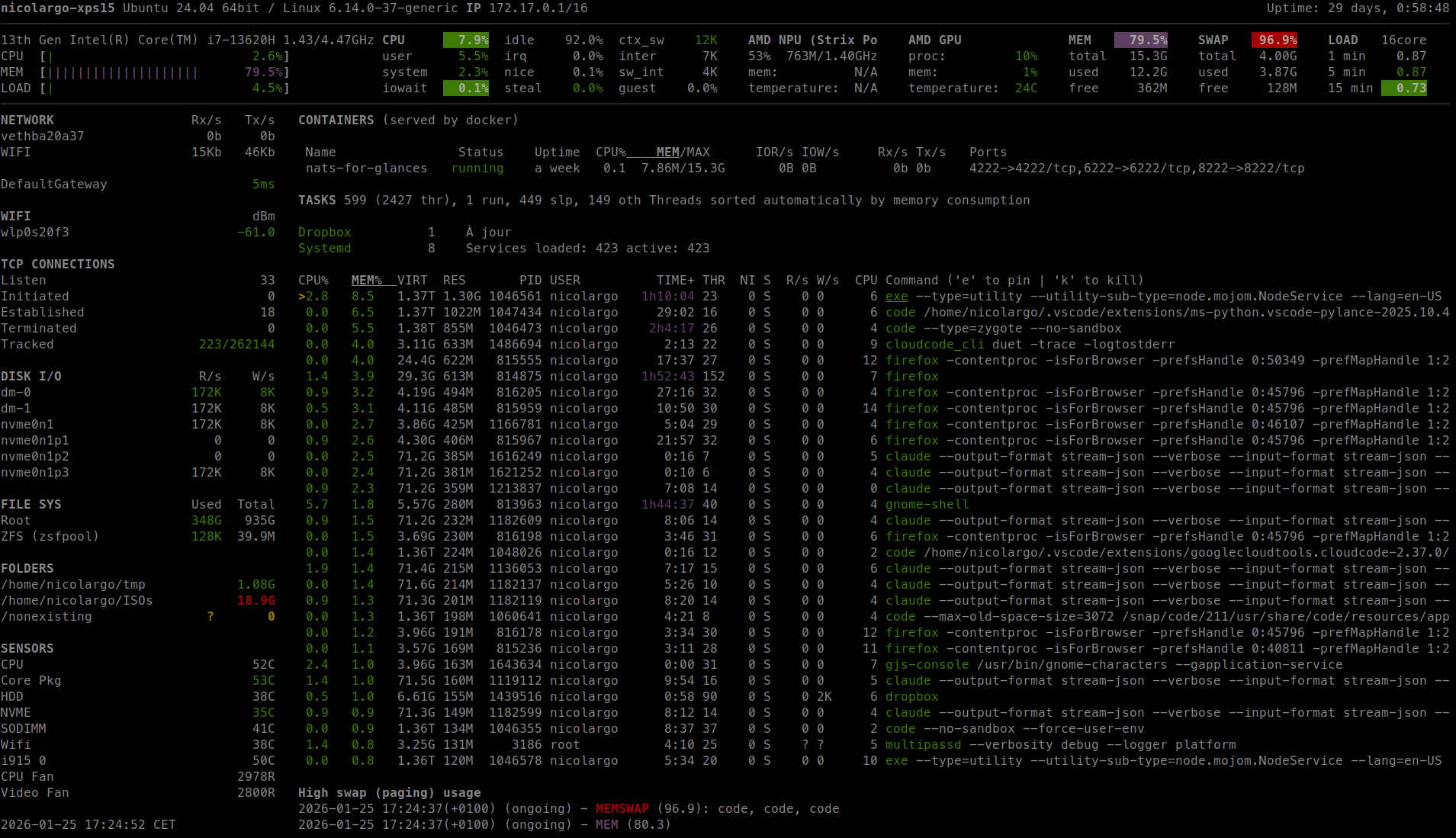
Glances an Eye on your system. A top/htop alternative for GNU/Linux, BSD, Mac OS and Windows operating systems.
Glances - An eye on your system Summary Glances is a cross-platform monitoring tool which aims to present a large amount of monitoring information thr
 22k Jan 4, 2023
22k Jan 4, 2023
Cross-platform lib for process and system monitoring in Python
Home Install Documentation Download Forum Blog Funding What's new Summary psutil (process and system utilities) is a cross-platform library for retrie
 9k Jan 2, 2023
9k Jan 2, 2023